




长期以来,PostgreSQL 一直拥有一个可扩展的索引访问方法 API(称为 AM),它经受住了时间的考验,并允许许多强大的扩展提供自己的索引类型。例如:rum、pgvector、bloom、zombodb等。PostgreSQL 12 引入了 Table AM API,承诺为表访问方法提供同等的灵活性。
尽管 PostgreSQL 的 Table AM API 从版本 12 开始就可用,并且其内置存储引擎(特别是 MVCC 模型([1]、[2]、[3]))不断受到批评,但令人惊讶的是,还没有功能齐全的事务存储引擎纯粹作为扩展出现。
由于表 AM 和索引 AM API 紧密耦合,因此这对于两种实现来说都是一个问题。
替代 PostgreSQL 表引擎最需要的功能是:
- 替代的 MVCC 实现,例如基于 UNDO 日志的存储。
- 非堆式存储。例如,在索引组织表中,索引不是表的可选附加功能(可加快请求速度),而是表存储内部使用的必要层。因此,表元组是复杂数据结构的一部分,不能通过页码和偏移量号等固定长度的地址来寻址。它需要通过索引键等可变长度的标识符来寻址。
OrioleDB是说明更改表和索引 AM API 动机的一个示例。它是一种扩展,提供我们开发的表访问方法,用于解决内置存储引擎的许多众所周知的缺点。但是,OrioleDB 还不是嵌入式扩展;它需要对 PostgreSQL Core 进行几个修补。
除了下面将要讨论的这两件事之外,还有许多需要进一步改进的 API,例如指针弯曲和替代 WAL 日志记录,这些超出了本文的讨论范围。
替代 MVCC
表 AM API 不会直接强制 MVCC 的实现方式。不过,索引 AM 和表 AM API 做出了以下假设:每个 TID 要么被所有索引编入索引,要么根本没有编入索引。即使索引 AM 对单个 TID 有多个引用(如 GIN),所有这些引用也应该对应于相同的索引值。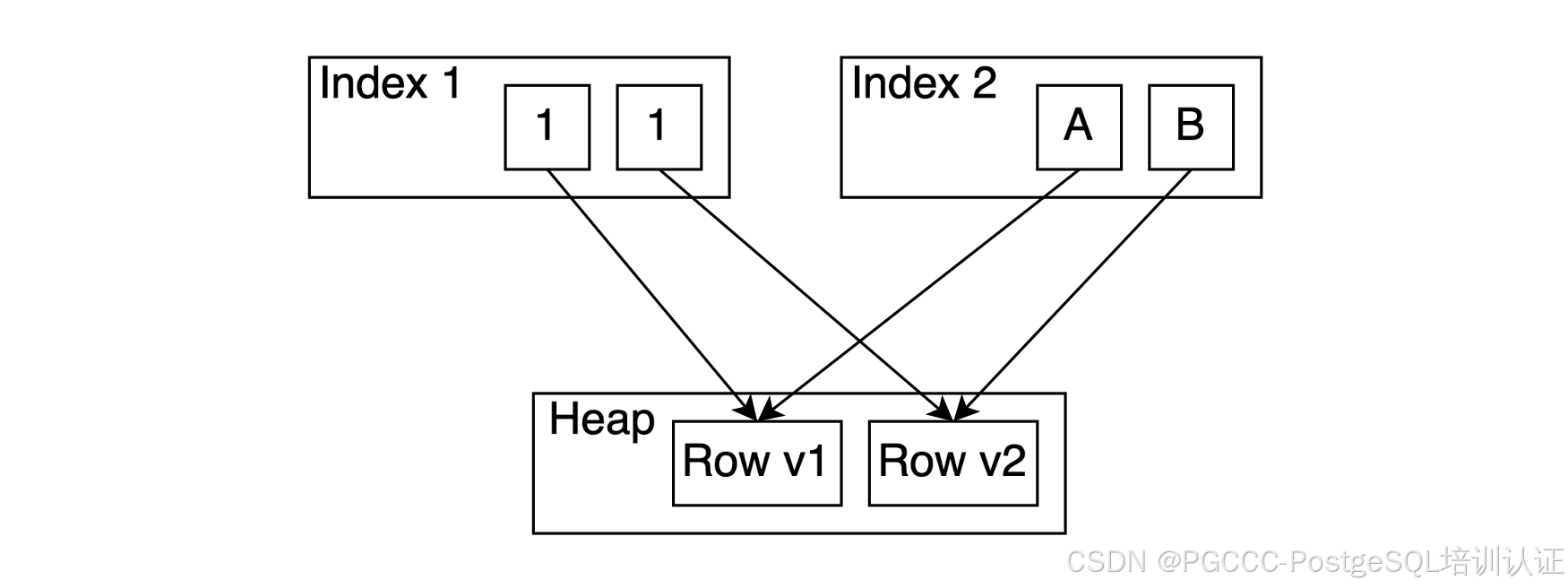
这一原则因存在写放大而受到批评。如果你更新一个索引属性,你必须将其插入到每个索引中。另外,如果我们想充分利用 undo log 的优势或构建其他无写放大的存储方法(例如 WARM 技术),我们必须打破这一假设。
