




不写代码也能玩转模型微调?
在DeepSeek-R1 的技术报告中提出了一种方法:先通过强化学习训练出一个具备推理能力的 R1-Zero 模型,然后用其输出的 60 万条推理数据来微调更小的 Qwen Llama 模型,从而赋予小模型推理能力。
在前文《使用AI Quick Action一键部署推理模型》中,我们已经介绍了如何利用 Oracle Cloud Infrastructure (OCI) 的 AI Quick Actions 部署 DeepSeek 模型。实际上,AI Quick Actions 的能力不仅限于模型部署,它还提供了模型管理、评估、微调、部署等一整套 AI 解决方案。
今天,我们将带你体验一条全新的路径——无需编写代码,仅凭界面操作,就能将一个普通模型微调为具备推理能力的reasoning模型。
为什么要微调模型?
开源的基座模型(Base Model)通常是基于海量数据训练得到的,能够应对诸如知识问答、代码生成等常见任务。然而,当涉及特定领域的专业应用时,基座模型往往力不从心。这时候,就需要通过专业领域数据的微调(Fine-Tuning)来提升模型在特定任务上的表现,使其更好地适应业务需求,比如法律、金融、医疗等专业领域。
以 SQL 生成任务为例,当前开源领域已有许多大模型支持 SQL 代码生成,但由于训练数据的滞后性,它们无法很好地支持一些新的语法特性。例如Oracle的向量检索和新的 SQL:2023 语法标准。Oracle 23ai 数据库已率先支持 SQL:2023,尤其是其中的 graph table 语法,大幅简化了图数据查询。这是一种全新的语法形式,我们的目标是,通过微调,让基座模型掌握这项新能力。
AI Quick Actions:一站式模型微调
Oracle 云上的 AI Quick Actions 让用户可以无缝浏览Hugging Face开源社区的基础模型,并通过 OCI 的基础架构和开发环境,一键完成模型的部署、微调和评估。
在本次实验中,我们的微调流程包括以下步骤:
1.生成合成数据:使用 Llama 3.3生成包含推理过程的微调数据。
2.注册基座模型:在 AI Quick Actions 上注册具备SQL生成能力的开源模型。
3.评估基座模型:对基座模型进行初始评估,以便后续对比。
4.微调模型:基于合成数据微调模型,使其具备推理能力。
5.测试效果:在测试数据上验证微调后的模型性能。
如何合成推理数据?
