





本文字数:16012;估计阅读时间:41 分钟
作者:Lionel Palacin & Sai Srirampur

Meetup活动
ClickHouse 深圳第二届 Meetup 讲师招募中,欢迎讲师在文末扫码报名!
2024-09-10

越来越多的客户开始同时使用 Postgres 和 ClickHouse,其中 Postgres 主要用于事务处理,而 ClickHouse 负责分析型工作负载。两者各自针对不同的工作负载进行了优化。Postgres 与 ClickHouse 的常见集成方式之一是变更数据捕获(Change Data Capture,CDC)。CDC 可持续跟踪 Postgres 中的插入、更新和删除操作,并将这些数据复制到 ClickHouse,从而支持实时分析。
要实现 Postgres CDC 到 ClickHouse,可以使用 PeerDB(一个开源复制工具),或在 ClickHouse Cloud 中通过 ClickPipes 享受更完整的集成体验。由于 Postgres 和 ClickHouse 在架构上存在差异,除了复制数据外,在 ClickHouse 中合理设计表结构和查询方式同样至关重要,以提升性能。
本文将深入解析 Postgres CDC 到 ClickHouse 的内部工作原理,并介绍数据建模和查询优化的最佳实践。主要内容包括数据去重策略、自定义排序键的处理、JOIN 优化、物化视图(MVs,包括可刷新 MVs)、反规范化等。此外,这些方法不仅适用于 CDC 方案,还可以用于一次性迁移,因此,希望本文能帮助所有希望在 ClickHouse 进行数据分析的 Postgres 用户。去年年底,我们发布了该博客的第一版,本次更新将是进阶版本。
数据集
在本文中,我们将通过一个真实的数据集来演示这些策略。具体来说,我们选用了 StackOverflow 数据集的一个子集,并将其加载到 PostgreSQL 中。该数据集广泛用于 ClickHouse 官方文档,您可以在此处找到更多相关信息。此外,我们还开发了一个 Python 脚本来模拟 StackOverflow 用户的行为,并在 GitHub 上提供了实验复现的详细说明。

PostgreSQL 逻辑解码
ClickPipes 和 PeerDB 通过 Postgres 逻辑解码(Logical Decoding)实时获取 Postgres 中的数据变更。逻辑解码的机制允许 ClickPipes 这样的客户端以易读的方式接收变更数据,例如一系列 INSERT、UPDATE 和 DELETE 语句。如果想深入了解逻辑解码的工作原理,可以参考我们的一篇详细介绍该过程的博客。
在数据同步过程中,ClickPipes 会自动在 ClickHouse 中创建对应的表,并采用最本地化的数据类型映射。此外,它还能高效执行初始快照(snapshot)和回填(backfill)操作,以确保数据同步的完整性。
ReplacingMergeTree
ClickPipes 在 ClickHouse 中使用 ReplacingMergeTree 引擎来映射 Postgres 表。ClickHouse 在仅追加(append-only)模式下性能最佳,因此不建议频繁执行 UPDATE 操作,而 ReplacingMergeTree 在这种场景下尤为适用。