不违背这一假设的撤消访问方法与现有的HOT技术非常相似 ,只是旧行版本存储在撤消日志中,并且不必适合同一页。在我看来,这并不是 AM 表的合理之处。
让我们看看这个假设在 API 级别是如何实际执行的。
- 在更新表行期间,索引以全有或全无的方式更新。表 AM 更新方法的签名如下:实现只能设置 的值 update_indexes。
/* see table_tuple_update() for reference about parameters */
TM_Result (*tuple_update) (Relation rel,
ItemPointer otid,
TupleTableSlot *slot,
CommandId cid,
Snapshot snapshot,
Snapshot crosscheck,
bool wait,
TM_FailureData *tmfd,
LockTupleMode *lockmode,
TU_UpdateIndexes *update_indexes);
相应的枚举完全是全有或全无的,除非有一个特殊值来处理BRIN。即使我们为这个枚举添加另一个特殊值,目前仍然没有地方存储每个索引的索引更新策略
/*
* Result codes for table_update(..., update_indexes*..).
* Used to determine which indexes to update.
*/
typedef enum TU_UpdateIndexes
{
/* No indexed columns were updated (incl. TID addressing of tuple) */
TU_None,
/* A non-summarizing indexed column was updated, or the TID has changed */
TU_All,
/* Only summarized columns were updated, TID is unchanged */
