




写在文章开头
在当今的信息技术领域,MySQL 作为广泛应用的数据库管理系统,其重要性不言而喻。当我们执行一条 MySQL 语句时,看似简单的操作背后,实则隐藏着一个严谨而有序的执行过程。深入探究这一过程,对于理解数据库的运作原理以及优化数据库性能都具有至关重要的意义。本文将以专业且深入的视角,对一条 MySQL 执行过程展开全面而细致的解析,旨在揭示其中蕴含的关键步骤和逻辑,带领读者一同领略 MySQL 执行机制的精妙与严谨。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
详解MySQL基本架构
从宏观角度来说MySQL
架构可以分为server
层和存储引擎层,其中Server
层核心组件如下:
连接器:进行身份认证和权限相关校验。 查询缓存:查询缓存主要是用于提高查询效率而加的一层缓存,但在 MySQL8.0
已废弃。分析器:对 SQL
执行动作、语法、词法进行分析。优化器:对要被执行的 SQL
进行优化。执行器:执行 SQL
查询语句,然后从存储引擎返回结果。
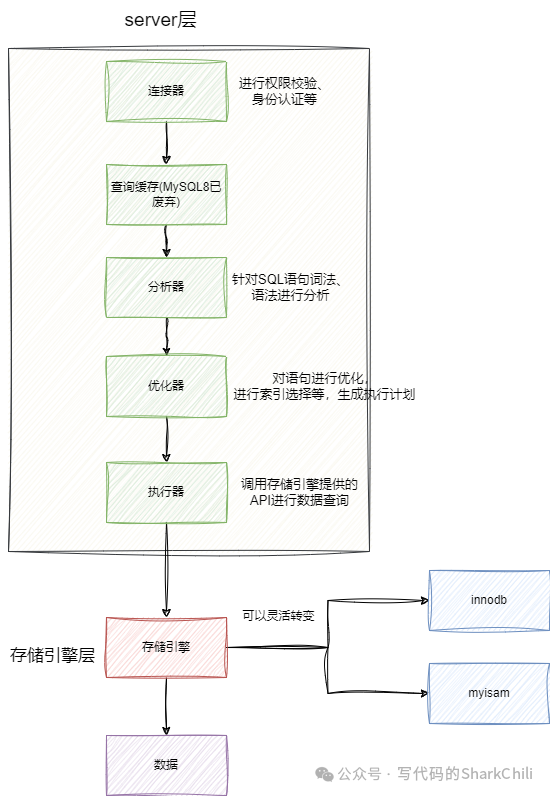
接下来说说存储引擎,对于MySQL而言存储引擎是支持插拔的,常见的存储引擎有myisam
、innodb
、memory
,而MySQL
默认的使用的是innodb
。
详解MySQL各层的组件分工内容与职责
MySQL客户端和服务端的通信协议
对于MySQL
而言,客户端和服务端之间采用的是一种半双工的通信协议,这样就意味着同一时刻要么客户端向服务端发送数据,要么服务端向客户端发送数据。所以客户端必须完整的收到服务端响应的数据才能断开连接。
这个交互流程也在告诉我们,进行大量数据查询的时候,若无必要尽可能使用limit
进行分页查询,避免这种半双工的通信方式导致客户端接收导致资源长时间的占用。

连接器
主要判断用户登录的账户密码是否正确,如果账户密码都正确,则进行权限查询,注意在本次连接期间只要不断开,无论外界如何修改权限,这个会话的权限都是以连接器查询到的为主。
查询缓存
MySQL8
已经废弃的功能,这个功能常用于结果的缓存复用以提高查询性能,例如我们进行select * from table where id=1的查询。第一次发现缓存中没有,就从数据库中查出来并放到缓存中下次可以在复用。 MySQL8之所以废弃是因为数据库中的数据经常更新导致缓存失效,就需要清空这个缓存,这期间和开销是非常没必要的,所以索性废掉这个功能。
这里笔者也补充一下MySQL8
废弃查询缓存的原因:
锁竞争:为了保存查询缓存正确性,我们必须在多线程读写操作时针对特定缓存进行锁定保证临界资源的线程安全,这势必导致高并发场景下因为缓存锁竞争而出现性能瓶颈。 缓存失效:在进行 insert
或者update
修改时,MySQL
都会将表级缓存清空,所以针对写多的场景下查询缓存命中率不高。内存负担:为缓存数据就需要一定的内存空间,如果查询和表的量级都十分庞大的话,那么就需要占用较大的内存资源。 维护成本:查询缓存的存在增加了 MySQL
的复杂性,为保存缓存一致性,针对缓存添加、删除等逻辑都需要有更加完善且复杂的举措,这势必增加开发和维护的成本,容易导致各种潜在的错误和性能问题。
分析器
分析器主要是负责SQL
解析和预处理,它会将客户端发来的查询一句进行解析生成一颗解析树,然后解析器根据自定义规则对SQL