在 ReplacingMergeTree 模型中,UPDATE 操作会转换为带有更新版本号(_peerdb_version)的新插入(INSERT),而 DELETE 操作则转换为新插入,并将 _peerdb_is_deleted 标记为 true。ReplacingMergeTree 引擎会在后台自动去重并合并数据,确保同一主键(id)只保留最新版本,从而高效地处理 UPDATE 和 DELETE 操作,使其表现得像是版本化的插入。
下面是 ClickPipes 在 ClickHouse 中执行的 CREATE TABLE 语句示例:
CREATE TABLE users(`id` Int32,`reputation` String,`creationdate` DateTime64(6),`displayname` String,`lastaccessdate` DateTime64(6),`aboutme` String,`views` Int32,`upvotes` Int32,`downvotes` Int32,`websiteurl` String,`location` String,`accountid` Int32,`_peerdb_synced_at` DateTime64(9) DEFAULT now64(),`_peerdb_is_deleted` Int8,`_peerdb_version` Int64)ENGINE = ReplacingMergeTree(_peerdb_version)PRIMARY KEY idORDER BY id;
示例说明
下图展示了如何使用 ClickPipes 在 PostgreSQL 和 ClickHouse 之间同步 users 表的基本流程。
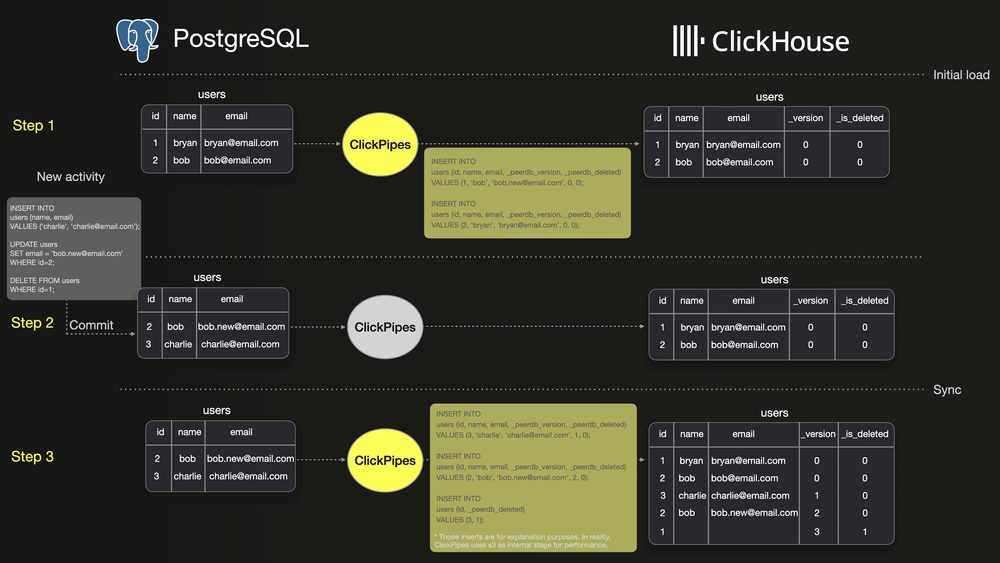
步骤 1:展示 PostgreSQL 中 users 表的初始快照,其中包含两行数据。同时,ClickPipes 执行初始加载,将这两行数据完整复制到 ClickHouse。
步骤 2:展示 users 表的三种数据变更操作——插入(INSERT)一行新数据、更新(UPDATE)一行已有数据,以及删除(DELETE)另一行数据。
步骤 3:展示 ClickPipes 如何将这些变更操作作为版本化的插入同步到 ClickHouse。UPDATE 操作会在 ClickHouse 中生成 ID 为 2 的新版本数据,而 DELETE 操作则会生成 ID 为 1 的新版本数据,并将 _deleted 字段标记为 true。因此,与 PostgreSQL 相比,ClickHouse 中的 users 表会额外存储三行数据。
因此,在 ClickHouse 中执行 SELECT count(*) FROM users; 这样的查询,可能会返回与 PostgreSQL 不同的结果。根据 ClickHouse 的合并(merge)机制,旧版本的数据最终会在合并过程中被清理。但由于合并发生的时间不可预测,这意味着在合并完成之前,ClickHouse 可能会返回与 PostgreSQL 不一致的查询结果。
那么,我们如何确保 ClickHouse 和 PostgreSQL 返回相同的查询结果呢?
