




数据库管理305期 2025-03-26
数据库管理-第305期 融合数据库需要融合些什么(20250326)
作者:胖头鱼的鱼缸(尹海文) Oracle ACE Pro: Database PostgreSQL ACE Partner 10年数据库行业经验 拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证 墨天轮MVP,ITPUB认证专家 圈内拥有“总监”称号,非著名社恐(社交恐怖分子) 公众号:胖头鱼的鱼缸 CSDN:胖头鱼的鱼缸(尹海文) 墨天轮:胖头鱼的鱼缸 ITPUB:yhw1809。 除授权转载并标明出处外,均为“非法”抄袭复制

2019年的OOW上,Oracle重点推出了融合数据库的概念(Converged database),23ai已基本完成实现并成功落地。那么数据库究竟需要融合些什么?
上周六(3月22日),在上海,有幸受邀参加了由金仓数据库与金仓社区组织的『KING大咖面对面』现场活动,在会上我的演讲主题是《什么是真正的融合数据库》,对融合数据库做出了自己的见解。

本期内容是对本次主题分享的总结,也会包含以前很多文章的汇总,因此可能会出现似曾相识的感觉。
1 数据大发展
1.1 数据类型大爆发
对比DB-Engines Ranking和墨天轮中国数据库流行度排行,我们可以看到现在有非常多的按照数据类型的分类:

在每一种分类下其实都有很多的专用数据库,这里对常见数据库做一个简单的典型总结:
- RDBMS关系型数据库:
Oracle, MySQL, PostgreSQL, DB2, SQLServer…
OceanBase, PolarDB, KingBase, DM, TiDB, GBase, HaloDB… - Document Stores文档型数据库:
MongoDB…
SequoiaDB… - Key-Value Stores键值数据库:
Redis… - Wide Column Stores列存数据库:
ClickHouse, Doris… - Vector DBMS向量数据库:
PGVector, Milvus… - Search Engines搜索引擎:
ElasticSearch, Solr…
EasySearch… - Graph DBMS图数据库:
Neo4J…
TuGraph, NebulaGraph… - Spatial DBMS空间数据库:
PostGIS…
1.2 场景更复合
在传统的数据架构中,每一种数据需要一种数据类型需要使用各自的专用数据库,比如:MySQL存储标量数据、Redis作为缓存或消息队列、Milvus支撑AI向量数据存放与检索、MongoDB存放APP的JSON数据、ElasticSearch支撑订单等业务的快速检索…在这种环境中一方面我们需要将部分数据在不同数据库之间进行同步,另一方面一般是通过应用代码来实现多种数据库数据的关联使用,IT架构灵活但也相对复杂,对IT开发和维护能力要求较高。
随着数据量越来越大,带来了几个问题,首先是不同数据库之间数据同步与校验的问题,还有数据存储的成本的问题;另一方面不同类型数据的使用关联性越来越高,原来作为周边支撑系统的业务也从非实时要求变成多模数据的快速数据分析需求,有非常高的时效性、准确性要求,这也导致了在传统依托多种专用数据库的架构下,需要付出更多的IT投入来应对不断提升的业务要求。
2 数据与场景融合
2.1 数据融合
在墨天轮排行中有多模的专属分项,只不过里面内容我认为不大合理,而DB-Engines则是在数据库的具体描述中体现:
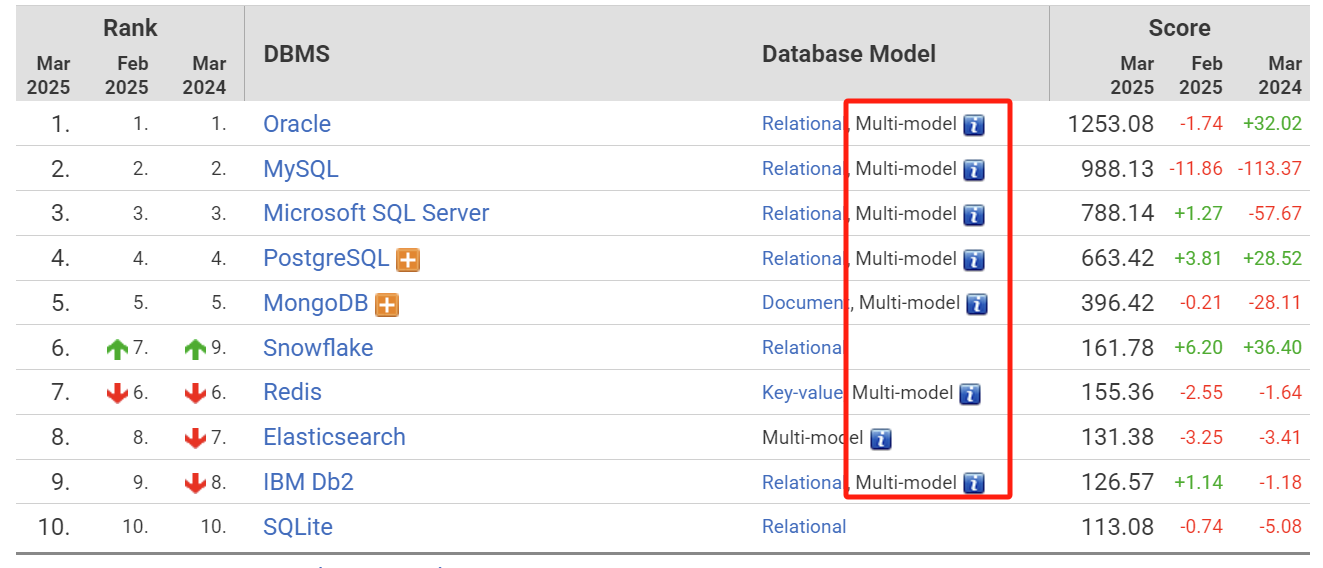
其实数据融合简单来说,就是在一个数据库中可以存储多种类型的数据,比如JSON、向量、空间等类型数据可以直接以对应数据类型的方式存储在关系表的列之中,通过特殊索引实现快速检索,通过架构变更支撑缓存加速等等,在这一点Oracle作为融合数据库先行者,给到我们很多启发,以各种传统或创新的方式实现了多模数据在一个数据库中的存储。
2.2 场景融合
其实数据融合的需求是来自于场景融合,除了前面说到的基于多模数据的查询分析的时效性、准确性要求以外,其他的业务场景也对多模数据联合查询带来了挑战,借用在各大国产数据库发布会中演示的比较多的场景“在成都春熙路2KM内评分8.5以上的好吃正宗四川火锅”,首先如果是自然语言转换成查询的话,前置AI相关的操作我们这里不考虑,在这里我只对数据查询需求拆解一下:
- “春熙路2KM以内”:这里就是空间数据
- “评分8.5以上”:是标量数据
- “好吃正宗四川 | 火锅”:这里其实是向量数据+标量数据
按照传统的方式就需要到GIS数据库查出范围,根据范围查出的结果在关系型数据库查到对应分数的美食,如果做好拆分就还能根据分类先把火锅摘出来,最后再进行向量匹配得出最终结果。当然在我看来,GIS往后的查询顺序是可以根据实际情况进行调整的。但是最终需要应用在不同的数据库中查询对应的结果,再进行关联。
如果是在多模数据库且支持多模关联查询的数据库中会变成怎样?那么在一条语句中就能够实现,大致如下:
select * from meishi
where
location ...
and rank > 8.5
and type in ()
and to_vector('xxx') distance ...
...;
复制如果向量数据和标量数据甚至加上全文检索可以创建关联索引,可以进一步提升性能和数据操作方式,在数据检索的步骤上也许能做到缩减。这里演示了多模联合查询的优势,一条语句解决以前可能是较多代码区各个数据库查询的操作,这即能降低开发难度也能打破数据孤岛提升数据质量和价值。
3 难做
前面说到了数据融合和场景融合,但是融合数据库很难做,不同类型的数据对存储的需求不一致,需要对数据库从内核至功能层进行大规模改造和适配;不同的数据类型在其传统对应的专用数据库的使用方式不同,融合数据库势必会改变开发人员你的开发习惯;最多人对融合数据库的疑虑则是性能,既要达到在各个数据类型上的性能不弱于(或者说差距不大)对应的专用数据库,也要达到关联使用快于使用专用数据库的全链路耗时;因为不同类型数据的融合后数据量的巨大增加,防止海量数据的性能衰退也很重要…总之,做融合数据库很难。
融合数据库是不是对传统数据库的颠覆,我认为不算完全是,它更像是一种组合与扩展,要做好融合数据库我觉得可以从以下一些方面入手:
- 增强传统:对传统功能要进一步增强
- 创新结合:对创新内容和新技术也要加速结合
- 软硬结合:充分利用当代硬件优势,让数据库充分利用
- …
总结
本期又讲了下融合数据库。
老规矩,不知道写了些啥。
文章被以下合辑收录
评论

 0 点赞
0 点赞




