




PolarDB PostgreSQL 扩展锁优化研究
关于 PolarDB PostgreSQL 版
PolarDB PostgreSQL 版是一款阿里云自主研发的云原生关系型数据库产品,100% 兼容 PostgreSQL,高度兼容Oracle语法;采用基于 Shared-Storage 的存储计算分离架构,具有极致弹性、毫秒级延迟、HTAP 、Ganos全空间数据处理能力和高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB PostgreSQL 版具有大规模并行计算能力,可以应对 OLTP 与 OLAP 混合负载。
前言
在进行并发 Insert
和Copy ... From ...
的时候,为了防止多个进程同时对一个表文件进行扩展,造成数据覆盖。PostgreSQL 设计了表扩展锁防止并发表扩展,但表扩展锁的锁定范围过长,同时也造成了并发 Insert
和 Copy ... From ...
的性能下降。本文将说明 PolarDB PostgreSQL 表扩展锁的分析和优化过程。
批量扩展性能分析
PolarDB PostgreSQL 为了适配底层 PolarFS(以下简称为 PFS)4 MB 扩展较优的特性,相较于 PostgreSQL 的 8KB 扩展,设计了 4MB 的批量扩展功能。但在 4MB 批量扩展的过程中,会全程持有表扩展锁,对性能造成影响。下面将从批量扩展的执行流程、性能瓶颈分析来进行说明。
执行流程
首先,一个 tuple 的写入基本可以表示为如下图的几个步骤:
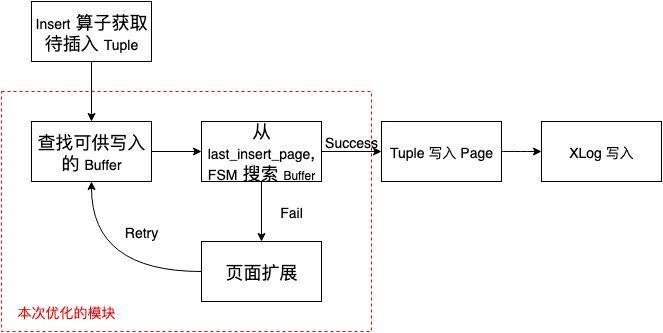
我们本次优化的部分主要是在页面扩展当中,而页面扩展的基本流程可以用下面的流程图来进行说明:
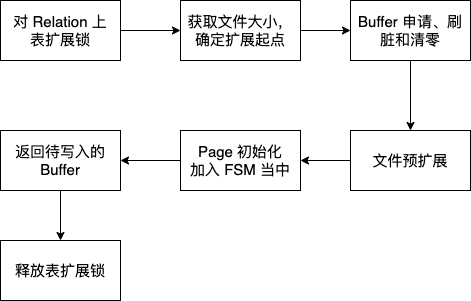
对 Relation 上表扩展锁,防止多个进程同时对表进行扩展,实现函数为
LockRelationForExtension()
,该锁为互斥锁。上完表扩展锁之后,文件的大小就只能由当前进程来修改,这时获取文件大小,确定扩展起点。
在 PostgreSQL 的设计中,我们对文件进行页面写入、扩展,都需要先写入 Buffer Pool 中这些文件页面对应的 Buffers,然后再由这些 Buffers 通过刷脏的方式写入到物理文件当中。所以批量扩展过程中需要对这些 Buffer 进行如下的步骤:
从 Buffer Pool 中申请 Buffer,申请的 Buffer 大小与要进行扩展的大小一致。批量扩展的大小是 4 MB,每个 Buffer 是 8 KB,一共要申请 512 个 Buffer。
如果申请出来的 Buffer 为 “脏”,也就是别的进程已经将其标记为脏页。则需要进行刷脏,将 Buffer 内的数据写入到文件当中,文件 I/O 是其中耗时较大的部分。
刷脏过后,则需要对这些 Buffer 通过 MemSet() 进行清零,保证写入扩展文件中的数据是全 0 的
对文件调用
smgr_bulkextend()
