




3.2. RTO
分布式数据库的核心特点就是高可用,集群中任何一个节点的故障都不影响整体的可用性。针对同机房场景部署一主两备的3节点典型部署形态,我们尝试对对一下三种场景进行可用性的测试:
- 中断主库,然后重启,观察过程中集群恢复可用性的RTO时间
- 中断任意一个备库,然后重启,观察过程中主库的可用性表现
3.2.1. 主库宕机+重启
无负载情况下, kill leader, 监控集群各节点状态变化以及是否可写,
| 步骤 | MGR | DN |
|---|---|---|
| 起始正常 | 0 | 0 |
| kill leader | 0 | 0 |
| 发现异常节点时间 | 5 秒 | 5 秒 |
| 3节点降为2节点时间 | 23 秒 | 8 秒 |
| 步骤 | MGR | DN |
| 起始正常 | 0 | 0 |
| kill leader,自动拉起 | 0 | 0 |
| 发现异常节点时间 | 5 秒 | 5 秒 |
| 3节点降为2节点时间 | 23 秒 | 8 秒 |
| 2节点恢复3节点时间 | 37 秒 | 15 秒 |
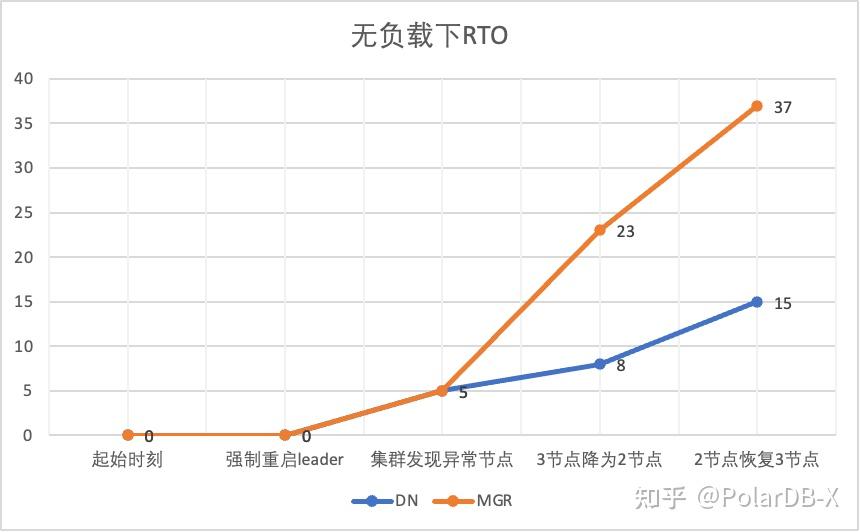
从测试结果可以看出,在无压力的情况下:
- DN的RTO在8-15s, 降为2节点需要8s,恢复3节点需要15s;
- MGR的RTO在23-37s, 降为2节点需要23s,恢复3节点需要37s
- RTO表现DN整体优于MGR
3.2.2. 备库宕机+重启
使用sysbench进行oltp_read_write场景下16个线程的并发压测,在图中第10s的时刻,手动kill一个备节点,观察sysbench的的实时输出TPS数据。
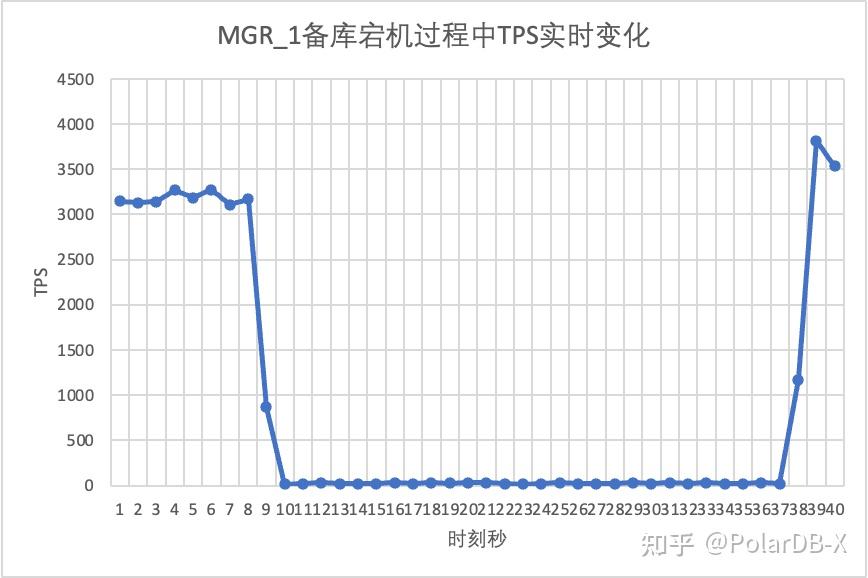
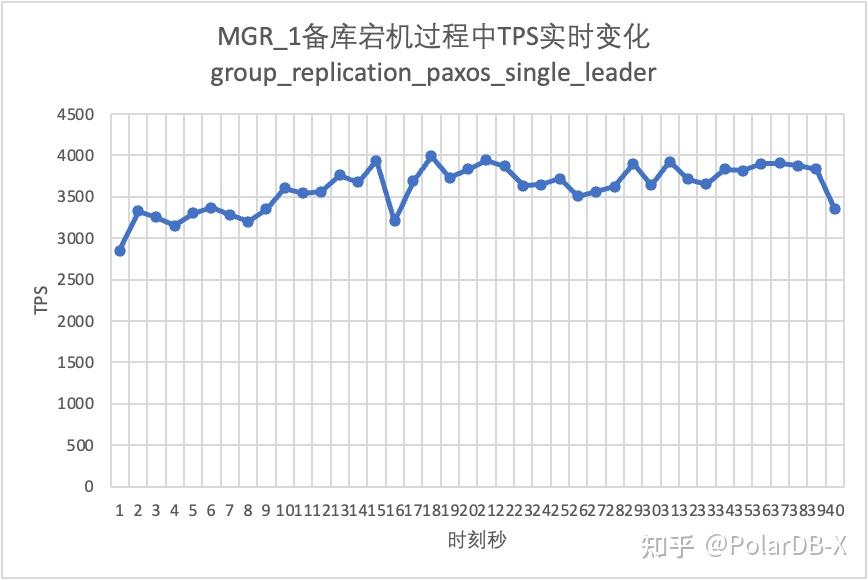
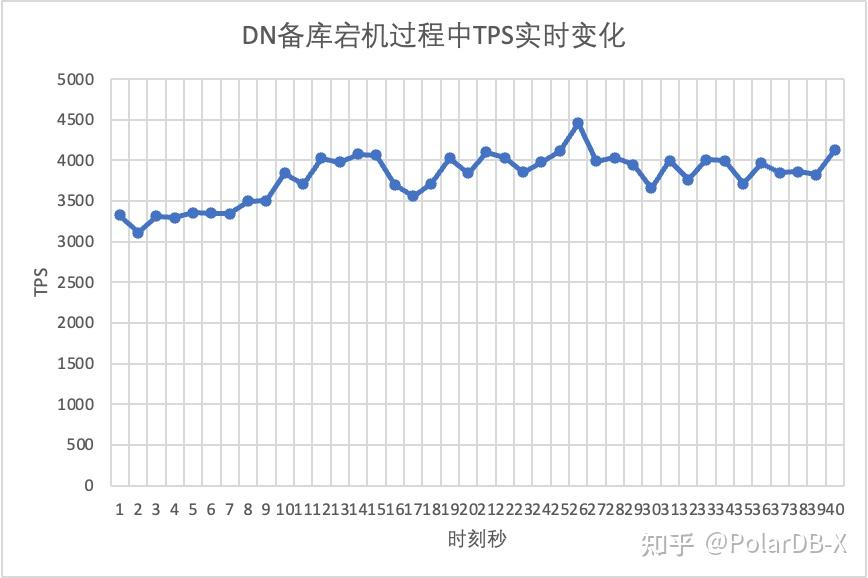
从测试结果图中可见:
- 中断备库后,MGR的主库TPS大幅下降,持续20s左右才恢复正常水平。根据日志分析,这里经历了检测故障节点变成unreachable状态、将故障节点踢出MGR集群两个过程。这个测试证实了MGR社区流传很久的一个缺陷,在3节点中即使只有1个节点不可用,整个集群就有一段时间的剧烈抖动不可用
- 针对单主时MGR存在单节点故障整个实例不可用的问题,社区从8.0.27中引入了MGR paxos single leader功能解决,但默认关闭。 这里我们将group_replication_paxos_single_leader开启后继续验证,这次中断备库后主库性能保持稳定,并且稍微还有所提升了,原因应该与网络负载降低有关
- 对于DN,中断备库后,主库TPS反而立刻上升约20%, 随后一直保持稳定,集群也一直处于可用状态。这里和MGR相反的表现,原因是中断一个备库后主库每次只用向剩下一个备库发送日志,网络收发包流程效率更高了
继续测试,我们将备库重启恢复,观察主库TPS数据变化:
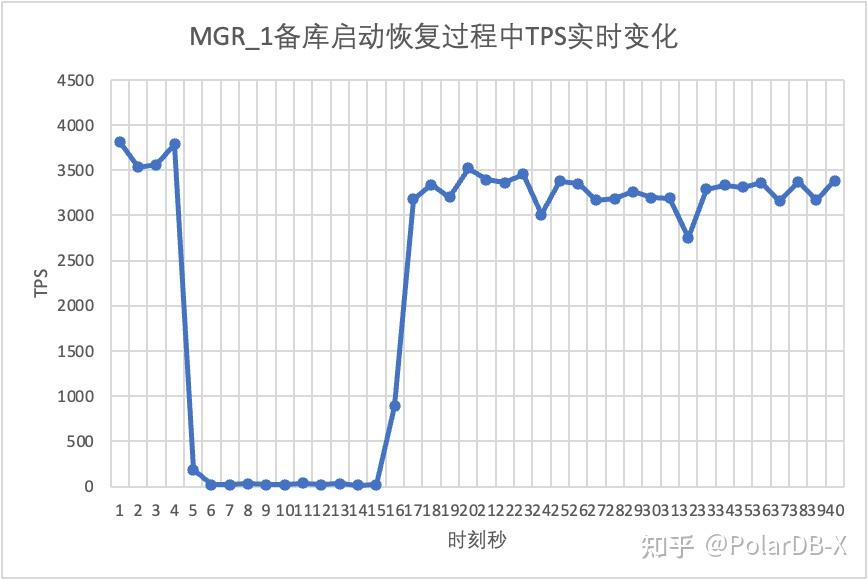
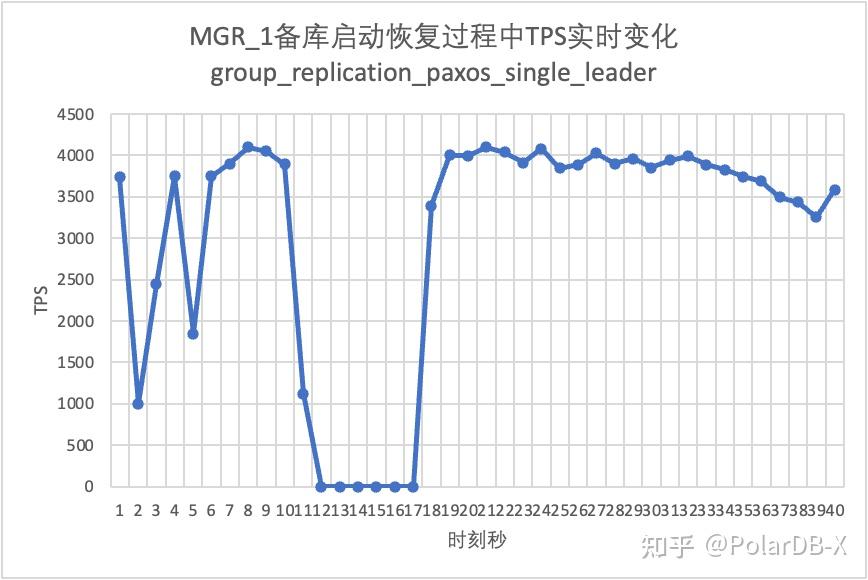
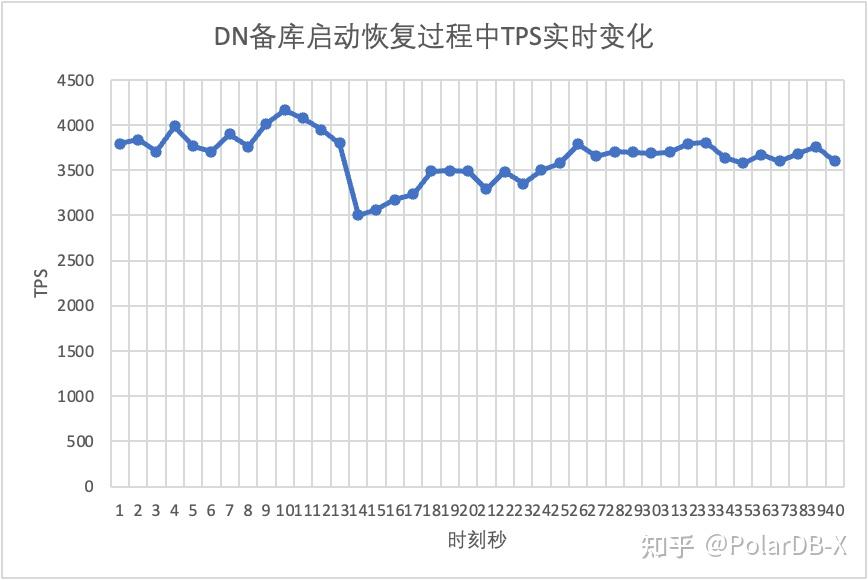
从测试结果图中可见:
- MGR在5s时刻从2节点恢复成3节点,但同样存在着主库不可用, 持续时间大约12s。尽管备库节点最终加入集群,但MEMBER_STATE状态一直为RECOVERING,说明此时正在追数据
- 对group_replication_paxos_single_leader开启后的场景同样进行备库重启的验证,结果MGR在10s时刻从2节点恢复成3节点,但仍然出现了持续时间大约7s的不可用时间,看来这个参数并不能完全解决单主时MGR存在单节点故障整个实例不可用的问题。
- 对于DN,备库在10s时刻从2节点恢复成3节点,主库一直保持可用状态。 这里TPS会有短暂的波动,这个是由于重启后备库日志复制延迟落后较多,需要从主库拉取落后的日志,因此对主库产生少量影响,待日志追评后,整体性能就处于稳定状态。
3.3. RPO
为了构造MGR多数派故障RPO<>0场景,我们使用社区自带的MTR Case方式,对MGR进行故障注入测试,设计的Case如下:
--echo
--echo ############################################################
--echo # 1. Deploy a 3 members group in single primary mode.
