




写在文章开头
之前的文章我们针对ElasticSearch
文档读写等工作流程进行了深入的剖析,基于此基础我们将从硬件配置、操作系统、应用配置几个层面对ElasticSearch
性能调优进行分析,希望对你有帮助。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

详解ES硬件和操作系统层面的调优
CPU配置选型
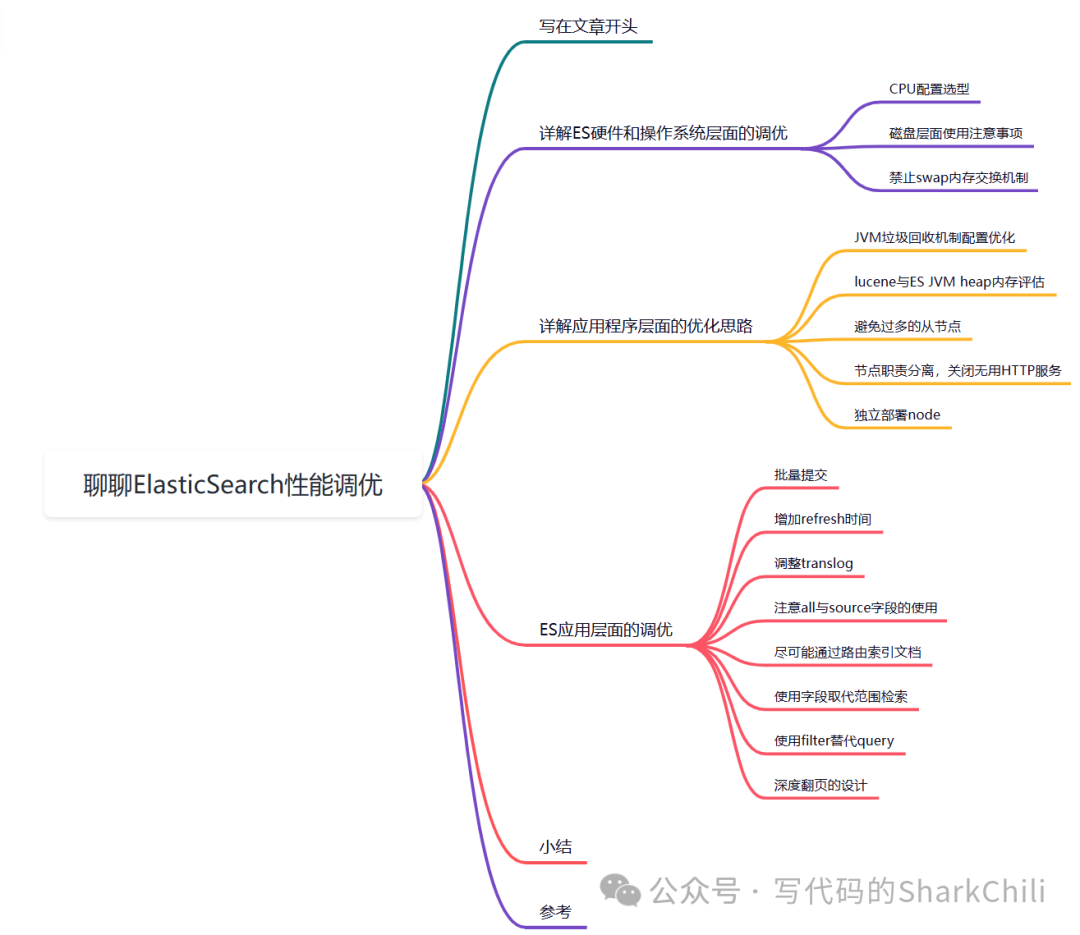
ES
对于CPU
配置没有太多的要求,因为大部分场景都属于偏IO
的操作,需要补充的是,当我们的分片集群查询会经常得涉及排序、归并、聚合、过滤等需要需要在内存中进行运算的工作时,优先考虑多的具有多个内核的现代CPU
处理器而非性能更好但是数量更少的CPU
,通过尽可能多的内核提升并发数来提升密集运算任务的性能。
磁盘层面使用注意事项
ElasticSearch
会定时将内存中的segment
、存储日志信息写入到磁盘中,所以,对于IO写入磁盘的操作如果选用性能表现差劲的磁盘,这也会间接的导致es性能下降。所以,为了保证写入时的效率,一般情况下我们建议服务器尽可能采用SSD
作为物理存储介质。
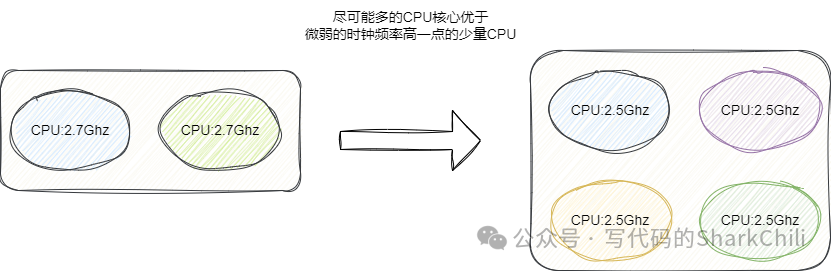
需要补充的是使用RAID 0
是提升硬盘读写速度的有效途径,对于机械硬盘和SSD
都是如此,又因为ES本身在应用层面就提供了数据副本这种备份的功能,所以使用独立磁盘冗余阵列技术时就不需要配合使用镜像或者其他RAID
变体,单单采用RAID 0
即可:
禁止swap内存交换机制
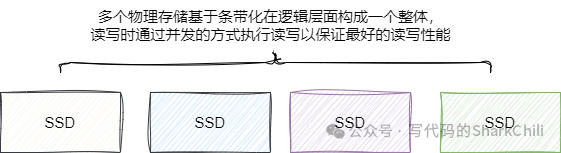
操作系统为了避免内存空间不足导致OOM
问题便提出了虚拟内存(virtual memory)
的概念,而虚拟内存我们也可以通俗的理解为将物理内存和部分磁盘空间逻辑上视为一个内存空间,而swap本质上就是在物理内存空间不够用的时候,将部分内存空间的数据交换到swap
分区(也就是物理磁盘)。
对于es来说,这种交换对于检索性能简直是一种灾难性的打击,所以我们可以通过 elasticsearch.yml
配置将bootstrap.memory_lock
设置为true
,保证JVM
对于实际物理内存的锁定,以保证ES
性能:
详解应用程序层面的优化思路
JVM垃圾回收机制配置优化
ElasticSearch
是通过Java
开发应用程序,这意味着它内存空间都统一交由JVM
处理,对于垃圾回收算法而言,ElasticSearch
官网文档推荐CMS算法,原因是最新的G1 GC算法在jdk 8u40及其之前的版本都存在一些bug
