




点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!
数据导出方法
我侧提供两种简便的ES数据导出方式:
kibana 通过kibana自带的CSV导出功能进行数据的导出(这种方式适用于数据量小于10m的数据,如果超过10m,会导致导出失败); logstash Logstash的配置非常灵活,用户可以通过修改配置文件来定义数据处理的流程和规则。这意味着在导出ES数据时,用户可以根据自己的需求定制Logstash的行为,例如指定导出的索引、设置查询条件、调整输出格式等。
kibana导出
2.1 创建索引模式
点击Stack Management:
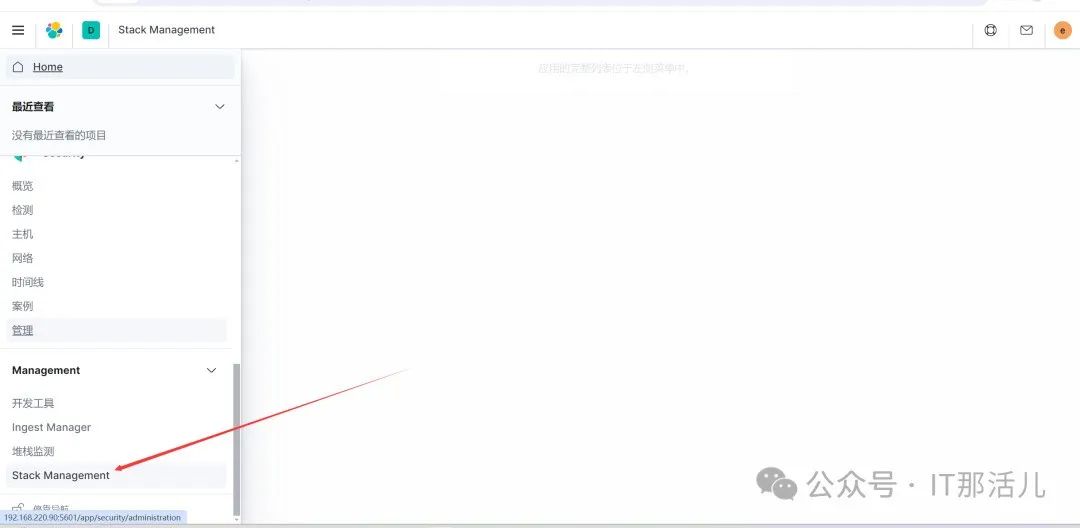