DeepSeek使用强化学习训练得到的推理模型,再用推理模型的输出数据,来微调小模型。但这样就存在一个悖论:需要先有一个较大的推理模型,然后才能输出数据样本来微调较小的模型。
如果通过强化学习来增强大模型的 SQL 生成能力,成本和资源消耗会非常高。为了绕过这个问题,我们采用了一种让LLM“自我解释”的方法来合成推理数据:
首先,从 Oracle SQL 语言参考文档 中提取 GRAPH_TABLE 语法介绍文档,其中包含示例问题、SQL答案和语法解释。
然后,调用 Llama 3.3,为每条SQL 生成多种中英文变体问题,这一步的目的是扩充数据的丰富性。
接下来是关键的一步,引导大模型“思考”解答过程:通过构造聊天记录,先输入问题和答案,然后让能力较强的Llama 3.3 模型自己解释推理步骤,以自我思考的描述 SQL 生成过程。

▲ 使用大模型构造包含推理过程的合成数据
最终,我们合成出的数据集不仅包括 SQL 语句,还附带详细的推理过程,使得模型在回答时能够先“思考”如何生成 SQL,而不是直接回答。数据集必须采用 JSONL 格式,并且必须包含必要的“prompt”和“completion”字段。
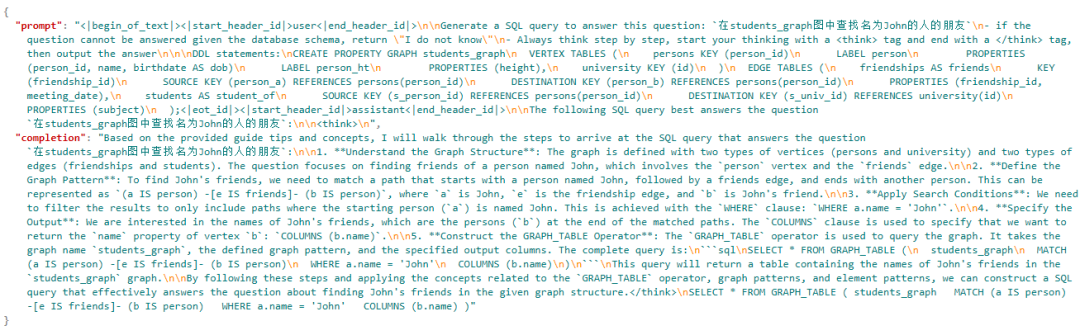
▲ 合成数据集示例,可以用于模型评估和模型微调
微调实战:一步步打造推理模型
1. 注册基座模型
AI Quick Actions 允许直接注册 Hugging Face 上的开源模型。需要注意,在注册时勾选“Enable Fine tuning”,即可允许对模型进行微调。
在本示例中,我们使用 defog/llama-3-sqlcoder-8b作为基座模型。这款基于 Llama 3 的 SQL 生成模型拥有卓越的文本到 SQL 生成能力,同时资源占用较低,仅需 1 个 A10 GPU 即可部署和微调。
2. 评估基座模型
llama-3-sqlcoder-8b 在开发过程中使用基于 PostgreSQL 的评估框架SQL-Eval进行评估,缺少对于GRAPH_TABLE 语法的支持。通过简单的测试,可以发现,模型会按照传统的JOIN方式来处理图数据的查询,无法生成符合 SQL:2023 规范的查询语句,这样不仅效率很低,而且结果是错误的。
