




❝开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, OceanBase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共2760人左右 1 + 2 + 3 + 4 +5 + 6 + 7 + 8 +9)(1 2 3 4 5 6 7群均已爆满,,开8群200+ 9群)
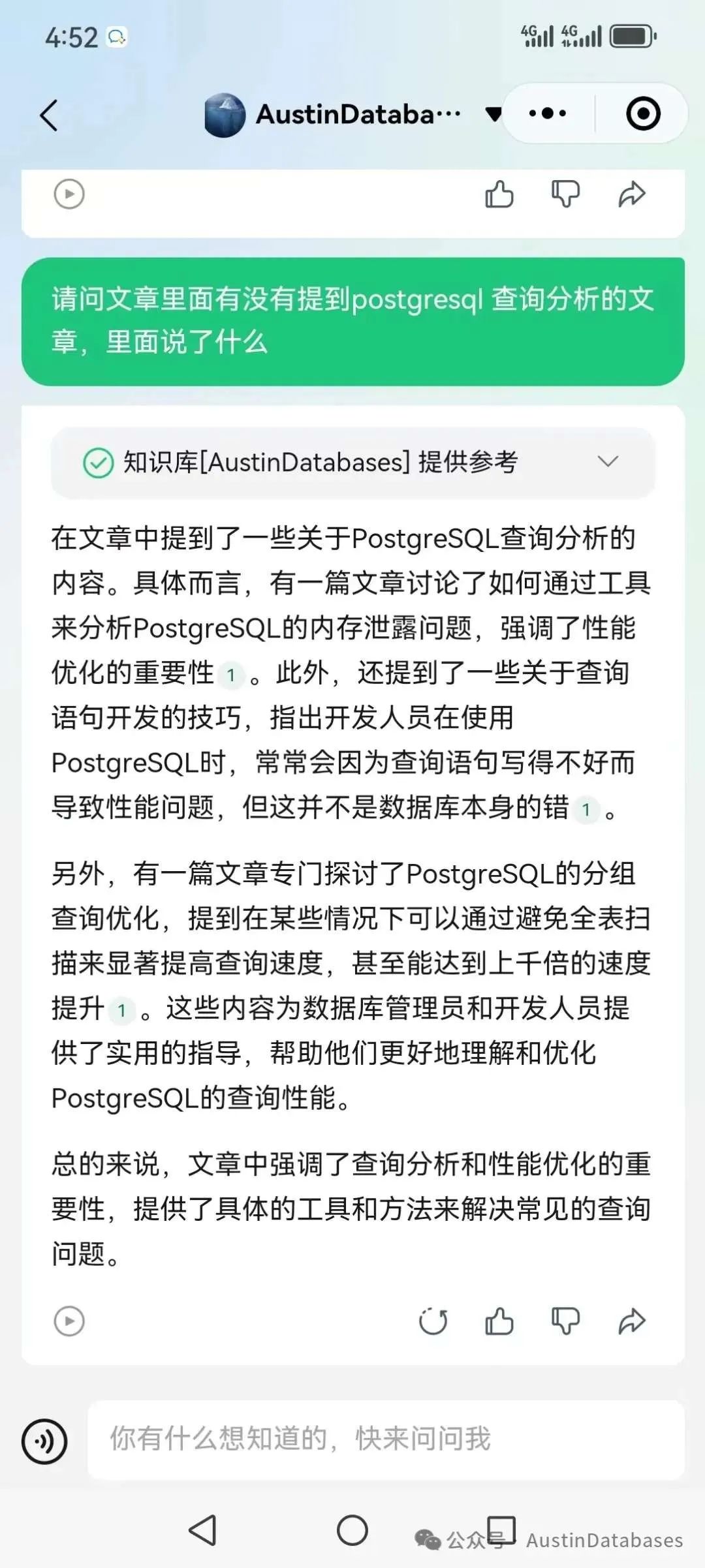
Austindatabases公众号已经开启了,AI 文章分析,AI 文章问答,比如你想知道AustinDatabases 里面,说了多少种数据库,那些是讲 MySQL,那些是PostgreSQL, 那些是OB ,POLARDB ,MongoDB ,SQL Server, 阿里云的,问他他会列出来,同时如果有问题不明白,可以将文章的文字粘贴到公众号提供的专用AI ,公众号将通过众多文章(目前1300多篇)来进行尝试性的解释。使用方法,直接到微信公众号中点击服务,选择AI问答。如下示例
一直提到框架学习法,其中主体的思想就是如何快速的学习某项数据库产品的知识。其中框架学习法里面有一条系统学习,系统学习是在给学习的知识搭建“骨架”,所以从这期起,开始搭建OceanBase学习的骨架。今年要和“申公豹”一样修炼岂可怠慢。

今天开始学习第5章OBCA 应用开发,本期学习的是应用开发,此为下半部分

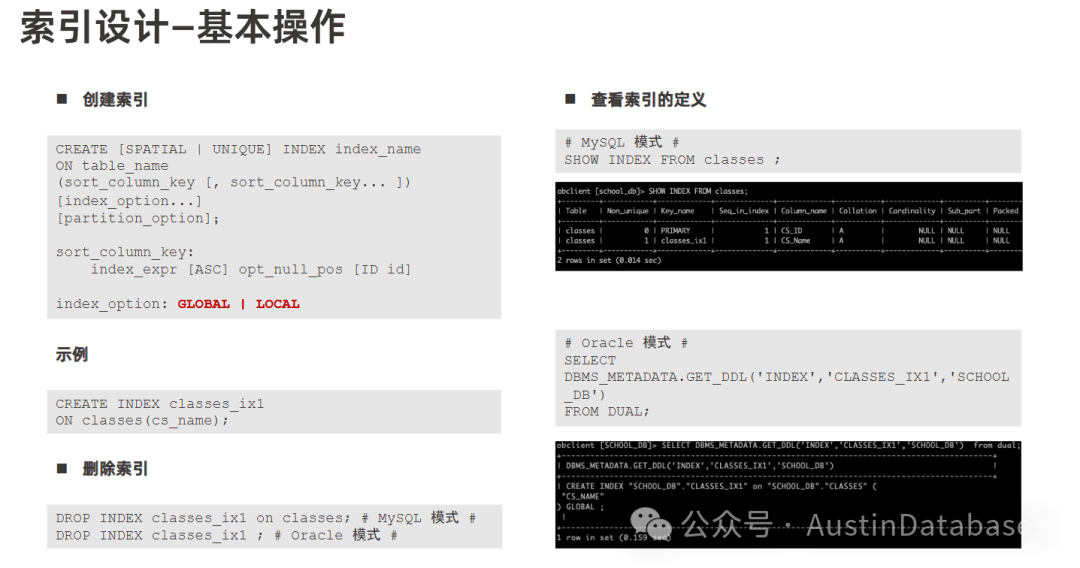
索引类型在OceanBase中有多种索引类型,包括:
主键索引:在OB中可以理解数据是以主键的顺序有序的组织的物理标识
唯一索引:保证在表内的索引列上不存在两行完全相同的值。在 OceanBase 数据库中,NULL 值也会存储在唯一索引中。(需要注意这点,所以尽量不要让唯一索引列是允许NULL存在)
二级索引 对于分区表,索引可以分为两类:局部索引和全局索引

这三者的不同在哪里
主键索引:主键是一种约束,用于唯一标识表中的每一行。在主键中不能存在null值,这是和唯一索引在逻辑上最大的不同。主键具有以下关键特性:非空 (NOT NULL),唯一 (UNIQUE),并且在表中是全局唯一的。 一个表中只能有一个主键。
物理存储: 在 OceanBase 数据库中,数据表是以主键有序存储的,主键和表数据存储在一起。这使得通过主键进行查找效率非常高,因为它直接定位到数据所在的物理位置。这可以被认为是物理索引。 当您为一个表定义了主键约束,数据库会自动创建并维护一个对应的主键索引。 主要用于保证数据的唯一性和完整性,以及作为表中行的主要访问路径。
唯一索引:唯一索引用于保证在表内的索引列上不存在两行完全相同的值。与主键不同的是,唯一索引允许包含 NULL 值,在 OceanBase 数据库中,NULL 值也会存储在唯一索引中 。一个表中可以创建多个唯一索引,作用于不同的列或列组合。
物理存储: 唯一索引是二级索引的一种,其索引结构与数据的物理存储不一定直接相关,需要通过索引查找到对应的行记录。可以通过 CREATE UNIQUE INDEX 语句显式创建。用于确保表中某些列或列组合的数值的唯一性,防止出现重复数据。
