





概述
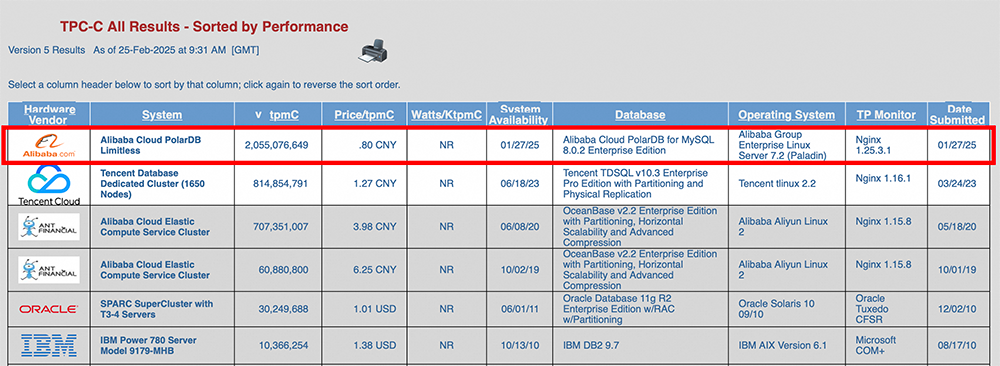
本次TPC-C基准测试,我们所使用的是PolarDB for MySQL 8.0.2版。PolarDB MySQL版支持多主集群(Limitless),客户通过加读写节点(RW)的方式即可从PolarDB MySQL一主多读变配为PolarDB MySQL版多主集群(Limitless)。
PolarDB MySQL版多主集群(Limitless)支持多主多写、内存融合、分布式存储、秒级横向扩展,支持单表读写透明的跨机扩展到海量节点。本次TPC-C基准测试中 PolarDB 以2340个读写节点的形态(规格为48核512GB),支持了每分钟20.55亿笔交易(tpmC)。从tmpC和price/tpmC刷新TPC-C性能和性价比双榜的世界纪录。
早期的云原生关系型数据库主要形态是基于存储和计算分离的一写多读形态,虽然其可以很好地替换原生或者托管的MySQL/PG数据库,但是因其单写架构限制了其写能力的扩展。随着云原生数据库技术的不断演进,支持大规模部署和横向读写扩展的云原生数据库PolarDB MySQL版多主集群(Limitless)功能就此诞生。其核心优势是可弹性扩缩计算节点且每个节点都可处理读写请求,可在多个节点上实现并发写入。此外,其在保留单机高性能,高弹性的同时,利用RDMA/CXL等技术,对节点间的事务和数据进行高效融合,在保证事务一致性的前提下,实现高效的透明秒级横向跨机读写线性扩展。
技术深入解读
01

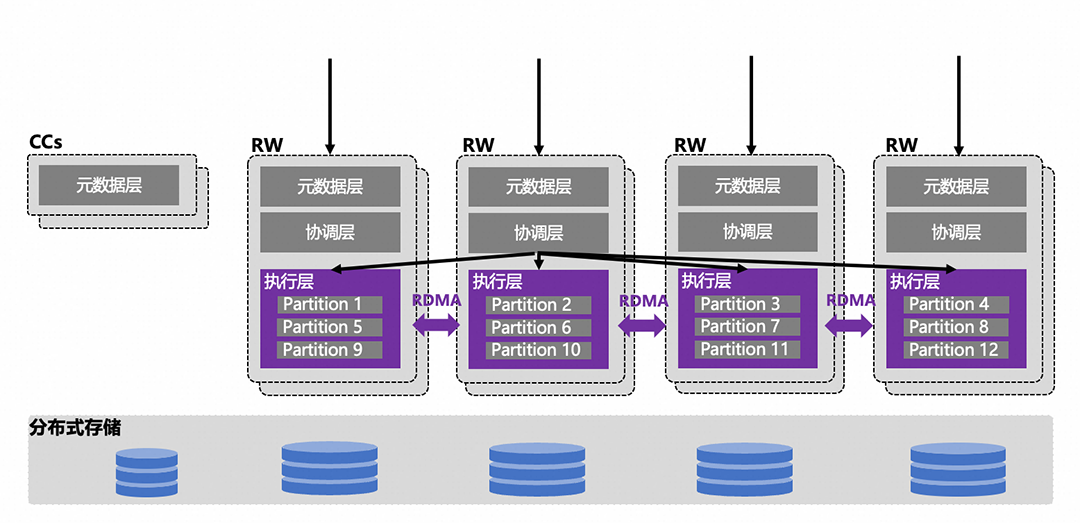
可充分提升资源利用率,避免因在不同负载下CN/DN某一个打满而另一个闲置的资源浪费;
可降低CN/DN分离带来的额外的通信成本,提升性能;
计算节点采用MySQL原始的语法解析/优化/执行器带来了100%的MySQL兼容性。
02
高性能横向跨机读写扩展