点击索引模式:
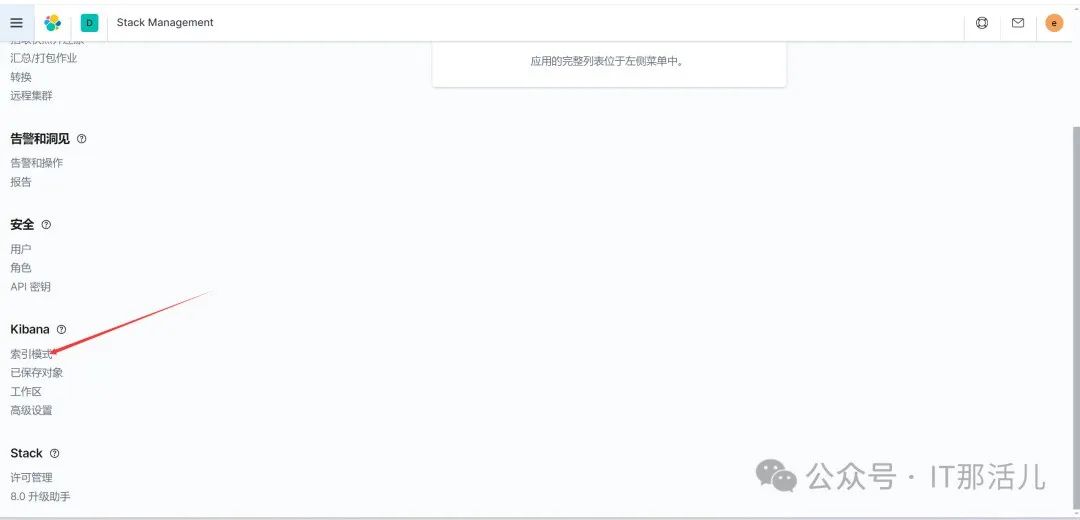
点击创建索引模式:
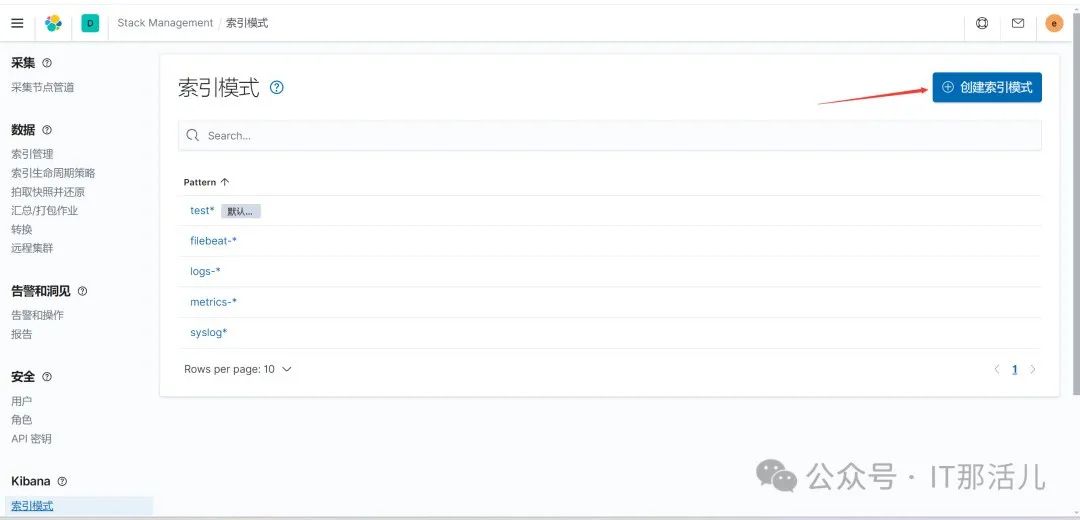
输入要导出的索引后,点击下一步:
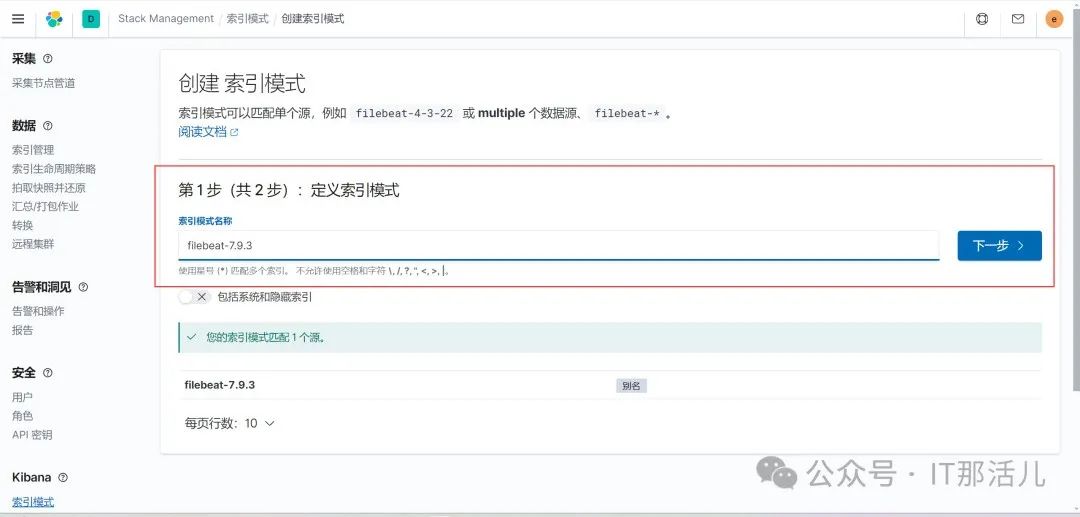
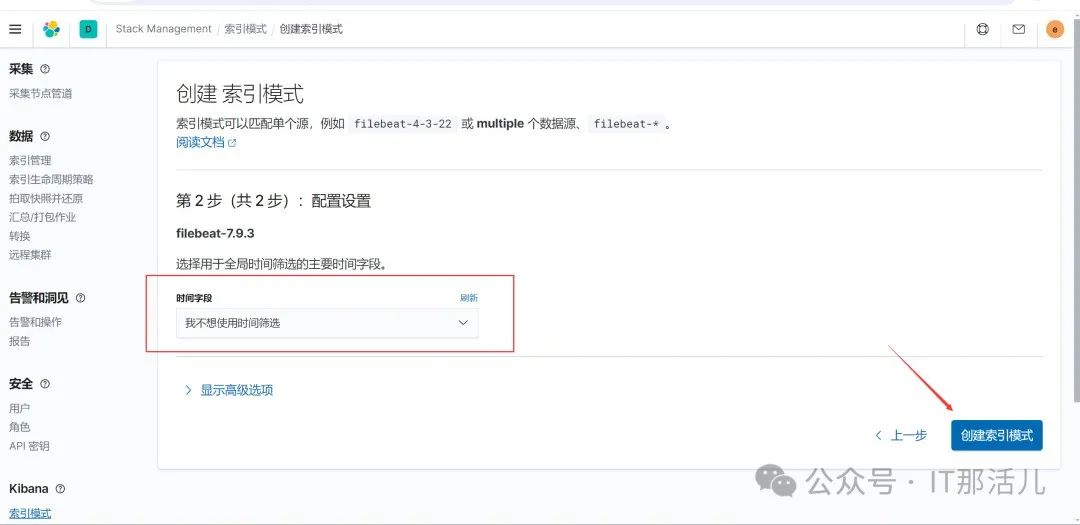
选择时间字段后,点击下一步:
2.2 导出CSV格式数据
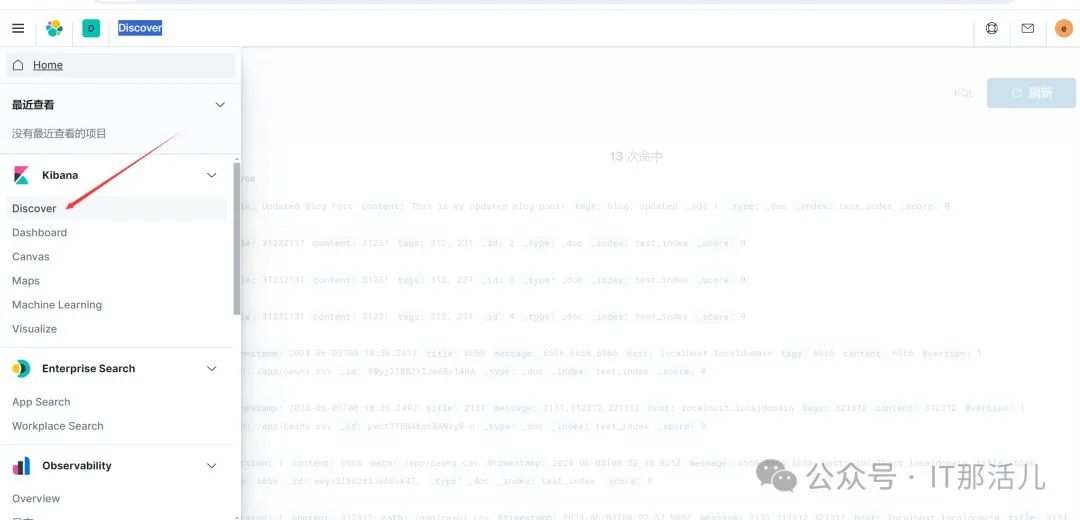
点击Discover:
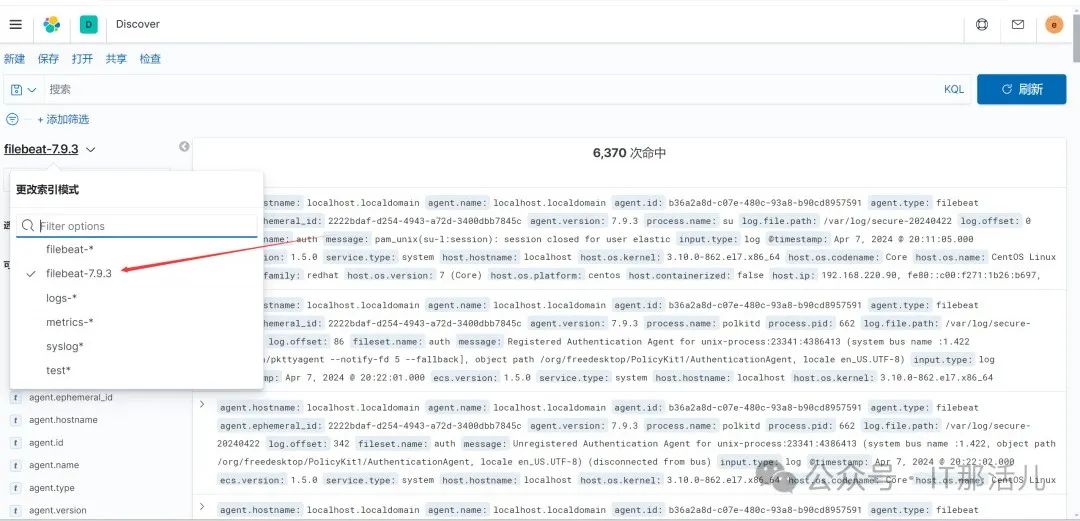