二级索引:二级索引是相对于主键索引而言的,它是在表的其他列上创建的索引。二级索引不具备强制的唯一性约束,可以包含重复的值。一个表中可以创建多个二级索引,用于优化不同条件的查询。
物理存储: 二级索引独立于数据的物理存储。它包含索引列的值以及指向对应数据行主键值的指针。当通过二级索引查询数据时,通常需要先在二级索引中找到匹配的记录,然后再通过主键值回表查询实际的数据行。 主要目的是提高基于非主键列的查询性能,减少全表扫描的需求。
无论是主键,唯一索引还是二级索引,它们的主要目的都是为了提高数据库的查询性能。通过使用索引,数据库可以更快地定位到所需的数据,而不需要扫描整个表。它们都使用特定的数据结构(通常是 B 树或其变种)来组织索引数据,以便进行高效的查找。数据库在执行插入、更新和删除操作时,需要维护所有相关的索引,以保证索引和数据的同步性。过多的索引会增加这些维护操作的开销。对于分区表,主键索引、唯一索引和二级索引都可以进一步划分为局部索引和全局索引,局部索引是针对单个分区上的数据创建的索引。

局部索引 (局部索引) 是针对单个分区上的数据所创建的索引。这意味着每个分区都有自己独立的索引,全局索引 (全局索引) 是跨越所有分区的索引,它是全局唯一的。
适用场景与优先级: 局部索引的优先级通常最高,是 OceanBase 在 MySQL 模式下的默认创建类型。其次是全局分区索引, 最后才是全局索引。
唯一性保证:
局部索引由于只针对单个分区,无法保证全局的唯一性。如果需要在局部索引的列上保证全局唯一,通常需要在索引列上添加表的分区列一起创建唯一索引。例如,如果一个按学号哈希分区的学生表需要在姓名列上创建唯一索引,则需要使用姓名加上分区字段序号组成一个唯一索引。全局索引是全局唯一的,因此可以保证索引列的唯一性。
局部索引的索引键值跟表中的数据是一一对应的在同一个分区内。全局索引的数据通常会单独集中存储在某一个或多个数据库服务器之上,与表分区的数据没有存储在一起。当插入、更新或删除分区表中的数据时,局部索引的维护只涉及到相应的分区,维护成本相对较低,由于全局索引和表分区的数据没有存储在一起,每次对表数据的插入、更新或删除都可能涉及到跨机器的 RPC 调用来维护全局索引的数据一致性,因此全局索引带来的维护代价通常比较高。
查询性能: 对于基于分区键的查询,局部索引通常能提供很好的性能,因为查询可以限制在特定的分区内进行。全局索引可以优化跨分区的查询,因为它包含了所有分区的数据索引信息。然而,如果全局索引没有很好地与查询条件匹配,或者由于其物理分布的特性,可能不会总是最优。
分区方式的影响: 局部索引的分区与表的分区方式直接对应。全局索引的分区(如果进行分区)可以独立于表的分区方式进行设计,以进一步提升查询性能,避免更新索引时产生数据热点。在创建索引时,可以使用 LOCAL 关键字显式指定创建局部索引。可以使用 GLOBAL 关键字显式指定创建全局索引。在 MySQL 模式下,默认创建的是局部索引。
总而言之,局部索引更轻量级,维护成本较低,适用于针对单个分区的查询,但无法保证全局唯一性。全局索引可以保证全局唯一性,适用于跨分区的查询,但维护成本较高,并且可能涉及跨机器的访问。在设计分区表索引时,通常优先考虑局部索引,其次是全局分区索引,最后才是全局索引。


