




写在文章开头
近期碰到很多读者提及面试会问到JVM调优相关的场景和实践,但是大部分企业都没有如此量级的需求,导致大部分求职者没有比较合适的调优案例应付面试,所以笔者结合个人经验,整理了一个入门级的JVM调优实践供读者参考。

Hi,我是sharkChili,是个不断在硬核技术上作死的java coder,是CSDN的博客专家,也是开源项目Java Guide的维护者之一,熟悉Java也会一点Go,偶尔也会在C源码边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号:写代码的SharkChili,获取笔者的联系方式备注 "加群" 和笔者的交流群进行深入交流。
需求说明
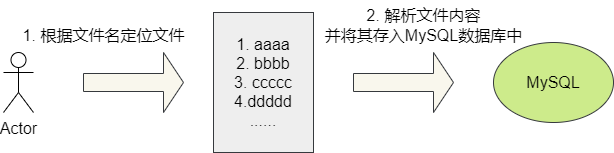
该需求是一个文件上传并导入到数据库的功能,用户首先会通过upload
接口将文件提交到文件服务器上,完成所有文件上传之后,用户会通过impData
接口传入上一个接口所提交的文件名,impData
接口会根据接口传入的文件名将数据导入的数据库中。
问题复现
首先我们模拟出要上传的文件,每个文件有大约200w条数据,每条数据差不多100个字节,对应的生成代码如下所示:
public class Main {
public static void main(String[] args) {
for (int i = 0; i < 200_0000; i++) {
FileUtil.appendUtf8String(RandomUtil.randomString(100)+"\r\n","F:\\tmp\\data.txt");
}
}
}复制
对应的文件内容样例数据如下,共200w
条:
5l7zu18hyccx4ewgoki02s1x07bqj0xsmsthldeqpi7q1rvbdl9bt0r34pmphbagfhodal4x38x5lv0z91go18ylur3sfa3na5ln
sa5ntpck3ysgsnrxabhnql2lh7o8xro6vuccq2nvjgzsnxkv1q2s901iny5rxfsmgpz9jycvzbcta8ddpg4x5ro6jmdj48ahhfni
y6c3ujiz20s7qsnou9cb1gm1ez3m3we8hdmobc4v6pm4ahld9cxetza6h2qu1c3u5h4vztzobokd1vn0963nacj9182eavt4uldc
116f90o9kc92stzyw2t2l3pn29eqencki31qfoh7pa9wwblvwitji9pizfzjvlu007smlba0sj3uad6d84a7ycqaco4sf56dl42x
4rpwzh8kgwvrenrlqvtyti0c9qfzpvlinyhbbinfas3sam225d1n3xafoybwg3luqcjzynhbkb72mzn3pi1dpcth7rhcjfaleuii
cscgvwni959vbpmhwtzkemtdfprb2cm0bfdc1e5qwle11ryuqjjgs7klvsi2empa82srupj62f96hdjhudkcc6i6ifat1u67plu3
.......复制
再来看看入口代码,用户在页面中提交文件后点击上传即可触发下面这个接口,该接口会根据文件名定位到文件服务器的文件,将数据解析并存入数据库:
@PostMapping("/impData")
public boolean impData(String fileName) {
//解析文件内容,内容包含数据
long begin = System.currentTimeMillis();
List<String> dataList = FileUtil.readUtf8Lines(DIR + fileName);
long end = System.currentTimeMillis();
log.info("文件读取耗时{}ms", end - begin);
//解析成内存集合
begin = System.currentTimeMillis();
List<TData> tDataList = dataList.stream()
.map(d -> {
TData tData = new TData();
tData.setData(d);
tData.setType(RandomUtil.randomBytes(1)[0]);
return tData;
})
.collect(Collectors.toList());
end = System.currentTimeMillis();
log.info("数据解析耗时{}ms", end - begin);
//提交到异步插入接口
tDataService.saveData(tDataList);
return true;
}复制
上一步在文件解析完成后会将数据通过批处理的方式存入数据库,对应的示例代码如下所示:
@Autowired
private SqlSessionFactory sqlSessionFactory;
public void saveData(List<TData> tDataList) {
try (SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH)) {
TDataMapper mapper = sqlSession.getMapper(TDataMapper.class);
for (int i = 0; i < tDataList.size(); i++) {
mapper.insert(tDataList.get(i));
}
long begin = System.currentTimeMillis();
sqlSession.commit();
long end = System.currentTimeMillis();
log.info("批出理插入结束,耗时:{}ms", end - begin);
} catch (Exception e) {
log.error("数据批量插入失败,失败原因:{}", e.getMessage(), e);
}
}复制
为了更加贴合实际业务场景,笔者将当前应用的堆内存设置为512m,并设置了发生OOM时导出内存快照的路径:
-Xms512m -Xmx512m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=F:\tmp\heapdump.hprof复制
我们启动服务调用上述接口,不久后控制台就输出OOM的错误:
2024-03-05 23:38:09.080 INFO 17272 --- [io-18080-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'
2024-03-05 23:38:09.080 INFO 17272 --- [io-18080-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 0 ms
java.lang.OutOfMemoryError: GC overhead limit exceeded
Dumping heap to F:\tmp\heapdump.hprof ...
