




计算下推
MySQL是一个多引擎数据库,在存储引擎和SQL计算层之间定义了清晰的数据访问接口,同时存储引擎和SQL计算引擎的行数据组织格式也有不同。这带来的好处是,存储引擎可以方便地对接MySQL。但同时也导致SQL层和存储引擎层缺少融合,不能充分利用存储引擎的特性来规避存储引擎一些较大的开销。
下图是社区MySQL在处理Limit Offset、Count时的逻辑,引擎层需要逐行扫描获取转换为SQL层数据格式,传递给SQL层。而SQL层对Offset的数据行在没有额外谓词情况下就会直接skip掉,对于Count也仅仅是计数。
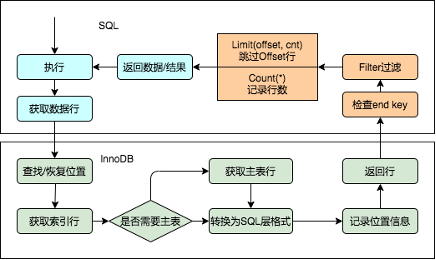
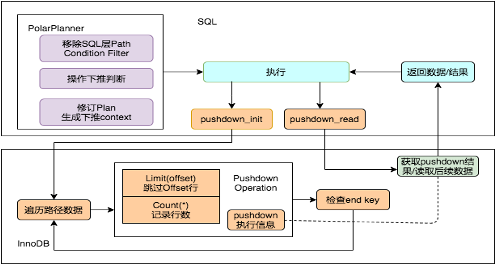
PolarDB MySQL针对InnoDB引擎做了很多的优化,可以将一些计算下推到存储引擎从而极大的提升性能。例如Limit Offset、Count、谓词等计算下推到引擎层后可以带来的好处有:
降低SQL层与引擎层交互的开销。
减少记录、恢复行位置的开销。
减少数据转换为SQL层格式的开销。
减少部分场景访问主表的开销。
计算下推在Limit Offset、Count的客户场景中可以获取的性能提升如下:
| 下推操作 | 是否回表 | 性能提升 |
|---|---|---|
| Limit | 否 | 6.69X |
| 是 | 75.90X | |
| Count | 否 | 2.38X |
自适应优化
在前面文章 MySQL查询优化分析 - 常见慢查问题与优化方法 中,我们提到了一些场景的慢查是由于优化器无法感知实际数据分布而导致计划选择错误。由于优化器无法感知真实数据情况导致估算偏差,最优计划和很差的计划之间代价可能差异不大。有时客户在业务验证期间发现这类问题,而有时会等业务迁移或者统计信息发生一些改变到临界点后,优化器才突然选择很差的计划从而影响业务。
我们可以看之前文章提到的场景,这类Order by Limit语句优化器选择提供ordering序的索引,而ordering序索引是否是较优的计划完全和用户数据的分布相关。这类问题在优化器行列路由选择中也会遇到,由于估算不准导致没有将慢查路由给列存执行。
--优化器认为索引i_c1仅需要扫描877行就能遇到满足条件的数据行。
--但实际满足条件的行在索引末尾,需要扫描166w行
mysql> EXPLAIN SELECT * FROM t9 WHERE c2 > 90100 AND c2 < 92000 ORDER BY c1 LIMIT 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t9
partitions: NULL
type: index
possible_keys: i_c2
key: i_c1