2.1 PolarTrans云原生事务系统
InnoDB原生事务系统是基于活跃事务列表实现的,但维护活跃事务列表需要全局大锁保护,成本开销较大,在高并发场景下容易成为整个系统的性能瓶颈点。另外,考虑到分布式事务一致性方案大多基于提交时间戳方案(TSO/TrueTime/HLC等),因此,PolarTrans通过提交时间戳技术(CTS)优化原生事务系统,核心数据结构为CTS log,由一段ring buffer组成,事务ID trx_id通过取模映射到其对应的slot,每个slot存储trx指针和cts值(事务提交时间戳)。其优化的核心思想是移除对复杂数据结构的维护,事务状态迭代、可见性判断等核心事务逻辑, 都是通过CTS log来完成,更加轻量级;同时PolarTrans将大部分的逻辑进行无锁优化,因此,PolarTrans事务系统对于读写混合场景、纯写场景都有较大的性能提升。
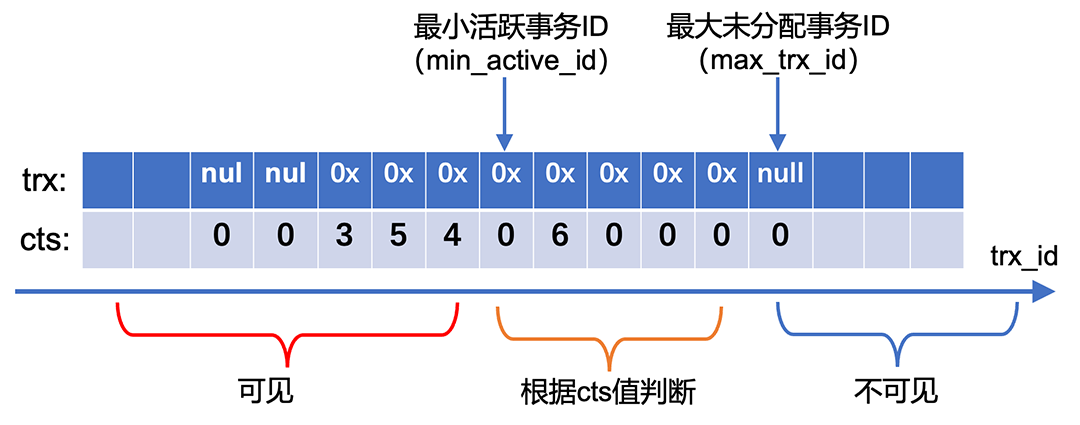
2.2 分布式快照一致性
InnoDB原生快照一致性读依赖活跃事务列表维护事务状态,提供事务可见性判断,该机制在分布式多写场景中暴露严重缺陷:维护集群跨节点的全局活跃事务列表,引发高频全局锁竞争,扩展性随节点数增长而急剧下降。PolarDB基于PolarTrans以及RDMA来构建分布式事务系统,提供分布式快照一致性能力:
集群中所有节点通过RDMA进行点对点互连,跨机共享RDMA注册的内存CTS Log来实现全局事务状态信息同步和跨物理机直接更新,避免通过中心节点维护全局活跃事务列表,同时CTS Log提供了事务远程提交,状态查询等能力。 通过TSO或HLC两种时间戳管理方案,生成事务提交时间戳,分布式写事务的所有子事务通过相同的时间戳进行原子提交,分布式读通过统一的时间戳结合CTS Log判断数据可见性,保证分布式读一致性。
2.3 多机事务一致性:云原生分布式事务