本节介绍几种方法,以确保 ClickHouse 查询结果与 PostgreSQL 保持一致。
默认方法:使用 FINAL 关键字
在 ClickHouse 查询中,推荐使用 FINAL 关键字进行数据去重。这可以确保查询结果中仅包含去重后的数据,非常适用于通过 Postgres CDC 同步的 ClickHouse 表。只需在查询语句中添加 FINAL 关键字即可。
使用 FINAL 会增加一定的查询开销,但 ClickHouse 依然具备出色的查询性能。此外,ClickHouse 在多个版本更新中已对 FINAL 进行了性能优化(#73132、#73682、#58120、#47915)。
下面我们来看 FINAL 在三种查询中的具体应用。
请注意,以下示例查询中都使用了 WHERE 子句来过滤已删除的行。
简单计数查询:计算帖子数量
这是验证数据同步是否正确的最简单方式。PostgreSQL 和 ClickHouse 应该返回相同的计数结果。
-- PostgreSQLSELECT count(*) FROM posts;-- ClickHouseSELECT count(*) FROM posts FINAL where _peerdb_is_deleted=0;
带 JOIN 的简单聚合查询:统计累计浏览量最多的前 10 名用户
这是一个针对单个表的聚合查询。如果数据存在重复,会导致 `SUM` 计算结果出现偏差。
-- PostgreSQLSELECTsum(p.viewcount) AS viewcount,p.owneruserid as user_id,u.displayname as display_nameFROM posts pLEFT JOIN users u ON u.id = p.owneruseridWHERE p.owneruserid > 0GROUP BY user_id, display_nameORDER BY viewcount DESCLIMIT 10;-- ClickHouseSELECTsum(p.viewcount) AS viewcount,p.owneruserid AS user_id,u.displayname AS display_nameFROM posts AS pFINALLEFT JOIN users AS uFINAL ON (u.id = p.owneruserid) AND (u._peerdb_is_deleted = 0)WHERE (p.owneruserid > 0) AND (p._peerdb_is_deleted = 0)GROUP BYuser_id,display_nameORDER BY viewcount DESCLIMIT 10
如果不想在每个表名后都手动添加 FINAL,可以使用 FINAL 设置,使其自动应用于查询中的所有表。
该设置既可以应用于单个查询,也可以应用于整个会话,以减少手动添加 FINAL 的工作量。
-- Per query FINAL settingSELECT count(*) FROM posts SETTINGS final = 1;-- Set FINAL for the sessionSET final = 1;SELECT count(*) FROM posts;
另一种简化查询的方式是使用 ROW policy,它可以自动隐藏 _peerdb_is_deleted = 0 这一过滤条件。例如,下面的示例创建了一个行策略,使 votes 表的所有查询默认排除已删除的行。
-- Apply row policy to all usersCREATE ROW POLICY cdc_policy ON votes FOR SELECT USING _peerdb_is_deleted = 0 TO ALL;
行策略可以针对特定的用户和角色进行配置。在示例中,我们将其应用于所有用户和角色,但在实际应用时,建议根据具体需求仅对特定用户或角色生效。
以 PostgreSQL 风格查询 —— 最小化迁移成本
在将分析数据集从 PostgreSQL 迁移到 ClickHouse 时,通常需要调整查询语句,以适应两者在数据处理方式和查询执行上的差异。如前所述,为了确保 ClickHouse 中的数据正确去重,可能需要对 PostgreSQL 查询进行一定调整。
本节介绍几种方法,使原始查询无需修改即可兼容 ClickHouse。
视图(Views)
视图是一种避免在查询中直接使用 FINAL 关键字的有效方式。由于视图本身不存储数据,每次查询时都会从源表读取最新的数据。
下面的示例展示了如何在 ClickHouse 中为每个表创建视图,并自动在查询中包含 FINAL 关键字和已删除数据的过滤条件。
CREATE VIEW posts_view AS SELECT * FROM posts FINAL where _peerdb_is_deleted=0;CREATE VIEW users_view AS SELECT * FROM users FINAL where _peerdb_is_deleted=0;CREATE VIEW votes_view AS SELECT * FROM votes FINAL where _peerdb_is_deleted=0;CREATE VIEW comments_view AS SELECT * FROM comments FINAL where _peerdb_is_deleted=0;
这样,我们可以使用与 PostgreSQL 相同的 SQL 语句查询视图,而无需修改原始查询。