语句进行词法和语法分析和语义分析。
词法分析:分析关键字是否拼写有误,并通过关键字判断这条 SQL
做什么。语法分析:对这条 SQL
语句的语法进行检查。语义分析:完成上述步骤后,分析器会解析出对应的表名和查询条件,将其放到MySQL服务器内部的特定数据结构上开始后续的步骤。
优化器
分析器分析无误之后,说明这条语句是可以正常执行的。MySQL
优化器就会通过分析找出成本最小的一种方式生成执行计划,交由执行器执行。
对此,我们这里不妨补充一下MySQL
能够自己处理的一些优化类型:
将外连接转为内连接:某些场景之下,我们可能会用到外连接,但是在 where
或者库表结构的调整之后,我们的左外连接后者右外连接可能不存在null
的连接。 例如下面这段sql,我们对table2
进行左外连接,但是我们条件关联之后,table1对应的id值在table2中都有,那么查询优化器可能就会对其进行优化,会将其转换为内连接,更加精确的去匹配索要查询的行避免没必要的扫描。
SELECT *
FROM table1
LEFT JOIN table2
ON table1.id = table2.id;复制
举个例子,上面的sql
如果table1
对应的id在table2
中都有,那么sql语句就会变成这样
SELECT *
FROM table1
LEFT JOIN table2
ON table1.id = table2.id
WHERE table2.id IS NOT NULL;复制
然后优化器就会将其优化成这样,直接通过inner join
进行查询,让优化器根据两个表的量级让小表驱动大表:
SELECT *
FROM table1
inner JOIN table2
ON table1.id = table2.id;复制
使用代数等价变换规则,例如我们的查询条件是
5=5 and a>5
,那么MySQL就会将其优化为:a>5
,再比如说我们有这样一条SQL,条件语句为(a<b and b=c) and a=5
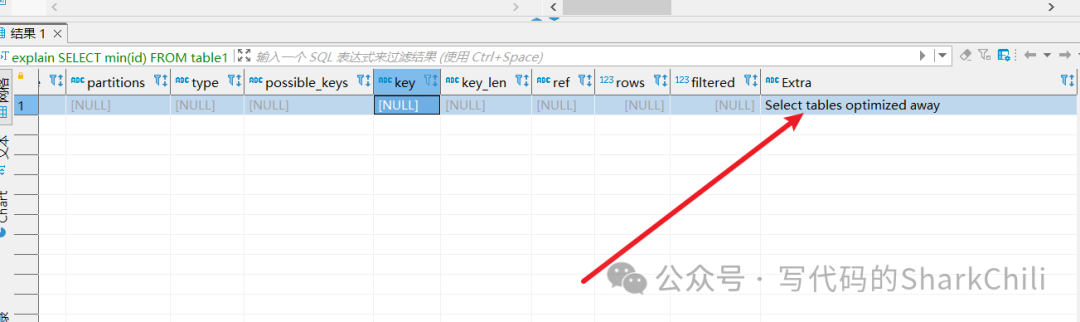
,那么MySQL就会将其优化为:b > 5 and b=c优化min、max,对于建立索引的数据表来说,使用索引所在列的进行最大值和最小值查询时,MySQL优化器会将这种sql判定为常数查询,例如笔者建立的下面这张表,我们将table1的id设置为索引。 然后查询下面这句sql:
SELECT min(id)
FROM table1;复制
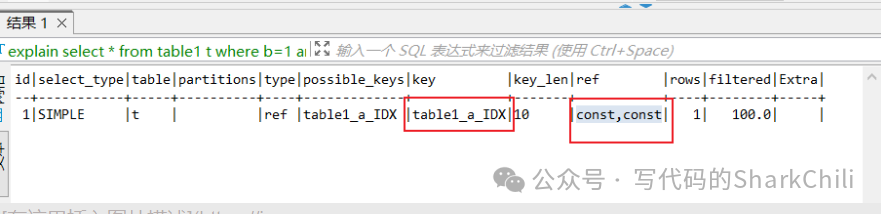
使用explain
查看其执行计划,可以看到执行计划显示Select tables optimized away
,原因很简单,这句查询仅仅是需要table1表的id最小值即通过索引就可以直接定位到数据列,本质上通过b+树
最左端即可:

这就意味查询不需要通过表的维度进行查询,而是用一个常数查询来代替。
预估并转为为常数表达式:最典型的例子就 select * from table1 where id=1+2
,MySQL优化器就会将其转为select * fromt table1 where id=3
。索引扫描:这个无需多说,当要查询的列都包含在索引中时,无需进行回表查询,避免没必要的 IO
操作。提前终止查询:对于 limit
查询而言,MySQL