TU_Summarizing,
} TU_UpdateIndexes;
- 索引 AM API 中缺少“点删除”方法来删除特定元组。目前,我们可以使用 ambulkdelete 和 amvacuumcleanup方法批量从索引中删除元组。是否删除特定 TID是通过调用回调来确定的(见下图)。这会导致效率低下,因为大多数当前实现都必须扫描整个索引。此外,从一个 TID可以引用的几个元组中,该方法无法选择应该删除哪一个。它只能删除所有元组。
/* Typedef for callback function to determine if a tuple is bulk-deletable */
typedef bool (*IndexBulkDeleteCallback) (ItemPointer itemptr, void *state);
/* bulk delete */
typedef IndexBulkDeleteResult *(*ambulkdelete_function) (IndexVacuumInfo *info,
IndexBulkDeleteResult *stats,
IndexBulkDeleteCallback callback,
void *callback_state);
/* post-VACUUM cleanup */
typedef IndexBulkDeleteResult *(*amvacuumcleanup_function) (IndexVacuumInfo *info,
IndexBulkDeleteResult *stats);
- 如前所述,索引当前通过块号和偏移号引用表行。并且只有11 位偏移号可以安全地从表 TID 传输到所有索引访问方法。但是,替代的 MVCC实现可能需要将额外的有效负载与 TID 一起存储。我们需要一个或几个位来实现“删除标记”索引甚至完整的可见性信息。让我们看看如何克服这个限制。一般来说,我认为有两种方法可以做到这一点。
方法 1:Index AM 为替代的 MVCC
