




玖章算术是曾经的阿里数据库专家叶正盛(斗佛)创办的科技创新企业,研发了云原生智能数据管理平台NineData。很久以前,我曾经到杭州的阿里总部,被斗佛和瑞哥面过试,后来几次线上和线下的沟通请教,让我更深地了解了这些技术前辈们的功力,很是佩服。对于NineData,其实产品刚出来的时候,我曾试用过,确实有种让人眼前一亮的感觉,一些理念还是比较超前的。最近NineData推出了社区版,而且宣传的是提供永久免费、一键安装的数据管理解决方案,专为开发者、初创团队、教育机构及个人用户设计。社区版中包含NineData的数据库DevOps、数据复制、数据库对比三个核心功能,对于一些基本的数据库管理可以提供很便捷的服务和支持,
数据库DevOps:数据库DevOps具有数据源管理、数据查询、SQL规范、SQL审核、审批流程等强大功能,帮助用户快速完成多种环境的数据管理任务,助力企业数字化转型。
数据复制:NineData数据复制支持多种同异构数据源之间的离线、实时数据复制。适合数据迁移、数据库扩缩容、数据库版本升级、异地容灾、异地多活、数据仓库及数据湖数据集成等多种业务场景。
数据库对比:NineData数据库对比功能支持对两个数据源之间的内容进行一致性对比,不一致的情况下支持自动生成变更SQL,实现数据与结构的一致性。
需要强调的是,NineData社区版是一个完全离线运行的本地化部署版本,无需连接任何云端服务或访问NineData网站,所有数据与操作100%留存于您的本地环境。特别适用于无法访问外网的内网环境,完美匹配小规模企业、个人项目或学习测试等场景。这种部署形式对于一些特别关注数据安全的企业和个人来说,是相当重要的。
为了安装NineData社区版,需要具备docker的部署环境,如下是安装docker的一些常用指令,供参考,
[root@centos ~]# yum install -y yum-utils[root@centos ~]# yum install -y device-mapper-persistent-data[root@centos ~]# yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo[root@centos ~]# yum install docker-ce[root@centos ~]# systemctl start docker[root@centos ~]# systemctl start docker[root@centos ~]# docker --versionDocker version 26.1.4, build 5650f9b
创建docker应用账号,避免用root造成越权,
[root@centos ~]# useradd -g docker docker
安装NineData的镜像文件,针对不同地区,可以选择不同源,
[docker@centos ~]# docker run -p 9999:9999 --privileged -v /opt/ninedata:/u01 --name ninedata -d swr.cn-north-4.myhuaweicloud.com/ninedata/ninedata:latest

镜像有几个G,下载完成,就会自动安装部署和初始化服务,可以通过日志,观测它的进度,大约要5-10min,
[docker@centos ~] docker logs -f ninedata...[2025-03-14 11:01:50] : Waiting for node server-ssmvt to be ready.[2025-03-14 11:01:54] : Node server-ssmvt is ready.Context "default" modified.[2025-03-14 11:01:55] : The NiUP installation job is started.[2025-03-14 11:01:56] : Waiting for the MinIO installation job to start.[2025-03-14 11:02:07] : The MinIO installation job is running.[2025-03-14 11:02:29] : The MinIO installation job is completed.[2025-03-14 11:02:30] : The Registry installation job is running.[2025-03-14 11:02:40] : The Registry installation job is completed.[2025-03-14 11:02:41] : The MetaDB installation job is running....[2025-03-14 11:06:16] : The MetaDB installation job is completed.[2025-03-14 11:06:16] : The NineData Service installation job is running....[2025-03-14 11:08:37] : The NiUP installation job is completed.
当看到这个输出的时候,说明服务已经启动了,

按照它的提示,
Get started in 3 steps:1. Open the console using the above URL.2. Configure datasource to connect your databases.3. You can experience seamless Database DevOps operations, real-time cross-database replication, automated data comparisonwith instant repair capabilities - all managed through an intuitive visual interface with full-chain observability.
浏览器中输入http://[your-server-IP]:9999,即可打开登录,