我们设计实现了一种软硬件协同的云原生分布式事务方案,可实现良好的多机写扩展性。核心思想是利用RDMA等新型硬件低延迟优势,加速提交流程中Prepare阶段和Commit阶段的执行。相对于传统或现有的数据库分布式事务方案来说,我们所设计的软硬件协同的云原生分布式事务方案的核心优化点有:
通过利用RDMA新型硬件低延迟的优势和LSN机制,优化了分布式事务Prepare阶段的执行流程,仅需执行远端RDMA读操作就可确定事务的Prepared状态,避免了Prepare阶段协调节点与参与节点之间的SQL交互开销。 设计了CTS Log记录事务提交时间戳,协调节点CN通过RDMA将事务提交时间戳cts,以微秒级延迟写入参与节点PN的CTS Log,优化了Commit阶段的执行逻辑,使得Commit阶段可以异步执行。
2.4 多机并行DDL
PolarDB全局共用全量dd信息的同时将表进行拆分,不同RW节点负责读写不同分表,以提升单表的吞吐和数据承载能力。在实际业务中对表拆分后,如何控制所有分表的DDL流程,协调与逻辑表的关系,防止表的元信息不一致,是分布式DDL设计需要考虑的难题。
DDL并发控制:在分布式表场景下,为了防止同一张表出现并发DDL,我们复用库/表锁的思想和管理逻辑,为全局库/表增加一个XB锁类型,执行DDL时首先拿XB锁,从而避免并发DDL。 分布式DDL原子性保证:设计一种基于多阶段提交协议的机制,在Commit阶段之前的任何时间点,如果DDL执行过程发生异常,会立即报告给协调节点CN;CN向所有DN发送指令,回滚DN节点上执行的DDL操作,从而保证分布式DDL操作的原子性。
03
高可用机制
为了实现数据库系统的高可用,传统OLTP数据库的做法是为每个主节点(Primary)维护一个或多个备节点(Standby)。为了降低成本且保证系统的高可用,我们提供了可供用户选择的多样化高可用方案。