关于视图,序列,存储过程的设计中的一些特点:
OceanBase 数据库中视图设计 (视图设计)、序列设计 (序列设计) 和 存储过程设计 (存储过程设计) 中视图是存储好的查询。用户可以通过访问视图来获取视图定义的数据。其中主要的目的为,简化复杂查询,当某个查询语句需要执行多张表的复杂关联查询,并且在应用程序开发中多个地方都需要使用该 SQL 语句获取数据时,可以基于该查询语句创建一个视图,应用程序可以直接使用视图替代之前的复杂查询语句,从而简化应用程序开发的复杂度。
提高数据安全性: 可以通过创建只包含部分列的视图,并将视图的权限开放给特定用户,从而限制用户对敏感数据的访问。例如,可以创建一个不包含员工薪水信息的视图,供普通用户查询员工基本信息。在设计视图时,需要考虑其目的是简化操作还是提高安全性,并根据实际的查询需求定义视图包含的列和关联关系。
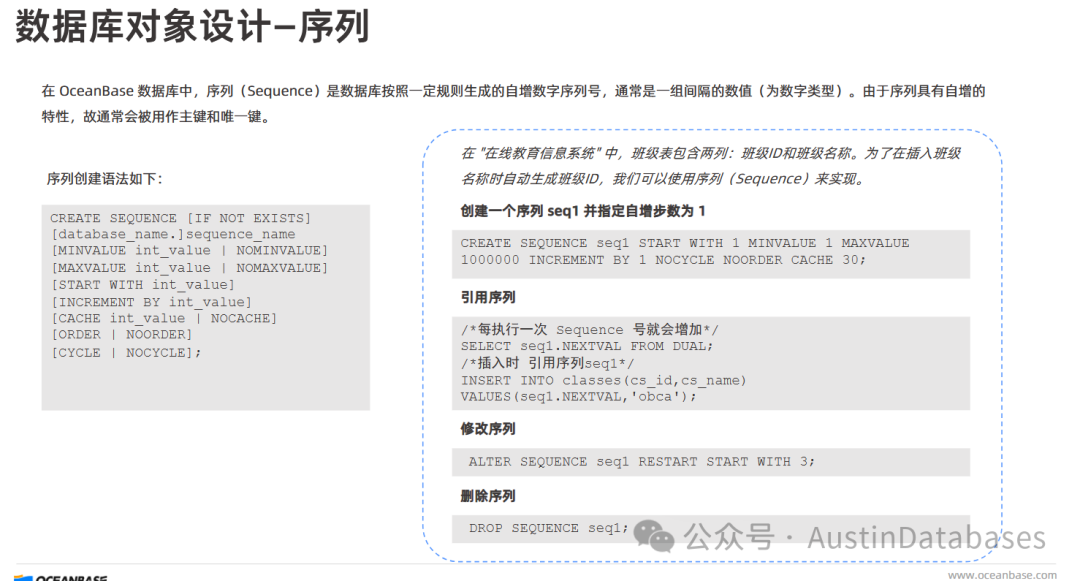
而序列的设计中,序列主要用于自动生成自增的序列号,常用于为主键或唯一键生成唯一的标识符。其中使用场景 例如,学生表的主键学号,可以在插入新数据时通过序列自动生成。
创建语法示例:
CREATE SEQUENCE 用于创建序列,s_seq1 是序列的名称。START WITH 1 表示序列从 1 开始增长。INCREMENT BY 1 表示每次增长 1。
获取下一个序列值: 使用 s_seq1.next_value 可以获取序列的下一个值。例如,在课程表插入记录时,课程号可以通过序列生成。OceanBase 提供了修改序列 (ALTER SEQUENCE) 和删除序列 (DROP SEQUENCE) 的基本操作命令。在设计序列时,需要考虑序列的起始值 (START WITH)、增长步长 (INCREMENT BY)、是否需要循环 (CYCLE) 等属性,以满足业务对唯一标识符生成的需求。
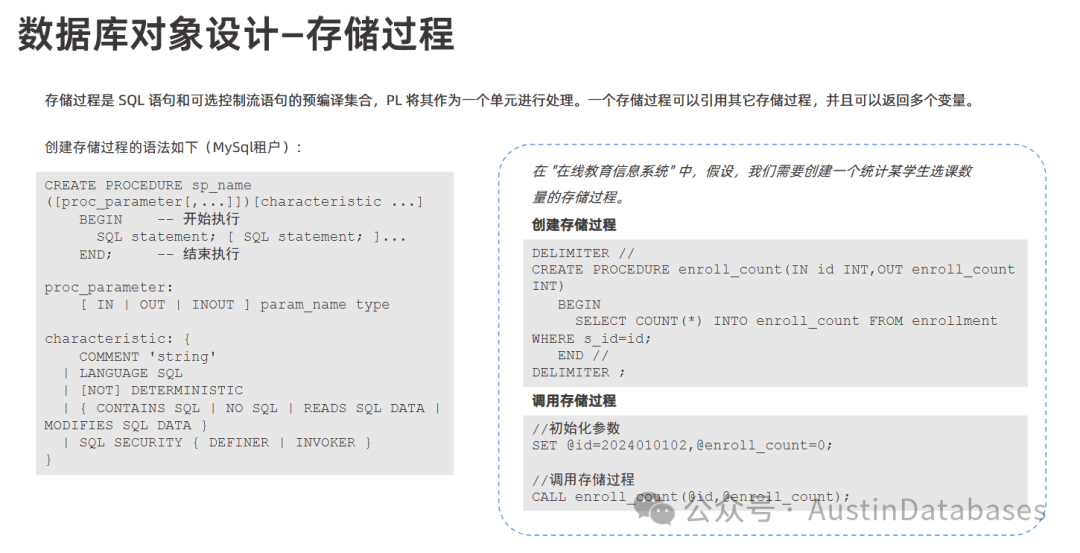
存储过程是一条或多条 SQL 语句的集合产物,用于在数据库内封装一系列复杂的操作,以便重复使用,从而减少数据库开发人员的工作量。其设计目的和优势主要在代码重用,代码重用可以将常用的、复杂的业务逻辑封装成存储过程,供多个应用程序或 SQL 语句调用,提高代码的重用性。
同时减少网络传输,用存储过程可以减少应用程序与数据库的交互次数,将多次 SQL 操作封装在数据库内部执行,节约了网络传输的开销,提升了系统的性能。提高安全性可以通过授权用户执行特定的存储过程,而无需直接授予他们对底层表的访问权限,从而提高数据的安全性。
创建与执行:源文件提供了一个创建统计学生选课数量的简单存储过程的示例。可以使用特定的命令(如 CALL)执行存储过程,并通过命令查看存储过程中的变量状态和返回值。设计考虑在实际的存储过程开发中,存储过程中可能包含多条 SQL 语句以及复杂的业务逻辑处理。设计存储过程时,需要根据具体的业务需求,将相关的 SQL 操作和逻辑封装在一起,考虑输入参数、输出参数、事务处理、错误处理等。 总而言之,视图、序列和存储过程都是 OceanBase 数据库中重要的数据库对象,合理地设计和使用它们可以简化开发、提高性能和保障数据安全。在设计时需要根据具体的业务场景和需求进行细致的规划。