优化器会在查询到需要的数据时直接终止查询,还有一些比较特殊的,例如对于某些不可能的条件,MySQL
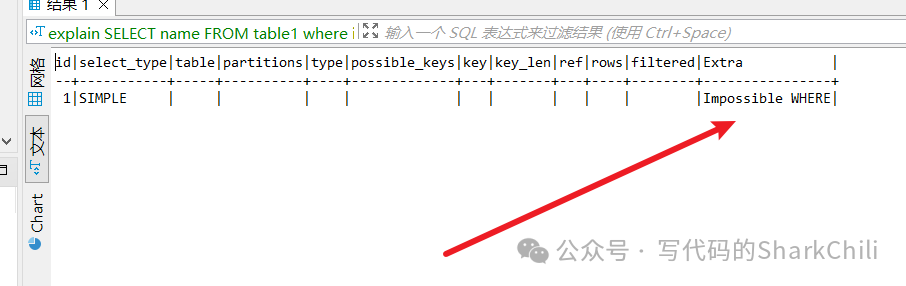
优化器也会提前将其终止,例如我们将tbale1的id设置为主键,然后键入下面这句查询语句。
selct * from table1 where id is null复制
那么执行计划就会显示Impossible WHERE
从而提前终止查询:
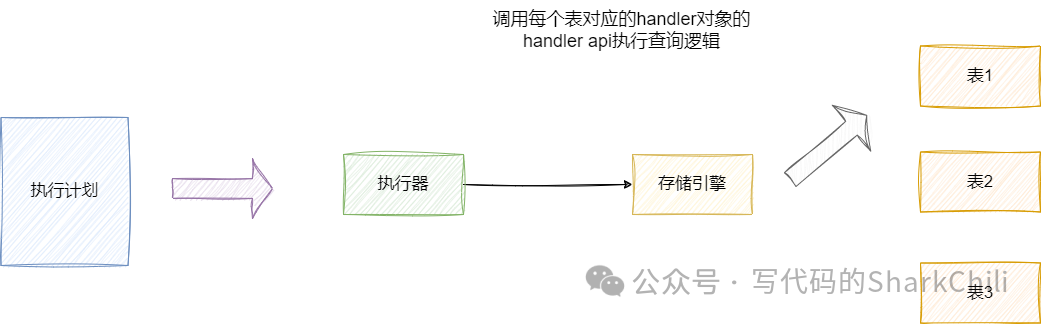
执行器
对用户进行权限校验,若权限校验不通过则报错,然后执行器就会根据优化器优化后的执行计划(这里的执行计划是一个数据结构),执行器根据这个数据结构顺序调用存储引擎提供的API
进行数据查询,并将查询结果返回给客户端,从而完成一次完整的SQL查询。
用两条完整的sql走一遍上述的流程
了解SQL执行过程之后,我们不妨通过一个实际的例子带入一下了解全过程。
查询语句的执行流程
sql如下所示:
select * from table where b=1 and a=2;复制
按照我们上文所说的过程:
校验用户账户密码是否正确,查询权限 查询缓存(mysql8.0之前),若有数据则直接返回,反之下一步 分析器进行词法、语法分析。 MySQL优化器进行优化,以本SQL为例,假如我们创建了一个 联合索引(a,b)
,那么优化器就会遵循最左匹配原则将a,b
条件进行调换。
进行权限校验,若有权限执行器进行查询,将结果从引擎取出返回。
更新语句的执行流程
更新语句我们示例SQL
如下:
update table set a=1 where b=1;复制
步骤还是一样:
连接器的工作,不多赘述 查询缓存,若有则直接操作这条数据 (mysql8不走这一步)分析器的工作,不多赘述 进行更新操作,首先调用引擎 API
,将这个修改写入内存中,同时记录redo log
,此时redo log
是prepare
状态,然后执行器执行操作,完成后提交事务成功,写入bin log
,最后redo log
更新为commit
。更新完成。
小结
通过对这条 MySQL 执行过程的详尽剖析,我们清晰地了解到从语句输入到最终结果输出所经历的各个关键阶段。我们看到了查询优化器如何智能地选择最优执行计划,索引在加速数据检索方面的关键作用,以及数据存储和读取的具体机制。这不仅让我们对 MySQL 的内部工作原理有了更深入的认知,也为我们在实际应用中更好地利用 MySQL 、优化性能提供了坚实的理论基础。然而,MySQL 的奥秘远不止于此,这仅仅是一个开始,未来我们还需不断探索和学习,以更好地驾驭这一强大的数据库工具。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
参考
SQL语句在MySQL中的执行过程:https://javaguide.cn/database/mysql/how-sql-executed-in-mysql.html
高性能MySQL(第4版):https://book.douban.com/subject/36096578/
SQL优化-MySQL Explain中出现Select tables optimized away :https://blog.csdn.net/weixin_46425661/article/details/142358763
