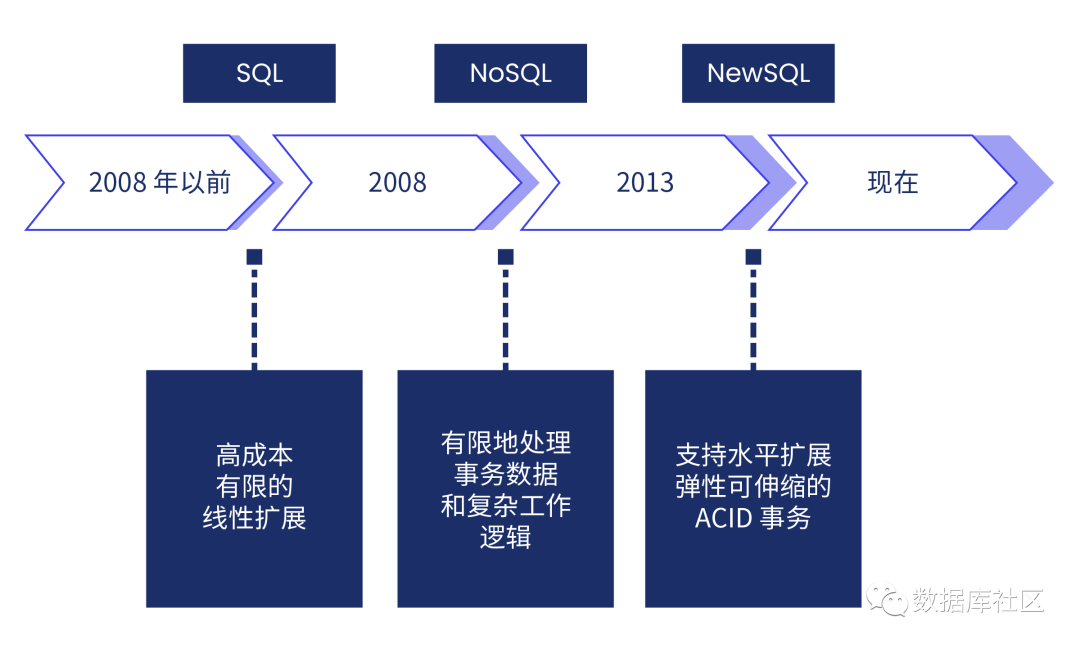
数据库系统发展历史表
自上世纪 70 年代, EF codd 提出了关系型数据库模型开始,数据库已经发展了将近半个世纪。可以说是一个历史悠久的计算机学科,在这个半个世纪里,这个学科发生了很多变化,但也有一些共性的驱动在里面。我们尝试一起探讨下数据技术发展的内在驱动、以及展望趋势。
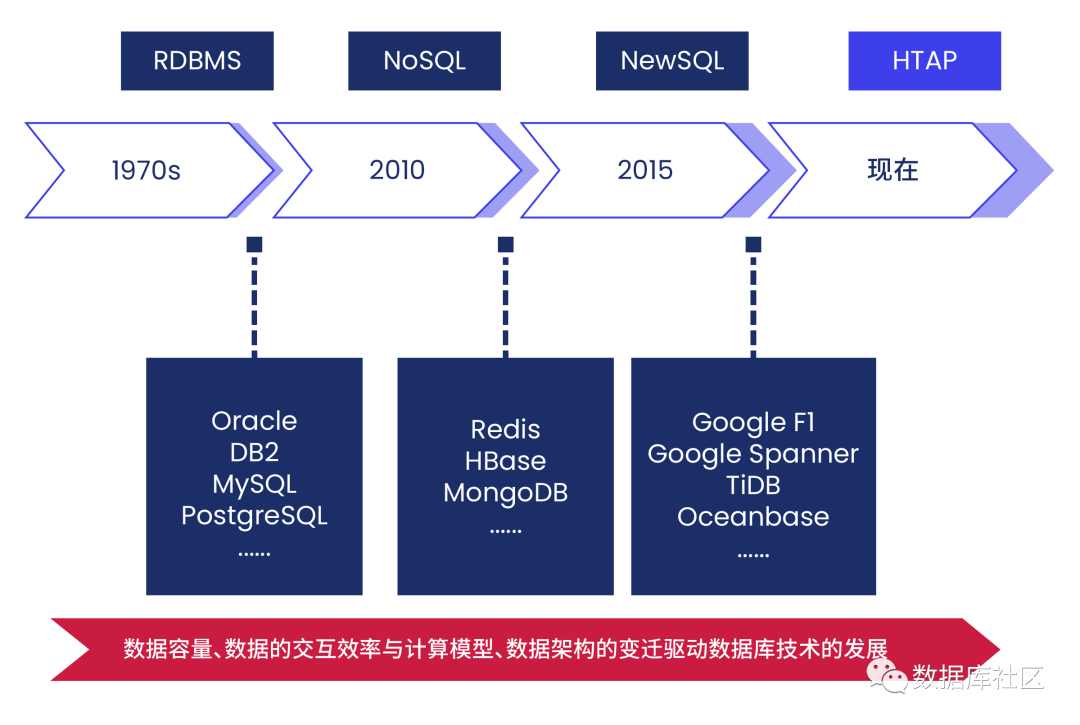
我们先按照时间维度,回顾数据库的发展简史:
上世纪 80 年代,也就是从提出关系型数据库模型后 10 多年,关系型数据库产品逐步完成了工程与产品实现, Oracle、IBM DB2、Sybase 以及 SQL Server 和 Informix 第一批关系型商业数据库开始出现。
到 90 年代中后期,MySQL、PostgreSQL 这类开源数据库开始萌芽。
上世纪末到本世纪初, IT 与通信两门技术发生第一次碰撞,开启互联网时代,数据量开始爆发增长,快速发展的各类互联网公司,更加青睐 MySQL、PostgreSQL 这类开源数据库,同时也给这类开源数据库带来丰富的产品生态,比如基于开源数据库的各种分库分表方案产生。同期,2006 年谷歌的三驾马车(GFS、Bigtable、Mapreduce)开启了大数据时代,涌现了 Hadoop(Hbase)、Redis 等 NoSQL 大数据生态。