虽然表 AM 仍然负责所有的 MVCC 内容,但是索引 AM 为替代的 MVCC 实现提供了必要的设施,包括自定义有效负载与 TID 一起存储、“点删除”方法,甚至“点更新”方法(如果索引中的 TID 无法更改,则自定义有效负载肯定可以更改)。由于我们应该允许多个索引元组引用同一个 TID,因此我们必须在从表 AM 中获取相应元组时提供更多信息。也就是说,我们可能需要传递索引值,以便 index_fetch_tuple 使用表行版本重新检查它们。
bool (*index_fetch_tuple) (struct IndexFetchTableData *scan,
ItemPointer tid,
Snapshot snapshot,
TupleTableSlot *slot,
bool *call_again, bool *all_dead);
对于基于撤消的存储,许多行版本可以驻留在同一个 TID 中,位图扫描可能可以“按原样”工作。不过,它可能会得到更多的误报。但如果我们想允许类似 WARM 的东西,最好为表 AM 提供一种重新定义位图扫描的方法。这已经是可能的了 set_rel_pathlist_hook,但零售方式会更好。
方法 2:MVCC 感知
另一种方法是允许 MVCC 感知索引。也就是说,执行器(或可以说是表 AM)只调用索引 AM insert() 和 delete() 方法,而索引 AM 提供 MVCC 感知扫描。这将使仅索引扫描变得更加简单。甚至整个表 AM 都可以是一个中间层,将数据存储在索引中并提供索引组织表。有人可能会说 MVCC 信息可能会给索引带来很大的负担。但是,我们应该记住,索引在压缩这些信息方面有更大的自由度。也就是说,当页面上的所有元组都需要标记为已更新/已删除时,堆必须为最坏情况保留空间。相比之下,索引可以在平均情况下优化存储,而在最坏情况下进行页面拆分
下图给出了示例。事务 11 将索引 2 的值从值 A 更新为值 B。因此,值 A 标记为 xmax == 11,值 B 标记为 xmin == 11。这些值允许扫描索引 2 并根据快照仅获取可见匹配,而无需检查堆。索引 2 的垃圾收集也可以在不检查堆的情况下执行。另外,请注意,我们不需要为值 A 的 xmin 和值 B 的 xmax 保留空间,因为我们可以在需要时执行页面拆分。
