




关于作者:


在跨境场景下,我们面临的客户形式和背景会非常多样化。
一方面其中有一些客户是游戏公司,面向不同国家的用户提供一个提供游戏内购款相关的产品;还有一些是电商平台,包括自营平台和类似于淘宝这种为不同商户提供服务的平台。
另一方面我们的客户不仅仅是这些平台本身,还包括平台上的商户。这些商户在法律上是一个独立的商业实体,所以我们需要对这些实体有非常清晰明确的认识。

以上展示的是一张从公司官网上摘录的 UI 界面,帮助大家感受 Airwallex 的业务场景。
我们把 NebulaGraph 的使用场景分为四个主要类目:

(一)客户关系洞察
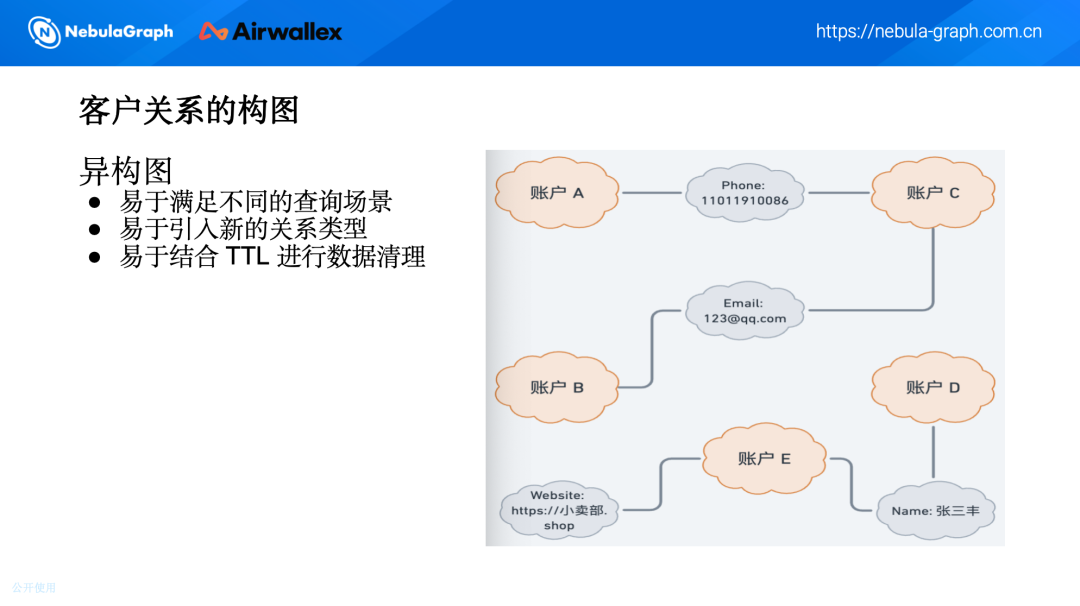
刚才已经简单提到,在跨境场景下,不同国家的法律法规有其特殊性,商业实体是法律上的基本单位,我们需要对这些实体进行分类和关联。这有助于我们了解客户所在地的法律法规和业务范围,确保合规性。
1. 个人信息关联
商业实体的授权人和法人:这些人的信息需要与商业实体相关联,以确保我们了解谁在实际控制和管理这些实体。
注册账户的实际操作者:当个人注册并使用我们的服务时,他们的邮箱、手机号等信息需要与他们的账户相关联,这有助于我们在需要时进行身份验证和风险评估。
2. 设备信息关联
涉及客户使用的设备,如 IP 地址、设备 ID 等。这些信息可以帮助我们识别异常登录行为,例如从不寻常的地理位置或设备进行的登录。
3. 网络信息关联
包括客户的网络行为和交易模式。通过分析客户的网络活动,我们可以识别异常的交易模式或潜在的风险交易。例如,频繁的大额交易或在短时间内从多个不同地点进行的交易都可能引发警报。
4. 人脸信息关联
这是生物识别技术的一部分,用于验证客户身份。
(二)实时交易关联
我们实时交易的时候,需要用 NebulaGraph 进行一些交易的关联。
设备信息关联,与 KYC 场景下的设备信息关联存在差异,这里的设备信息主要来源于集成了 Airwallex SDK 的支付组件。当用户进行支付操作时,会应用 Airwallex 不同平台的 SDK(移动端,网页端等),用户追踪设备 ID,设备型号,IP 地址等信息。