进行批量物理扩展对申请出来的这些全零 Buffer 通过
PageInit()
进行初始化,写入页面头和当前页面的剩余空间,并加入到 FSM 当中(FSM 全称为 free space map,该结构的作用是加快对表结构中空闲块的搜索和设置),其他进程可以访问这些空闲页面返回需要写入的 Buffer
释放表扩展锁
性能瓶颈分析
我们用 64 并发 Copy 来对批量扩展进行 Profiling 性能分析,具体的测试场景和参数在后文进行说明。通过 perf 和火焰图对 bulk_extend
进行了 ON-CPU 和 OFF-CPU 分析,由于在测试过程中看到 CPU 负载普遍在 30%~40% 之间,我们主要关注 OFF-CPU 的 profiling 结果
ON-CPU
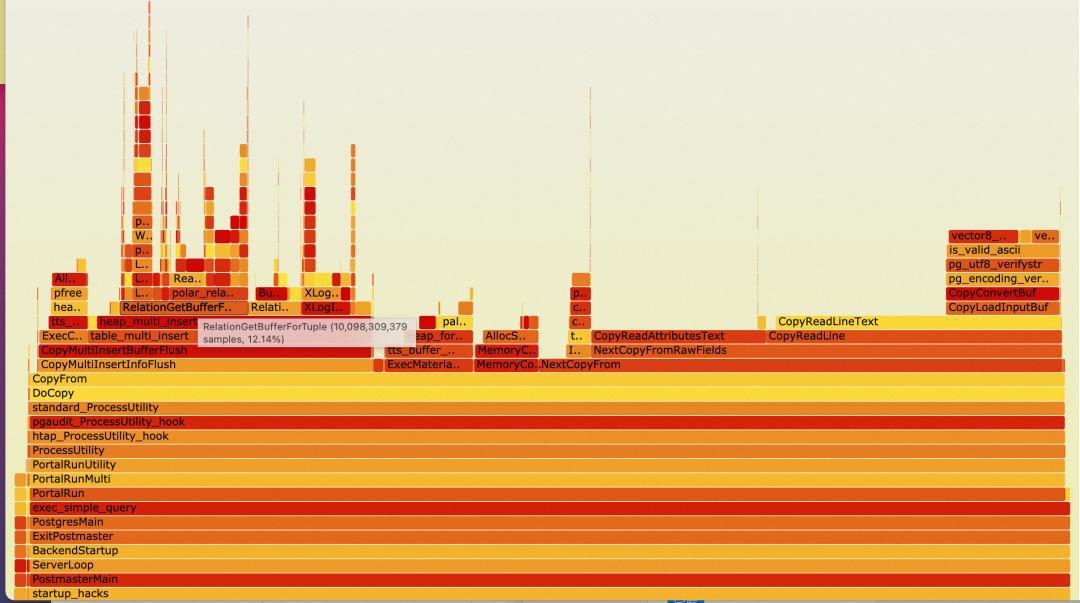
OFF-CPU

可以从 OFF-CPU 上很明显的看到 LockRelationForExtension
表扩展锁的开销占据所有 OFF-CPU 的开销 98.70%。表扩展为主要的瓶颈,所有的进程均在等待表扩展。
优化表扩展锁
这部分表扩展锁优化主要参考了 PG16 的表扩展锁优化方法,资料链接如下:
https://www.postgresql.org/message-id/flat/20221029025420.eplyow6k7tgu6he3%40awork3.anarazel.de
表扩展锁锁定范围
我们再来回顾一下表扩展锁的具体作用,他的锁定范围中有哪些是必要,哪些不必要。
必要:
调用
smgrnblocks()
获取当前文件大小将 Buffers 写入到 buffer mapping table 当中
将 Buffers 标记为 IO_IN_PROCESS
原因解释:
上锁的目的是为了防止当前进程在确定扩展起点的时候,不会将其他进程已经扩展的页面作为扩展起点,防止重复扩展
2,3. 目的是为了防止其他非扩页进程,在我们进行扩展的过程中,访问到该页面,进行刷脏,然后当前扩页进程又重复刷脏
不必要:
页面申请、刷脏和清零,这三个步骤均属于进程获取 Buffer 的过程,这部分由 Buffer Content 和 BufHdr 锁来保护并发,无需表扩展锁保护。
优化后的扩展流程
有了上文对扩展锁的分析,我们可以对表扩展锁的锁定范围进行如下图所示的优化:
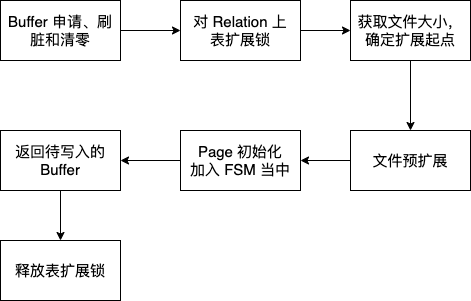
伪代码如下所示:
1. 计算扩展页面数量,一般为 512 (4MB),至多只能扩满一个 segment。
2. VictimBuffer(), 刷脏, MemSet() 清零
for (i = 0->block_count)
{
Get victim_buffer from StrategyGetBuffer()
Pin victim_buffer
if (victim_buffer is dirty)
{
Flush();
}
InvalidateVictimBuffer
{