登陆进入主界面,第一感觉就是比较简洁,界面上显示的基本都是重要的信息,没有任何拖拉,
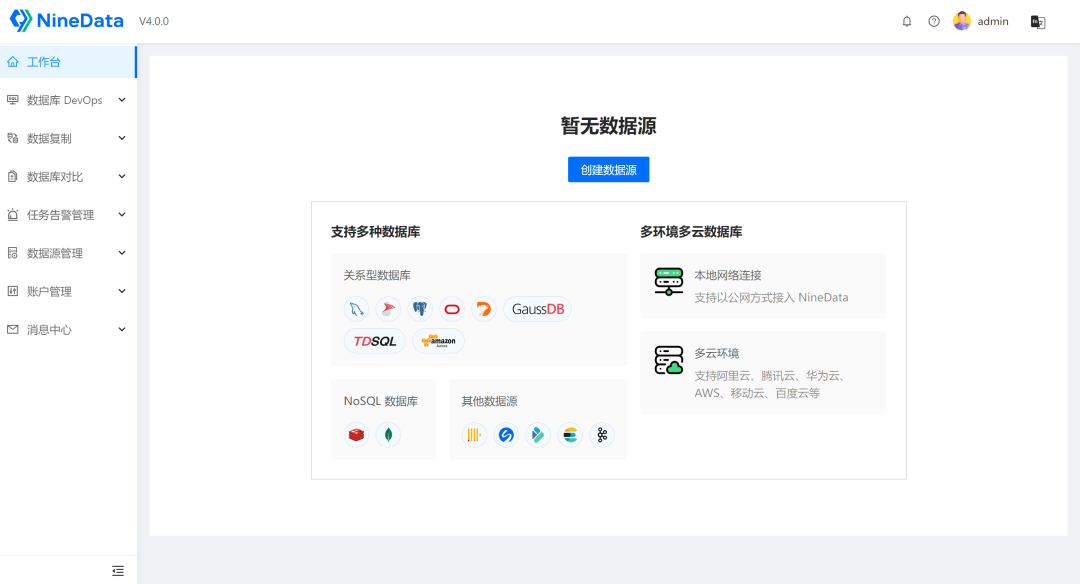
可支持创建的数据源类型很多,包括自建的,以及各种云服务厂商的,数据库类型涵盖了大部分主流的数据库,商业的、开源的、国产的,
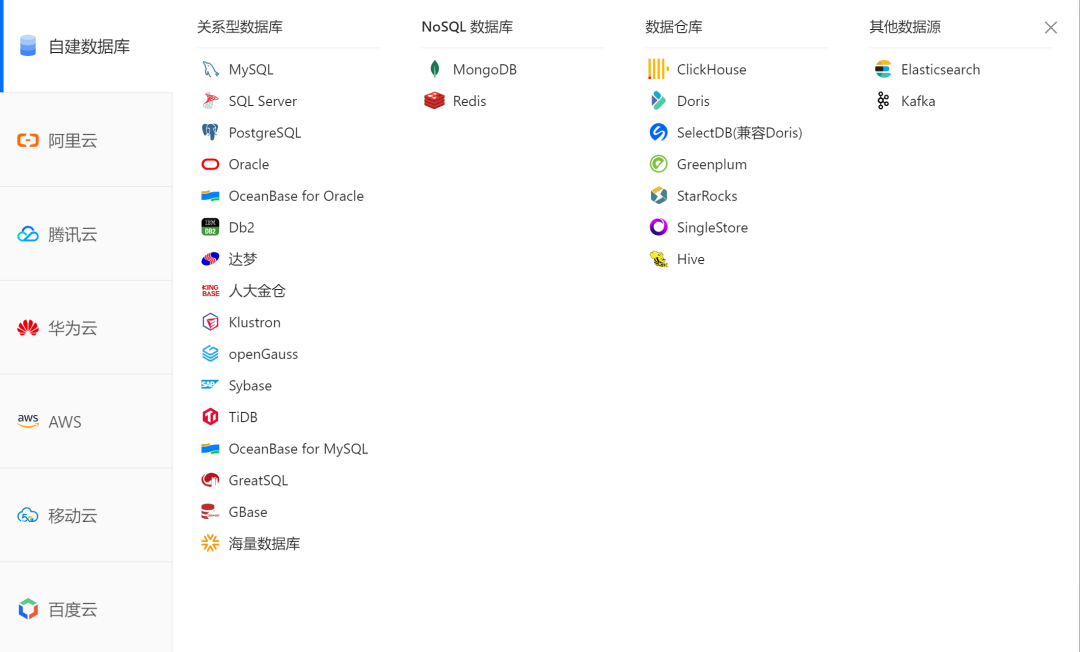
创建数据源,可以选择直连、SSH等多种形式,