Heap dump file created [461299630 bytes in 1.097 secs]
2024-03-05 23:38:38.819 ERROR 17272 --- [io-18080-exec-1] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Handler dispatch failed; nested exception is java.lang.OutOfMemoryError: GC overhead limit exceeded] with root cause
java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.Arrays.copyOfRange(Arrays.java:3664) ~[na:1.8.0_251]复制
我们通过mat打开导出的内存快照,可以看到大量的char出现我们的面前:
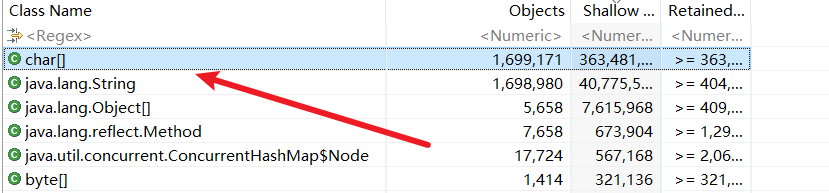
点击with incoming references
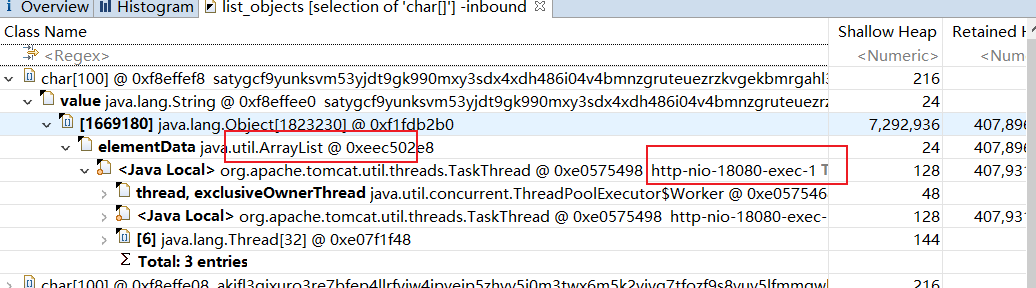
查看这个数组被谁引用了。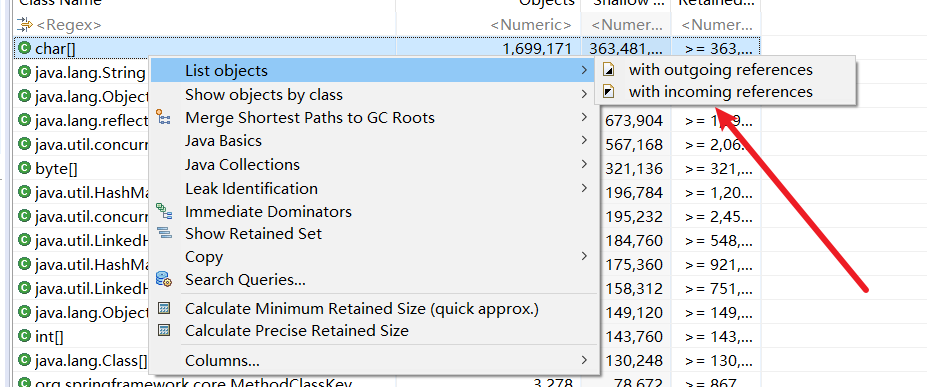
可以看到这个对象被一个tomcat线程请求下的一个List持有,很明显问题就出在我们导入接口:
解决方案
自此我们大概知道因为大数据文件导入内存导致堆内存被打满,对于这类问题,我们首先要考虑单位时间内的内存使用率不会超过设置的堆内存大小,对于上述代码,我们对文件采用逐行批次读取一次然后解析插入的方式。
改良后的代码如下所示,可以看到笔者采用BufferedReader
进行逐行读取,每1w行进行一次插入,这样就可以保证单位时间内仅处理1w条的数据的插入,而这些数据插入之后就可以被GC,确保单位时间内不会由大量数据占用宝贵的堆空间。
@PostMapping("/impData")
public boolean impData(String fileName) {
//解析文件内容,内容包含数据
long begin = System.currentTimeMillis();
String str;
List<TData> tDataList = new ArrayList<>();
try (BufferedReader utf8Reader = FileUtil.getUtf8Reader(DIR + fileName)) {