key_len: 9
ref: NULL
rows: 877
filtered: 0.11
Extra: Using where
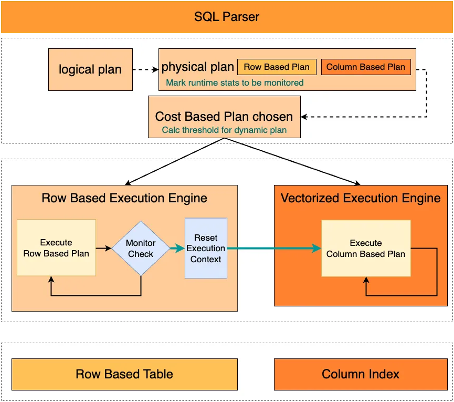
为了解决这一问题,PolarDB在优化器中会标记这类无法感知真实数据分布仅做推算的信息,在执行阶段收集真实扫描行数等信息。当真实执行达到优化器预先评估的阈值后,就会触发计划的切换。下图是自适应执行在行列路由中的应用。相关参数loose_adaptive_plans_switch有imci_chosen和ordering_index两个开关,分别控制自适应执行在行列路由和ordering index选择上的使用。
Fast Query Cache
Fast Query Cache也是PolarDB MySQL研发的一项功能,做了大量无锁设计和自适应优化,能够支持高并发,能够使业务享受缓存命中带来的性能提升而无需担心有不适配场景使业务性能受影响。
社区MySQL的Query Cache是2001年引入,其对现代硬件的多核并发支持非常差,社区在MySQL 8.0将其移除。
PolarDB设计实现的Fast Query Cache功能,有以下特点:
极致并发能力。没有任何全局锁,主要缓存结构使用无锁HASH。失效和淘汰使用版本号和引用计数处理,相关行为简化为一个原子操作。
动态的内存使用和回收。维护LRU链表,缓存命中时间、lease时间。
支持集群架构。支持一主多读、多主等架构,集群代理访问。
正确性保证。各个场景设计、全量测试回归等等保证结果正确性。
自适应缓存。自适应控制模块记录了缓存命中收益、缓存额外开销,根据负载实际情况动态调整缓存策略。
其在sysbench压测下的读性能提升如下。
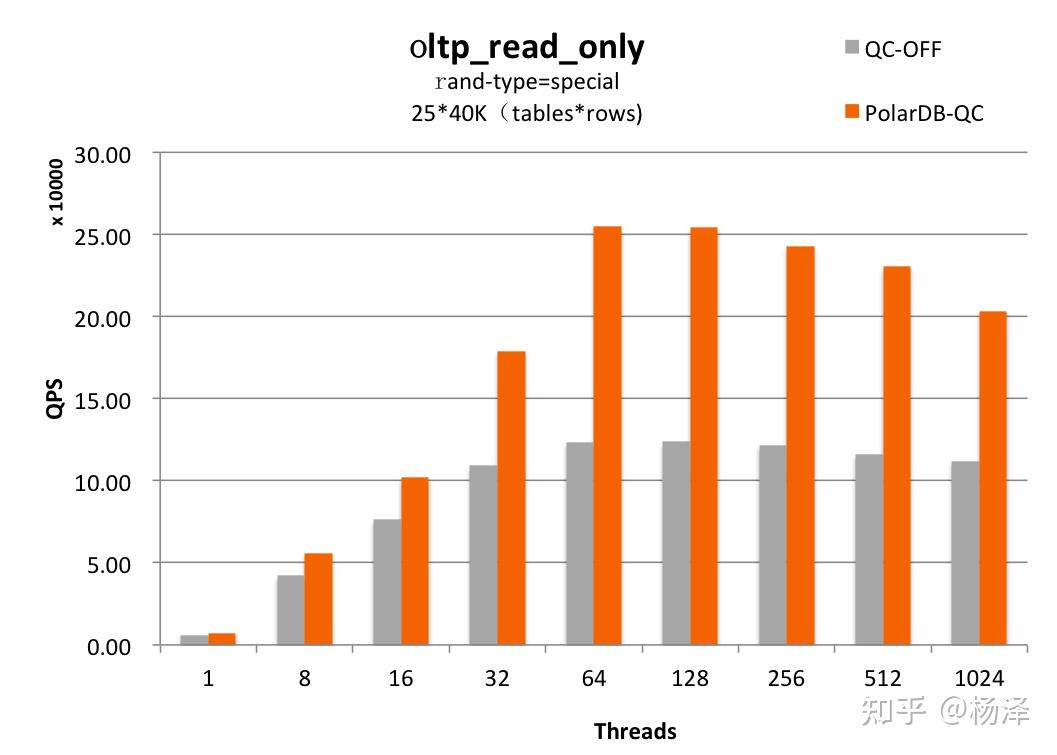
目前在最新版本的PolarDB MySQL中Fast Query Cache默认打开。各类客户业务场景都有很好的收益,缓存命中率往往在30%-60%,甚至更高。这些业务系统示例:营销系统,数据导入后更新少;教育行业,学生名单、成绩等很少更新;对于订单系统,其地理信息表、商品类目表、供应商表、用户表较少更新,也可以有不错的命中率。
Auto Plan Cache
执行计划的选择需要考虑诸多因素,如统计信息、不同的连接顺序和不同的查询变换等。对于不同的查询语句,其优化时间不同,可能会存在某些SQL语句的查询优化时间在整体执行时间中占比很大的情况。如果这类SQL语句执行的次数较多,就会因为优化时间占比大导致系统负载增加。
