




作者:Digital Observer(施嘉伟)
Oracle ACE Pro: Database
PostgreSQL ACE Partner
11年数据库行业经验,现主要从事数据库服务工作
拥有Oracle OCM、DB2 10.1 Fundamentals、MySQL 8.0 OCP、WebLogic 12c OCA、KCP、PCTP、PCSD、PGCM、OCI、PolarDB技术专家、达梦师资认证、数据安全咨询高级等认证
ITPUB认证专家、PolarDB开源社区技术顾问、HaloDB技术顾问、TiDB社区技术布道师、青学会MOP技术社区专家顾问、国内某高校企业实践指导教师
公众号/墨天轮:Digital Observer;CSDN/PGfans:施嘉伟;ITPUB:sjw1933
故障类型
磁盘IO性能异常
现象错误号
存储电池失效,数据库整体性能性能下降。
故障描述
某客户的业务系统在月结时出现严重性能问题。平时月结时间大概维持在1小时左右,但故障期间1天都无法完成月结。需要特别指出的是,该系统除了月结,其他业务都一切正常。这在某种程度上加大了问题的判断难度。最终排查由于存储电池失效引起此次故障。
故障原因分析
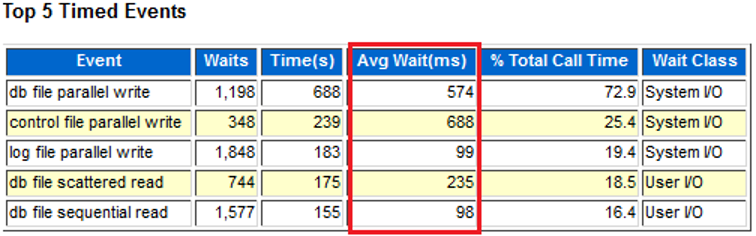
数据库在月结时的AWR报告如下:
其中影响数据库性能最大的SQL是一条insert语句,如下所示:

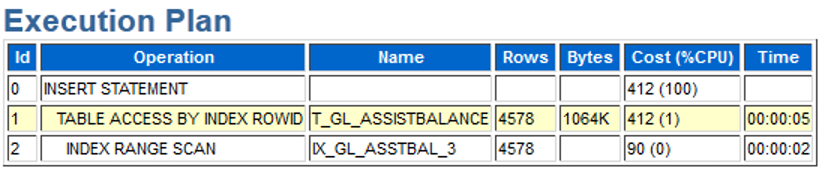
该insert语句的执行计划显示完全正常,如下所
从AWR报告中可以看到,数据库性能问题的原因已经相当明显:存储的I/O已经严重出现问题。其中存储的平均每次写的时间最高达到了688ms,平均读的时间最高达到了235ms。而根据经验,平均读的时间应该维持在5-10ms左右,最高也不应该超过20ms(在存储cache不命中的情况下)。
但是存储工程师在查看了存储之后,告之客户存储没问题!确实,简单地查看存储是没问题:
首页页面没有错误。
电池没有报警。
硬盘没有亮灯。
操作系统日志没有存储相关错误。
当局者迷,旁观者清。在月结业务积压的时候,客户信了存储工程师的诊断结果。于是自己做了如下操作:
1、将核心业务用户使用exp/imp的方法迁移到一台PC服务器进行月结处理,月结正常。
2、使用exp/imp的方法重组t_Gl_AssistBalance表,重组完成之后月结依旧缓慢。
同样的操作,同样的数据,同样的业务。低端配置的PC服务器月结正常,而配置相对高端的小机却出现严重问题。这样的现象客户无论如何是想不通的。于是请来了业务厂商的DBA,该DBA在不观察数据库症状的情况下,三下五除二地设了以下隐含参数:
1、_b_tree_bitmap_plans=false
2、_no_or_expansion=true
可想而知,月结症状依旧。这时该DBA又三下五除二地进行了SGA参数调整,将buffer cache从原来的3G调整为16G,将shared pool从原来的200m调整为现在的2G。如下所示:

在存储I/O紧张的情况下,适当加大buffer cache有利于缓解存储的I/O压力,但这是建立在合理调整基础之上的。内存不是越多越好,只要够用就行。DBA调整完这些参数之后,又再一次开始月结业务,结果系统更加缓慢,产生了大量交换。如下所示:
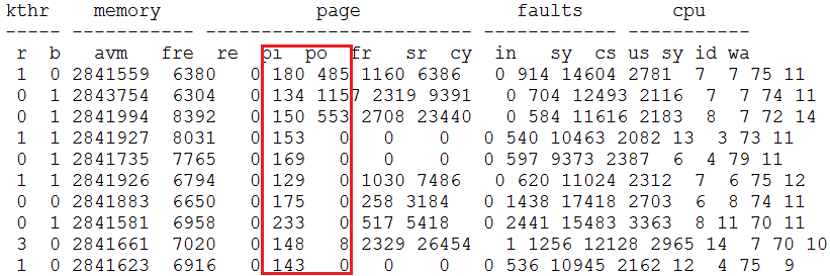
在只有24G内存的主机上,将SGA设置为18G,这明显是不合理的。这时业务厂商DBA也无能为力,仍下一句话:“你们的业务系统版本太老了,需要升级!”客户傻眼了。
做了这么多无效功,客户终于又找我们了。于是紧急前往现场。我的结论还是一样:存储出现问题。但存储工程师又说:存储没问题。最后我建议存储工程师将电池重新激活一下,这时柳暗花明又一村了,激活完成之后,操作系统errpt出现如下清晰而又愉快的警告:
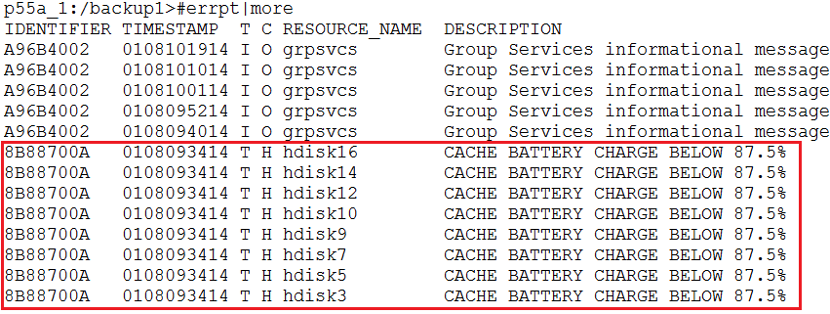
果然是存储电池出现了问题,进而导致cache失效,进而导致存储I/O大幅度下降。接下来存储工程师进行了一些操作,cache恢复正常。月结操作也恢复正常。
事情还没有完。由于在客户现场,虽然问题已经解决,但闲着也是闲着,于是我向存储工程师要来了这个存储底层配置情况:
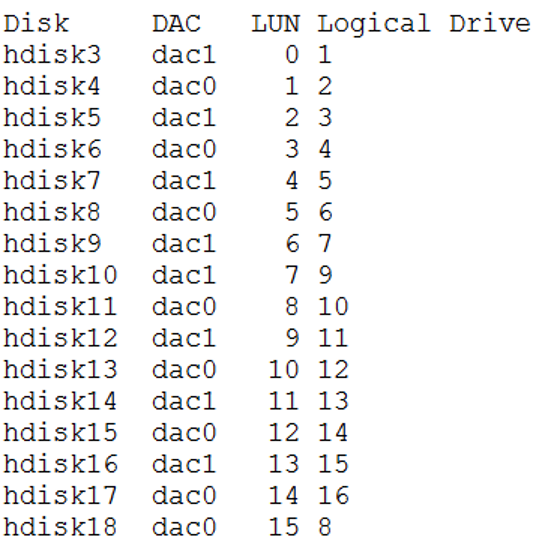
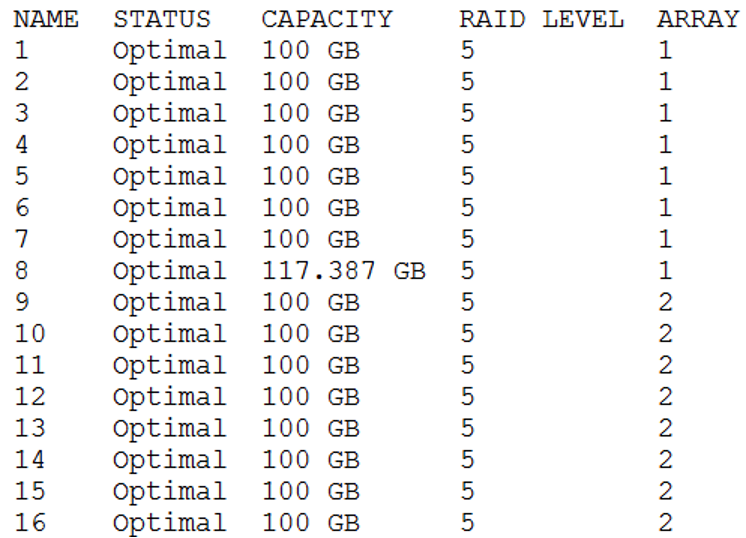
也就是说hdisk3-9和hdisk18属于raid组1,hdisk10-17盘属于raid组2。而数据库的数据文件全部存放在raid组1,这是极不合理的,这相当于没有将存储的I/O性能完全发挥出来。文件系统创建情况如下所示:
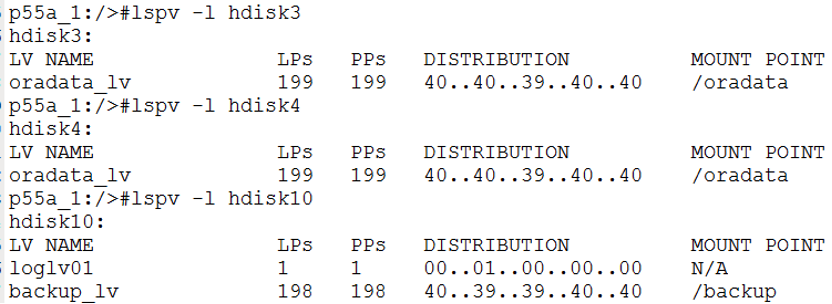
总结建议
为了最大程度地发挥存储的性能,于是我建议将online redolog和undo数据文件在线迁移到/backup文件系统中。迁移完成之后,月结速度进一步提升。

