
近日,渊亭科技自主研发的「一种基于共享内存的图计算实现方法、终端设备及介质」正式获得国家知识产权局发明专利授权。
此项专利针对大规模图计算场景中性能瓶颈的问题,提出了一种高效、低延迟的图计算解决方案,为大规模图数据处理场景提供了更优的技术路径。


随着大数据与人工智能技术的深化应用,图计算在关系挖掘、用户行为分析、风险防控等领域的重要性日益凸显。
然而,当图的规模达到一定程度(千亿级)时,便难以应对海量数据处理需求,传统图计算架构正遭遇前所未有的挑战:
●单机处理:面对超大规模图数据时,内存溢出、计算超时成为常态;
●分布式方案:多节点协同产生的网络延迟高达百毫秒级,资源消耗激增;
●实时响应:快速决策要求场景(金融反欺诈等),传统架构难以满足。
为了解决上述问题,本发明创新性提出"共享内存+多线程”图计算架构,在保持分布式扩展能力的同时,实现多线程并发数据处理。
该方法通过以下关键步骤实现:
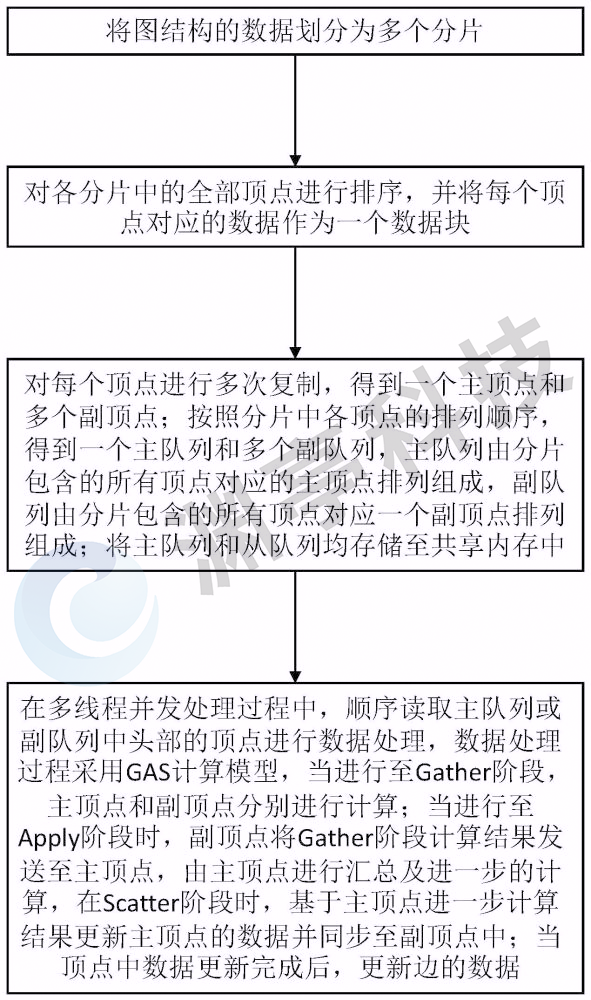
1. 数据分片与主副顶点协同机制
●将图结构数据划分为多个分片,并通过PSW算法对分片内顶点排序,生成连续存储的数据块。每个顶点被多次复制为“主顶点”与多个“副顶点”,分别构建主队列和副队列存储于共享内存中。
●多线程并发读取时,主顶点负责汇总计算和数据更新,副顶点并行执行数据收集,减少线程竞争,显著提升吞吐量。
2. 高效读写机制
●允许多个进程并发读取共享内存数据,但同一时间仅允许一个进程执行写操作。写进程从队尾增量追加数据,读进程从队首顺序提取数据,避免读写冲突。
●支持并发读取,有效避免了传统方案中因大量线程切换造成的上下文切换开销,降低系统资源消耗。
3. GAS计算模型的高效协同
基于GAS(Gather-Apply-Scatter)计算模型,进行三阶段优化:
●Gather阶段:主、副顶点并行收集相邻边和顶点数据,仅执行读操作;
●Apply阶段:副顶点将局部计算结果汇总至主顶点,由主顶点完成全局计算;
●Scatter阶段:主顶点更新数据并同步至副顶点,确保数据一致性。
该流程通过共享内存减少数据冗余传输,实现计算资源的高效利用。
该技术可广泛应用于社交网络分析、知识图谱构建、网络安全态势感知等领域。例如,在金融反欺诈场景中,通过快速处理大规模交易关系图,实时识别异常模式;在智能推荐场景中,加速用户行为图谱分析,提升推荐响应速度。
近年来,渊亭科技不断加强知识产权创新工作,已拥有200余项人工智能类发明专利和软件著作权。
未来,渊亭科技将不断探索和创新,以期在认知决策智能领域取得更多突破,为各行业提供更高效、稳定的数据处理解决方案,助力企业最大化释放数据价值,赋能核心业务,为各行各业发展注入崭新活力。