--source include/have_debug.inc
--source include/have_group_replication_plugin.inc
--let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
--let $rpl_group_replication_single_primary_mode=1
--let $rpl_skip_group_replication_start= 1
--let $rpl_server_count= 3
--source include/group_replication.inc
--let $rpl_connection_name= server1
--source include/rpl_connection.inc
--let $server1_uuid= `SELECT @@server_uuid`
--source include/start_and_bootstrap_group_replication.inc
--let $rpl_connection_name= server2
--source include/rpl_connection.inc
--source include/start_group_replication.inc
--let $rpl_connection_name= server3
--source include/rpl_connection.inc
--source include/start_group_replication.inc
--echo
--echo ############################################################
--echo # 2. Init data
--let $rpl_connection_name = server1
--source include/rpl_connection.inc
CREATE TABLE t1 (c1 INT PRIMARY KEY);
INSERT INTO t1 VALUES(1);
--source include/rpl_sync.inc
SELECT * FROM t1;
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
SELECT * FROM t1;
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
SELECT * FROM t1;
--echo
--echo ############################################################
--echo # 3. Mock crash majority members
--echo # server 2 wait before write relay log
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
--echo # server 3 wait before write relay log
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
--echo # server 1 commit new transaction
--let $rpl_connection_name = server1
--source include/rpl_connection.inc
INSERT INTO t1 VALUES(2);
# server 1 commit t1(c1=2) record
SELECT * FROM t1;
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 1 crash
--source include/kill_mysqld.inc
--echo # sleep enough time for electing new leader
sleep 60;
--echo
--echo # server 3 check
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
SELECT * FROM t1;
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 3 crash and restart
--source include/kill_and_restart_mysqld.inc
--echo # sleep enough time for electing new leader
sleep 60;
--echo
--echo # server 2 check
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
SELECT * FROM t1;
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 2 crash and restart
--source include/kill_and_restart_mysqld.inc
--echo # sleep enough time for electing new leader
sleep 60;
--echo
--echo ############################################################
--echo # 4. Check alive members, lost t1(c1=2) record
--echo # server 3 check
--let $rpl_connection_name= server3
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 3 lost t1(c1=2) record
SELECT * FROM t1;
--echo
--echo # server 2 check
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 2 lost t1(c1=2) record
SELECT * FROM t1;
!include ../my.cnf
[mysqld.1]
loose-group_replication_member_weight=100
[mysqld.2]
loose-group_replication_member_weight=90
[mysqld.3]
loose-group_replication_member_weight=80
[ENV]
SERVER_MYPORT_3= @mysqld.3.port
SERVER_MYSOCK_3= @mysqld.3.socketCase运行结果如下:
############################################################
# 1. Deploy a 3 members group in single primary mode.
include/group_replication.inc [rpl_server_count=3]