-- Most viewed postsSELECTsum(viewcount) AS viewcount,owneruseridFROM posts_viewWHERE owneruserid > 0GROUP BY owneruseridORDER BY viewcount DESCLIMIT 10
另一种方法是使用可刷新的物化视图(Refreshable Materialized View),通过定期执行查询,将去重后的数据存入目标表。每次刷新时,目标表都会被最新的查询结果替换。
这种方法的最大优势是,使用 FINAL 关键字的查询仅在刷新时执行一次,避免了后续查询的额外开销,提高了查询效率。
不过,这种方法的缺点是,目标表的数据只会在刷新时更新,因此数据的实时性取决于刷新频率。对于大多数场景来说,几分钟到几小时的刷新间隔通常已经足够。
-- Create deduplicated posts tableCREATE table deduplicated_posts AS posts;-- Create the Materialized view and schedule to run every hourCREATE MATERIALIZED VIEW deduplicated_posts_mv REFRESH EVERY 1 HOUR TO deduplicated_posts ASSELECT * FROM posts FINAL where _peerdb_is_deleted=0
之后,就可以像查询普通表一样查询 deduplicated_posts。
SELECTsum(viewcount) AS viewcount,owneruseridFROM deduplicated_postsWHERE owneruserid > 0GROUP BY owneruseridORDER BY viewcount DESCLIMIT 10;
进阶优化:调整合并设置
ClickHouse 的 ReplicatingMergeTree 引擎在数据合并(merge)时会自动进行去重,具体行为可参考官方文档。
默认情况下,ClickHouse 的合并操作频率较低,无法作为可靠的去重机制。不过,可以通过调整表的配置来优化合并的执行时间。
ReplacingMergeTree 文档列出了三个可以调整的参数,以便更频繁地触发数据合并:
min_age_to_force_merge_seconds:ClickHouse 仅合并比该值更早的数据分片。默认值为 0(禁用)。
min_age_to_force_merge_on_partition_only:控制 min_age_to_force_merge_seconds 是否仅适用于整个分区,而不适用于分区的子集。默认值为 false。
可以使用 ALTER TABLE 语句对现有表应用这些参数。例如,以下命令会将 posts 表的 min_age_to_force_merge_seconds 设置为 10 秒,并将 min_age_to_force_merge_on_partition_only 设置为 true:
-- Tune merge settingsALTER TABLE posts MODIFY SETTING min_age_to_force_merge_seconds=10;ALTER TABLE posts MODIFY SETTING min_age_to_force_merge_on_partition_only=true;
调整这些参数可以提高合并频率,显著减少重复数据,但无法完全杜绝重复。在某些分析型工作负载中,这种程度的去重已经足够。
排序键定义了 ClickHouse 表在磁盘上的数据排序方式,并影响查询的索引机制。在从 Postgres 复制数据时,ClickPipes 默认将 Postgres 表的主键作为 ClickHouse 表的排序键。通常,Postgres 主键已经足够用作 ClickHouse 的排序键,因为 ClickHouse 本身已针对快速扫描进行了优化,因此通常无需额外的自定义排序键。
但在更大规模的数据场景下,建议在 ClickHouse 的排序键中增加额外列,以提升查询性能。然而,修改排序键可能会导致 ClickHouse 处理数据去重的方式发生变化。因为在 ClickHouse 中,排序键不仅决定数据的存储顺序和索引方式,还会影响去重逻辑。关于这一限制的详细说明,请参考相关文档。最简单的解决方案是使用可刷新的物化视图(Refreshable Materialized Views)。
使用可刷新的物化视图
使用可刷新的物化视图(MVs)是一种定义自定义排序键(ORDER BY)的简单方法。MVs 允许你定期(例如每 5 或 10 分钟)重新整理整个表,并按照指定的排序键存储数据。有关更多详细信息和注意事项,请参考上面的章节。
以下是一个包含自定义 `ORDER BY` 和去重逻辑的可刷新的物化视图示例:
CREATE MATERIALIZED VIEW posts_finalREFRESH EVERY 10 second ENGINE = ReplacingMergeTree(_peerdb_version)ORDER BY (owneruserid,id) -- different ordering key but with suffixed postgres pkeyASSELECT * FROM posts FINALWHERE _peerdb_is_deleted = 0; -- this does the deduplication
自定义排序键(不使用可刷新的物化视图)
如果由于数据规模过大,导致可刷新的物化视图不可行,可以采用以下方法,在大型表上定义自定义排序键,并解决与去重相关的问题。
选择不会随行变化的排序键列