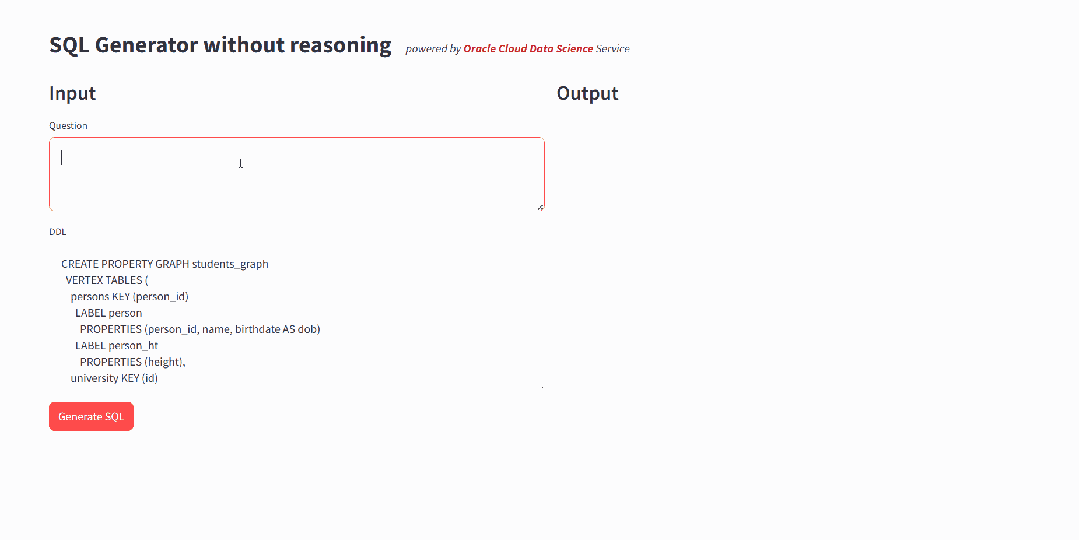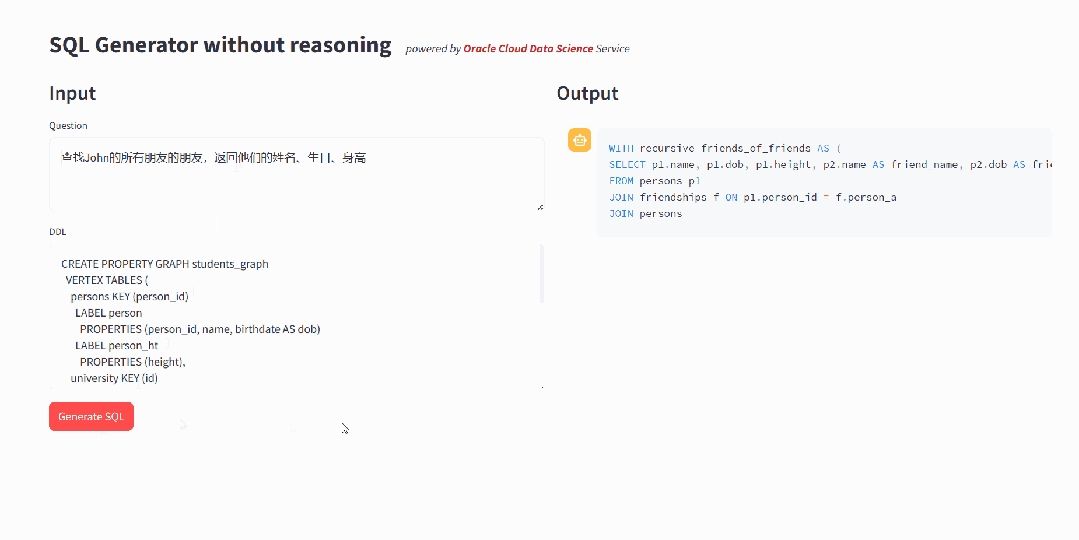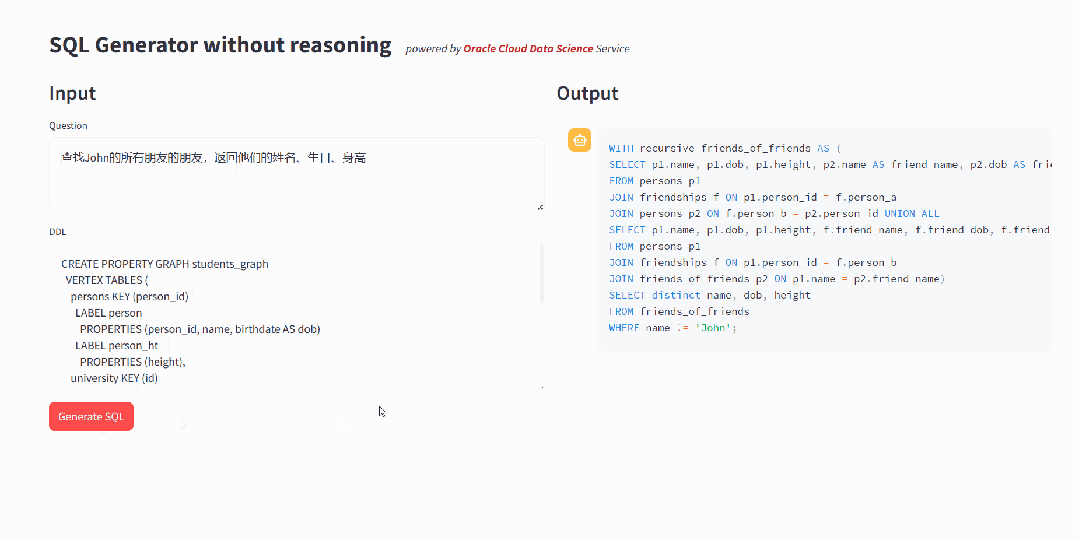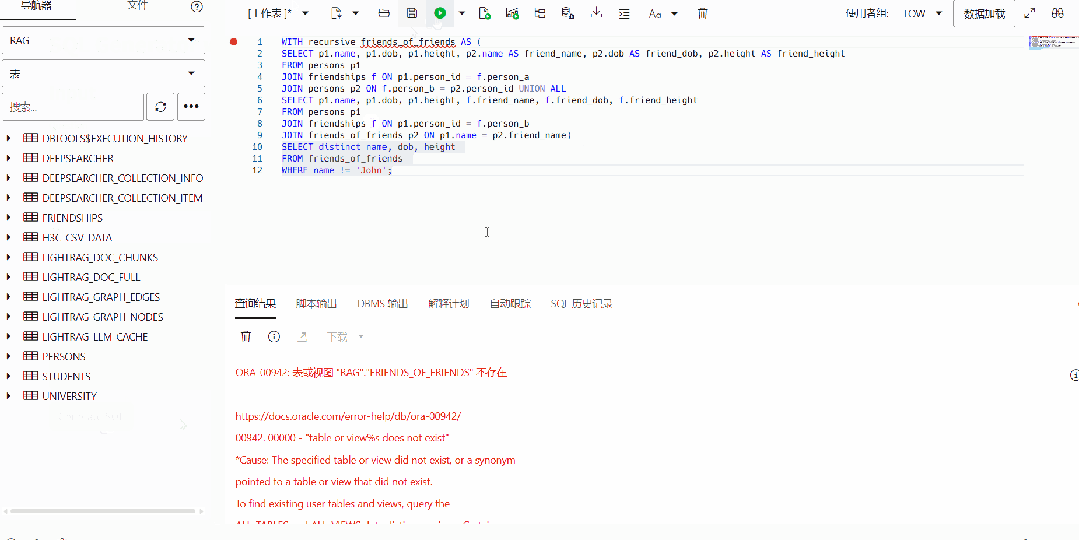
▲ 在基座模型上的测试表明模型不具有GRAPH_TABLE的查询能力
在 AI Quick Actions 中,我们可以轻松创建模型评估任务。系统会自动将指定数据集中的 prompt 发送给模型部署,并计算生成文本的质量指标,创建一个详细的评估报告。
下图是基座模型的BERT 分数,评估报告还支持ROUGE、Perplexity等多种评分指标。结果显示,基座模型在 Oracle Graph Table 相关任务上的表现较差。
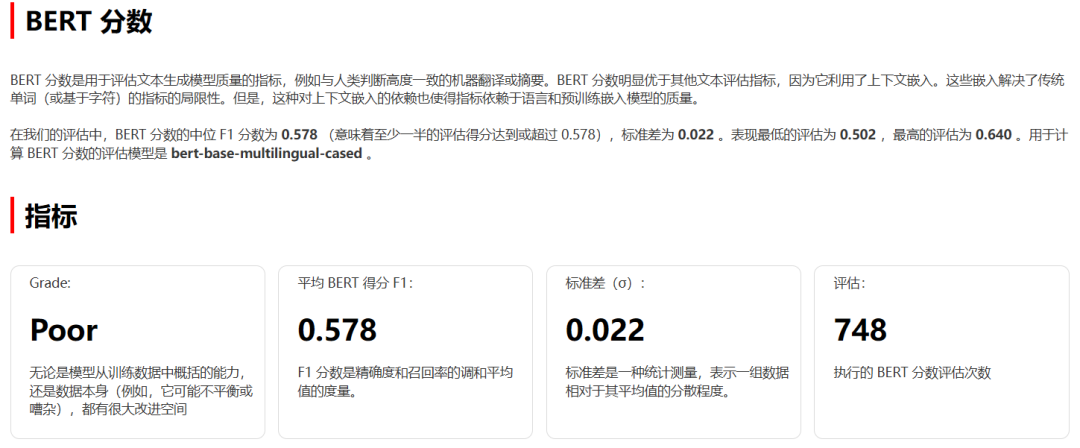
▲ 截取的基座模型评估报告部分内容,指标显示模型效果较差
3. 微调模型
在 AI Quick Actions 的“Model Overview”界面,点击“Fine-Tune”即可创建微调任务。其中可以配置的主要内容包括:
l 选择数据集:前面的推理数据,保存到对象存储,可以指定训练集和验证集的比例。
l 指定模型保存位置:模型权重文件存储在对象存储。