支付和收款信息的关联主要用于验证交易的合法性和安全性;在电商环境下,账单信息关联是识别异常购买模式和潜在欺诈行为的关键,而物流信息关联主要用于追踪商品流向和确保交易的完整性。
(三)模型特征提取
在模型特征提取方面,我们并不是直接使用原始数据,而是先对数据进行处理,生成特征。这些特征随后被用于不同模型的训练和实时推断。在线图服务运行时,会定期生成数据快照用于模型训练,同时在线服务也需要实时接口来计算特征,用于模型推断。
(四)可视化交互
我们目前的实现较为简单,主要面向内部运营人员。我们提供了一些 Web 页面,允许运营人员根据自身需求输入信息并进行操作,以实现按需查询和交互。
(一)背景
上述提到的客户关系洞察(KYC,Know Your Customer)是风控领域确保客户身份真实性和评估其风险状况的重要流程。它不仅在新客户注册时进行,还贯穿于客户整个生命周期,以应对客户资料或交易行为的变化。
KYC 的核心在于验证客户身份、了解其财务状况和风险特征,从而防止欺诈和金融犯罪。
图关系是 KYC 的自然表征。通过图数据库,可以将客户、账户、设备、交易等信息以节点和边的形式进行建模,直观地展示客户之间的复杂关联。例如,法人与商业实体的关联、账户与设备的关联等。这种结构化表示不仅提升了数据的可读性,还使得异常行为的识别更加高效,比如通过关联分析发现潜在的欺诈链条。
因此,我们使用 NebulaGraph 其实是一种非常水到渠成的选择。
(二)面临的问题
在引入 NebulaGraph 之前,我们使用的是一个简单的 Python 图服务,主要用于处理一些基础的图关系应用。当时公司还处于早期阶段,数据量相对较小,因此我们从离线数仓中读取所有数据,通过传统的操作提取点和边的信息,并将其存储在内存中构图。
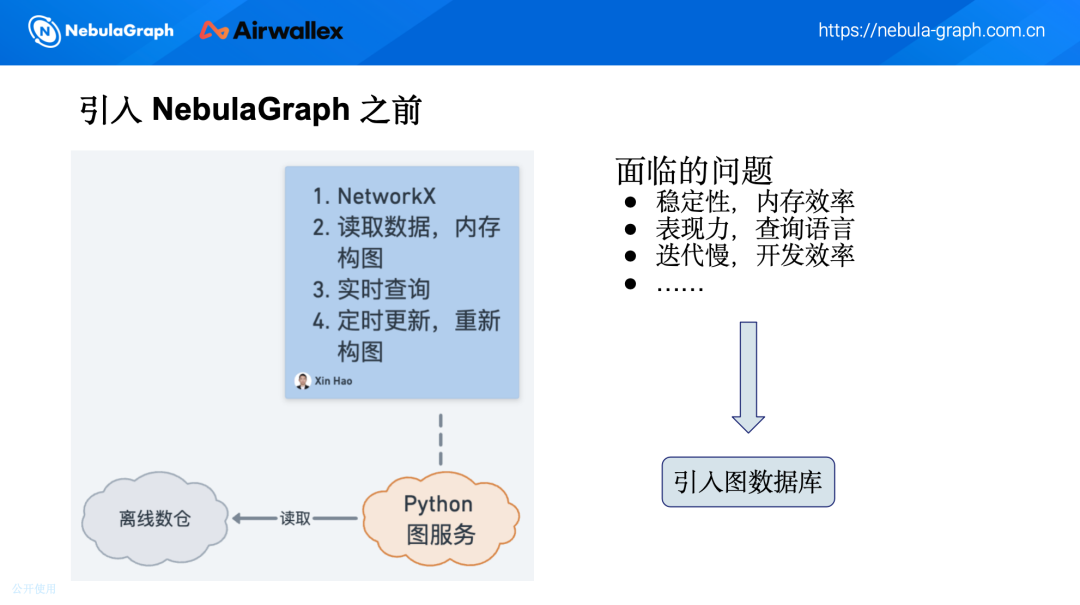
这种架构在数据量较小时表现尚可,但随着业务的发展,逐渐暴露出一些问题。
首先,稳定性不足,因为需要定时更新数据,每隔 10 分钟就需要重新读取和构图,这个过程容易出现故障。其次,内存效率较低,尤其是在数据量逐渐增加的情况下,内存占用成为一个瓶颈。此外,查询语言的表现力有限,无法满足复杂场景的需求,导致开发效率低下。这些问题促使我们考虑引入图数据库来解决业务中的挑战。
(三)NebulaGraph 选型