在 ClickHouse 中定义排序键时(除了 Postgres 主键之外),建议选择不会随行变化的列,以避免 ReplacingMergeTree 可能遇到的数据一致性和去重问题。
例如,在多租户 SaaS 应用中,使用 (tenant_id, id) 作为排序键是一个合理的选择。这些列可以唯一标识每一行数据,同时,即使其他列发生变化,tenant_id 也不会变更。由于 id 的去重方式与 (tenant_id, id) 一致,因此如果 tenant_id 发生变化,也不会影响去重。
注意:如果你的应用场景需要在排序键中包含可能发生变化的列,请联系我们(support@clickhouse.com)。我们有更高级的方法来应对这种情况,并可以与你一起制定合适的解决方案。
在 Postgres 表上设置 REPLICA IDENTITY 以匹配自定义排序键
为了确保 Postgres CDC 能够正确工作,必须修改表的 REPLICA IDENTITY,使其包含排序键列。这对于 DELETE 操作的正确处理尤为重要。
如果 REPLICA IDENTITY 不包含排序键列,Postgres CDC 仅捕获主键列的值,而不会记录其他列的变化——这是 Postgres 逻辑解码的限制。因此,在 Postgres CDC 解析时,除了主键之外的所有排序键列都将显示为 NULL。这可能导致去重失败,使得旧版本的行无法与 _peerdb_is_deleted 设为 1 的最新删除版本正确去重。
以 owneruserid 和 id 为例,如果主键中未包含 owneruserid,则需要在 (owneruserid, id) 上创建 UNIQUE INDEX,并将其设置为表的 REPLICA IDENTITY。这样可以确保 Postgres CDC 能够捕获必要的列值,以实现准确的复制和去重。
下面是 events 表的示例,展示如何应用这一配置。请确保对所有使用自定义排序键的表都进行相应的设置。
-- Create a UNIQUE INDEX on (owneruserid, id)CREATE UNIQUE INDEX posts_unique_owneruserid_idx ON posts(owneruserid, id);-- Set REPLICA IDENTITY to use this indexALTER TABLE posts REPLICA IDENTITY USING INDEX posts_unique_owneruserid_idx;
另一种选择:Projections(投影)
根据 ClickHouse 官方文档,Projections 适用于查询非主键列的数据。
但需要注意的是,Projections 在使用 FINAL 关键字查询时会被跳过,并且不会执行去重。因此,如果数据中不存在或很少出现重复(如 UPDATE、DELETE 操作),Projections 可能是一个可行的优化方案。
例如,我们希望按照 creationdate 字段对 posts 表进行排序,而不是使用默认的 id 排序。这种方式对于按日期范围筛选数据的查询有较大优势。
来看一个示例,我们查询 2024 年提及 "clickhouse" 的浏览量最高的帖子。
SELECTid,title,viewcountFROM stackoverflow.postsWHERE (toYear(creationdate) = 2024) AND (body LIKE '%clickhouse%')ORDER BY viewcount DESCLIMIT 55 rows in set. Elapsed: 0.617 sec. Processed 4.69 million rows, 714.67 MB (7.60 million rows/s., 1.16 GB/s.)Peak memory usage: 147.04 MiB.
默认情况下,ClickHouse 需要对整个表进行全表扫描,因为 ORDER BY 默认使用的是 id。在上一次查询中,ClickHouse 处理了 469 万行数据。现在,我们添加一个 Projection,使数据按照 creationdate 进行排序。
-- Create the ProjectionALTER TABLE posts ADD PROJECTION creation_date_projection (SELECT*ORDER BY creationdate);-- Materialize the ProjectionALTER TABLE posts MATERIALIZE PROJECTION creation_date_projection;
然后,我们再次运行相同的查询。
SELECTid,title,viewcountFROM stackoverflow.postsWHERE (toYear(creationdate) = 2024) AND (body LIKE '%clickhouse%')ORDER BY viewcount DESCLIMIT 55 rows in set. Elapsed: 0.438 sec. Processed 386.80 thousand rows, 680.42 MB (882.29 thousand rows/s., 1.55 GB/s.)Peak memory usage: 79.37 MiB.
ClickHouse 采用了 Projection 进行优化,使查询扫描的行数从 469 万大幅减少到 38.6 万,同时降低了内存消耗。
作为关系型数据库,Postgres 的数据模型通常高度规范化,可能涉及数百张表。用户常问:ClickHouse 是否可以沿用相同的数据模型?如何优化 JOIN 查询?