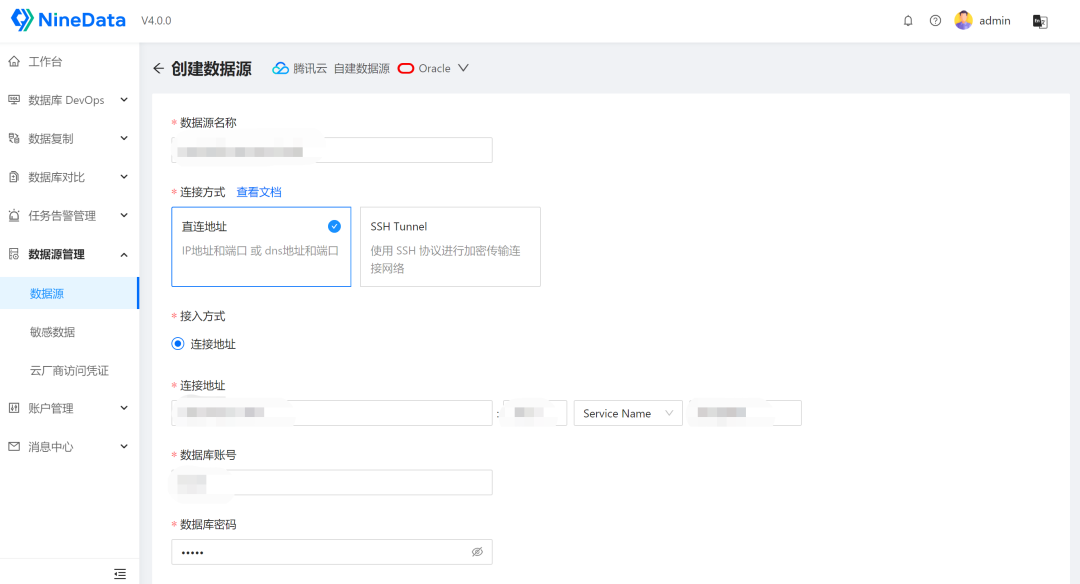
可以通过测试连接验证创建数据源的准确性,
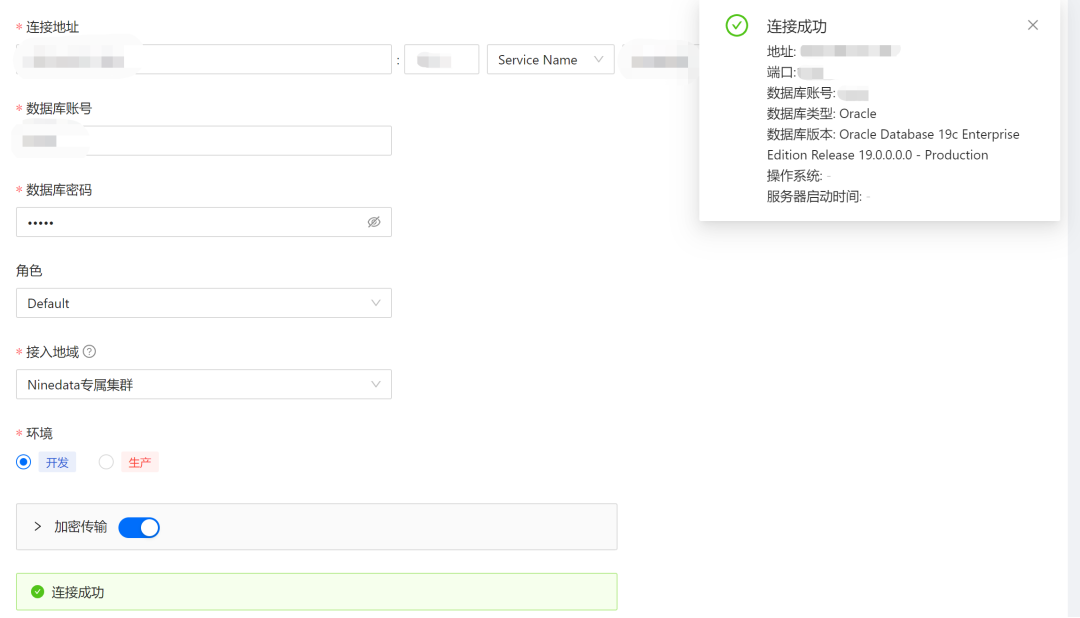
界面中会显示当前数据源的可用状态,比较直观清晰,
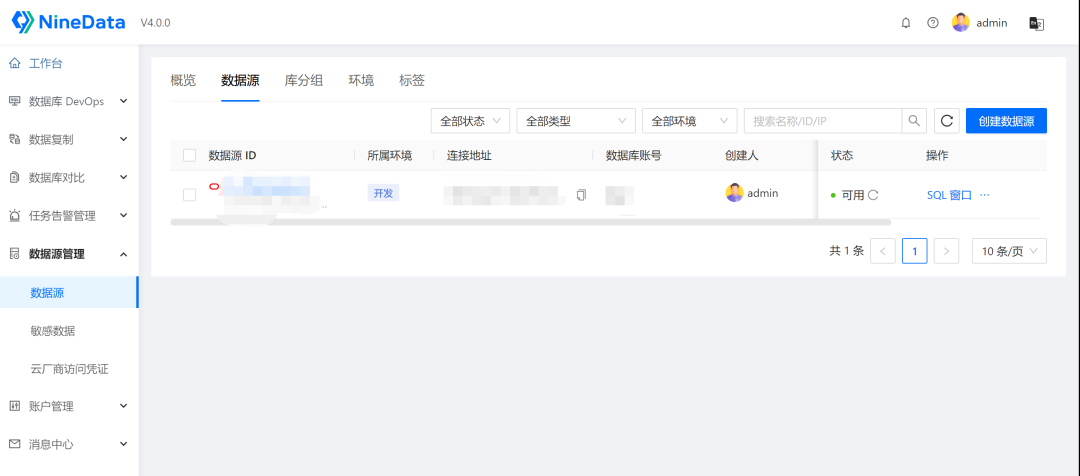
可以通过SQL窗口,远程执行SQL,相关的schema等信息,提供选择,