2010 年后,IT 技术与通信技术发生第二次碰撞,4G 网络开启了移动互联网时代,在这个时代,产生了很多业务与场景创新,底层数据技术更是进入前所未有的快速通道,有几个特点:
数据技术栈与方向百花齐放。
集成了分布式技术与关系模型的 NewSQL 数据库开始出现,代表产品有 Spanner、TiDB 等。
云计算与数据库、大数据发生融合;很多云原生数据库出现,云计算不仅给数据技术带来新的变革,也给数据库厂商提供了更高效的服务交付、商业模式,各种 DBaaS(Database-as-a-Service)产品涌现。
2020 年后,各行各业都逐步进入数字化时期,虽然从技术创新角度,会有越来越多的数据技术栈与产品将出现;但这么多的技术栈也会大大增加使用成本,从用户需求的角度看,能不能将在线处理业务与分析业务进行整合,也就是我们经常说的 HTAP ,(Hybrid Transactional/Analytical Processing) 作为一种统一的数据服务变成了一个强需求
数据库技术发展内在驱动
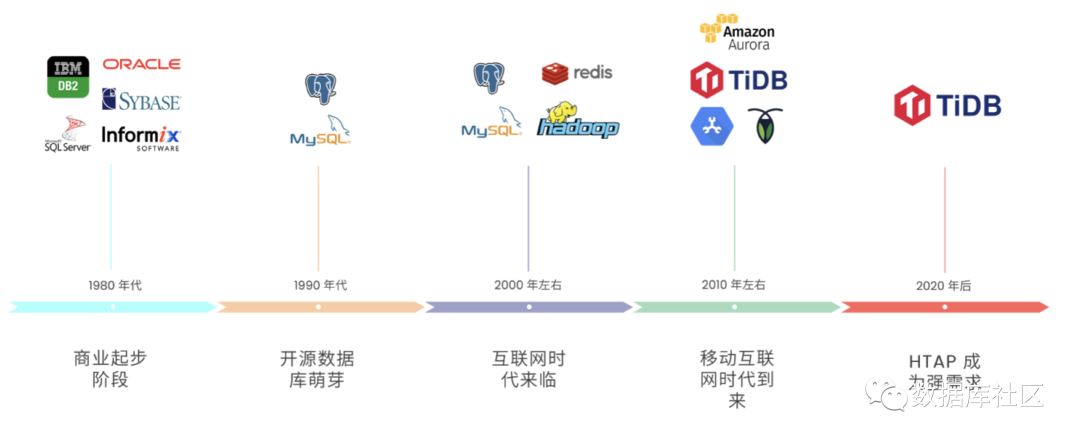
那么,在这个数据库发展的简史背后,驱动数据库技术发展与创新的内因是什么呢?