,对应配置如下:
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
实际上,如果使用jJDK8
是较高的版本,我们建议垃圾回收算法还是采用G1 GC
完成垃圾回收,这种垃圾回收算法由于其设计理念和内存空间分配的机制使其可以非常灵活的调整每次垃圾回收时间,实现每次暂停时间允许范围内进行逐步进行增量垃圾回收,从而保证系统吞吐量:
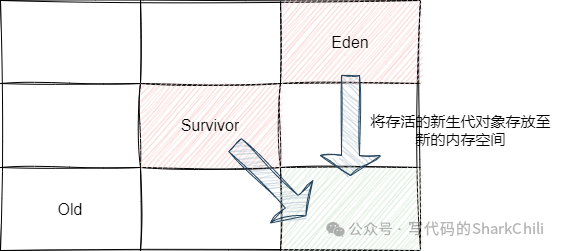
对应配置如下所示:
-XX:+UseG1GC
-XX:MaxGCPauseMillis=50
lucene与ES JVM heap内存评估
ElasticSearch
底层是由lucene
实现检索的,ElasticSearch
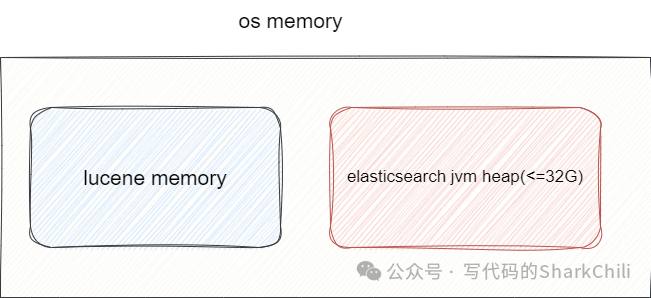
本质上是在其基础上的拓展和封装,所以我们需要两者不同工作机制进行内存预算和分配,为了保证两者能够尽可能的利用缓存提升程序运行和检索性能,我们建议lucene物理内存
和ElasticSearch堆内存空间
比例尽可能是1:1。
唯一需要调整的场景就是内存大于64g
的情况下,我们建议es
的堆内存空间要尽可能不超过32g
,避免JVM
对于普通java
对象内存压缩和指针压缩机制就会失效,进而导致内存空间消耗增加以及垃圾回收处理开销增大。
避免过多的从节点
在分布式集群环境下,es每次写入必须所有副本节点完成同步后才会返回,所以为了索引等工作的效率,我们建议集群节点数也尽量不要超过3个,甚至说像是内部ELK日志系统、分布式链路追踪等场景副本数可以直接设置为1个,通过减少从节点个数避免主从同步的时间开销,提升系统执行效率。
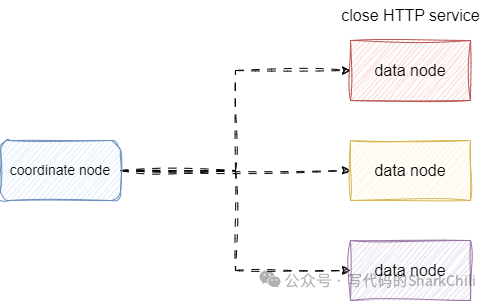
节点职责分离,关闭无用HTTP服务
ElasticSearch
集群为了避免单服务占用过多的系统资源,提供了角色的概念,一般情况下我们所有读写操作都是向coordinate node
发起的,数据节点本质上就是提供增删改查等数据操作的,所以为了尽可能减少没必要的服务器资源浪费,我们建于关闭数据节点所以对外提供的网络服务以利用尽可能多的系统资源提升程序性能之外,还能避免一些安全问题:
独立部署node
在硬件条件允许的情况下,为了避免单点异常和资源开销,我们建议每一个节点都部署在单独的服务器上以保证分布式系统稳定性以及每个检索的执行效率。
ES应用层面的调优
批量提交
本质上ElasticSearch