但是社区版不支持"数据追踪与回滚"、"数据规定与清理"和"SQL代码审核",

其实像"SQL代码审核"还是比较想尝试的,不知道后续社区版能否提供体验,
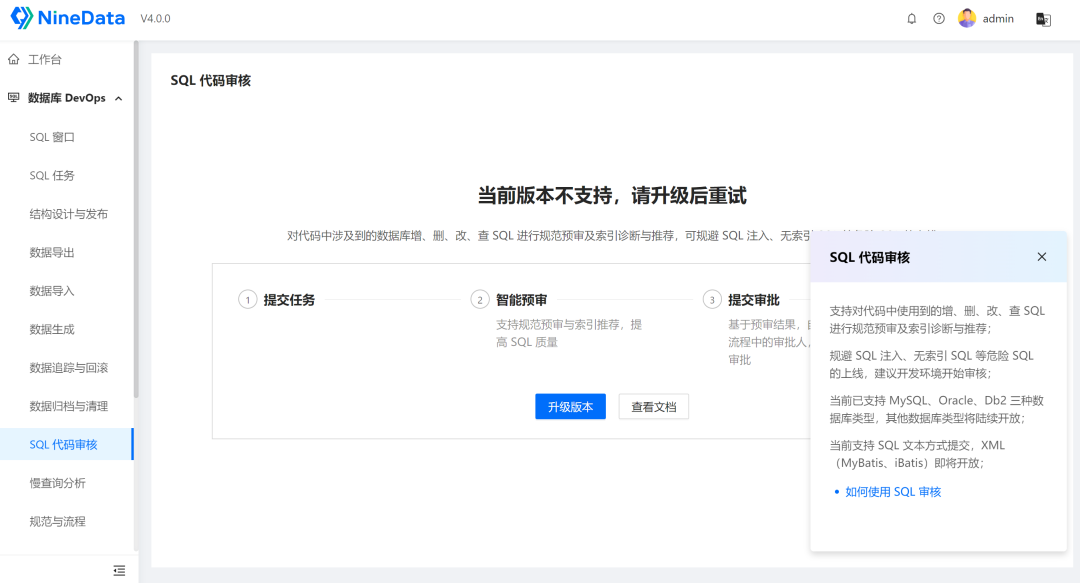
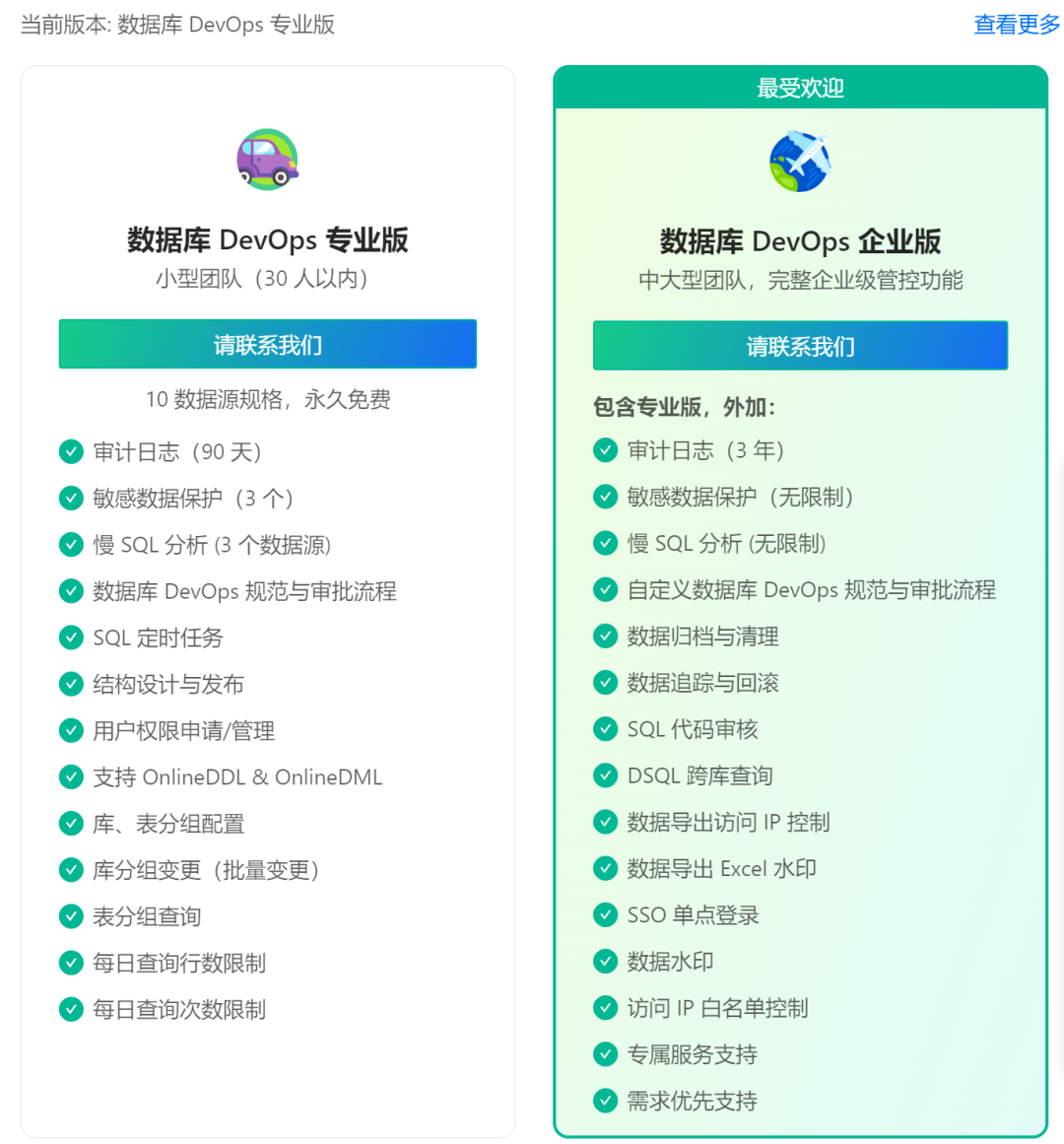
如果要使用这些功能,需要进行升级,
可用的功能中,这个"慢查询分析"功能还是比较实用的,屏蔽了通过数据字典寻找关键数据的过程,降低了数据库性能监测的门槛。手动跑了一条笛卡尔积的SQL,根据数据显示,应该展示的是执行时间超过10秒的SQL,但是我没找到这个阈值的配置,是系统默认的,还是可以自定义?
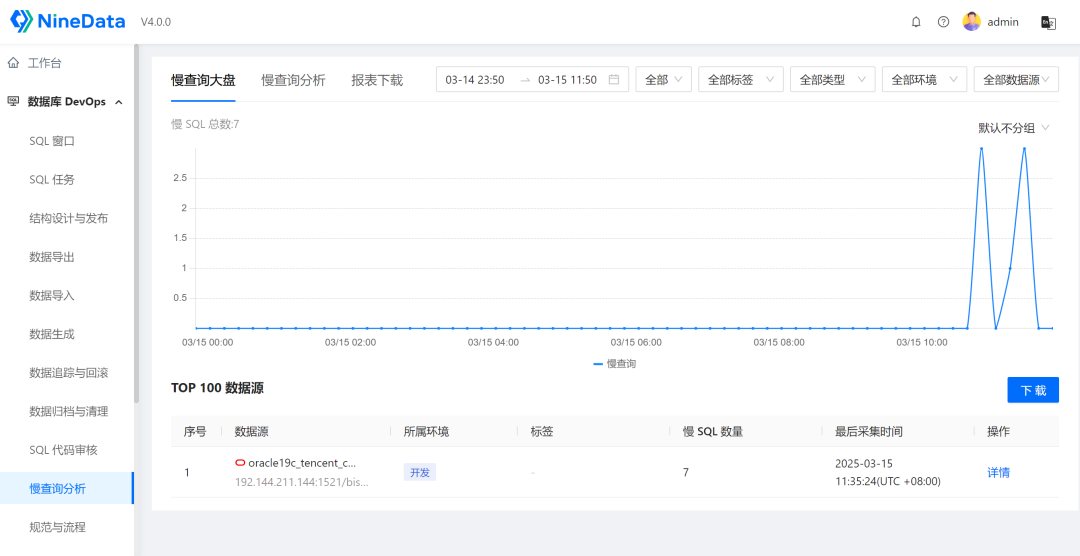
另外,除了用户执行的语句外,当前用户的一些用于系统检索的语句,以及SYS等系统用户执行的语句,都会被采集到,不知道能不能过滤这些非用户主动执行的语句,减少数据噪音,