点击刚刚创建的索引模式:
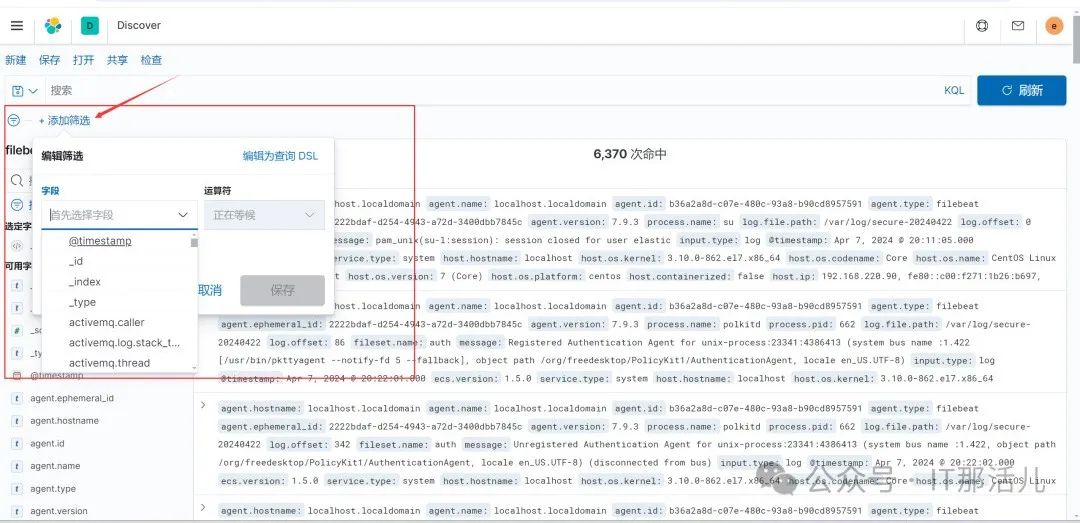
可以筛选出需要的数据(可省略):
保存Discover (保存的名字不能是中文):
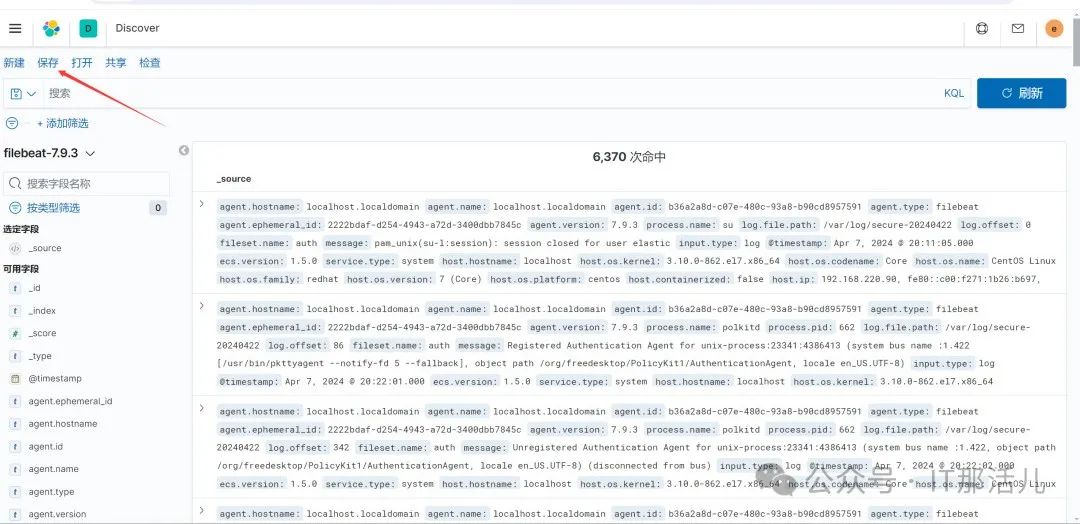
点击共享后,点击CSV报告,再点击生成CSV:
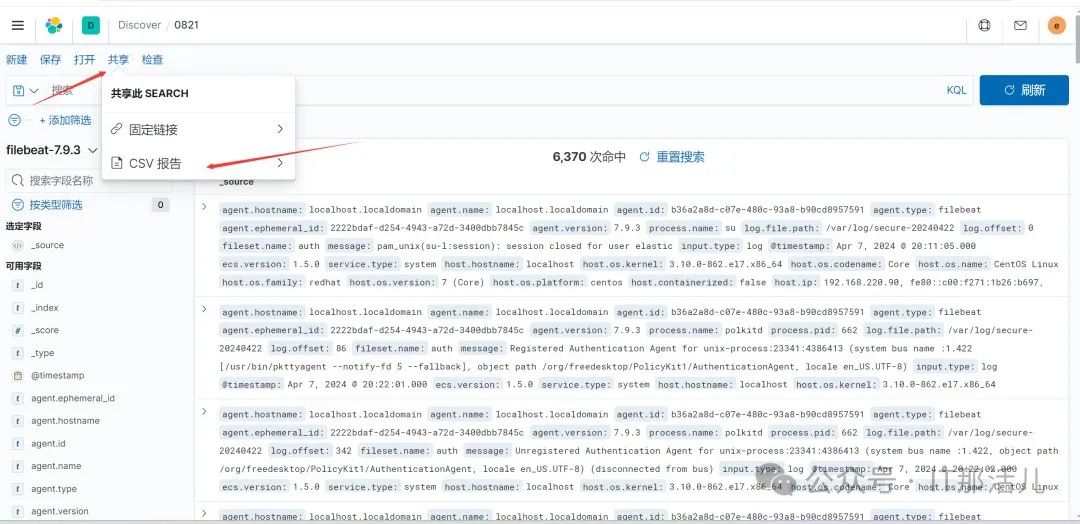
点击Stack Management:
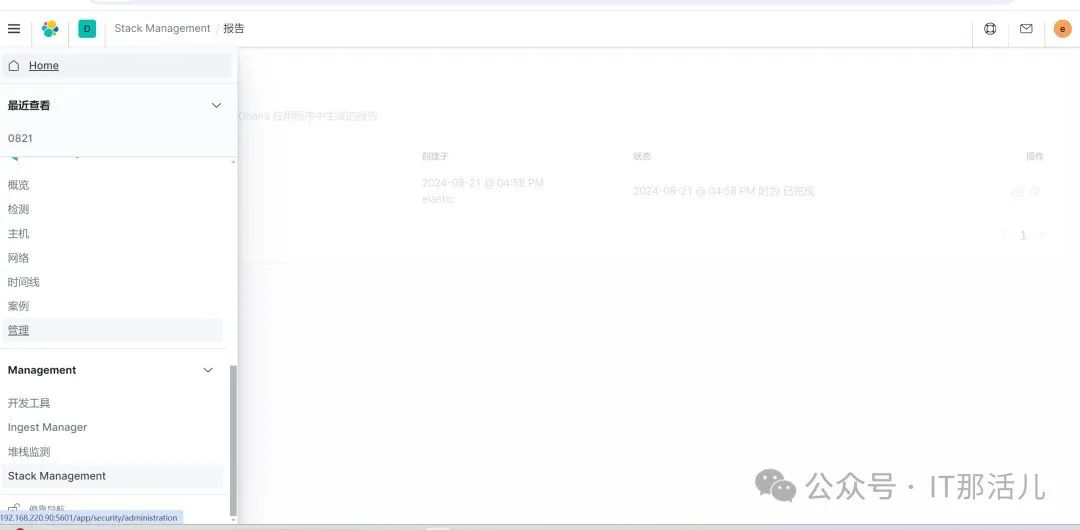
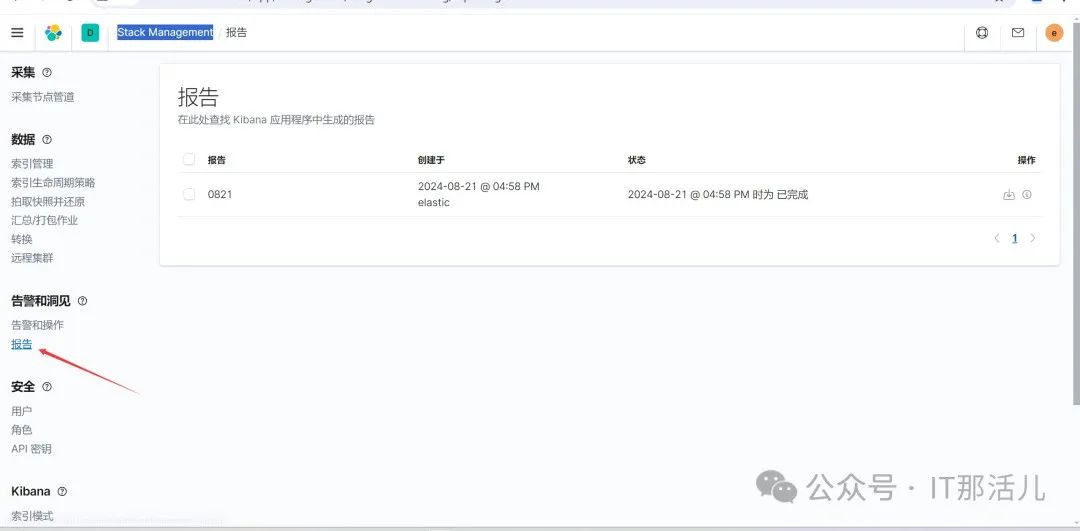
点击报告,会出现刚才的csv,最后点击下载按钮就可以了:
logstash导出
3.1 下载logstash
下载地址:
https://mirrors.huaweicloud.com/logstash/?C=N&O=D
根据集群的ES的版本选择相一致的版本进行安装。
logstash解压即可用,需要jdk环境。
3.2 创建配置文件
进入logstash目录下的config目录,创建一个名为0821.conf的配置文件(配置文件名可以修改):
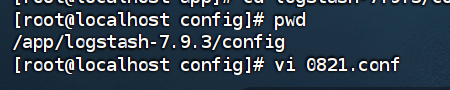
CSV格式配置文件:
input{
elasticsearch {
hosts => ["192.168.XXX.X0:9201","192.168.XXX.X1:9201"] #ES集群地址
user => "xxx"#ES用户名
password => "xxx"#ES用户密码
index => "test_index"#需要导出的索引名字
}
}
output{
csv {
fields => ["title", "content"] #需要导出的字段
path => "/app/0821.csv "#导出的路径
}
}
JSON格式配置文件:
input{
elasticsearch {
hosts => ["192.168.XXX.X0:9201","192.168.XXX.X1:9201"] #ES集群地址
user => "xxx" #ES用户名
password => "xxx" #ES用户密码
index => "test_index" #需要导出的索引名字
}
}
output{
file {
path => "/app/0821.csv " #导出的路径
}
}
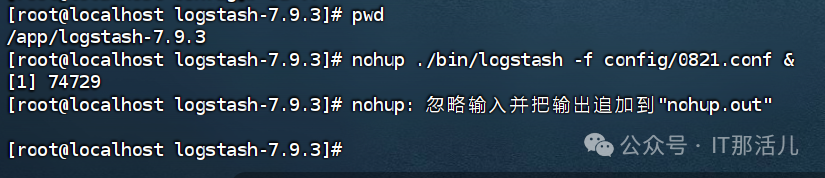
配置文件创建好后,返回logstash目录,执行logstash启动命令:
nohup ./bin/logstash -f config/0821.conf &
启动后输入两次回车:
查看logstash日志:
tail -200f nohup.out

然后去导出的路径就能看到数据已经导出:
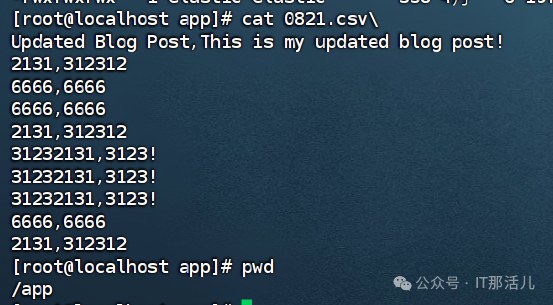
本文作者:章啸林(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
