





随着互联网和社交网络的快速发展,出现了连续多表连接查询这种新的查询变体。它要求随着数据库以流式方式更新而持续监控查询结果。如下图所示。
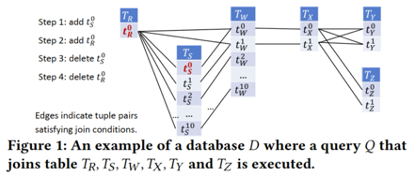
然而,现有的连续多表连接顺序选择方法大多基于启发式策略,可能无法选择出最高效的连接顺序。同时,直接将静态多表连接顺序选择算法应用于流式环境,也会因高昂的计算成本而成为系统瓶颈。 针对上述问题,论文提出了AJOSC这种自适应连接顺序选择算法。AJOSC包含三个技术点:
新的代价模型
AJOSC利用动态规划,结合专为连续多表连接设计的新代价模型,寻找最优连接顺序。 新代价模型提出了LA cost。对于每一个子查询P,LA(P)是,按照最优顺序使用P的一个实例来计算包含该实例的查询结果的期望cost。
LA(P)的计算方法如下:






从头计算所有子查询(此处子查询默认指的是join graph connected的子查询)的LA cost的方法是,利用如下图的cost dependency graph (abbr. CDG),自底向上BFS搜索。
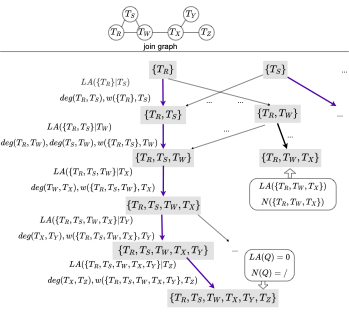
搜索完成后,从root node开始,沿着计算好的向下walk,就会得到选出来的order。
重新计算order的增量算法
在数据分布发生变化的时候,我们需要重新计算order。从头计算order代价太高了。因此,我们提出了增量算法来解决这个问题。
先介绍基础的增量算法,再介绍基于下界的优化算法。
基础的增量算法如下。

例子如下图b1.
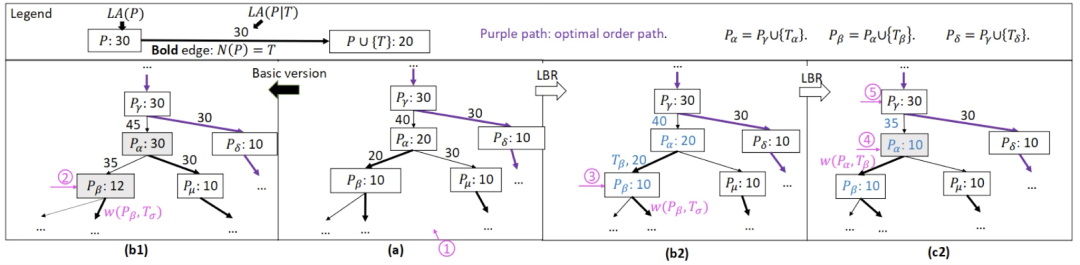
基于以下的观察,我们提出了基于下界的优化算法 (LBR):
如果节点P不在CDG中的任何最优顺序路径上,则最优顺序不会因为LA(P)增加而改变。
这个观察让我们可以在statistic发生某些变化时,不更新value的值,从而节省开销。具体来说,我们的LBR算法如下:



increment 和 decrement分别对应例子中的箭头3和4.
在计算order阶段,依然是从root node开始,沿着计算好的向下walk。但是,有些node的可能是inaccurate的。因此,我们调用如下图的
来计算accurate的。
延迟重新计算的机制
AJOSC在统计量和变化较大时,认为数据分布发生了较大的变化,因而重新计算order。我们设计了一系列机制来判断什么叫“变化较大”。
一种天真的方法是,当统计数据的变化超出预定义的比率时触发重新排序。但是,这将出发不必要的重新排序。在遇到的离群值时,会变化很大,但在处理新的更新时将很快恢复到原来的期望值。
因此,我们提出了延迟重新计算的机制。

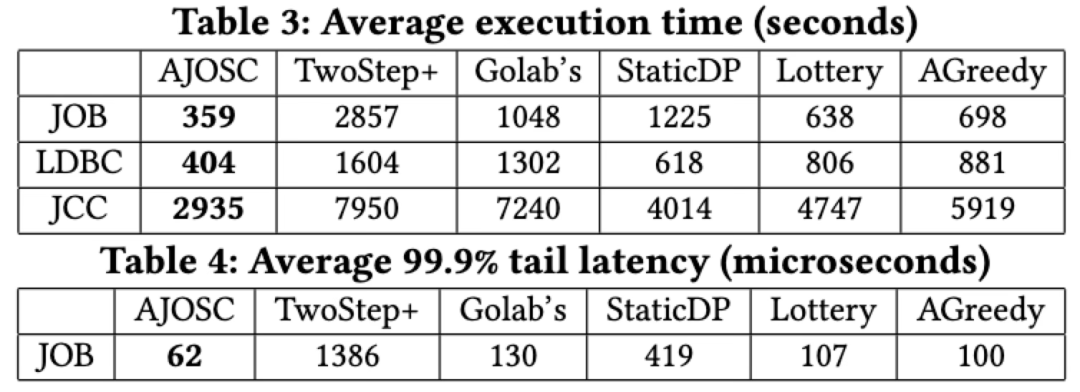
实验结果
实验结果表明,AJOSC算法的性能相较于当前方法有显著提升。


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