可以点击进入具体的数据,查看相关慢查询的数据,
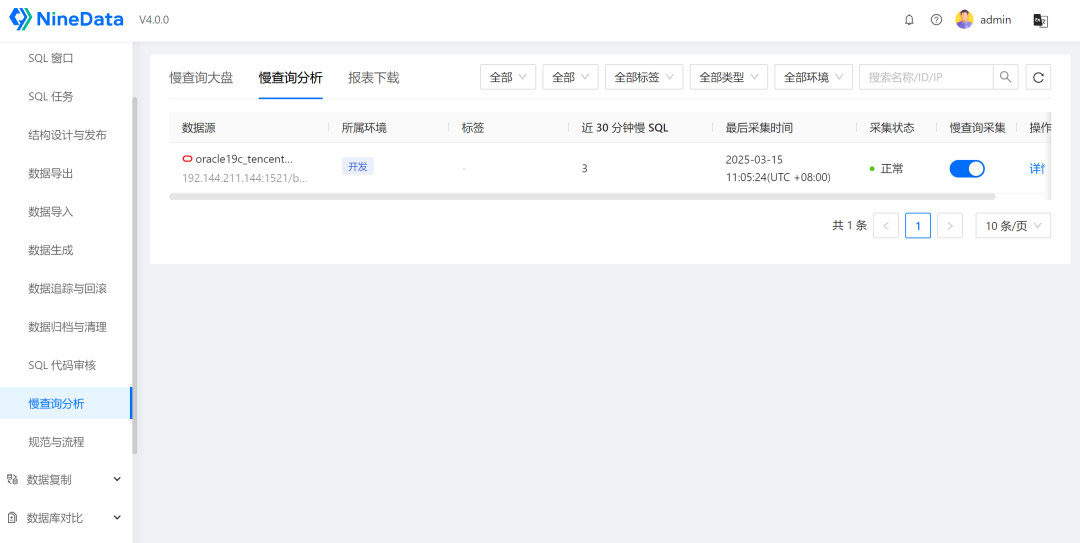
统计图很直观,
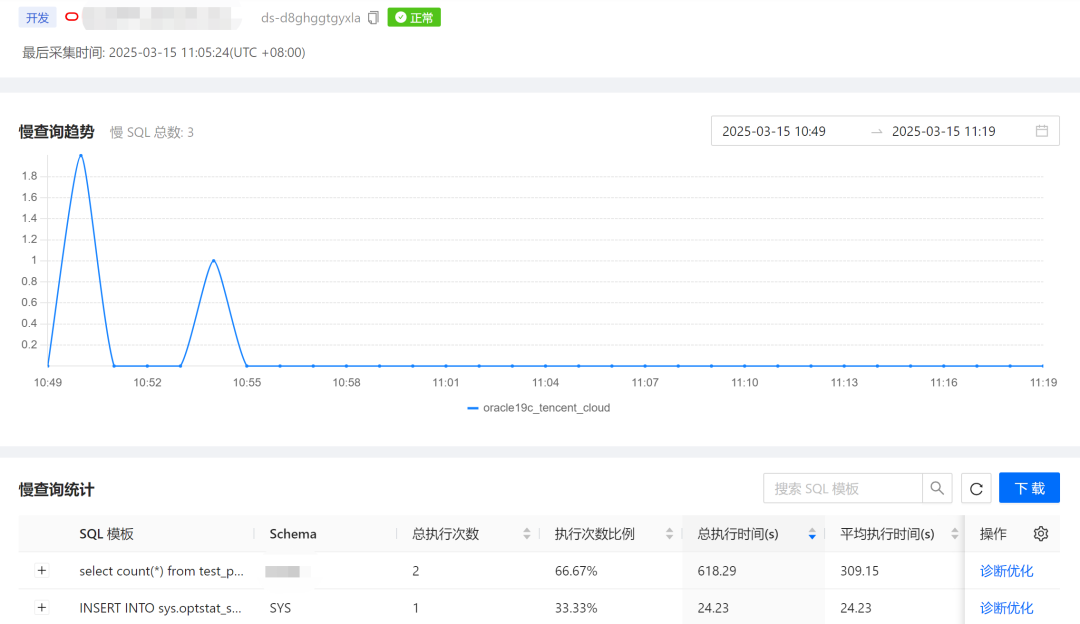
会展示出慢查询具体的SQL、平均执行时间等基本信息,应该都来自数据库的数据字典,