l 选择 GPU 资源(如 A10,支持单节点训练和使用多张 GPU 卡的训练。)。
l 设置训练参数(如迭代次数、学习率)。
l 其它:日志、网络、模型版本集等等。
启动任务后,平台会自动执行数据集导入和拆分,管理计算资源,并提供训练日志和性能指标,让用户随时掌握进度。训练完成的模型可以在“Fine-tuned models”页面查看。
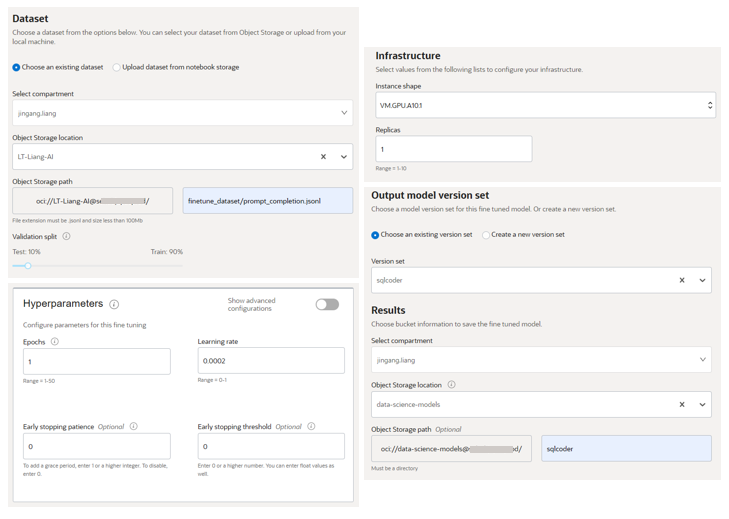
▲模型微调参数配置示例
4. 验证微调效果
为了验证微调是否有效,我们首先使用与GRAPH_TABLE相关的问题,对模型进行简单直接的测试,要求模型生成SQL。结果显示:对于基座模型则无法完成的任务,微调模型能够推导出正确的查询语句,生成的SQL 语句符合 SQL:2023 规范。模型推理能力有明显提升,可以先“思考”如何构造 SQL,然后再进行最终SQL生成。
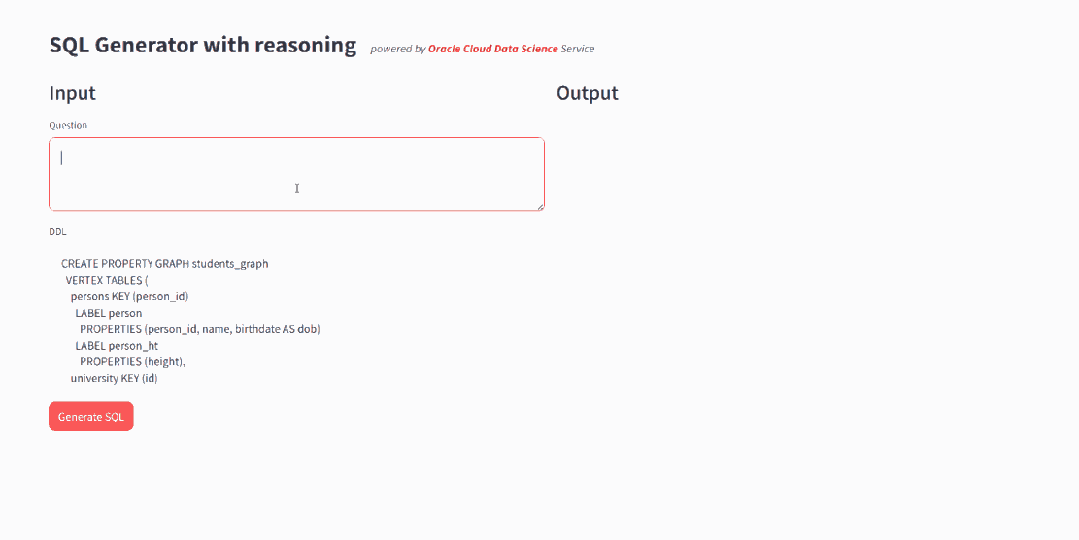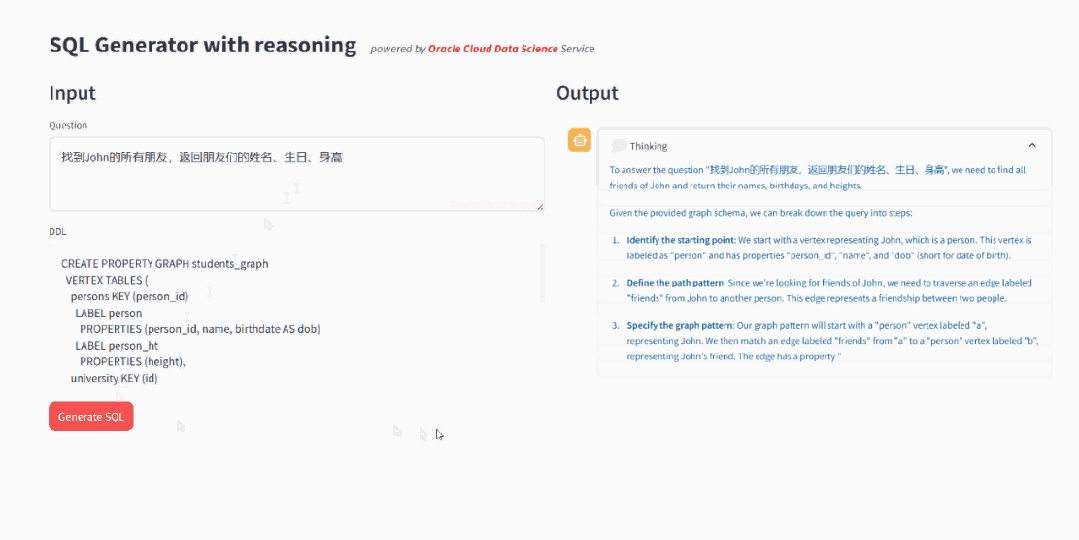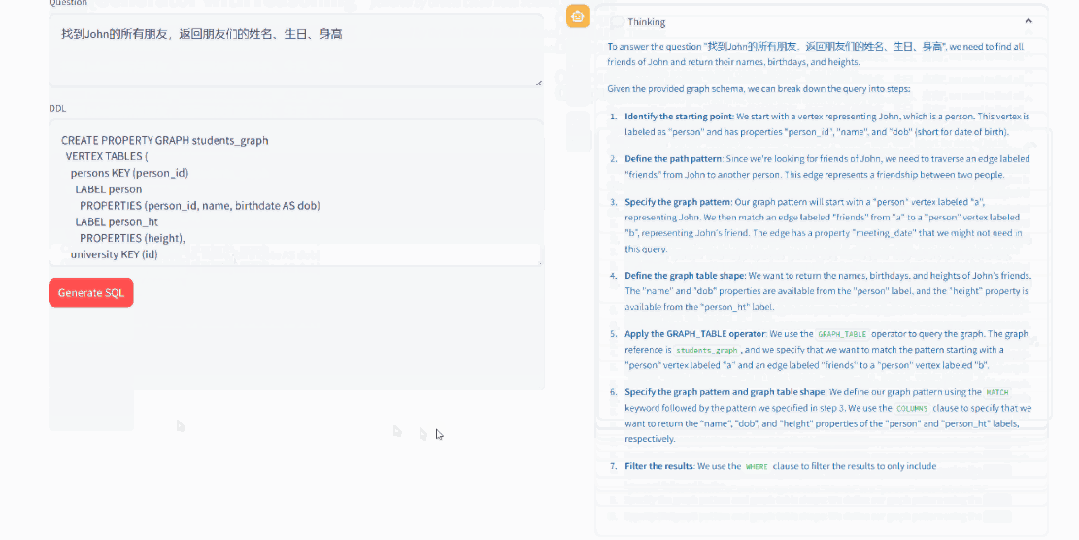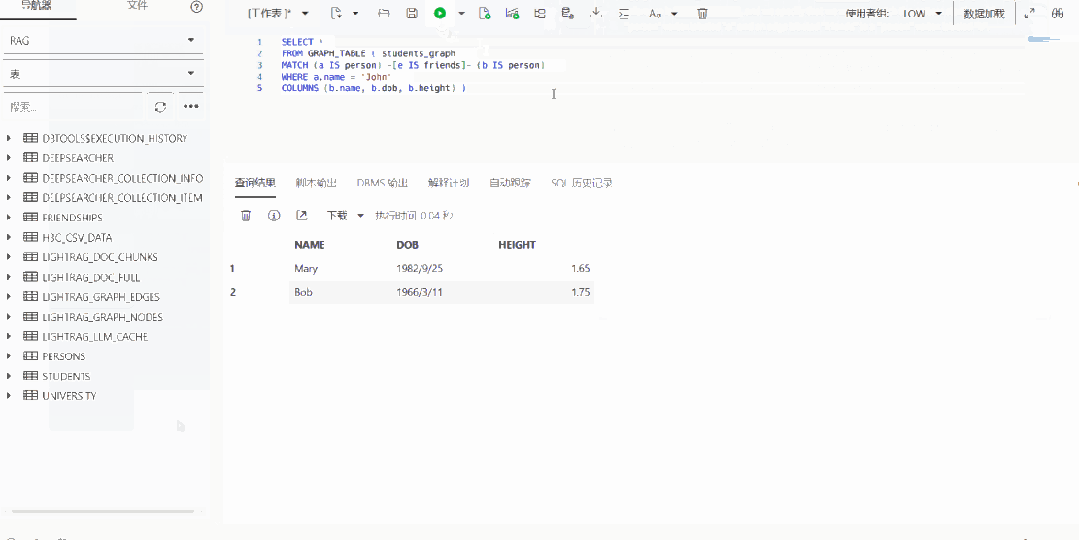