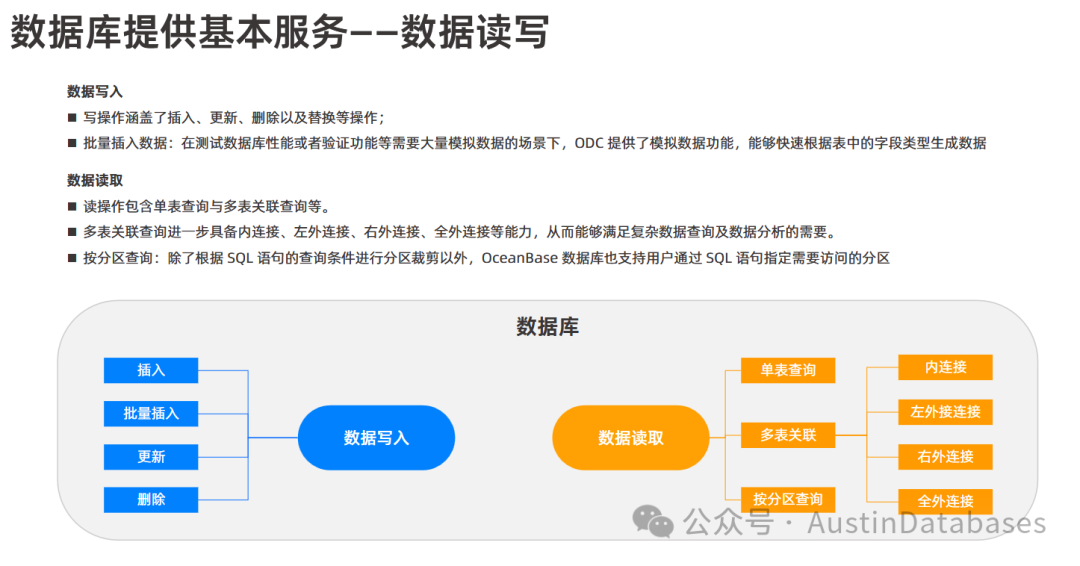

在数据库中的链接操作是一个每个数据库都应该具有,但每个数据库在处理这方都有自己特性的部分,尤其分布式数据库在数据库的连接中,处理起来是有难度的。OceanBase 数据库支持以下四种表与表之间的连接方式:
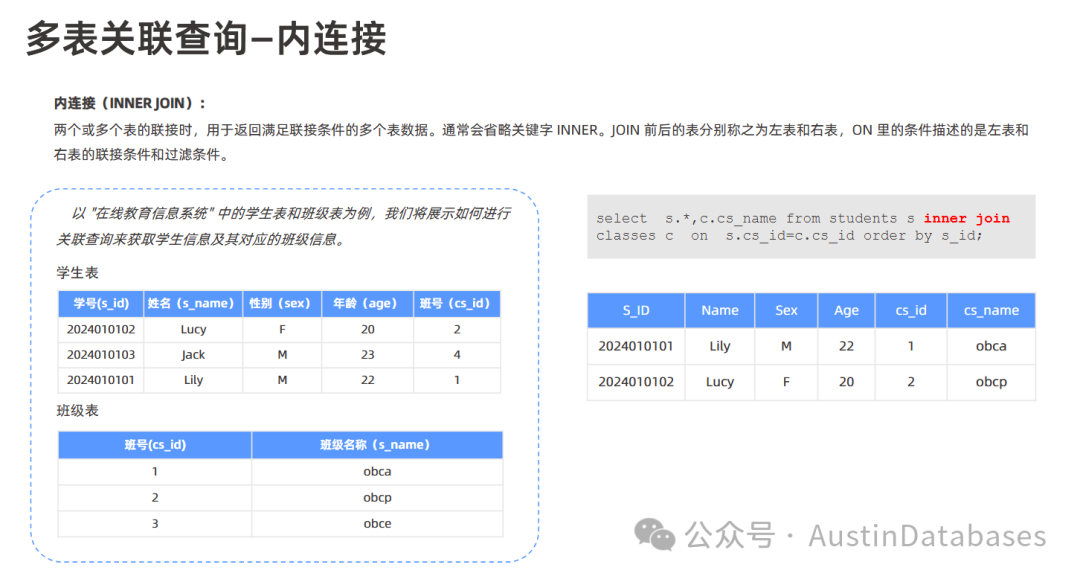
内连接 (INNER JOIN):
定义:内连接要求左表和右表都要有对应的数据记录,只有当连接条件在两个表中都满足时,才会返回结果。
示例:通过关联学生表和班级表查询学生信息和班级信息,使用内连接时,只有在学生表和班级表都有匹配的班级编号时,才会显示该学生的信息和对应的班级信息。例如,如果某个学生的班号在班级表中没有记录,那么该学生的信息就不会在内连接的结果中显示。
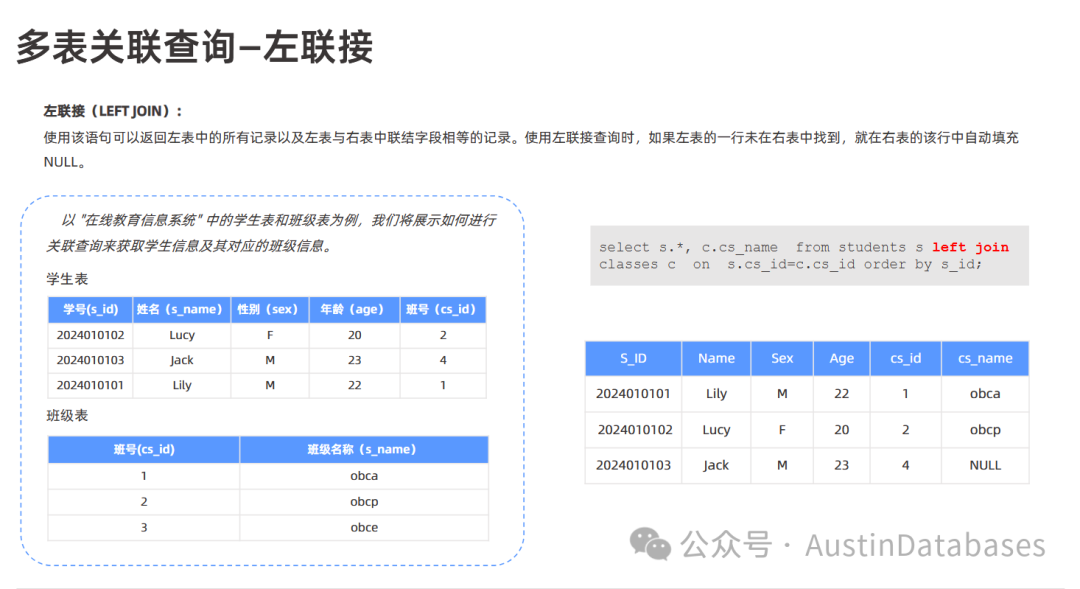
左外连接 (LEFT OUTER JOIN 或 LEFT JOIN):
定义:左外连接以左表为基准,返回左表中的所有记录,以及左表与右表中连接字段相等的记录。如果左表中的某行在右表中没有匹配的记录,则结果中右表对应的列会填充 NULL 值。
示例:通过关联学生表和班级表查询学生信息和班级信息,使用左外连接时,学生表中的所有学生信息都会显示出来。如果某个学生的班号在班级表中没有对应的记录,那么该学生的班级信息会显示为空。
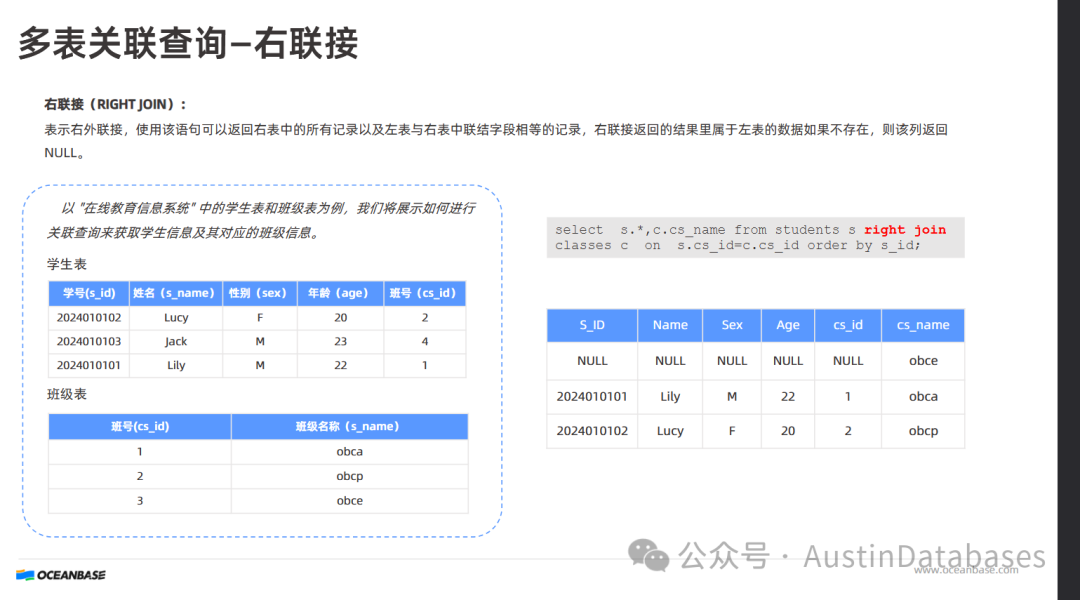
右外连接 (RIGHT OUTER JOIN 或 RIGHT JOIN):
定义:右外连接以右表为基准,返回右表中的所有记录,以及右表与左表中连接字段相等的记录。如果右表中的某行在左表中没有匹配的记录,则结果中左表对应的列会填充 NULL 值。
示例:通过关联学生表和班级表查询学生信息和班级信息,使用右外连接时,班级表中的所有班级信息都会显示出来。如果某个班级的班号在学生表中没有对应的学生记录,那么该班级的学生信息会显示为空。
全外连接 (FULL OUTER JOIN 或 FULL JOIN):
定义:全外连接会返回所有连接中的所有行,无论它们是否匹配。如果左表中的某行在右表中没有匹配的记录,则结果中右表对应的列会填充 NULL 值。如果右表中的某行在左表中没有匹配的记录,则结果中左表对应的列会填充 NULL 值。
示例:通过关联学生表和班级表查询学生信息和班级信息,使用全外连接时,学生表和班级表中的所有记录都会显示出来。对于在另一张表中没有匹配记录的行,其对应的列会显示为空。例如,某个学生没有对应的班级信息,其班级相关的列会显示为空;某个班级没有学生记录,其学生相关的列会显示为空。 总结来说,OceanBase 数据库支持常见的 SQL 表连接操作,开发者可以根据实际的业务需求和数据关联情况选择合适的连接方式来查询所需的数据。理解不同连接方式的特点对于编写正确的 SQL 查询语句至关重要

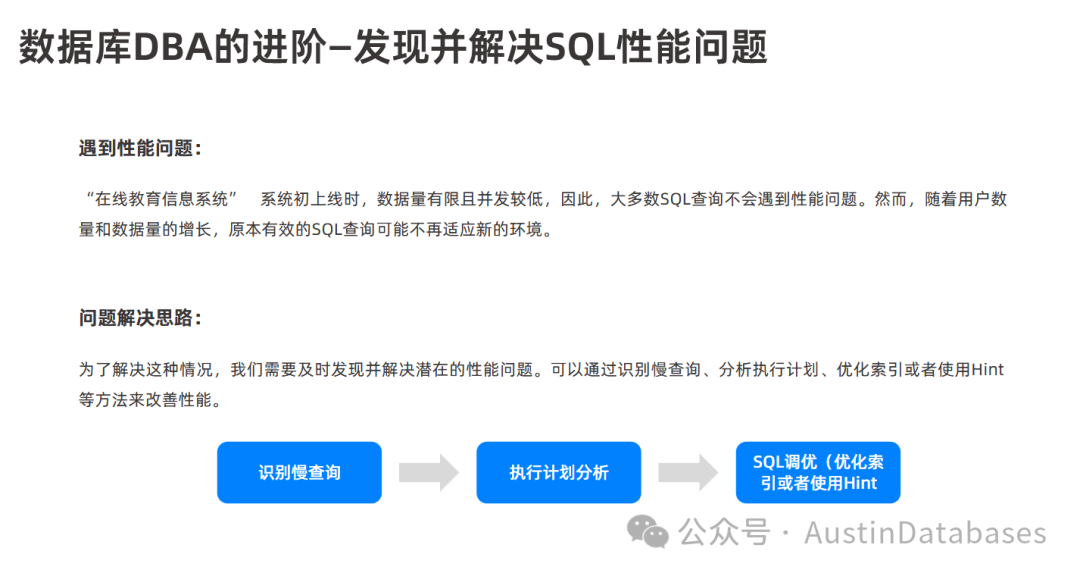