优化 JOINs
ClickHouse 在 JOIN 性能优化方面投入了大量资源。对于大多数场景,直接在 ClickHouse 上执行类似于 Postgres 的 JOIN 查询,通常能够获得更好的性能。
你可以直接运行原始的 JOIN 查询,看看 ClickHouse 的执行效果。
如果希望进一步优化,可以尝试以下方法:
使用子查询或 CTE 进行筛选:可以先在子查询中过滤数据,再传递给查询优化器执行 JOIN。虽然大多数情况下不需要,但在某些复杂查询中,这种方法可能会提高性能。下面是一个使用子查询优化 JOIN 的示例。
-- Use a subquery to reduce the number of rows to joinSELECTt.id AS UserId,t.displayname,t.views,COUNTDistinct(multiIf(c.id != 0, c.id, NULL)) AS CommentsCountFROM (SELECT id, displayname, viewsFROM usersORDER BY views DESCLIMIT 10) tLEFT JOIN comments c ON t.id = c.useridGROUP BY t.id, t.displayname, t.viewsORDER BY t.views DESCSETTINGS final=1;
优化排序键:可以考虑在表的排序键(Ordering Key)中包含 JOIN 相关的列。这样可以减少数据扫描量,提高查询效率。有关详细信息,请参考上方关于修改排序键的章节。
使用字典(Dictionaries)优化维度表:对于维度表,可以将其转换为 ClickHouse 的字典(Dictionary),以加快查询时的查找速度。例如,在 StackOverflow 数据集中,`votes` 表可以转换为字典,从而提高查询性能。官方文档提供了相关示例,展示如何利用字典优化 JOIN 查询。
选择合适的 JOIN 算法:ClickHouse 支持多种 JOIN 方式,具体选择取决于实际需求。本博客介绍了如何根据不同场景选择最优的 JOIN 算法。以下是两种 JOIN 查询的示例:第一种情况的目标是减少内存使用,因此使用 partial_merge 算法。第二种情况关注性能,因此使用 parallel_hash 算法。请注意,不同算法在内存占用和性能上的表现有所不同。
-- Use partial merge algorithmSELECTsum(p.viewcount) AS viewcount,p.owneruserid AS user_id,u.displayname AS display_nameFROM posts AS pFINALLEFT JOIN users AS uFINAL ON (u.id = p.owneruserid) AND (u._peerdb_is_deleted = 0)WHERE (p.owneruserid > 0) AND (p._peerdb_is_deleted = 0)GROUP BYuser_id,display_nameORDER BY viewcount DESCLIMIT 10FORMAT `NULL`SETTINGS join_algorithm = 'partial_merge'10 rows in set. Elapsed: 7.202 sec. Processed 60.42 million rows, 1.83 GB (8.39 million rows/s., 254.19 MB/s.)Peak memory usage: 1.99 GiB.-- Use parallel hash algorithmSELECTsum(p.viewcount) AS viewcount,p.owneruserid AS user_id,u.displayname AS display_nameFROM posts AS pFINALLEFT JOIN users AS uFINAL ON (u.id = p.owneruserid) AND (u._peerdb_is_deleted = 0)WHERE (p.owneruserid > 0) AND (p._peerdb_is_deleted = 0)GROUP BYuser_id,display_nameORDER BY viewcount DESCLIMIT 10FORMAT `NULL`SETTINGS join_algorithm = 'parallel_hash'10 rows in set. Elapsed: 2.160 sec. Processed 60.42 million rows, 1.83 GB (27.97 million rows/s., 847.53 MB/s.)Peak memory usage: 5.44 GiB.