同时会给出一些性能诊断的建议,应该是相对静态的数据,
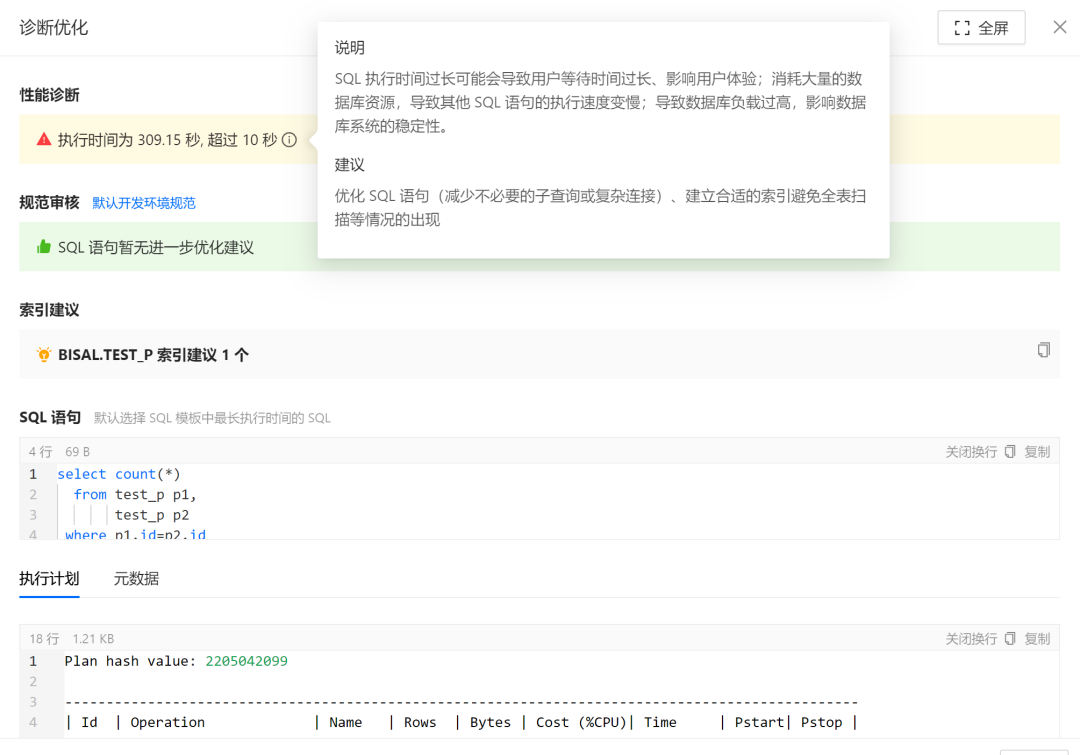
还会给出索引的建议,不是机械的,会根据表字段的统计信息,综合判断给出,这点还是很赞的,如果对数据库不太了解的,往往可能会创建很多索引,但实际上索引的创建还是有讲究的,
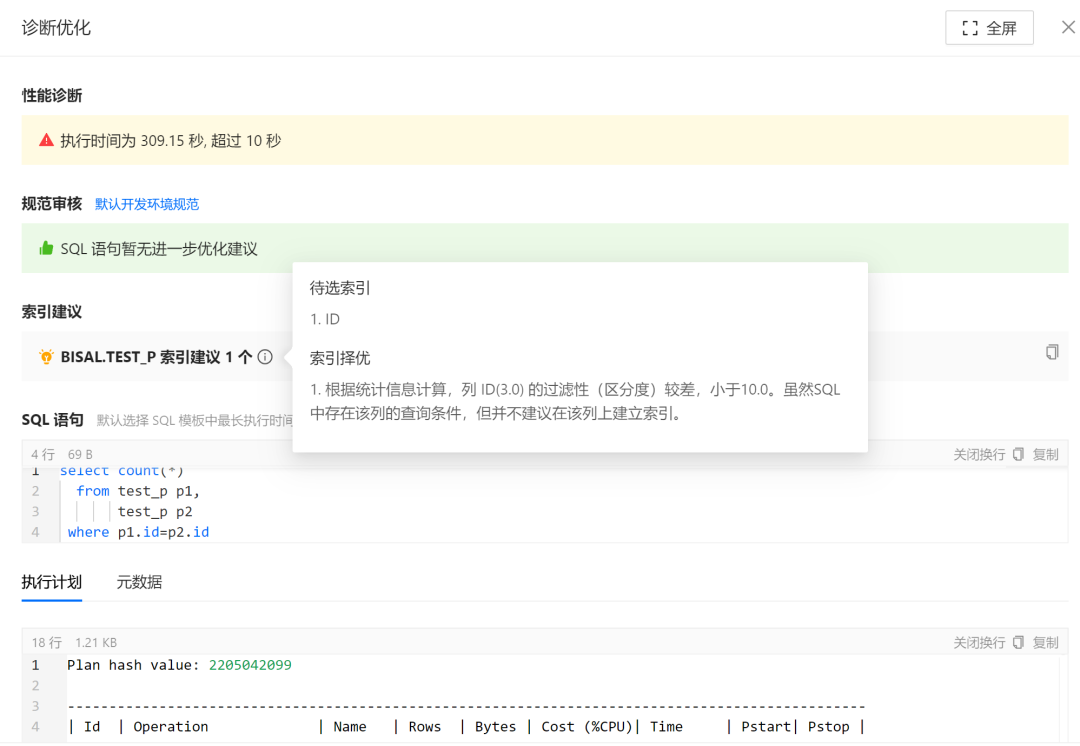
该SQL的执行计划也会给出来,格式化效果很好,
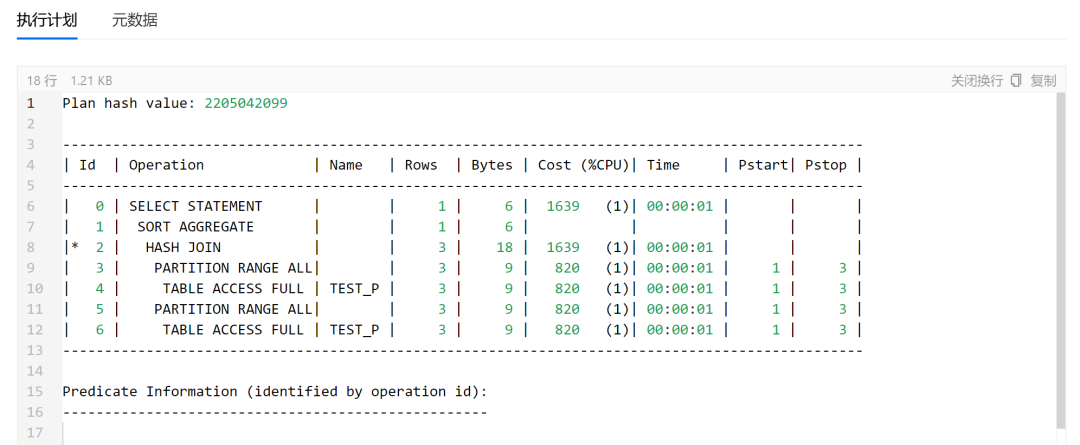
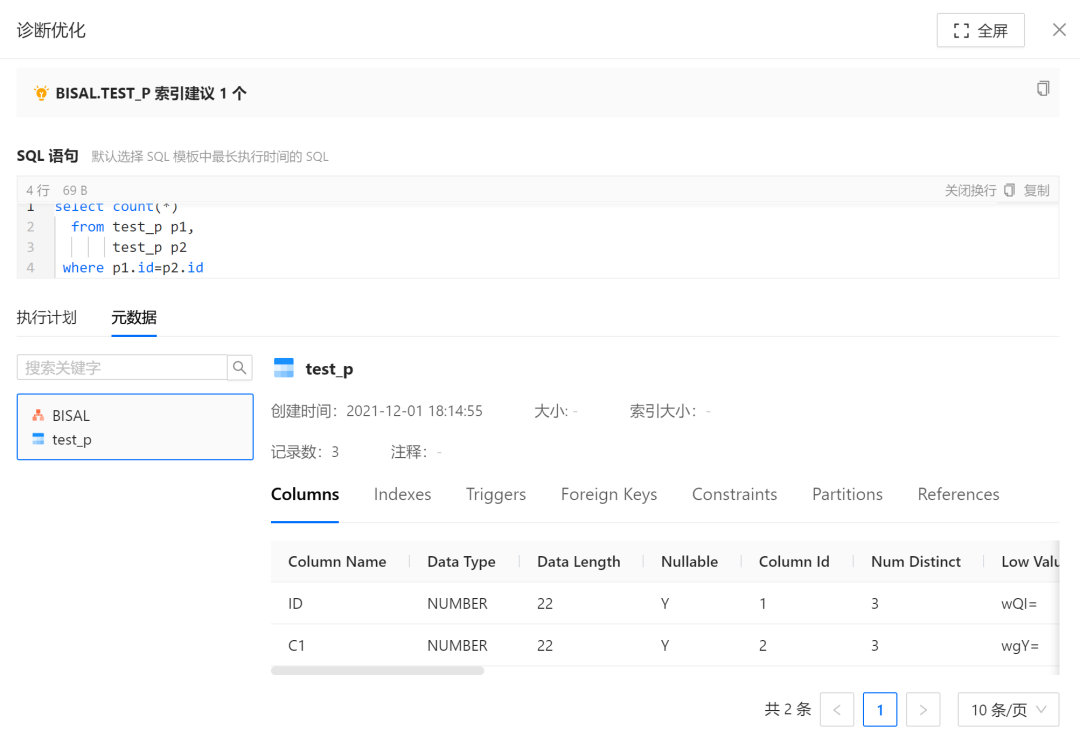
该SQL涉及到的对象信息也是可以展示,可以更加方便地结合数据字典信息,对该语句的优化进行判断,
在"规范与流程"模块中,可以自定义很多规则,