识别慢SQL是SQL调优的首要步骤。在对 SQL 语句进行优化之前,首先需要找到那些执行效率较低的 SQL 语句。 在实际的数据库管理和开发中,识别慢查询通常会在以下的几个位置来进行查找
监控工具: 许多数据库系统(包括 OceanBase)都提供监控工具,可以实时或定期地分析 SQL 语句的执行情况,并标记出执行时间较长的语句。
慢查询日志: 数据库通常会配置慢查询日志,记录执行时间超过预设阈值的 SQL 语句,开发者可以通过分析这些日志来找到需要优化的目标。
应用反馈: 用户或应用程序可能会报告某些功能响应缓慢,这通常也指向了某些执行效率低的 SQL 查询。
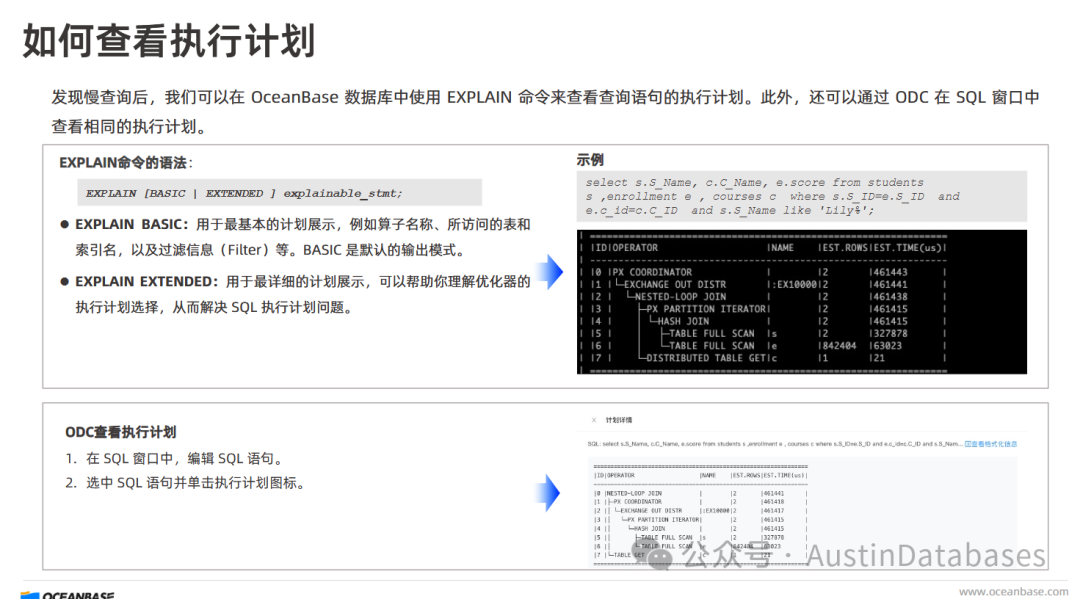
查看查询计划 (执行计划) “执行计划”是 SQL 调优的一个重要方面,查看 SQL 语句的执行计划 是理解数据库如何执行该语句的关键步骤,它可以帮助我们分析查询过程中可能存在的性能瓶颈。在标准的 SQL 数据库中,通常可以使用 EXPLAIN 或类似的命令来查看 SQL 语句的执行计划。(
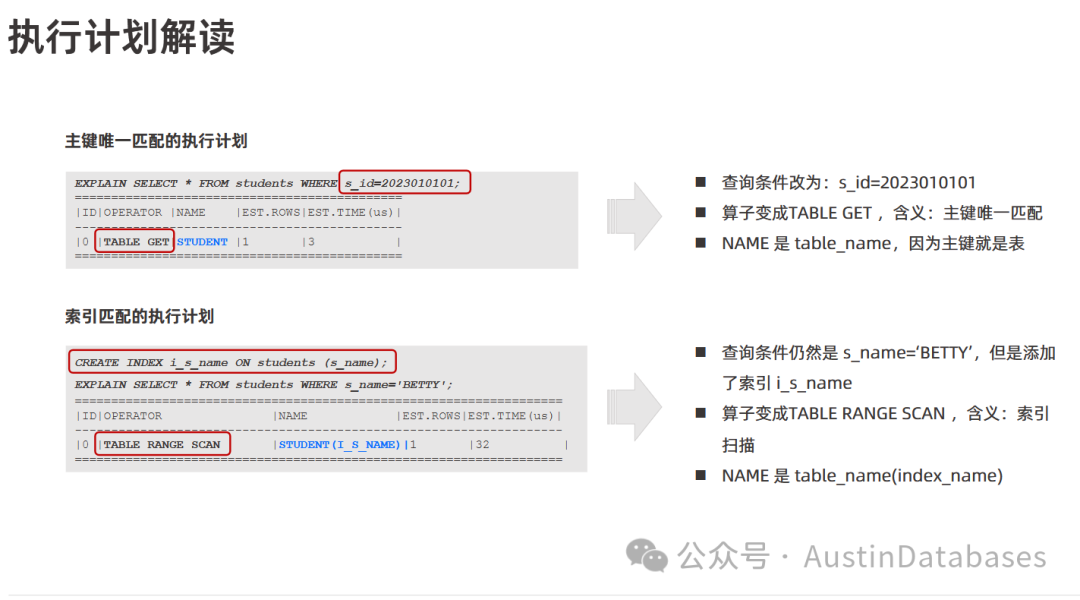
执行计划的解读 (执行计划的解读) 了解 SQL 语句的执行计划可以帮助分析 SQL 语句的执行过程,找出潜在的性能瓶颈。解读执行计划 是 SQL 调优中至关重要的一环。通过分析执行计划,开发者可以了解:查询访问哪些表和索引,表之间的连接方式(例如,Nested Loop Join, Hash Join 等)。数据的读取顺序,是否使用了索引以及使用了哪些索引。是否存在全表扫描等可能导致性能问题的操作。


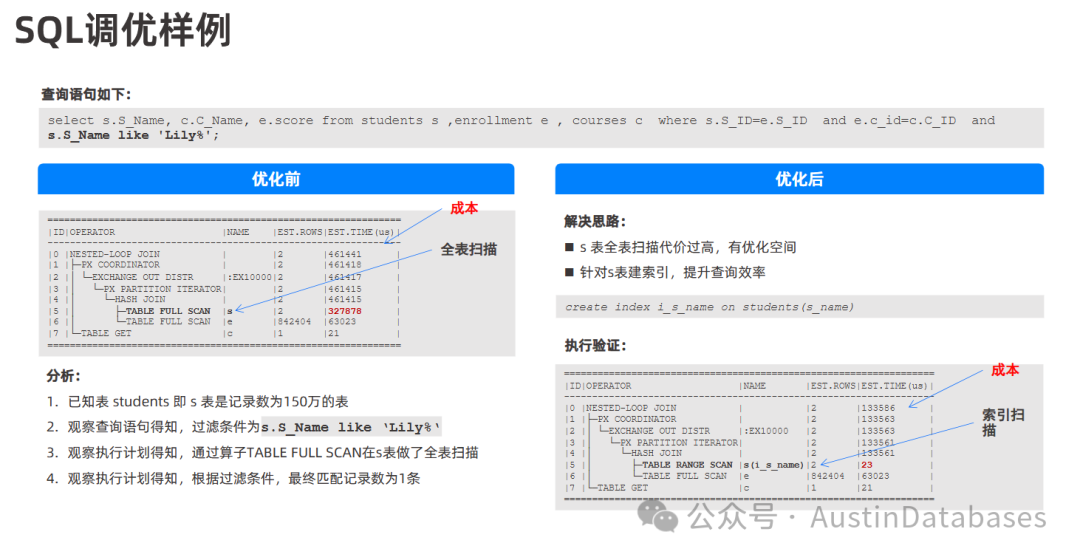


如何建立一套行之有效的SQL优化体系呢,我们可以进行列举:
1 制定开发规范和数据库对象设计原则,例如表结构设计、索引设计(包括局部索引和全局索引的选择)以及分区策略,合理的数据库设计是 SQL 优化的基础。这包括:选择合适的列类型,为频繁查询和高选择性的列创建索引,考虑索引的类型、唯一性和覆盖度。对于大数据量的表,设计合适的分区策略(Range 分区、List 分区、Hash 分区等)。考虑使用表组 (Table Group) 来优化关联查询的性能,将相关联的分区数据调度到同一主机。利用主键、外键约束和唯一索引来保证数据的完整性。
2 建立 SQL 性能监控机制,识别慢查询:源文件指出 识别慢 SQL 是 SQL 调优的首要步骤
3 掌握执行计划分析方法,对于分析 SQL 语句的执行过程和找出性能瓶颈的重要性。因此,建立能够查看和解读 SQL 执行计划的能力是优化体系的关键部分。
4 熟悉常用的 SQL 优化工具和技术:如OceanBase 提供的开发工具(如 ODC, OB Client, MySQL client 客户端),这些工具可能包含一些辅助 SQL 优化的功能。此外,源文件还介绍了数据导入导出工具,虽然不是直接的 SQL 优化工具,但在进行性能测试和数据准备时可能会用到。
5 持续进行 SQL 调优和知识积累: SQL 优化是一个持续进行的过程。建立知识库,记录优化经验和案例,对于构建和完善优化体系至关重要。