Warnings:
Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
[connection server1]
[connection server1]
include/start_and_bootstrap_group_replication.inc
[connection server2]
include/start_group_replication.inc
[connection server3]
include/start_group_replication.inc
############################################################
# 2. Init data
[connection server1]
CREATE TABLE t1 (c1 INT PRIMARY KEY);
INSERT INTO t1 VALUES(1);
include/rpl_sync.inc
SELECT * FROM t1;
c1
1
[connection server2]
SELECT * FROM t1;
c1
1
[connection server3]
SELECT * FROM t1;
c1
1
############################################################
# 3. Mock crash majority members
# server 2 wait before write relay log
[connection server2]
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
# server 3 wait before write relay log
[connection server3]
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
# server 1 commit new transaction
[connection server1]
INSERT INTO t1 VALUES(2);
SELECT * FROM t1;
c1
1
2
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
# server 1 crash
# Kill the server
# sleep enough time for electing new leader
# server 3 check
[connection server3]
SELECT * FROM t1;
c1
1
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
# server 3 crash and restart
# Kill and restart
# sleep enough time for electing new leader
# server 2 check
[connection server2]
SELECT * FROM t1;
c1
1
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
# server 2 crash and restart
# Kill and restart
# sleep enough time for electing new leader
############################################################
# 4. Check alive members, lost t1(c1=2) record
# server 3 check
[connection server3]
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier NULL OFFLINE
# server 3 lost t1(c1=2) record
SELECT * FROM t1;
c1
1
# server 2 check
[connection server2]
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier NULL OFFLINE
# server 2 lost t1(c1=2) record
SELECT * FROM t1;
c1
1复现丢数的Case大概逻辑是这样的:
- MGR由3个节点组成单主模式,Server 1/2/3,其中Server 1为主库,并初始化1条记录c1=1
- 故障注入Server 2/3在写Relay Log时会hang住
- 连接到Server 1节点,写入了c1=2的记录,事务commit也返回了成功
- 然后Mock server1的异常crash(机器故障,不能恢复,无法访问),此时剩下Server 2/3形成多数派
- 正常重启Server 2/3(快速恢复),但是Server 2/3无法恢复集群可用状态
- 连接Server 2/3节点,查询数据库记录,仅看到了c1=1的记录(Server 2/3都丢失了c1=2)
根据以上Case可见,对于MGR,当多数派宕机,主库不可用,备库恢复后,存在数据丢失的RPO<>0的情况,原本已返回客户端commit成功的记录丢了。
而对于DN,多数派的达成需要日志在多数派中都持久化,所以即使在上述场景下,数据也不会丢失,也能保证RPO=0。
3.4. 备库回放延迟
MySQL的传统主备模式下,备库一般会包含IO线程和Apply线程,引入了Paxos协议后替换了IO线程同步主备库binlog的工作,备库的复制延迟主要就看备库Apply回放的开销,我们这里成为备库回放延迟。
我们使用sysbench测试oltp_write_only场景,测试100并发下, 不同event数量时, 备库回放出现延迟的持续时间。备库回放延迟时间通过监控performance_schema.replication_applier_status_by_worker表的APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP列来实时查看各worker是否工作来断定复制是否结束
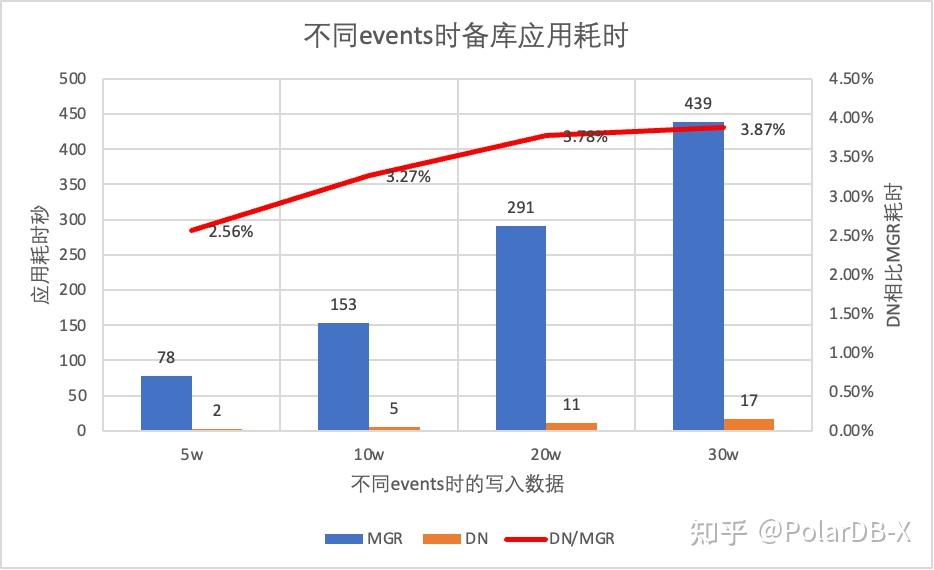
从测试结果图中可见:
- 相同写入数据量下,DN的备库回放所有日志的完成时间远远优于MGR,DN的的耗时仅是MGR的3%~4%。 这对主备切换的及时性十分关键。
- 随着写入数量的增加,DN相比MGR的备库回放延迟优势继续保持,十分稳定。
- 分析备库回放延迟原因,MGR的备库回放策略采用group_replication_consistency默认值为EVENTUAL,即RO和RW事务在执行之前都不等待应用前面的事务。这样可以保证主库写入性能的最大化,但是备库延迟就会比较大(通过牺牲备库延迟和RPO=0来换取主库的高性能写入,开启MGR的限流功能可以平衡性能和备库延迟,但主库的性能就会打折扣)