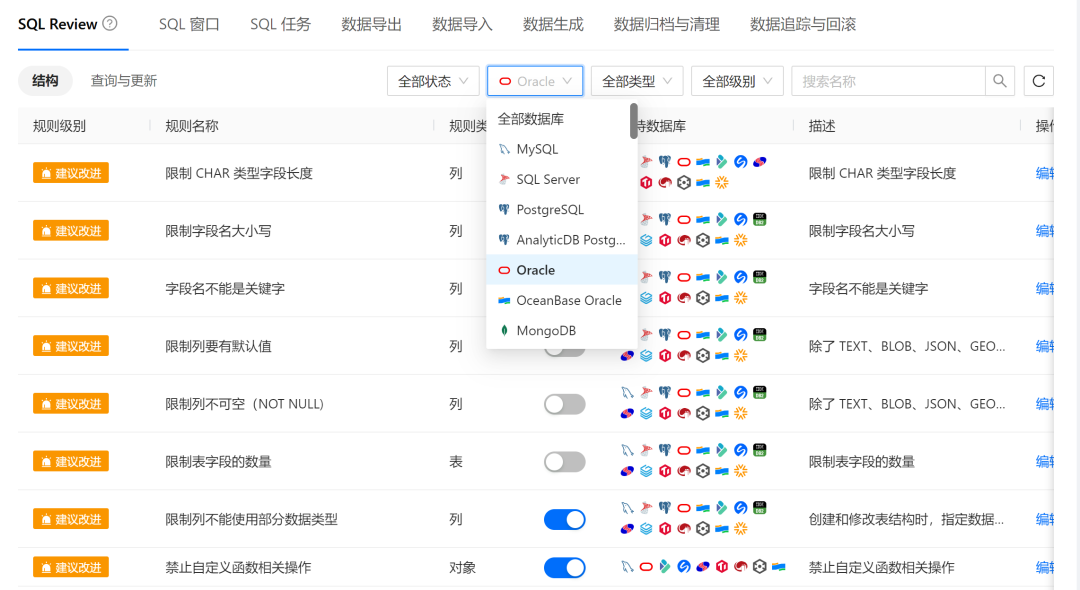
根据对象类型的,

根据建议强度的,

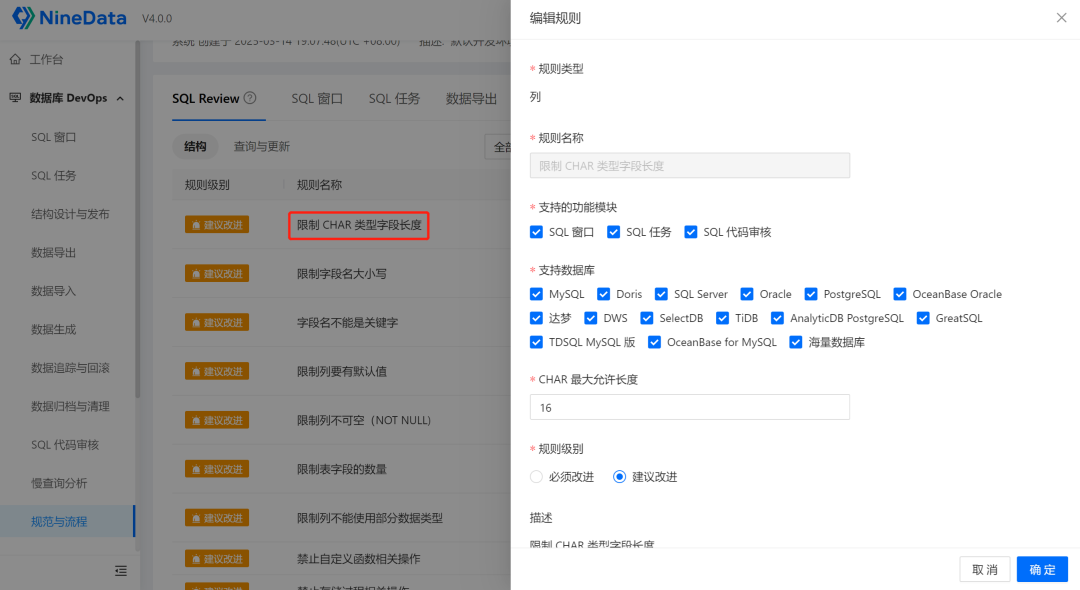
对具体的规则,可以自定义阈值,例如"限制CHAR类型字段长度",默认是16,可以改成其它,
例如"表名不能是关键字",可以提供关键字列表,自定义具体值,