6 建立完善的性能测试流程:充分的性能测试是发现和验证优化效果的重要环节。
7 制定 SQL 编写规范:除了数据库对象设计,SQL 语句的编写方式也会显著影响性能。建立 SQL 编写规范,例如避免在 WHERE 子句中使用函数作用于索引列等,是预防性能问题的有效手段。


ODC (OceanBase Developer Center)
介绍: ODC OceanBase 打造的一个企业级的数据库开发平台。它支持个人 PC 桌面版本和 Web 版。ODC 支持连接 MySQL 租户和 Oracle 租户。
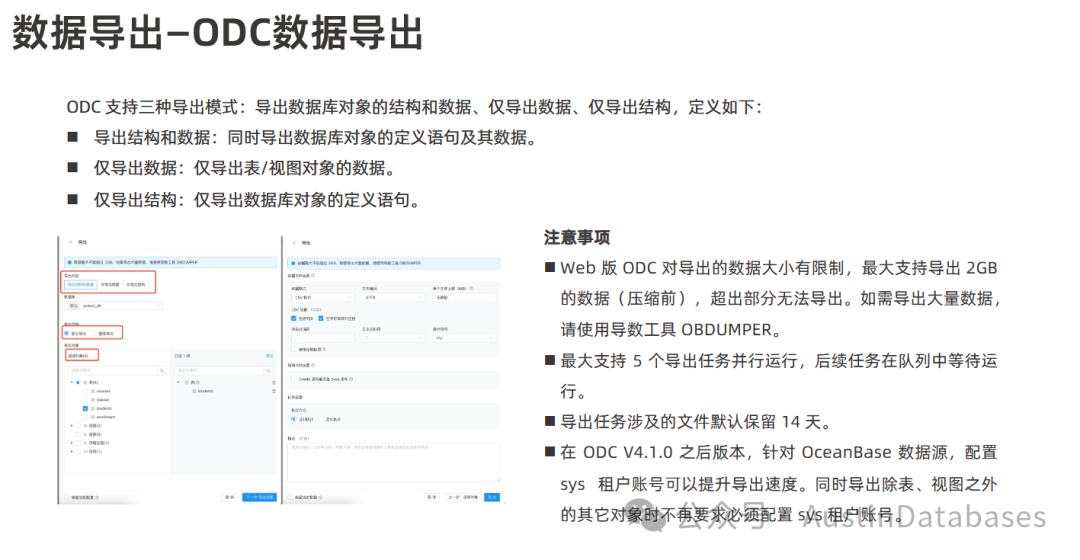
ODC 提供三种导出方式:
1 导出结构和数据: 同时导出数据库对象的定义语句及其数据。
2 仅导出数据: 仅导出表和视图对象的数据。
3 仅导出结构: 仅导出数据库对象的定义语句。 用户可以在 ODC 中选择对应的数据表,创建一个导出任务即可将数据导出。
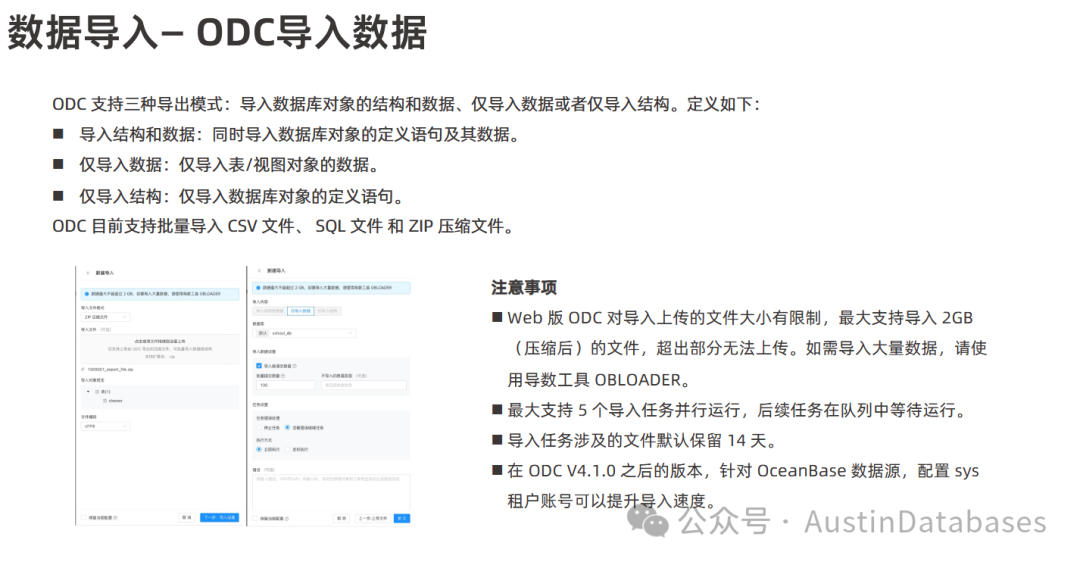
数据导入: ODC 支持三种导入方式:
1 导入结构和数据: 同时导入数据库对象的定义语句及其数据。
2 仅导入数据: 仅导入表视图对象的数据。
3 仅导入结构: 仅导入数据库对象的定义语句。 用户需要在 ODC 中选择需要导入的数据文件,然后选择导入的目标数据表,完成数据导入。
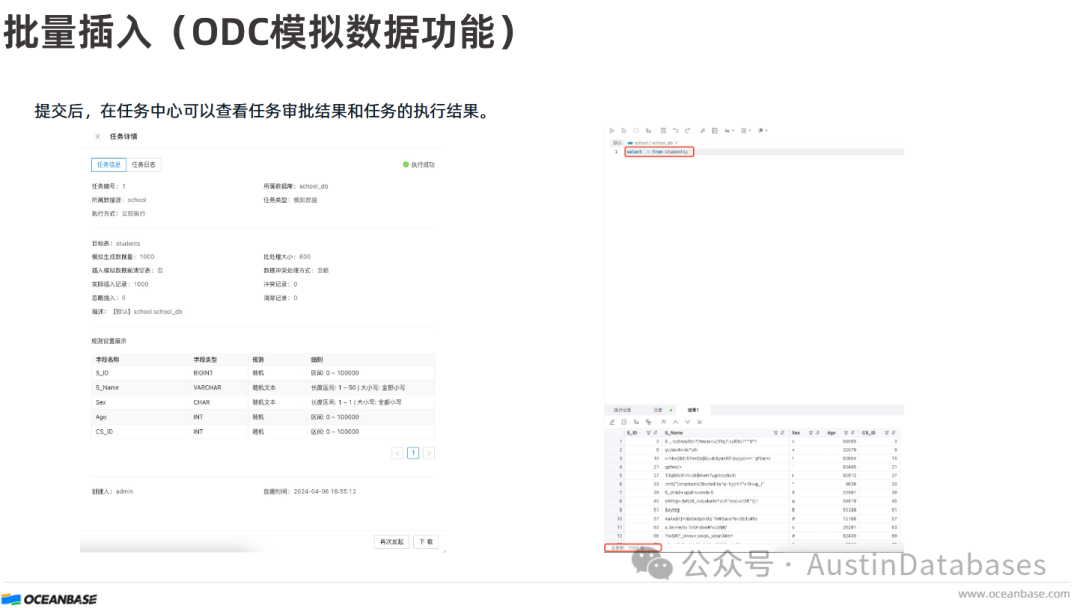
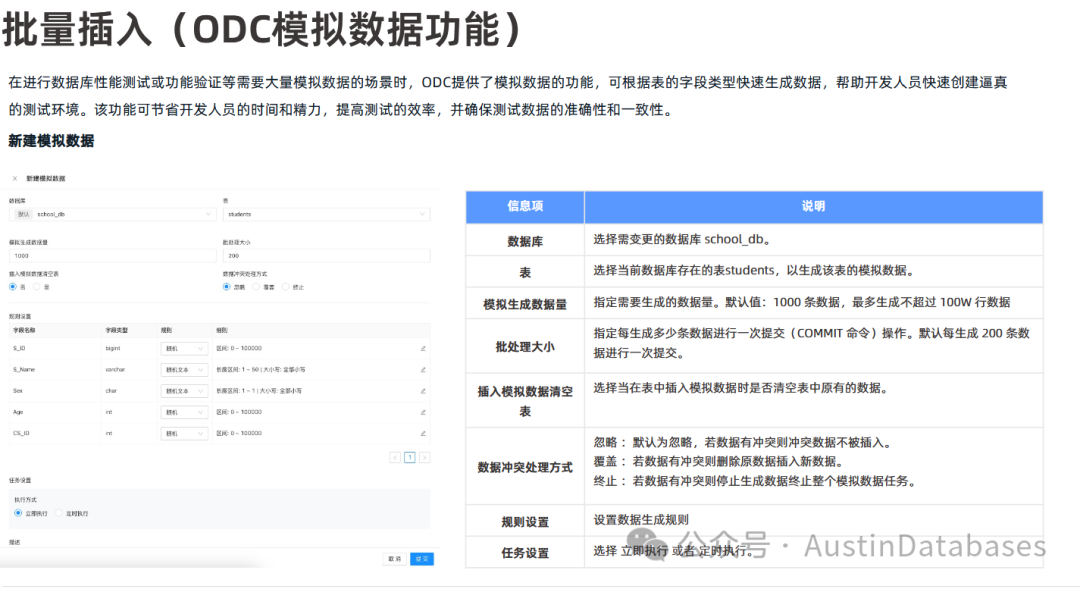
模拟插入数据: ODC 提供了模拟插入数据的功能,可以自动在测试的数据表中插入指定的记录数,提升开发人员的工作效率。用户在 ODC 中选择新建模拟数据,打开窗口后选择对应的数据库数据表,输入模拟生成的数据量,然后对表中的数据列选择相应的数据生成方式,最后点提交即可。
特点:
1 图形化工具: 提供图形化界面,操作相对简单。
2 支持 MySQL 和 Oracle 两种类型的租户。
3 提供结构和数据的不同导出/导入选项。
4 具备模拟数据生成等辅助开发的功能。
OBDUMPER
OB Dumper 是一个功能很强的命令行工具。它可以部署在应用服务器之上,在导出数据时可以指定一些选项,将数据按要求进行导出。OB Dumper 是一种使用 Java 语言开发的客户端工具。在功能性和性能方面相较于常见的 MySQL、Dumper 等工具有明显的优势。
核心功能:支持把数据库里的对象结构 DDL 进行导出。支持将数据表中的数据导出为 CSV 或 SQL 的格式。 支持按分区名称导出某一个分区的数据。支持简单的数据处理规则,在数据导出时进行处理。可以生成导出任务的控制文件,该控制文件中定义了导出字段和处理规格。
环境配置: 由于是 Java 开发,OB Dumper 依赖 Java 环境,需要安装 JDK1.8。为提高数据导出的性能,需要调整 JVM 的内存大小。导出数据的数据库用户需要相应的数据库权限,例如数据表的查询以及创建 CBA 权限等。使用 OB Dumper 进行数据导出时,需要指定数据库的 IP 地址、端口、用户名、密码以及导出的数据表名称、导出的数据格式等信息.
参数说明:
-H: 指定数据库服务器的 IP 地址,一般是 OB Proxy 的 IP 地址。
-P: 指定数据库服务器的端口号,例如 2883。
-U: 指定数据库的用户名。
-p: 指定数据库用户的密码。
-F: 指定数据库导出的目录。
--ddl: 表示导出数据表或者对象的 DDL 结构。
--csv: 表示数据导出的格式为 CSV 格式。
--sql: 表示数据导出的格式为 SQL 格式。
案例:
导出 user_a 中所有对象的 DDL 结构: 命令中指定 --ddl 参数。
导出 user_a 中所有对象的数据,导出格式为 SQL: 命令中指定 --sql 参数。
导出 user_a 中所有对象的数据,导出格式为 CSV: 命令中指定 --csv 参数。
特点:
通过命令行进行操作,支持导出 DDL、数据,并可以指定导出格式和分区, 相较于常见的 MySQL、Dumper 等工具有明显的优势,支持数据处理规则和控制文件,提供更灵活的导出方式。
ODC 是一款图形化的企业级数据库开发平台,提供了便捷的数据导入导出功能,并且具备模拟数据生成等辅助开发特性,适合开发人员日常使用.OBDUMPER 是一款命令行工具,功能更加强大,支持多种导出格式、按分区导出以及数据处理规则等高级特性,更适合需要自动化或者更精细化控制的导出场景. 两者都是 OceanBase 数据库进行数据导入导出常用的工具,










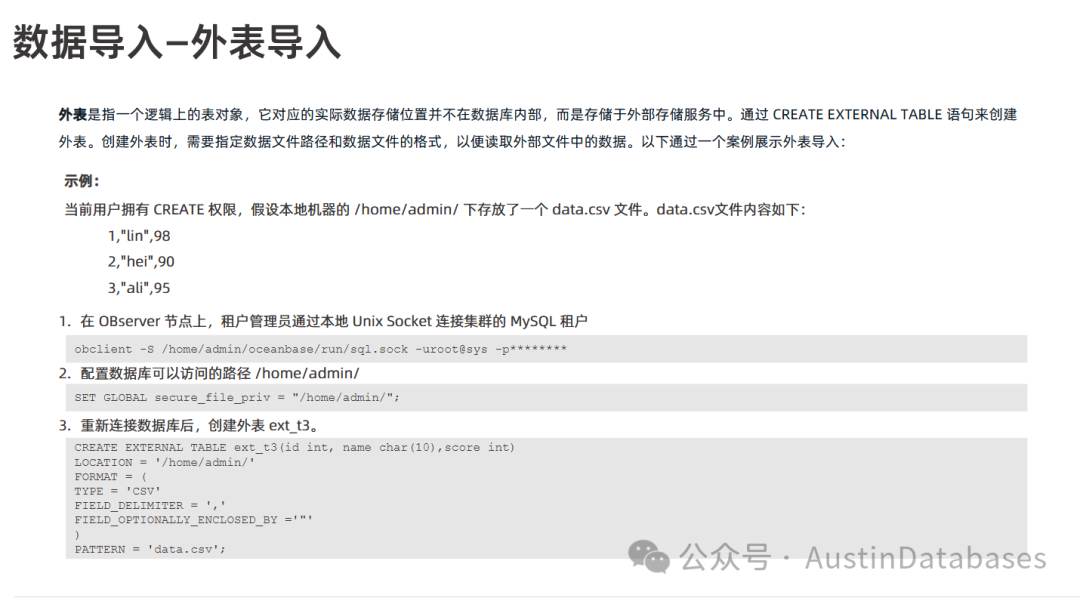
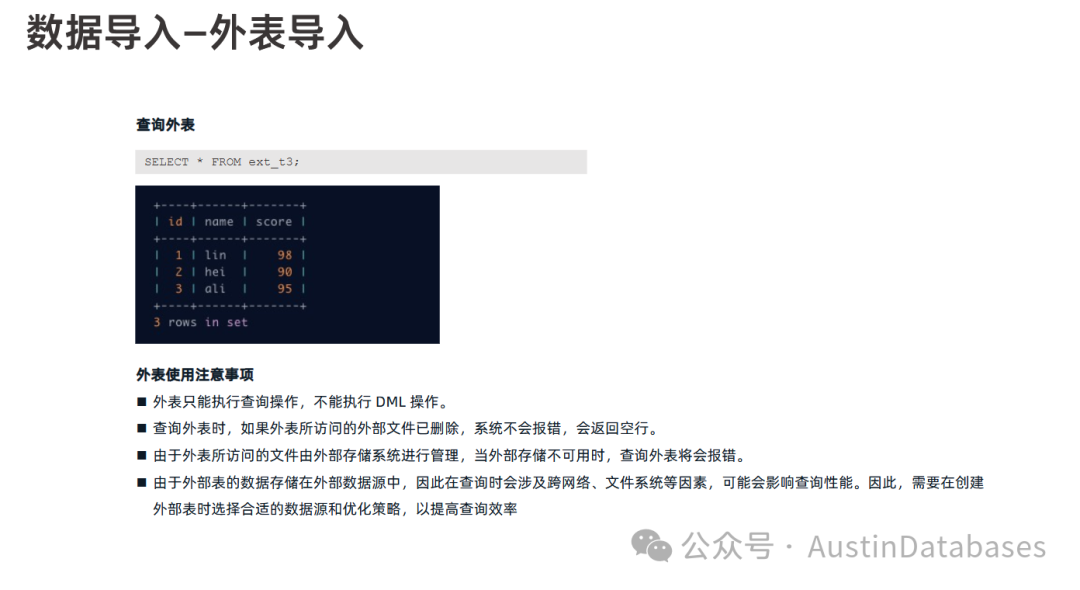
OBLOADER 是欧贝斯数据库提供的一个功能强大的命令行工具,专门用于数据导入。它与 OBDUMPER 工具(用于数据导出)是一组工具。 以下是关于 OBLOADER 工具的一些关键信息:
功能:
支持导入数据库对象的 DDL 结构,支持导入 CSV 和 SQL 格式的数据文件,具备限流和防导爆等特性,以确保在大数据量导入期间不会将租户的 map table 写满。支持通过配置简单的数据清洗规则对导入的数据进行处理。
适用场景:
在需要将外部文件(如 OBDUMPER 导出的 SQL 或 CSV 文件)导入到 OceanBase 数据库时使用。适用于需要进行大数据量导入的场景,其限流和防导爆特性可以保证系统的稳定性。可以通过配置数据清洗规则,在导入过程中对数据进行初步处理。
环境配置:
运行环境: 由于 OBLOADER 是使用 Java 开发的,因此依赖 Java 环境,需要安装 JDK 1.8。
性能优化: 为了提高数据导入的性能,可能需要调整 JVM 的运行内存大小。
数据库权限: 执行数据导入的数据库用户需要相应的数据库权限,例如数据表的写入、更新以及创建的权限,或者 DBA 的权限。
使用方法:
使用 OBLOADER 进行数据导入时,需要指定数据库的 IP 地址(通常是 OB Proxy 的 IP 地址)、端口号(通常是 2883)、用户名、密码以及导入的数据表名称和导入的数据格式等信息。
常用的命令行参数包括:
-H: 指定数据库服务器的 IP 地址。
-P: 指定数据库服务器的端口号,例如 2883。
-U: 指定数据库的用户名。