为了提升优化时间占比太多的SQL语句的查询性能,降低系统负载,PolarDB MySQL版提供了Auto Plan Cache功能。Auto Plan Cache功能提供了AUTO、DEMAND和ENFORCE三种模式。用户可以根据需要将loose_plan_cache_type参数设置为三种模式中的任意一种模式,推荐模式为AUTO,将SQL语句的执行计划缓存在Plan Cache中,以减少执行查询语句时的优化时间,提升查询性能。当缓存在Plan Cache中的执行计划涉及的表的统计信息发生变化,或对缓存中执行计划引用的表执行了DDL操作时,缓存的执行计划会自动失效。
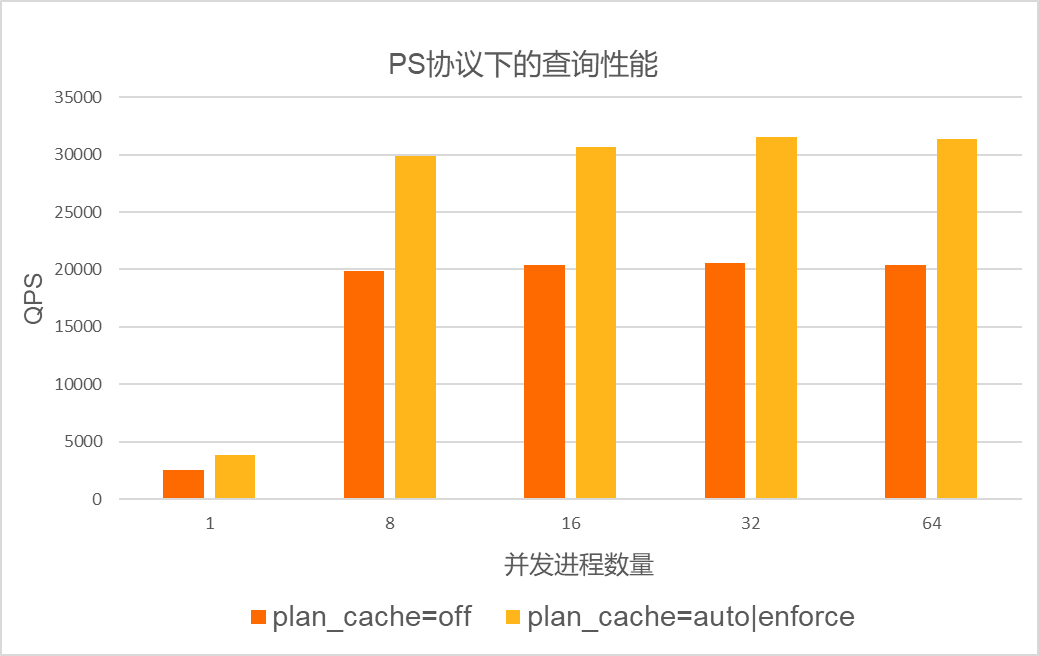
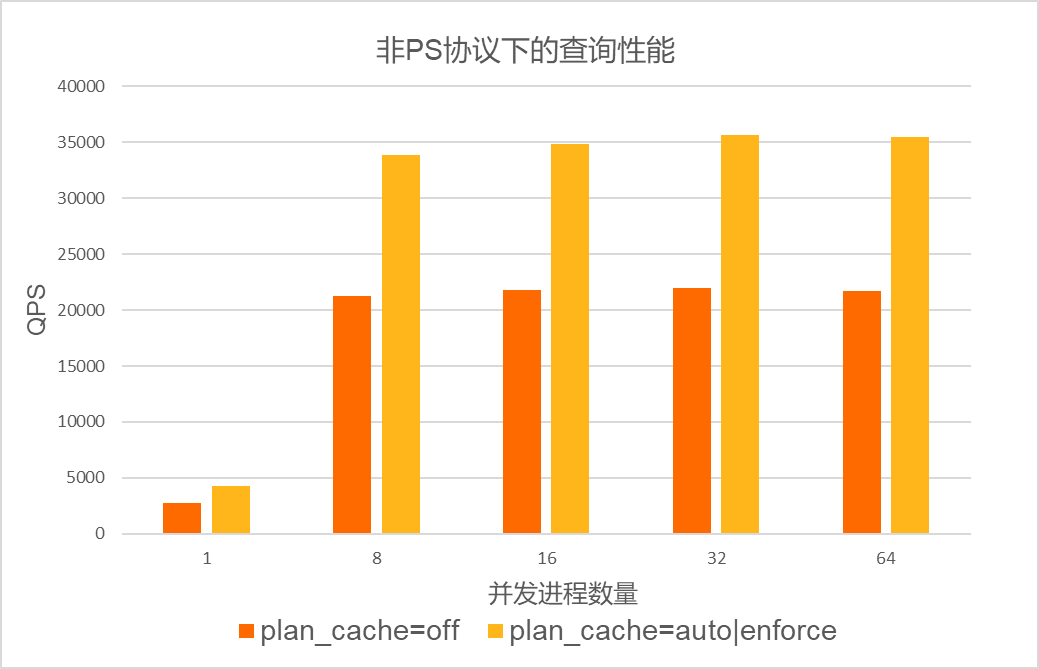
对于优化时间占比较多的场景,例如in list场景。在集群规格为8核32 GB,数据库中已创建25张表,单张表存储400万行数据的场景下进行压测。压测使用的SQL语句为:SELECT id FROM sbtestN WHERE k IN(...),其中,IN LIST的长度为20。在PS协议和非PS协议下,测试loose_plan_cache_type参数配置为OFF、AUTO和ENFORCE时的性能。测试结果如下:
- PS协议下的性能测试结果如下:
- 非PS协议下的性能测试结果如下:
常用的辅助功能
Outline固定执行计划
Outline是一个用于后台固定执行计划的功能。优化器是基于统计信息估算代价选择最优计划,其无法得知真实执行时的各种数据情况,也就无法保证能一直选择到正确的执行计划。对于自适应执行优化,也难以处理所有的复杂查询,数据分布场景。当在生产环境中,发生计划选择错误问题,如果要求数据库管理员在业务SQL中固定执行计划会面临诸多挑战:
发布流程的复杂性:在应用程序中手动添加HINT,并且每次调整HINT都需要发布新的应用版本,这不仅耗时耗力,还可能带来额外的风险。
添加HINT的复杂性:一些应用的SQL是通过中间件自动生成的,手动添加HINT既不现实又十分繁琐。
HINT管理的复杂性:在应用程序中添加了大量HINT后,管理成本随之增加,数据库管理员难以清晰了解整个系统中存在的HINT数量。
而用于后台固定执行计划的Outline功能允许数据库管理员在后台固定特定SQL语句的执行计划,并对这类SQL的HINT进行添加和修改。Outline提供了以下优势:
独立于应用程序:无需修改应用程序代码,也无需重新发布,仅在数据库层面进行配置即可生效。
快速响应和调整:及时响应并调整执行计划,以有效解决慢SQL问题,提升系统的稳定性与性能。
精细化控制和管理:为不同的SQL提供相应的Outline,可以清晰呈现整个系统的Outline及其状态(例如命中情况、是否开启等)。
Outline是根据语句模板匹配,同一个查询模板不同的常量值会匹配同一个规则。具体使用方法可以查看PolarDB MySQL的官网文档 计划固化 (Statement Outline)。
Concurrency Control(CCL)