▲ 微调后的推理过程,模型学会了先“思考”再回答
使用评估数据集对微调后的模型进行完整的评估任务,从结果来看,BERT评级从基座模型的“Poor”提升为“Very good”,F1得分也有明显提高,表明微调后的模型在我们提供的特定数据集上,能力有了明显提升。
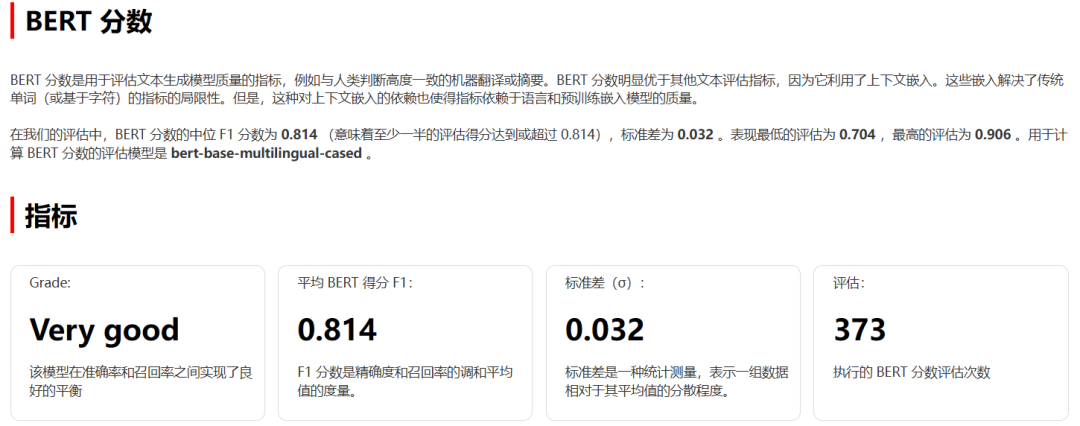
▲ 微调后模型评估报告,指标明显好于微调前
注意:本示例中的流程只是作为一种探索性实验,演示模型微调所具备的潜力,并不追求模型能力全面、稳定的提升,实际的模型微调需要大量的数据集整理和模型调试工作,把以上过程重复多次。
结语
本次实验展示了如何使用 Oracle AI Quick Actions,无需编写代码,轻松完成大模型的微调。借助 DeepSeek 技术报告中的蒸馏方法,我们利用大模型生成合成数据,使得普通模型也能具备推理能力。
AI Quick Actions 大幅降低了模型微调的门槛,让非 AI 专业人士也能定制和优化大模型,以满足各种业务需求。
如果你对 AI 领域感兴趣,不妨亲自尝试,让 AI 成为更专业的得力助手!
编辑:赵靖宇

