





点击蓝字关注我们
本文提供了一些关于调整TCP设置的建议,这些设置既可以在PostgreSQL级别,也可以在内核级别进行调整,以便比默认行为更快地终止挂起的连接。
TCP连接可能会处于以下两种状态之一:要么是空闲状态,即没有待交付的应用程序数据排队;要么是有发送队列,操作系统进入重试循环,尝试重新传输数据。
TCP keepalive 是一种机制,用于确定TCP连接的另一端是否已停止响应,或者连接在本地处于空闲状态。
主机将在一段时间的空闲时间后向另一主机发送多个 keepalive探测包。如果收到回复,它可以假设连接仍然正常运行,否则,套接字将被关闭。这也可以防止中间的有状态的网络设备(防火墙、入侵检测系统)由于不活动而丢弃连接。
只要本地主机尝试发送数据,空闲连接就会切换到重试模式,无论已经发送了多少keepalive数据包。如果应用程序实现了自己的keepalive机制,通过定期发送一些数据(例如PostgreSQL的walsender),这会有效覆盖TCP keepalive机制。
“连接超时”错误可以告诉我们连接在超时之前处于哪种模式:如果 read 系统调用收到错误,它可能处于空闲状态,如果 write 系统调用报告超时错误,则更可能处于重试模式。
TCP重试
每当有数据需要发送,但由于某种原因未能到达目的地时,TCP会以指数退避的方式重试,以避免进一步加重可能已经拥塞的网络。以下两个参数控制Linux内核级别的TCP重传。
sudo sysctl net.ipv4.tcp_retries1 - 通知底层网络栈检查目的地的不同路由之前重试的次数。对用户空间应用程序没有任何影响。
sudo sysctl net.ipv4.tcp_retries2 - 在放弃并通知用户空间应用程序连接丢失(即关闭TCP套接字)之前,总体重试次数。
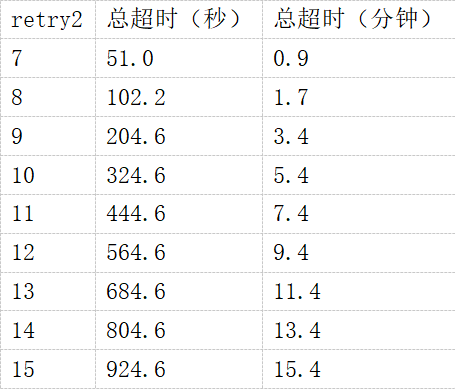
对于像Postgres这样的应用程序,只有后一个设置是相关的。默认值为15次重试,因此只有在第15次重传尝试在没有确认的情况下,内核才会关闭TCP连接。重试之间的延迟称为重传超时(RTO),从200毫秒开始,并呈指数增长。直到限制达120秒的最大值。默认的15次retry2设置导致15.4分钟的超时,下表列出了其他值的预期超时时间。
【注意】
RFC 1122“互联网主机的要求”建议(“应该”)最小100秒,因此8次retry2的设置似乎是最低的合规设置。
目前没有办法仅针对Postgres TCP连接进行调整,因此系统范围的更改显然会影响其他应用程序和服务。
TCP Keepalive
Keepalive行为可以仅针对PostgreSQL连接进行配置,也可以在整个主机范围内进行配置。
PostgreSQL级别设置
PostgreSQL在 postgresql.conf 文件中有3个参数用于处理TCP keepalive设置:
tcp_keepalives_idle:在TCP应该向客户端发送keepalive消息之前的不活动秒数。
tcp_keepalives_interval:在客户端未确认TCP keepalive消息后,重传的间隔秒数。
tcp_keepalive_count:在服务器与客户端的连接被视为死亡之前,丢失的TCP keepalive消息的数量。
这三个设置共同控制PostgreSQL关闭在网络数据包方面不活动的空闲连接所需的时间。它们也可以被调整为积极检测死客户端。一个激进的设置可以确保,如果客户端不再能够连接到数据库,那么任何挂起的连接都会很快被关闭。
死连接可以保持空闲的时间由以下公式给出:
tcp_keepalives_idle + (tcp_keepalive_count * tcp_keepalives_interval)复制
可以通过在 postgresql.conf 文件中查看或运行以下SQL命令来验证这些设置的值:
SELECT name, setting FROM pg_settings WHERE name ~ 'keepalive';复制
这些参数默认设置为0,这意味着将使用操作系统的设置。
Linux内核中的默认TCP keepalive设置(以秒为单位)如下:
net.ipv4.tcp_keepalive_intvl = 75net.ipv4.tcp_keepalive_probes = 9net.ipv4.tcp_keepalive_time = 7200复制
tcp_* 设置在 ipv4 下也适用于IPv6,因此如果您使用IPv6连接,则不需要额外的参数更改。
这意味着TCP keepalive进程在等待 两小时(7200秒)的套接字不活动后才发送第一个keepalive探测,然后如果未收到 ACK(确认)则每75秒重新发送一次。如果连续九次未收到 ACK 响应,则连接被标记为已断开。
如果您希望在主服务器和备用服务器之间正确配置流复制,尤其是当网络不稳定时,这些值有点过高。
确切的值取决于客户端和网络,但在 postgresql.conf 文件中的以下设置可能是一个好的起点:
tcp_keepalives_idle = 600tcp_keepalives_interval = 60tcp_keepalives_count = 6复制