SQL窗口配置,可以限制WHERE条件、拦截等功能,
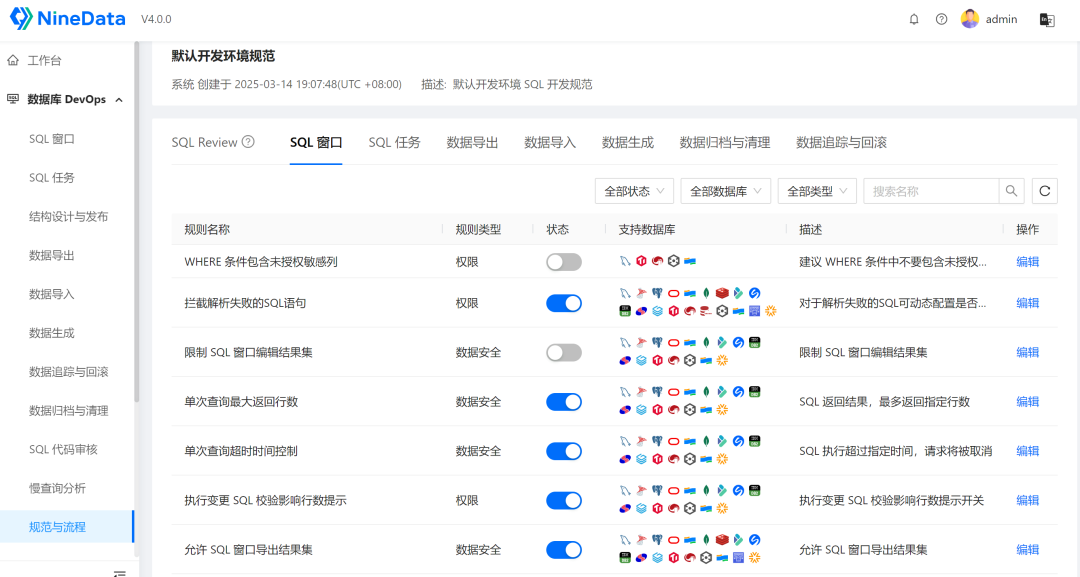
"数据导出"的配置中可以限制访问IP,更细力度的控制,

还可以配置审批的流程,确认线上执行,

相较于企业版,社区版不支持ChatDBA,可以理解,毕竟这需要算力,至少要联网,但是不知道后台能不能支持对接企业自己的大模型,

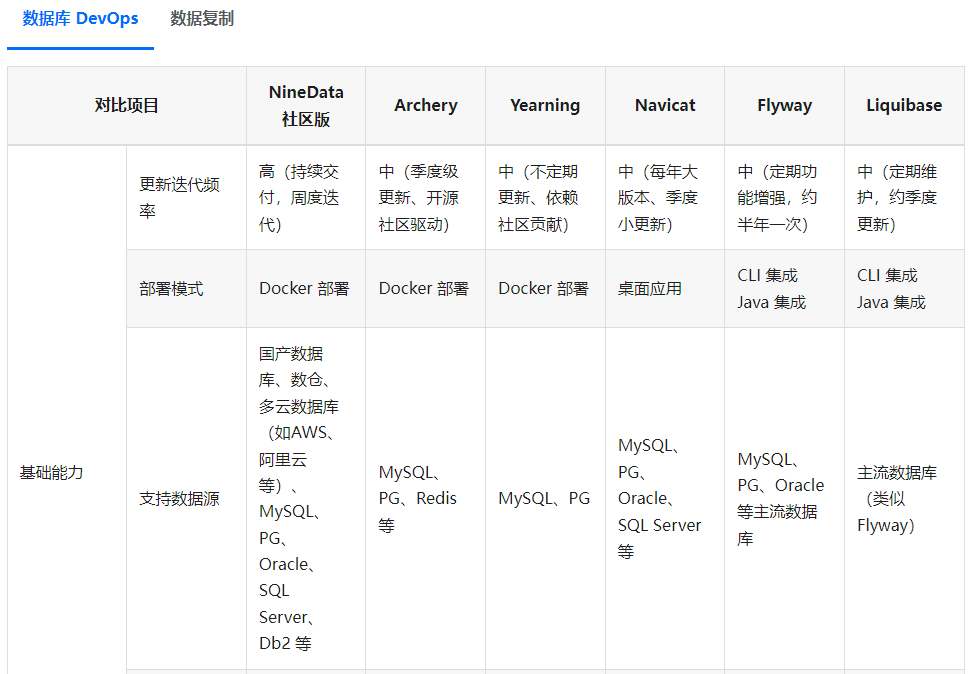
NineData社区版和主流工具全方位对比,
具体请参考,https://docs.ninedata.cloud/community_edition/

虽然社区版和企业版相比,还是阉割了很多的功能,但是可以理解,毕竟不是开源的产品,核心功能还是要进行保护和盈利,对于一般用途的数据库管理而言,社区版已经能提供很多基本的功能了,很实用,手动点赞。

热文鉴赏:
《推荐一篇Oracle RAC Cache Fusion的经典论文》
文章分类和索引:
