





MySQL数据库中的SQL执行的时候经常会遇到未按预期走索引从而导致SQL执行时间长的情况出现。本文通过实际案例演示如何通过不修改SQL脚本而是通过修改数据库的参数来解决的案例。
1. 基础信息
数据库版本:MySQL5.7.30 (percona分支)
表结构信息如下
因包含字段较多,只截取部分重要字段CREATE TABLE `tb1` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',c3 varchar(50) NOT NULL COMMENT '',c1 varchar(20) NOT NULL COMMENT '',c2 varchar(30) NOT NULL COMMENT '',c4 tinyint(1) NOT NULL DEFAULT '0' COMMENT '',c6 datetime NOT NULL COMMENT '',c5 datetime NOT NULL COMMENT '',c7 varchar(10) DEFAULT '' COMMENT '','c20' text ,PRIMARY KEY (`id`),KEY `idx_c1_c2` (c1,c2) USING BTREE,KEY `idx_c3` (c3),KEY `idx_c1_c4` (c1,c4),KEY `idx_c1_c5` (c1,c5),KEY `idx_c6_c7_c4` (c6,c7,c4) USING BTREE,KEY `idx_c7_c2_c6` (c7,c2,c6)) ENGINE=InnoDB AUTO_INCREMENT=76579517 DEFAULT CHARSET=utf8
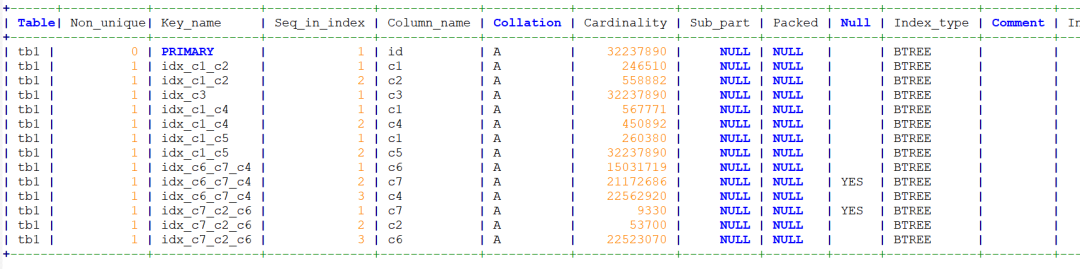
索引统计信息如下
+------+-----------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+| Table| Non_unique| Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |+------------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+| tb1 | 0 | PRIMARY | 1 | id | A | 32237890 | NULL | NULL | | BTREE | | || tb1 | 1 | idx_c1_c2 | 1 | c1 | A | 246510 | NULL | NULL | | BTREE | | || tb1 | 1 | idx_c1_c2 | 2 | c2 | A | 558882 | NULL | NULL | | BTREE | | || tb1 | 1 | idx_c3 | 1 | c3 | A | 32237890 | NULL | NULL | | BTREE | | || tb1 | 1 | idx_c1_c4 | 1 | c1 | A | 567771 | NULL | NULL | | BTREE | | || tb1 | 1 | idx_c1_c4 | 2 | c4 | A | 450892 | NULL | NULL | | BTREE | | || tb1 | 1 | idx_c1_c5 | 1 | c1 | A | 260380 | NULL | NULL | | BTREE | | || tb1 | 1 | idx_c1_c5 | 2 | c5 | A | 32237890 | NULL | NULL | | BTREE | | || tb1 | 1 | idx_c6_c7_c4 | 1 | c6 | A | 15031719 | NULL | NULL | | BTREE | | || tb1 | 1 | idx_c6_c7_c4 | 2 | c7 | A | 21172686 | NULL | NULL | YES | BTREE | | || tb1 | 1 | idx_c6_c7_c4 | 3 | c4 | A | 22562920 | NULL | NULL | | BTREE | | || tb1 | 1 | idx_c7_c2_c6 | 1 | c7 | A | 9330 | NULL | NULL | YES | BTREE | | || tb1 | 1 | idx_c7_c2_c6 | 2 | c2 | A | 53700 | NULL | NULL | | BTREE | | || tb1 | 1 | idx_c7_c2_c6 | 3 | c6 | A | 22523070 | NULL | NULL | | BTREE | | |+------------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
实际数据量约4千万。
select a.* from tb1 a where a.c1 = '123' and c4 in (0, 3) and c5 >=DATE_SUB('2025-03-21 14:40:14', INTERVAL 15 DAY) order by id limit 100;
+----+-------------+-------+------------+-------+--------------------------------+---------+---------+------+-------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------------------------+---------+---------+------+-------+----------+-------------+| 1 | SIMPLE | a | NULL | index | idx_c1_c2,idx_c1_c4,idx_c1_c5 | PRIMARY | 8 | NULL | 21978 | 0.11 | Using where |+----+-------------+-------+------------+-------+---------------------------------+---------+---------+------+-------+----------+-------------+