读写文档的开销都发生在网络传输上,所以对于大数据量提交操作,我们建议一次性通过bulk操作完成,以减少网络IO的开销同时保证批处理的效率。
增加refresh时间
es
通过定时refresh
这种延迟写入策略将新写入的文档数据的segment
写入文件系统缓冲区,只有写入文件系统缓冲区的数据才能被外部检索到,所以我们才说es
是一个近实时的搜索功能。一旦refresh
写入内存的数据达到一定体量之后就会触发flush
将这些内存缓冲区数据写入到磁盘中,这就是一件大开销的工作了,所以如果我们对于实时性要求不高,我们建议适当调整refresh
的时间,对于这个时间的调整,我们可以通过如下指令对 index.refresh_interval
根据业务场景进行增减:
PUT /{index}/_settings
{
"refresh_interval": "2s"
}
调整translog
对于还未flush
的数据,es
都会通过translog
记录以保证故障恢复的可靠性,默认情况下translog
达到512mb
时会触发刷盘将文件系统缓冲区数据冲刷到物理磁盘中,所以如果我们对于系统性能有较高要求的情况下,我们建议调整translog
的体积通过增大文件体积减少刷盘频率以提升程序执行性能:
PUT /{index}/_settings
{
"settings": {
"index.translog.retention.size": "5gb"
}
}
注意all与source字段的使用
尽可能通过路由索引文档
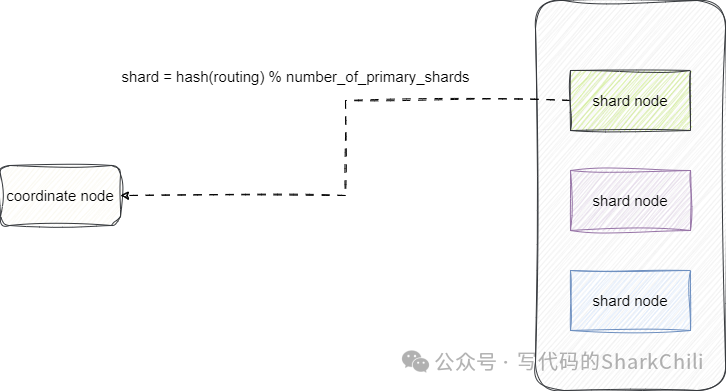
分布式场景下,es会通过如下算法完成文档的检索,需要通过的是下面的routing可以是es自生成的文档id也可以是用户自定义值:
shard = hash(routing) % number_of_primary_shards
一旦索引数据时不知道要索引的数据会落到哪个分片上,es
就会全局广播将查询请求分发到每个节点上获取符合要求文档信息完成聚合、排序等操作后再将数据返回给用户:
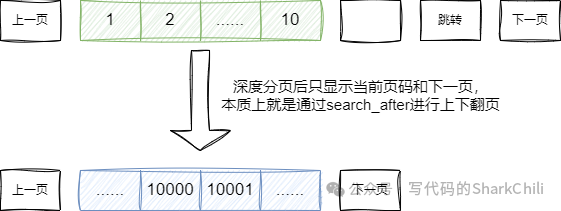
所以为了提升系统吞吐量我们建议进行索引时尽可能通过携带唯一文档id让es通过上述算法直接定位到分片以提升检索效率:
使用字段取代范围检索
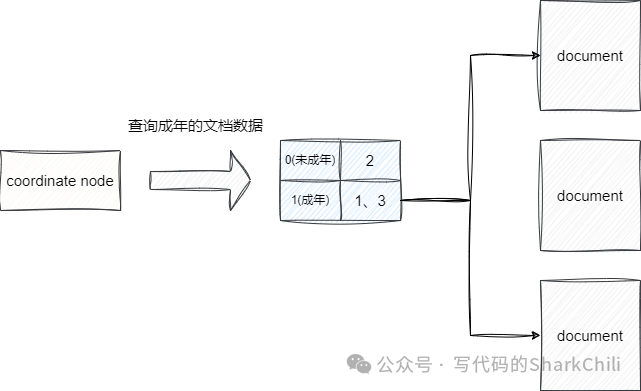
对于范围查询(range aggregations)
本质上es需要进行全扫描才能完成数据检索,这点对于运算开销是非常大的,实际上我们完全可以针对这些数值通过归类将其替换为terms aggregations
,假设1-17为未成年人,其余是成年人,我们可以通过设置一个is_adult