数据最终服务于上层应用,所以我们认为数据技术发展的驱动力总结起来,主要有三点:
业务发展
场景创新
硬件与云计算的发展
业务发展需求最主要体现在数据容量持续爆发增长,数据容量不仅包括数据存储量,更重要的包括数据的吞吐量、读写 QPS 等。
场景创新主要体现数据的交互效率与数据模型多样性,比如查询语言、计算模型、数据模型、读写延时等。
硬件与云计算主要体现在数据架构的变迁上,比如读写分离、一体机、云原生等。
数据容量催生数据架构演进
从数据容量的角度来看,数据库系统总是被动去适配业务数据量增长。
在早期,业务数据量基本在几百 GB 时代,单节点本地磁盘是最高效的数据架构,单机关系型数据库是主流。
随着数据量增加,人们可以通过加入更多 CPU、更大内层、更快硬盘等升级硬件的方式来应对,也就是大家说的纵向扩展 Scale up,包括引入网络存储(SAN)Share Disk 成了一种代表性的架构。
但硬件的升级总是有上限,当数据量的增加速度远远超过了硬件升级速度,Scale up 失效,只能通过分布式的(Share Nothing) 架构来应对,也就是我们说的横向扩展 Scale out。所以这个时期,分布式逐渐成为海量数据技术的代名词。

数据模型与交互效率的演进
我们在“数据模型与交互效率”这个维度来看:
除了,上面提到的对于水平扩展的需求外,还有关于数据存储结构、事务的需求也是我们要解决的问题。
早期的单机数据库查询使用标准 SQL 语言,支持事务并绝大部分采用结构化的方式进行存储。
2000 年后,特别是伴随着移动互联网的发展,在很多场景下,结构化的存储方式慢慢显得力不从心,诸如 Key-value、文本、图、时序数据、地理信息等非结构化数据的需求变得突出起来。于是就衍生出了 NoSQL(Not Only SQL)数据库。
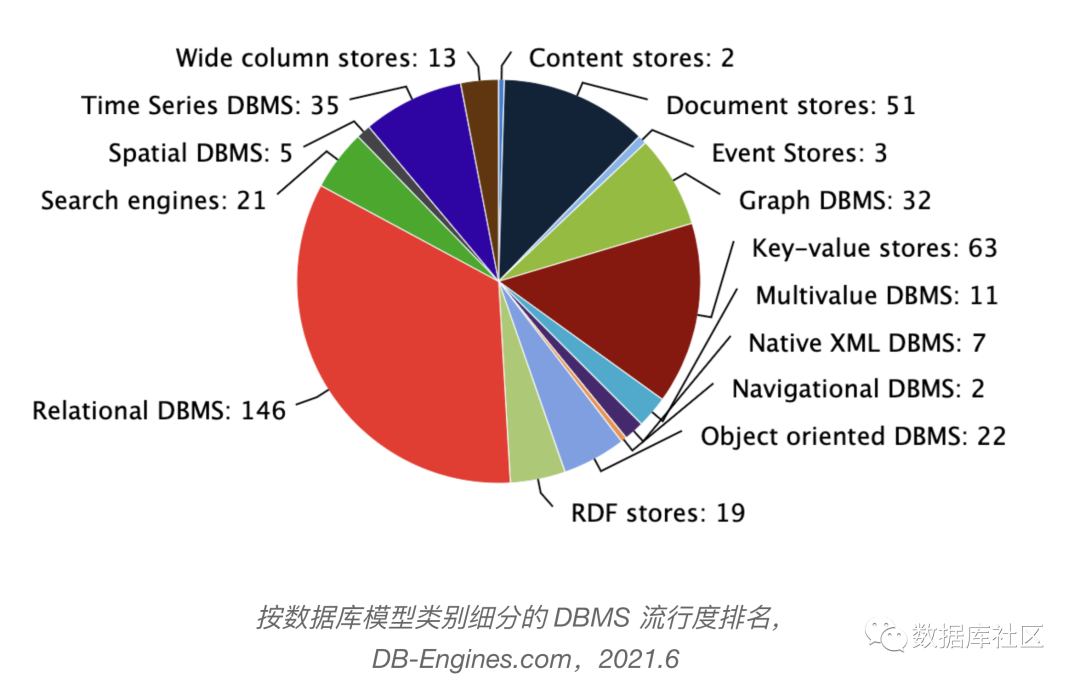
伴随着 NoSQL 数据库的快速发展,又一个新的问题摆在我们面前。那就是大部分 NoSQL 数据库对于事务无法支持。而事务对于 OLTP 场景是不可或缺的,也也就是为什么关系型数据库需求依然是当前的主流,如下图所示。
于是,即要求支持事务(OLTP场景)又同时兼容多种数据模式的可扩展需求就自然提了出来。这就是 NewSQL 的由来。
数据架构,融合还是细分?