3. 常规优化方式
2.1 修改SQL语句
原SQL语句可以有多种修改方式,最简单的方式便是去掉order by id,即改为
select a.* from tb1 a where a.c1 = '123' and c4 in (0, 3) and c5 >=DATE_SUB('2025-03-21 14:40:14', INTERVAL 15 DAY) limit 100;
+----+-------------+-------+-----------+-------+--------------------------------+------------+---------+------+-------+----------+-------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------------------------+-----------+---------+------+-------+----------+-------------------------------------+| 1 | SIMPLE | a | NULL | range | idx_c1_c2,idx_c1_c4,idx_c1_c5 | idx_c1_c4 | 63 | NULL |158207 | 33.33 | Using index condition; Using where|+----+-------------+-------+------------+-------+---------------------------------+-----------+---------+------+-------+----------+-------------------------------------+

alter table tb1 add key idx_c1_c4_c5(c1,c4,c5);
当表中存在低基数字段(如性别字段)或优化器因统计信息不准确而错误选择全表扫描时,通过调整此参数可强制优化器优先使用索引,尤其在以下情况:
索引实际效率高于优化器估算值(例如大表中通过索引快速定位少量数据全表扫描
因磁盘I/O或数据量过大导致性能瓶颈。
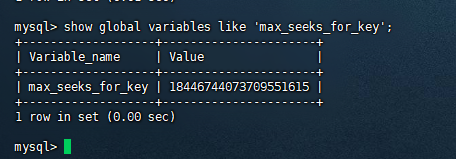
本案例调整演示
该参数使用的很小众,但本案例正好适用,例如:
mysql> set max_seeks_for_key=100;Query OK, 0 rows affected (0.00 sec)
修改后执行计划如下:
+----+-------------+-------+-----------+-------+--------------------------------+------------+---------+------+-------+----------+---------------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------------------------+-----------+---------+------+-------+----------+---------------------------------------------------+| 1 | SIMPLE | a | NULL | range | idx_c1_c2,idx_c1_c4,idx_c1_c5 | idx_c1_c2 | 62 | NULL |524552 | 6.67 | Using index condition; Using where; Using filesort|+----+-------------+-------+------------+-------+---------------------------------+-----------+---------+------+-------+----------+---------------------------------------------------+
可见,虽然调整后虽然选择的索引依然不是最优的,但是已经相对较快了。优化后执行时间不到1s。
因此可以在添加组合索引及数据归档清理前临时调整该参数临时解决。
想要全局生效需要修改全局参数
set global max_seeks_for_key=100;

2. mysql8.0新增用户及加密规则修改的那些事
3. 比hive快10倍的大数据查询利器-- presto
4. 监控利器出鞘:Prometheus+Grafana监控MySQL、Redis数据库
5. PostgreSQL主从复制--物理复制
6. MySQL传统点位复制在线转为GTID模式复制



文章转载自数据库干货铺,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