CCL是一个基于SQL语句做并发控制的功能。在生产环境中,可能会遇到以下场景:
突发的数据库访问流量,导致数据库活跃线程数非常大,数据库Hang死。
消耗资源大的SQL,大并发执行。
一些SQL执行消耗的资源突然大幅增加,可能计划变差或者导入大量数据,数据量突然变化。
CCL就可以对SQL做并发控制,避免大的并发把使数据库雪崩,也可以在问题排查与处理期间控制业务影响范围。
CCL支持按照语句模板匹配、Schema\Table匹配、命令类型匹配多种方式。对触发最大并发限制后的行为,可以配置拒绝或者等待。其具体使用方法可以查看PoalrDB MySQL官网文档 Concurrency Control。
SQL Trace
在数据库使用过程中,面对负载的持续高位,我们可能会需要查看消耗负载比较大的TopSQL。当一条查询语句的性能突然下降,我们可能需要排查语句的执行计划是否变化,语句执行时扫描行数、物理IO读是否明显变化。
PolarDB MySQL版提供的SQL Trace功能,会跟踪SQL语句的各类执行信息,如:执行计划和执行统计信息(包括扫描行数、执行时间等)。可以帮助用户快速地发现因执行计划变更而引发的性能变化,统计当前集群中消耗负载较大的TopSQL。
当开启SQL Trace后,在查询优化阶段会记录当前查询选择的执行计划,包含了索引路径和访问方式的选择、JOIN ORDER、选择的查询变换等,还包含了是否选择并行执行、IMCI列存执行。
在执行阶段会收集执行时的统计信息,包含了等待时间、执行时间、返回行数、扫描行数、影响行数、逻辑读次数、物理同步读次数、物理异步读次数的总值、最小值、最大值,还有总的执行次数、第一次执行时间和最后一次执行时间等信息。同时会记录是普通执行方式还是Prepare/Execute方式。如果是命中query cache直接返回也会记录下来。
SQL Trace的信息存储在SQL Sharing的基础组件中,后台线程会根据SQL Trace的引用时间和过期时间判断是否可以回收。同时用户可以通过接口来控制SQL Trace的记录。
- 获取指定SQL的执行信息和执行计划信息。
SELECT * FROM information_schema.sql_sharing WHERE sql_id = polar_sql_id('select * from t');
- 分别获取按照总执行时间、平均执行时间和总扫描行数三个维度Top10的SQL语句。
SELECT * FROM information_schema.sql_sharing WHERE TYPE='sql' ORDER BY SUM_EXEC_TIME DESC LIMIT 10;
SELECT * FROM information_schema.sql_sharing WHERE TYPE='sql' ORDER BY SUM_EXEC_TIME/EXECUTIONS DESC LIMIT 10;