当时在选型时,我们对比测试了多个图数据库。我们淘汰了性能测试中表现不佳的一些图数据库,即使个别图数据库与 NebulaGraph 性能接近,但在功能全面性上有所欠缺。此外, NebulaGraph 拥有丰富的企业应用案例也是我们选择它的重要因素。
四、系统架构设计

1. 数据写入
小时级批处理(全量):通过一个中等量级的属性更新,将所有数据一次性写入到数据库。
业务系统实时数据补齐(增量):在新客户注册时,由于没有历史数据,业务系统会通过 API 实时补齐数据,并写入到数据库中。
2. Schema First
Schema as Code:所有字段的定义和变更都在代码中完成,自动生成功能确保了数据的一致性。
单一 Schema:既用于服务代码,同时也生成 ETL 的 Schema。这样可以确保数据的一致性和开发效率。
我们的图服务主要用于以下几个方面:
1. 模型特征提取
我们需要实时进行客户分析,以及其他不同场景下的交易和用户行为分析。
2. 规则引擎
这是我们内部的一个风控引擎,通过图的特征数据进行规则处理,最终做出不同的判断。
3. 业务服务
内部的其他业务服务可以利用图数据库的数据进行相应的处理。
4. 可视化
提供一些界面让运营人员进行查询和分析。
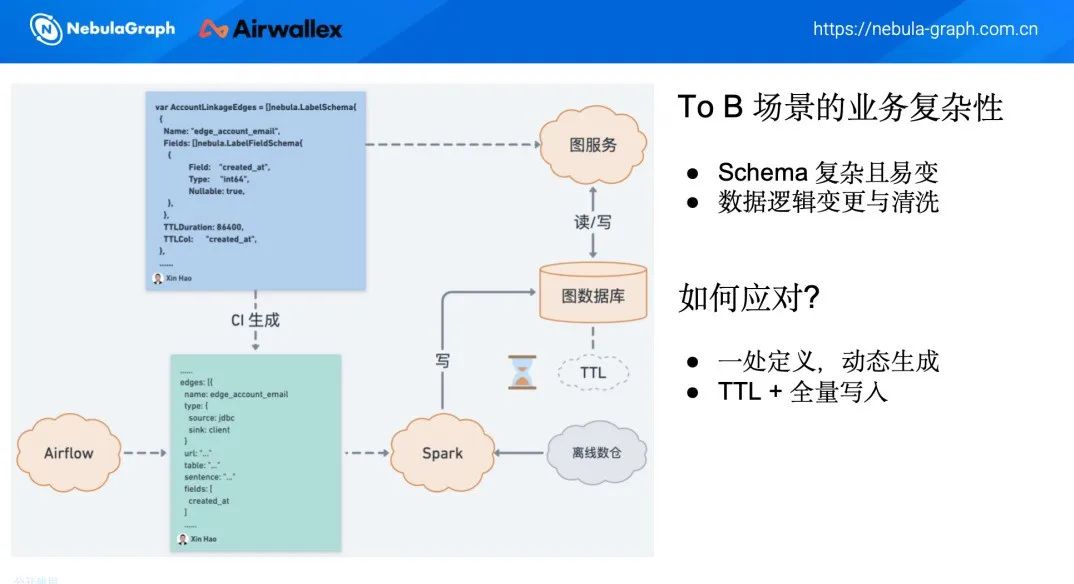
1. Schema复杂且易变
数据模式复杂,节点类型多样(约 10 多种),不同节点上的属性信息差异较大。
数据模式变更频繁,每月可能有局部调整,需要灵活的管理流程。
2. 数据逻辑变更与清洗
数据清洗和逻辑变更需要一个易于操作的流程,以应对业务的快速变化。
1. 一处定义,动态生成
在代码中统一定义数据模式(Schema),每次代码提交时自动生成相应的数据模式定义。
修改字段名称、添加字段或调整属性时,只需在代码中操作,系统会自动生成变更语句并逐步完成自动变更。
2. TTL + 全量写入
使用 TTL 机制结合全量写入的方式,确保数据的时效性和完整性。