反规范化(Denormalization)
另一种提升查询性能的方法是,在 ClickHouse 中对数据进行反规范化,使表结构更加扁平化。这可以通过可刷新的物化视图(Refreshable Materialized Views)或增量物化视图(Incremental Materialized Views)来实现。
在使用物化视图进行反规范化时,主要有两种方法。一种是原始反规范化(Raw Denormalization),直接展平原始数据,不进行任何转换。另一张是聚合反规范化(Aggregated Denormalization),在反规范化的同时,对数据进行聚合计算,并存入物化视图。
使用可刷新的物化视图进行原始反规范化
可刷新的物化视图可以轻松实现数据展平,同时还能在刷新时去重(具体方法请参考去重策略部分)。
以下示例展示了如何展平 posts 和 users 表以实现反规范化。
-- Create the RMVCREATE MATERIALIZED VIEW raw_denormalization_rmvREFRESH EVERY 1 MINUTE ENGINE = MergeTree()ORDER BY (id)ASSELECT p.*, u.* FROM posts p FINAL LEFT JOIN users u FINAL ON u.id = p.owneruserid AND u._peerdb_is_deleted = 0WHERE p._peerdb_is_deleted = 0;
几秒钟后,物化视图将填充 JOIN 查询的结果。此时,我们可以直接查询物化视图,而无需执行 JOIN 操作或使用 `FINAL` 关键字。
-- Number of posts and sum view for top 10 most upvoted usersSELECTcountDistinct(id) AS nb_posts,sum(viewcount) AS viewcount,u.id as user_id,displayname,upvotesFROM raw_denormalization_rmvGROUP BYuser_id,displayname,upvotesORDER BY upvotes DESCLIMIT 10
另一种常见的方法是,在反规范化的同时对数据进行聚合,并将结果存入单独的表,以提高查询性能,但这种方式会降低查询的灵活性。
例如,我们可以创建一个查询,将 posts、users、comments 和 votes 表进行 JOIN,以统计最受欢迎用户的帖子数、投票数和评论数。然后,使用可刷新的物化视图存储该查询结果。
-- Create the Refreshable materialized viewCREATE MATERIALIZED VIEW top_upvoted_users_activity_mv REFRESH EVERY 10 minute ENGINE = MergeTree()ORDER BY (upvotes)ASSELECTu.id AS UserId,u.displayname,u.upvotes,COUNT(DISTINCT CASE WHEN p.id <> 0 THEN p.id END) AS PostCount,COUNT(DISTINCT CASE WHEN c.id <> 0 THEN c.id END) AS CommentsCount,COUNT(DISTINCT CASE WHEN v.id <> 0 THEN v.id END) AS VotesCountFROM users AS uLEFT JOIN posts AS p ON u.id = p.owneruserid AND p._peerdb_is_deleted=0LEFT JOIN comments AS c ON u.id = c.userid AND c._peerdb_is_deleted=0LEFT JOIN votes AS v ON u.id = v.userid AND v._peerdb_is_deleted=0WHERE u._peerdb_is_deleted=0GROUP BYu.id,u.displayname,u.upvotesORDER BY u.upvotes DESCSETTINGS final=1;
由于该查询可能需要几分钟才能完成,因此在这种情况下无需使用公用表表达式(CTE),因为我们希望处理整个数据集。
要获取与 JOIN 查询相同的结果,我们只需对物化视图执行一个简单的查询。
SELECT *FROM top_upvoted_users_activity_mvORDER BY upvotes DESCLIMIT 10;
增量物化视图(Incremental Materialized Views)同样适用于原始反规范化(Raw Denormalization),相比可刷新的物化视图(RMVs),它有两个主要优势:
查询仅处理新插入的行,而不会扫描整个源表,因此适用于 PB 级别的大规模数据集。
增量物化视图在源表插入新行时实时更新,而 RMVs 需要定期刷新。
但它的一个局限是,无法在数据插入时去重。因此,在查询目标表时,仍需使用 FINAL 关键字来处理重复数据。