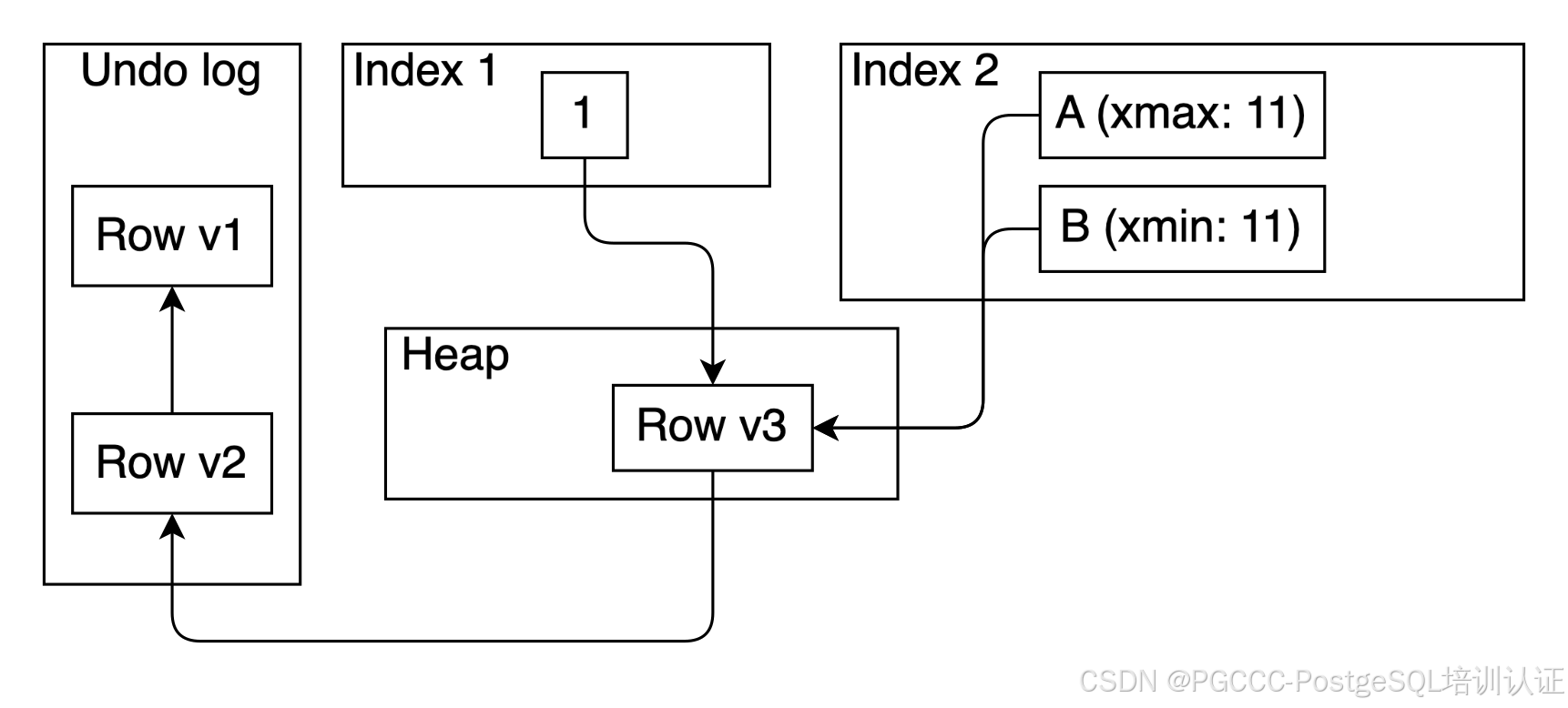
分裂指数
上述讨论强调,改进 PostgreSQL 的索引 AM API 以适应新的存储模型需要的不仅仅是渐进式的更改。鉴于现有的索引 AM 与运算符系列、类和规划器启发式算法紧密交织在一起,并且实现假设物理元组标识符 (TID) 模型,因此无法使用替代 MVCC 实现或索引组织表所需的功能来增强它们。为了保持所有现有索引和表功能不变,更可持续的方法是将索引 AM 拆分为两个不同的层:- 逻辑索引 AM。该层将充当与现有实体(例如运算符系列和运算符类)交互的抽象边界,公开查询规划器所需的信息并继承现有的规划器技巧。
- 索引 AM 实现。此层负责索引的实际实现,包括索引页面布局、插入/删除/搜索算法等。特定实现提供诸如 MVCC感知、对任意行标识符的支持等属性。
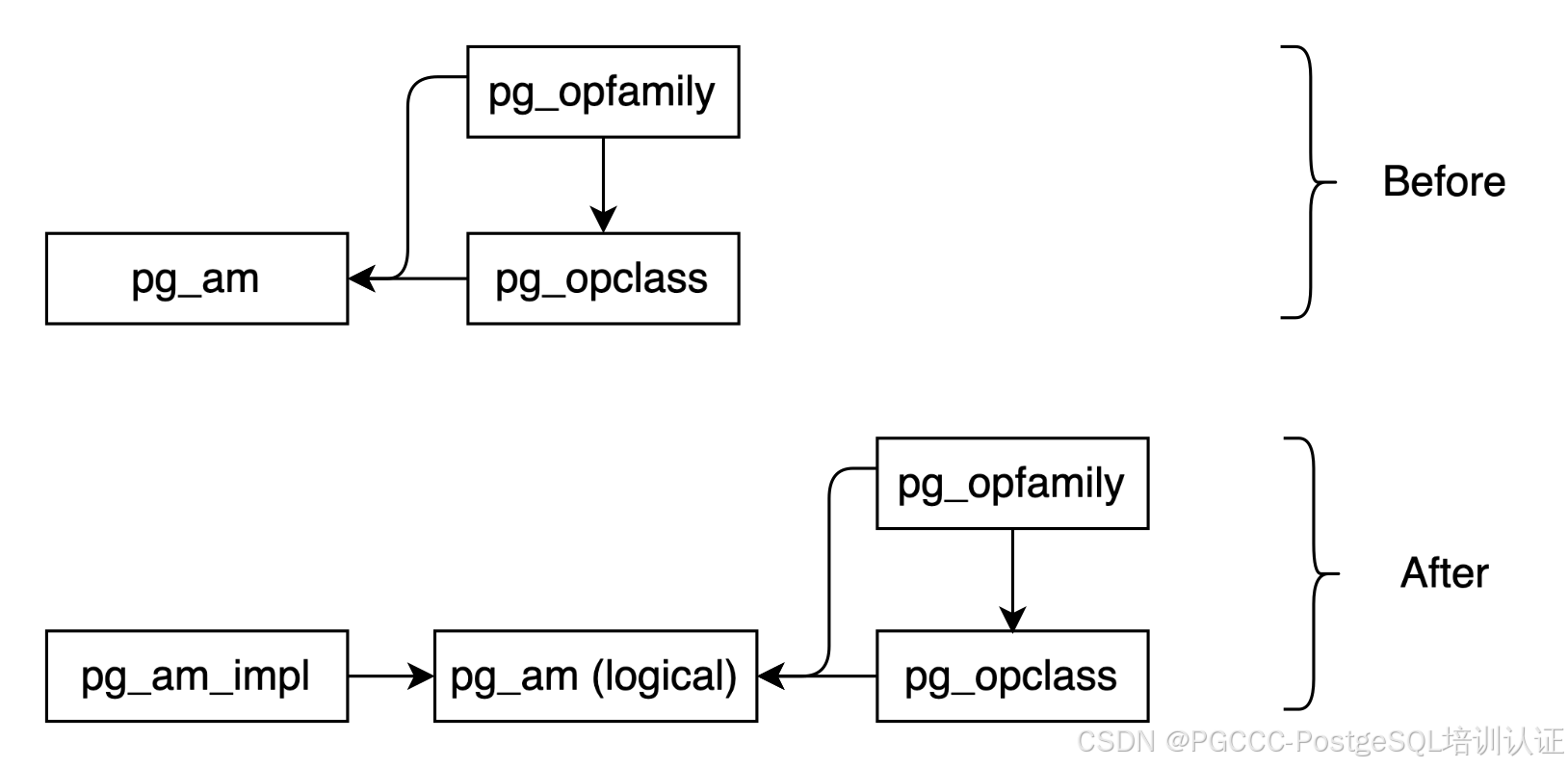
例如,使用此设计扩展可以定义新的索引 AM 和 MVCC 感知 B 树实现(在 pg_am_impl 中定义)。通过 pg_am,它将重用所有现有的运算符类/系列、规划器黑客等。此 MVCC 感知 B 树将经过定制,以服务于此扩展中定义的基于撤消的表 AM。
结论
虽然 PostgreSQL 现有的表和索引 AM API 多年来一直为社区提供良好的服务,但对替代存储引擎和 MVCC 实现的需求暴露了其当前设计中固有的局限性。从全有或全无的更新机制到基于 TID 的索引的僵化,所讨论的挑战强调了需要一种更灵活、更细致入微的方法。我们可以从支持完全支持 MVCC 的索引或扩展索引 AM 以支持替代的 MVCC 策略开始。此外,将索引 AM 分为逻辑层和实现层的提议是一个有前途的方向,它不仅解决了当前的限制,而且为未来的创新奠定了基础。这种重新构想的架构可以使 PostgreSQL 支持多种存储模型,减少写入放大,并提高整体系统性能,最终为更模块化、可扩展和强大的数据库生态系统打开大门。#PG证书#PG考试#PostgreSQL培训#PostgreSQL考试#PostgreSQL认证