Lock old buffer mapping table
Lock victim_buffer hdr
Invalidate victim_buffer hdr
Unlock victim_buffer hdr
Delete victim_buffer from buffer mapping table
Unlock old buffer mapping table
}
* Buffer 清零 */
MemSet(victim_buffer,0);
}
3. 上表扩展锁
LockRelationForExtension(relation, ExclusiveLock);
4. 获取文件大小,确定扩展起点
first_block = smgrnblocks(bmr.smgr, fork);
5. victim_buffer 写入 BufTable 中,并且将 hdr 置为 IO_IN_PROGRESS
for (i = 0->block_count)
{
Lock new buffer mapping table
Insert victim_buffer to buffer mapping table
Lock victim_buffer hdr
Init victim_buffer hdr
Unlock victim_buffer hdr
Unlock new buffer mapping table
StartBufferIO(victim_buffer);
}
6. 物理扩页
polar_smgrbulkextend();
7. 释放表扩展锁
8. TerminateBuffer()
for (i = 0->block_number)
{
对 first_block 上 Buffer_content 锁
TerminateBuffer(i);
}
9. 对 first_block 进行页面初始化,返回首个页面
对已经扩展的页面分为两类,一类即将使用的页面,另一类为不使用页面,不使用页面放入到 FSM 当中复制
简单来说,就是将 Buffer 申请、刷脏、清零操作,放在表扩展外,来提升性能。
同时,我们对 FSM 争抢问题也进行了优化,即将使用的页面用链表进行维护,来给下一次扩展使用;不使用的页面放入到 FSM 当中,给其他进程使用。
优化效果
在上述所示的 64 并发 Copy 的场景中进行了测试,测试的场景和相关参数如下图所示:
TPS 由 35.73 提升到了 41.40 ,同样的,我们也对并发 Copy 进行了 ON-CPU 和 OFF-CPU 的分析。我们仍然较为关注 OFF-CPU 的性能。
ON-CPU
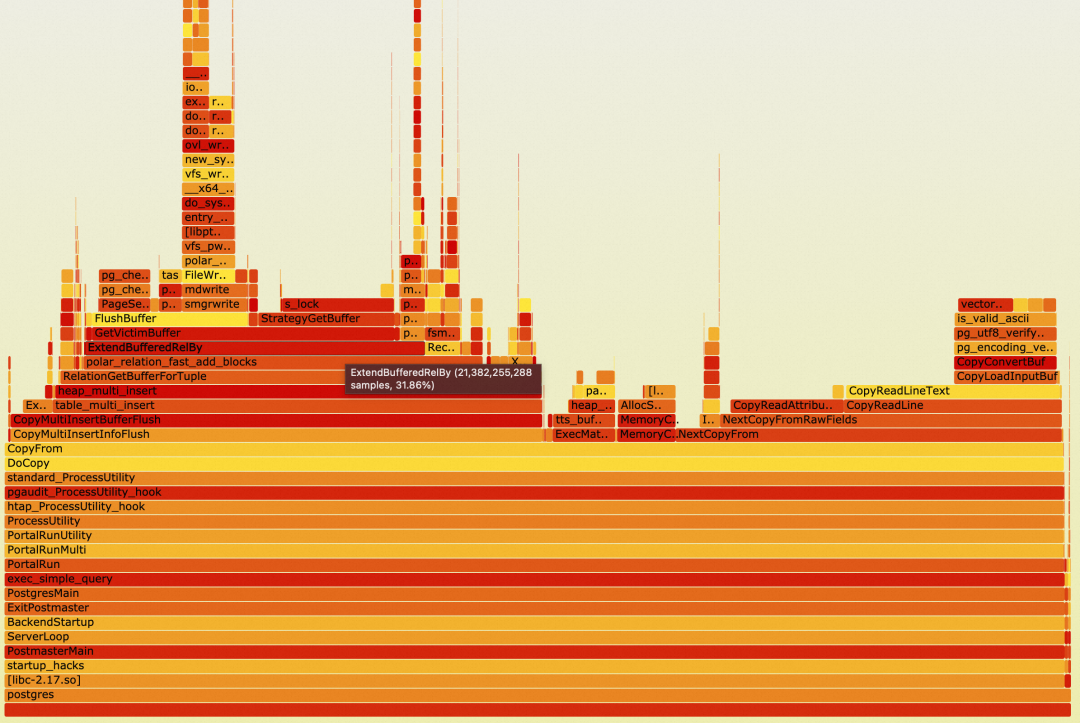
OFF-CPU

表扩展锁的 OFF-CPU 占比由 98% 降低到了 7.86%,这个时候 FlushBuffer 成为主要的性能瓶颈,占比 83%。
结论
通过表扩展锁优化,可以让并发 Copy 的性能提升约 15%,这部分的优化目前还仍处于 POC 阶段,后续将在 PolarDB PostgreSQL 进行上线。