-- Create Materialized viewCREATE MATERIALIZED VIEW raw_denormalization_imvENGINE = ReplacingMergeTree(_peerdb_version)ORDER BY (id) POPULATE ASSELECT p.id as id, p.*, u.* FROM posts p LEFT JOIN users u ON p.owneruserid = u.id;
在查询该视图时,我们必须包含 FINAL 关键字,以去重数据。
SELECT count()FROM raw_denormalization_imvFINALWHERE _peerdb_is_deleted = 0
增量物化视图还可以在数据同步至 ClickHouse 时执行聚合,但这一过程更为复杂,因为需要同时处理重复数据和已删除数据。ClickHouse 提供了 AggregatingMergeTree 引擎,专门用于此类高级场景。
例如,我们希望统计 StackOverflow 上每日新增的问题数量。
-- Number of Questions and Answers per daySELECTCAST(toStartOfDay(creationdate), 'Date') AS Day,countIf(posttypeid = 1) AS Questions,countIf(posttypeid = 2) AS AnswersFROM postsGROUP BY DayORDER BY Day DESCLIMIT 5
一个挑战是,PostgreSQL 中的每次更新都会在 ClickHouse 中插入一条新行。如果直接聚合新增数据,可能会导致重复计数。
让我们看看 ClickHouse 在使用物化视图 (Materialized View) 结合 PostgreSQL 变更数据捕获 (CDC) 时是如何处理数据的。
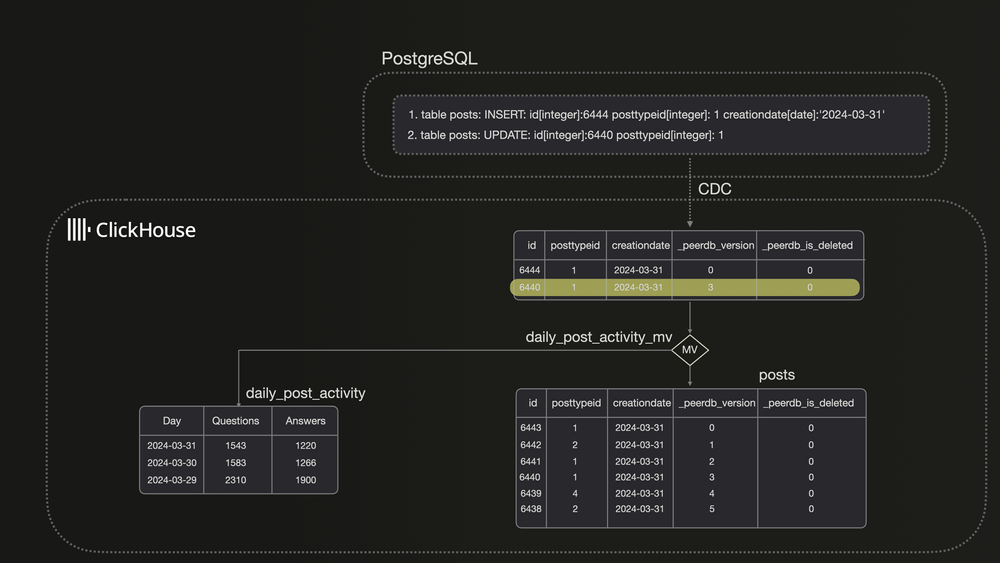
当 PostgreSQL 中 id=6440 的行被更新时,ClickHouse 会将新版本作为独立行插入。由于物化视图仅处理新插入的数据块,无法访问整个表,因此可能导致重复计数。
AggregatingMergeTree 通过仅保留每个主键(或 ORDER BY 键)对应的一行数据,并存储聚合计算状态,来避免这一问题。我们可以创建 daily_posts_activity 表,并使用 uniqState 进行去重。
CREATE TABLE daily_posts_activity(Day Date NOT NULL,Questions AggregateFunction(uniq, Nullable(Int32)),Answers AggregateFunction(uniq, Nullable(Int32)))ENGINE = AggregatingMergeTree()ORDER BY Day;
首先,我们从 posts 表导入数据,并使用 uniqState 函数统计字段的唯一值,以便去重。
INSERT INTO daily_posts_activitySELECT toStartOfDay(creationdate)::Date AS Day,uniqState(CASE WHEN posttypeid=1 THEN id END) as Questions,uniqState(CASE WHEN posttypeid=2 THEN id END) as AnswersFROM posts FINALGROUP BY Day
接着,我们创建一个物化视图,使其在每个新的数据块到来时自动执行查询。
CREATE MATERIALIZED VIEW daily_posts_activity_mv TO daily_posts_activity ASSELECT toStartOfDay(creationdate)::Date AS Day,uniqState(CASE WHEN posttypeid=1 THEN id END) as Questions,uniqState(CASE WHEN posttypeid=2 THEN id END) as AnswersFROM postsGROUP BY Day
要查询 daily_posts_activity,我们需要使用 uniqMerge 函数合并状态并返回正确的计数。
SELECTDay,uniqMerge(Questions) AS Questions,uniqMerge(Answers) AS AnswersFROM daily_posts_activityGROUP BY DayORDER BY Day DESCLIMIT 5
这种方法非常适用于我们的场景。
Postgres CDC 让 PostgreSQL 数据高效同步到 ClickHouse,支持大规模数据的实时分析。你可以使用 ClickPipes 进行云端集成,或尝试开源的 PeerDB 进行本地部署。

我们正为深圳活动招募讲师,如果你有独特的技术见解、实践经验或 ClickHouse 使用故事,非常欢迎你加入我们,成为这次活动的讲师,与大家分享你的经验。

/END/
 注册ClickHouse中国社区大使,领取认证考试券
注册ClickHouse中国社区大使,领取认证考试券

ClickHouse社区大使计划正式启动,首批过审贡献者享原厂认证考试券!
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