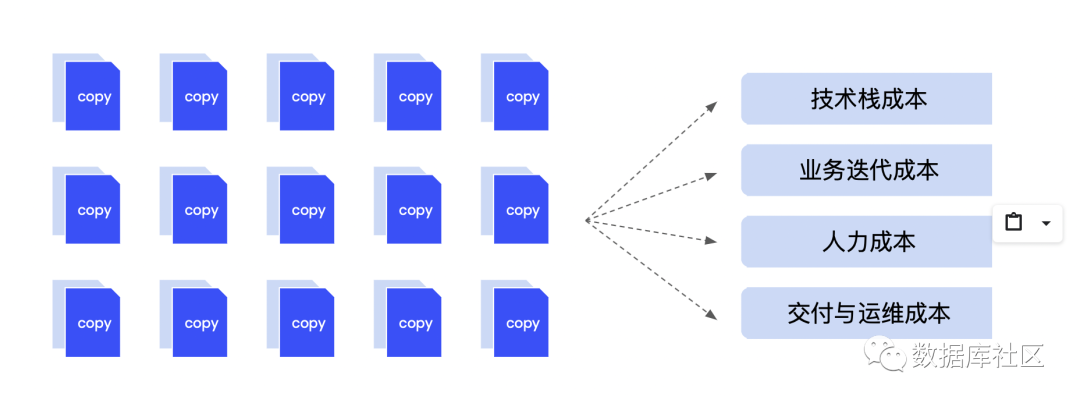
场景创新催生了数据技术栈与产品的多样性。但同时,数据技术栈与产品多样性导致了数据副本无序扩大。以一个真实电商平台为例,一份商品订单数据在电商平台的整个业务链条里,存在 30+ 份副本。而数据副本背后导致了巨大的技术栈成本、业务迭代时间成本、人力成本、交付与运维成本等。如何有效减少业务数据副本将是一个越来越重要的需求。
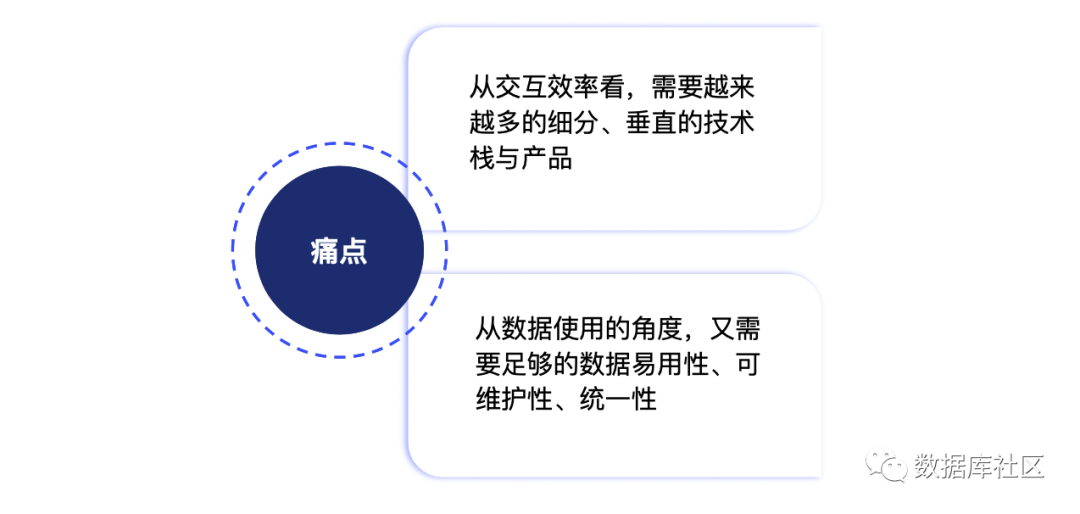
一方面从交互效率看,需要越来越多的细分、垂直的技术栈与产品;另一方面,从数据使用的角度,又需要足够的数据易用性、可维护性、统一性。这两个真实的需求形成一个巨大的矛盾与痛点。企业数据化加速,业务创新加速,数据将会持续以指数级增长,如何解决这一个痛点,是未来数据技术很重要的一个课题,或许未来趋势将是数据技术的细分与数据服务的融合。
总之,数据模型、数据结构、存储算法、复制协议、算子、计算模型、硬件构建了数据基础技术要素,而数据技术栈方向或者数据产品的本质是:应对不同业务场景,基于这些相对固定数据基础技术,进行数据架构 Trade Off(选择与平衡),我们会在接下来的课程详细解读,在数据架构里无处不在的 Trade Off 。