




Redis 集群主备切换原因分析
当我们在使用 Redis 集群时,有时会遇到主备节点频繁切换的情况。这种现象并不罕见,但了解其原因和解决方案是每个开发者必须掌握的技能。接下来,我将通过一系列步骤,带领你理解这个问题。
事情的流程
为了更清晰地展示整个过程,我们将其分为以下几个主要步骤:
| 步骤 | 描述 |
|---|---|
| 1 | 确认 Redis 环境是否正常 |
| 2 | 查看 Redis 日志 |
| 3 | 检查网络连接 |
| 4 | 监控主节点状态 |
| 5 | 劳损检测 |
每一步的具体操作
第一步:确认 Redis 环境是否正常
首先,我们需要确保我们的 Redis 实例正在运行。可以通过以下命令确认状态:
redis-cli ping
# 返回 PONG,表示 Redis 服务正常
这条命令会检查 Redis 是否正在运行,并返回 PONG 表示正常。
第二步:查看 Redis 日志
Redis 会记录大量日志,可以通过查看日志来找出主备切换的原因。日志一般位于 /var/log/redis/redis-server.log,可以使用以下命令查看:
cat /var/log/redis/redis-server.log | grep -i "error"
# 查看所有错误信息这个命令将输出所有包含 “error” 的日志条目,如果发现错误信息,可以进一步定位问题。
第三步:检查网络连接
网络不稳定是导致主备切换的常见原因之一。可以使用以下命令检查网络连接:
ping <主节点IP>
# ping指令用于检查是否可以连接到主节点确保你可以稳定地 ping 到主节点,任何网络问题都可能导致主节点和备节点失去联系,从而引发切换。
第四步:监控主节点状态
Redis 集群中,主节点的状态决定了数据的一致性。可以通过以下命令检查主节点的信息:
redis-cli info replication这会输出有关主备节点状态的信息,比如主节点的同步状态。如果 role 显示为 slave,且 master_link_status 显示为 down,说明主节点失去了连接。
第五步:劳损检测
可以通过监控 Redis 实例的 CPU、内存等资源来检测是否存在劳损可能。一般情况下,通过监控工具(如 Prometheus、Grafana)来完成。
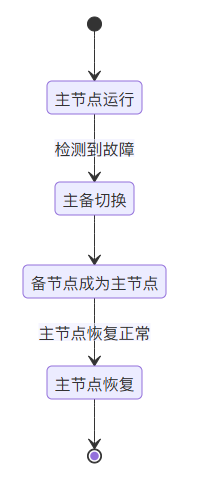
状态图
下面是主备切换的状态图,能帮助我们更好地理解整个过程:
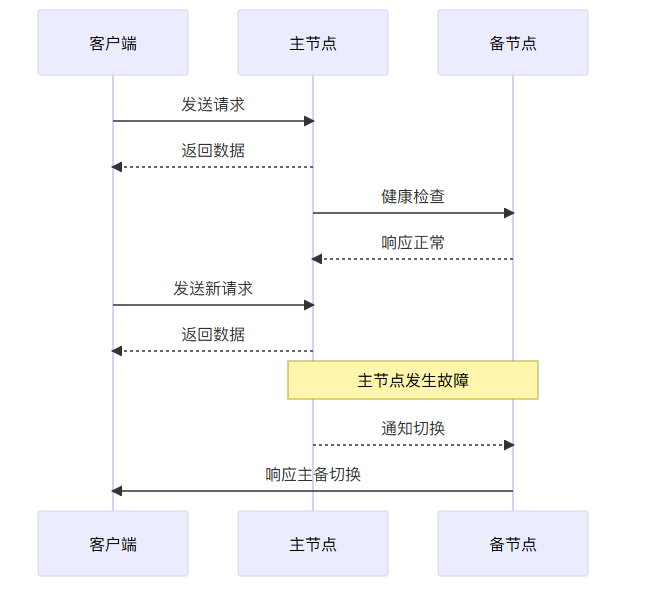
序列图
为更直观地展示主备切换的过程,以下是序列图:
结尾
通过上述步骤,你可以对 Redis 集群中的主备切换有更深入的理解。不同的原因可以导致切换,并且每一个步骤都是排查问题的关键。希望通过本文的介绍,你能够更好地监控和管理 Redis 集群,减少主备切换带来的影响。实践中,你还可以使用监控工具来实时监控 Redis 的状态,以便及时做出处理。祝你在 Redis 的学习与工作中越做越好!