-t: 指定数据库用户的密码。
-F: 指定数据导入的目录。
-DDL: 表示导入数据表或者对象的 DDL。
-CSV: 表示数据导入的格式为 CSV 格式。
-SQL: 表示数据导入的格式为 SQL 格式。
使用示例:
导入 user a 中所有对象的 DDL 结构,命令中指定导入格式为 DDL 参数。
导入 user a 中所有对象的数据,导入格式为 CSV,命令中指定格式为 CSV 参数。
导入 user a 中所有对象的数据,导入格式为 SQL,命令中指定格式为 SQL 参数。 总而言之,OBLOADER 是 OceanBase 数据库中用于高效、稳定地导入 SQL 或 CSV 格式数据的命令行工具。它需要 Java 环境支持,并且执行导入操作的用户需要具备相应的数据库权限。使用时需要通过命令行参数指定数据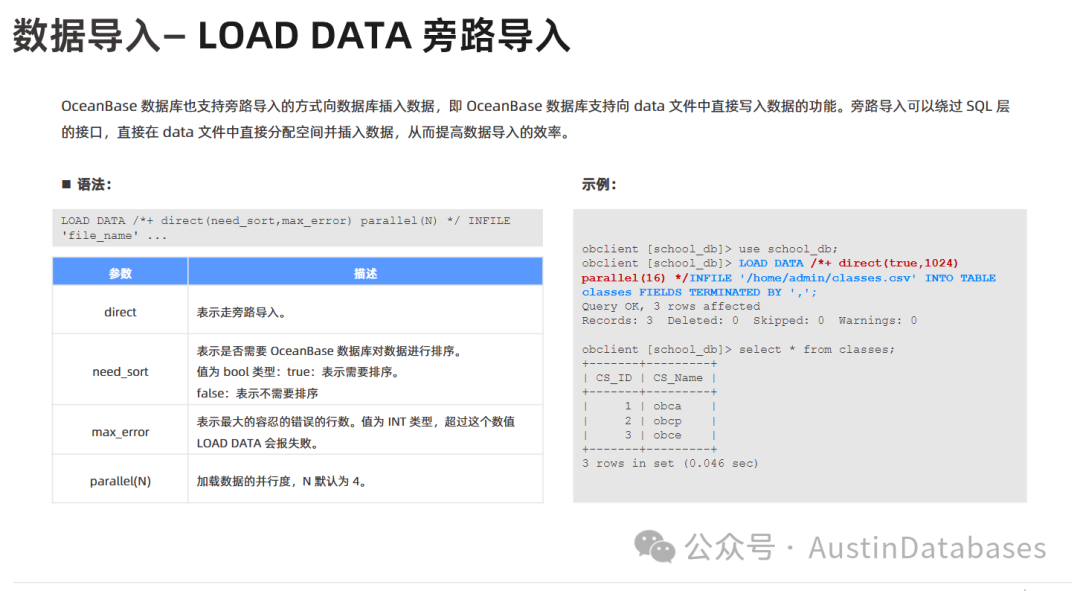


跟我学OceanBase4.0 --阅读白皮书 (OB分布式优化哪里了提高了速度)
跟我学OceanBase4.0 --阅读白皮书 (4.0优化的核心点是什么)
跟我学OceanBase4.0 --阅读白皮书 (0.5-4.0的架构与之前架构特点)
跟我学OceanBase4.0 --阅读白皮书 (旧的概念害死人呀,更新知识和理念)
PostgreSQL 相关文章
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
全世界都在“搞” PostgreSQL ,从Oracle 得到一个“馊主意”开始
PostgreSQL 加索引系统OOM 怨我了--- 不怨你怨谁
PostgreSQL “我怎么就连个数据库都不会建?” --- 你还真不会!
PostgreSQL 稳定性平台 PG中文社区大会--杭州来去匆匆
PostgreSQL 分组查询可以不进行全表扫描吗?速度提高上千倍?
POSTGRESQL --Austindatabaes 历年文章整理
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
PolarDB 相关文章
“PostgreSQL” 高性能主从强一致读写分离,我行,你没戏!
POLARDB 添加字段 “卡” 住---这锅Polar不背
PolarDB 版本差异分析--外人不知道的秘密(谁是绵羊,谁是怪兽)
PolarDB 答题拿-- 飞刀总的书、同款卫衣、T恤,来自杭州的Package(活动结束了)
PolarDB for MySQL 三大核心之一POLARFS 今天扒开它--- 嘛是火
MongoDB 大俗大雅,上来问分片真三俗 -- 4 分什么分
MongoDB 大俗大雅,高端知识讲“庸俗” --3 奇葩数据更新方法
MongoDB 大俗大雅,高端的知识讲“通俗” -- 2 嵌套和引用
MongoDB 大俗大雅,高端的知识讲“低俗” -- 1 什么叫多模
MongoDB 合作考试报销活动 贴附属,MongoDB基础知识速通
MongoDB 使用网上妙招,直接DOWN机---清理表碎片导致的灾祸 (送书活动结束)
MongoDB 2023年度纽约 MongoDB 年度大会话题 -- MongoDB 数据模式与建模