while (StrUtil.isNotEmpty(str = utf8Reader.readLine())) {
TData tData = new TData();
tData.setData(str);
tData.setType(RandomUtil.randomBytes(1)[0]);
tDataList.add(tData);
//每读取1w条进行一次插入
if (tDataList.size() % 10000 == 0) {
tDataService.saveData(tDataList);
tDataList.clear();
}
}
//将剩余数据插入
if (CollUtil.isNotEmpty(tDataList)) {
tDataService.saveData(tDataList);
}
} catch (Exception e) {
log.info("数据导入失败,失败原因:{}", e.getMessage(), e);
}
long end = System.currentTimeMillis();
log.info("插入完成,总耗时:{}ms", end - begin);
return true;
}复制
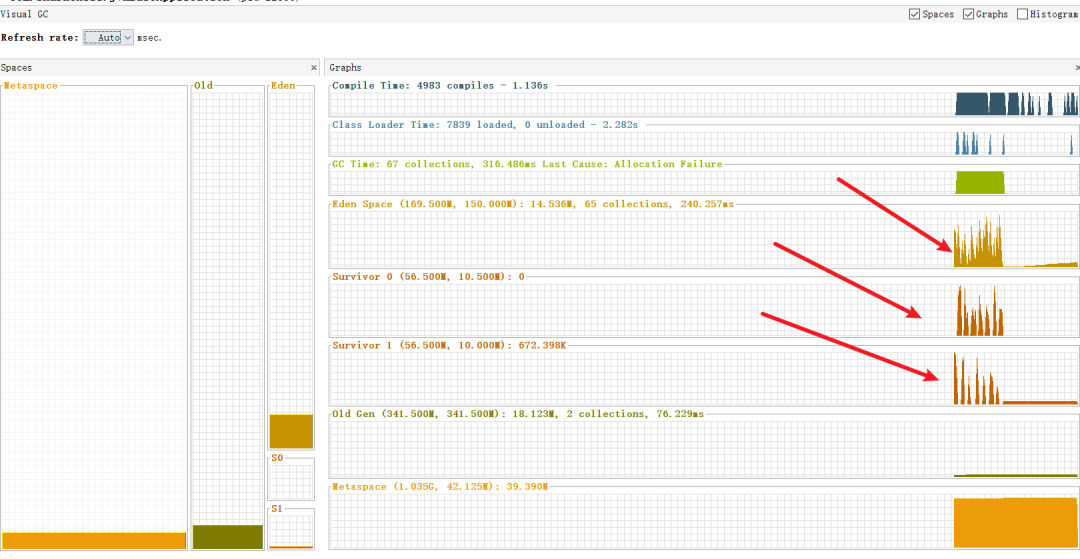
启动在此测试,此时我们使用jvisualvm查看进程的GC情况,可以看到堆内存非常平稳的升降,并没有占用大量堆空间,

查看gc也可以看出,因为数据基本都是逐小批次的处理,基本上垃圾都在新生代被及时回收,系统的性能也不会因为这个接口而下降。
小结
简单小结一下笔者本次案例的排查和优化过程:
模拟线上环境,做好内存快照指令。 基于日志定位问题接口。 走查接口问题,定位业务功能和处理过程。 针对大内存使用接口的数据进行分批次处理,确保小批量执行,小批量GC。
我是sharkchili,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号:写代码的SharkChili,取笔者的联系方式备注 "加群" 和笔者的交流群进行深入交流。
参考
Java命令:jstat — 查看JVM的GC信息 :https://blog.csdn.net/wangzhongshun/article/details/112545871
cpu性能查看:https://blog.csdn.net/qq_35260875/article/details/107231885
JVM常见面试题 :https://blog.csdn.net/shark_chili3007/article/details/107599680