我们采用了一种 Declarative 的 Schema 管理方式。 当我们对一个字段进行命名、添加、属性信息进行修改的时候的时候,会在内部自动生成相应的变更语句。
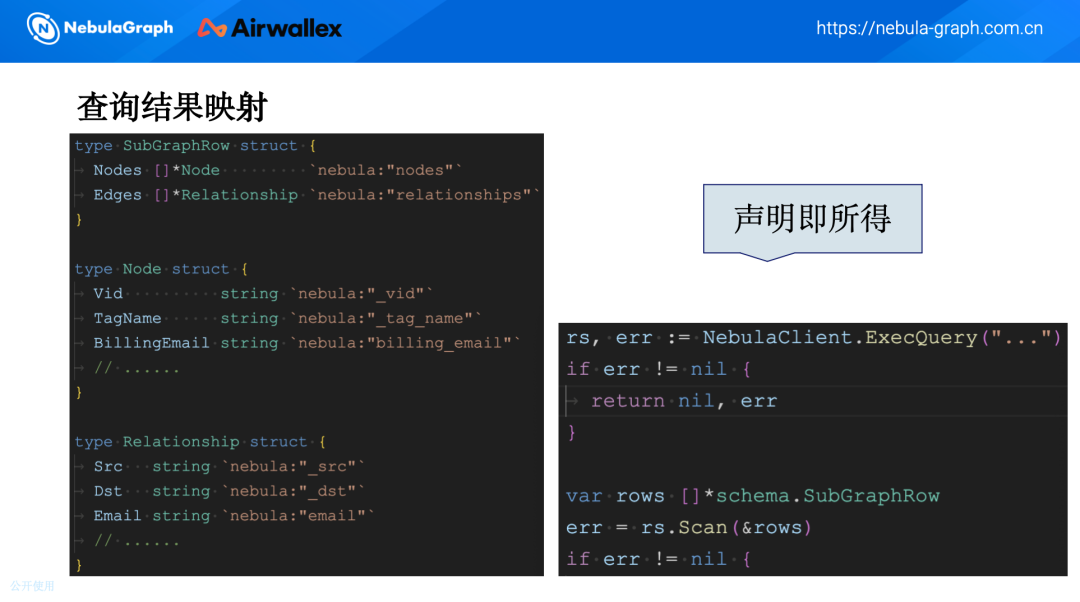
在查询结果映射方面,我们采用了“声明即所得”的方式。
通过在代码中定义结构体,并使用注解直接映射查询结果中的字段,查询结果会自动填充到对应的结构体字段中,无需手动处理字段映射。此外,通过 SDK 或接口动态获取字段信息,确保每次查询都能正确映射到最新的 Schema,避免了因字段变化导致的查询错误,提高了系统的稳定性。



在交易关联系统中,与客户关系系统存在较大差异,在这里,我们对实时性要求更高,因此我们采用了分离计算、读时合并的架构。
历史数据(超过 4 小时)通过小时级批处理进行预计算,生成子图的点边信息,并存储在图数据库中。实时数据(4 小时以内)则通过 Kafka 实时获取上游交易的原始数据,在服务端进行拆分和构建后写入 NebulaGraph.

目前,单一 Nebula 集群在计算资源隔离方面存在不足,导致不同应用间的查询峰值会相互干扰,且一套集群无法同时满足 TP(事务处理)和 AP(分析处理)的目标。此外,图算法的支持也存在一定的开放性不足和生态不够丰富的问题。
在未来,我们希望能够改善这些问题,通过更好的资源隔离技术和更丰富的图算法生态,来提升系统的性能和可用性。我们期待与社区和其他开发者一起合作,共同推动技术的发展和生态的建设。
「ps:本文整理自 Airwallex 在 NebulaGraph 社区 nMeetup 上的分享,Airwallex 目前已升级为 NebulaGraph 企业版」
欢迎关注 Airwallex 公众号
了解更多跨境金融相关资讯
✦
如果你觉得 NebulaGraph能帮到你,或者你只是单纯支持开源精神,可以在 GitHub 上为 NebulaGraph 点个 Star!每一个 Star 都是对我们的支持和鼓励✨
https://github.com/vesoft-inc/nebula
✦
✦

扫码添加
可爱星云
技术交流
资料分享
NebulaGraph 用户案例
✦
风控场景:携程|众安保险|中国移动|Akulaku|邦盛科技|360数科|BOSS直聘|金蝶征信|快手|青藤云安全|
平台建设:博睿数据|众安科技|微信|OPPO|vivo|美团|百度爱番番|携程金融|普适智能|BIGO
✦
✦