首先,基于私有RO节点的高可用方案,用户可选择为每个RW节点配置私有RO节点,私有RO节点和RW共享同一份数据,无需额外存储数据。当一个RW节点发生故障时,可将其私有RO节点秒级切换为RW,接管流量请求,集群整体性能不会受到影响。另一方面,如果用户没有为RW节点配置私有RO,当RW节点发生故障时,我们还提供RW节点间互为备节点的机制来保证高可用。当一个RW节点发生故障时,可选择另外一个低负载的RW节点来快速接管故障节点上的流量,只需将故障节点上的库表重映射到低负载的RW即可,但由于资源限制在高压力负载下可能会影响集群整体性能。
04
全局RO节点
05
极致的性能和扩展性
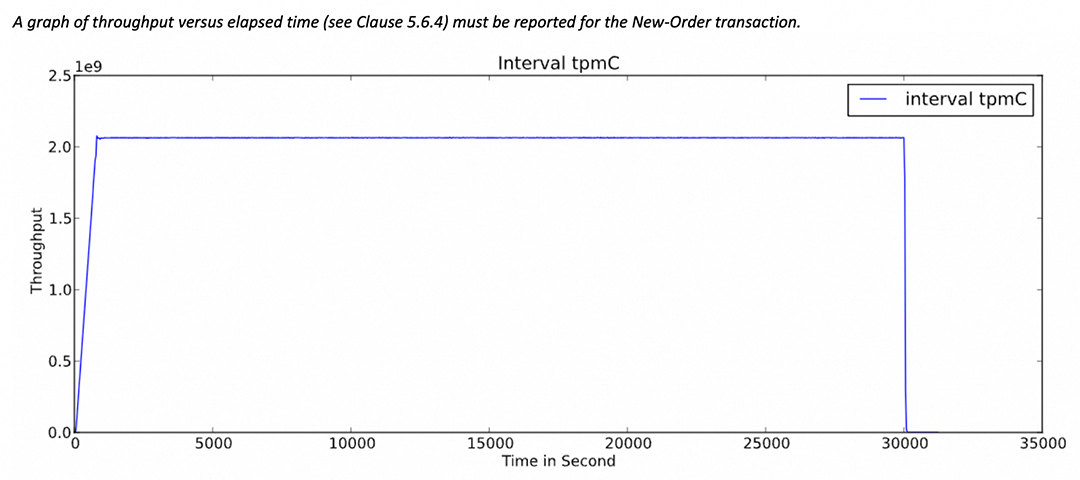
使用TPC-C基准测试程序对PolarDB MySQL版Limitless超大规模集群(2340个读写节点,节点规格48核512GB)进行了性能测试,TPC-C被认为是数据库领域的“奥林匹克”,它是OLTP(联机交易处理系统)数据库性能测试唯一的国际权威榜单。
5.1 超大规模集群下稳定的性能
5.2 超大规模集群下高可用和容灾能力
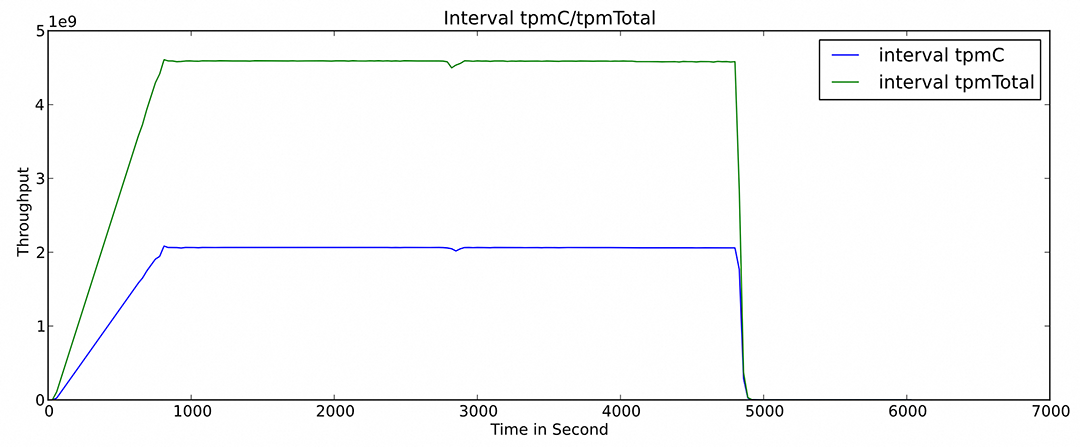
图4:PolarDB TPCC 容灾场景性能数据
在容灾场景测试中,执行了不同组件的故障测试,真实的物理机器断电,验证了集群在物理机器故障的突发情况下,能在10 秒内完成故障容灾切换,2分钟内完成整体性能的恢复,容灾测试过程中对集群整体性能的影响控制在2%以内(标准要求10%以内),并且可以保证数据不丢失,分布式事务一致性等。
5.3 秒级水平扩容能力
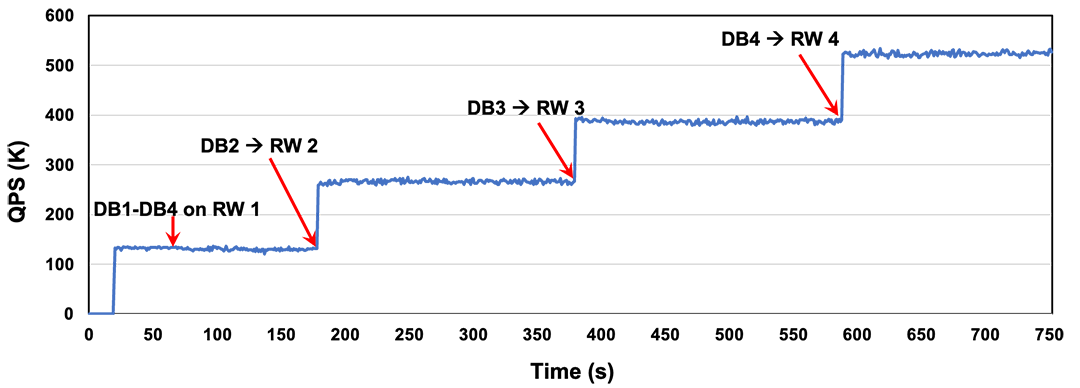
在横向水平扩容测试时,创建的4个DB最开始都在RW1上,压测过程中,逐渐增加RW节点个数,并将DB2-DB4依次绑定到新增的RW节点。图中展示了扩容过程中集群整体的性能变化,表明集群可以实现秒级的水平扩容。
整体总结



点击了解 PolarDB登顶TPC-C 更多内容
一键申请 PolarDB免费试用