SELECT * FROM information_schema.sql_sharing WHERE TYPE='sql' ORDER BY SUM_ROWS_EXAMINED DESC LIMIT 10;
SQL Trace功能具体使用方法可以查看PoalrDB MySQL官网文档 SQL Trace。
总结
本文介绍了PolarDB MySQL对查询加速与优化做的一些功能,用户可以根据自己的需要选择适合的功能。例如:业务慢查希望有几倍的性能提升,又有较多的计算资源,可以尝试并行执行做加速;当业务是分析类查询,可以尝试选择列存加速。
在MySQL查询优化分析这个系列的文章中,我们介绍了MySQL优化执行的基础概念、常用分析方法、常见慢查问题与优化方法、PolarDB MySQL的查询加速与优化。希望读者能够通过这些文章,对查询优化分析有更多了解,使用PolarDB有更好的体验。
相关资料
弹性并行查询(Elastic Parallel Query) https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/elastic-parallel-query/
列存索引(IMCI) https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/imcis/
查询改写 https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/query-rewrite/
Fast Query Cache https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/fast-query-cache
计算下推 https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/computing-pushdown/
Auto Plan Cache https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/auto-plan-cache?spm=a2c4g.11186623.help-menu-2249963.d_5_15_1_1.418023d122lFoR
计划固化 (Statement Outline)https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/statement-outline
Concurrency Control https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/concurrency-control