用0表示未成年1表示成年,从而通过词项走倒排索引完成数据检索,以避免范围查询开销快速获得数据:
使用filter替代query
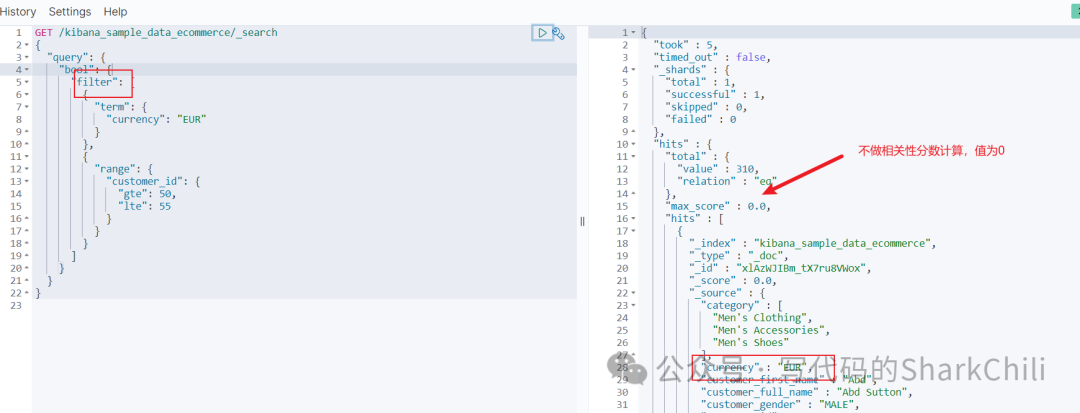
使用filter
是精准过滤符合要求项并且会将查询结果缓存到内存空间中,而query
则是会基于用户检索进行模糊匹配后给出相关性查询结果和相关性分数信息,所以无论从查询的体量和缓存机制前者性能表现都更加出色,我们更建议使用filter
完成过滤检索,具体的使用示例如下所示:
深度翻页的设计
关于深度分页问题笔者已经在往期的文章做了相应的整理和分析,感兴趣的读者可以移步这篇文章:
elasticsearch如何完成文档读取的 :https://mp.weixin.qq.com/s?__biz=MzkwODYyNTM2MQ==&mid=2247486508&idx=1&sn=cba09bfd7ee14fa7db66a48b62b7344d&chksm=c0c65892f7b1d184c9ff784b2d110309423ac1f7dd43ec2fc6749b8503843e4a7d6dadd6085c#rd
小结
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。 因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
参考
ES详解 - 优化:ElasticSearch性能优化详解:https://www.pdai.tech/md/db/nosql-es/elasticsearch-y-peformance.html
RAID0、1、5、6、10、50、60超详细说明,简单易懂!:https://cloud.tencent.com/developer/article/2230770
时钟频率是什么意思?:https://blog.csdn.net/Reborn_Lee/article/details/82913282
在Linux下禁用、添加|修改Swap分区(虚拟内存)教程:https://blog.csdn.net/inthat/article/details/107211445#:~:text=SWAP分区是Lin
linux swap 内存交换分区 详细介绍:https://blog.csdn.net/whatday/article/details/108942838#:~:text=Swap的工作原理是
这可能是最清晰易懂的 G1 GC 资料:https://segmentfault.com/a/1190000039411521