要更改这些参数,只需重新加载PostgreSQL服务即可。这意味着不会产生停机时间。在 postgresql.conf 中设置可以确保仅应用于PostgreSQL连接。
与 statement_timeout 的交互
当查询取消发生时(由于 statement_timeout 或其他原因,如 pg_cancel_backend()),数据库服务器必须在释放服务器端的后端资源之前向客户端发送一条消息,通知事件的发生。
PostgreSQL协议发送的数据以大小为前缀,并且只有在传输了该数量的数据后才接受下一个控制命令。
但如果在取消发生时,大量数据正在传输中或网络无响应,那么取消消息还不能发送,因为它必须等待数据发送完成。
这意味着在某些情况下,特别是当网络无响应时,statement_timeout 设置可能不会立即中断查询。
因此,在需要 statement_timeout 快速释放后端资源的情况下,最好调整它和 tcp_keepalive_* 设置,以便网络中断可以像希望 statement_timeout 那样快速地被识别。
一般来说,应尝试在它们之间保持以下关系:
tcp_keepalives_idle + (tcp_keepalive_count * tcp_keepalives_interval) < statement_timeout复制
请注意,statement_timeout 影响应用程序的查询和事务,因此其值应与应用程序团队讨论,并与应用程序工作负载一起仔细测试。
在驱动程序中设置参数
可以在客户端为每个连接设置TCP keepalive参数。但是,执行此操作的步骤可能因驱动程序和应用程序而异。
libpq(PostgreSQL和EPAS)
当使用 libpq(PostgreSQL的内置客户端库)时,可用的选项与服务器设置类似,但没有 tcp_ 前缀:
keepalives(默认1,启用):控制是否使用客户端TCP keepalives。
keepalives_idle(默认0,使用系统值):控制在TCP应该向服务器发送keepalive消息之前的不活动秒数。
keepalives_interval(默认0,使用系统值):控制在服务器未确认TCP keepalive消息后,重新传输的秒数。
keepalives_count(默认0,使用系统值):控制在客户端与服务器的连接被视为死亡之前,可以丢失的TCP keepalive消息的数量。
JDBC驱动程序(社区版和EDB)
JDBC驱动程序只有一个选项,可以用于启用TCP keepalives,但不能控制超时或计数:
tcpKeepAlive(布尔值;默认false,禁用):启用或禁用TCP keep-alive探测。
.Net驱动程序(社区版和EDB)
Tcp Keepalive(默认false,禁用):是否使用系统默认值的TCP keepalive,如果未指定覆盖值。
Keepalive(默认0,禁用):连接不活动的秒数,之后Npgsql发送一个keepalive查询。
Tcp Keepalive Time(默认0,禁用):连接不活动的毫秒数,之后发送TCP keepalive查询。如果可能,建议使用KeepAlive而不是此选项。仅在Windows上受支持。
Tcp Keepalive Interval(默认值为 Tcp Keepalive Time):如果未收到确认,则连续发送keep-alive数据包之间的间隔,以毫秒为单位。Tcp KeepAlive Time必须为非零。仅在Windows上受支持。
EDB OCL和ODBC(社区版和EDB)
OCL和ODBC都基于 libpq,因此必须在连接字符串中设置 libpq 参数。
有关如何编辑OCL驱动程序的连接字符串的详细信息,请参阅OCL - 形成连接字符串。https://www.enterprisedb.com/docs/ocl_connector/latest/04_open_client_library/02_forming_a_connection_string/
有关如何编辑ODBC驱动程序的连接字符串的详细信息,请参阅ODBC配置选项。https://odbc.postgresql.org/docs/config.html
内核级别设置
要在全局级别更改它们,必须配置内核TCP keepalive参数。为此,我们建议首先通过命令行设置TCP keepalive参数进行测试:
sudo sysctl net.ipv4.tcp_keepalive_time=600sudo sysctl net.ipv4.tcp_keepalive_intvl=60sudo sysctl net.ipv4.tcp_keepalive_probes=6复制
一旦找到适合应用程序的配置,可以通过将以下行(使用您选择的值)添加到 etc/sysctl.conf 中,使这些设置在重新启动后保持不变:
net.ipv4.tcp_keepalive_time = 600net.ipv4.tcp_keepalive_intvl = 60net.ipv4.tcp_keepalive_probes = 6复制
监控TCP重试和keepalive
ss 工具具有 -o 或 --options 参数,该参数以下格式显示TCP套接字的超时状态:
timer:(,,)复制
第一个字段是计时器名称(on、keepalive、timewait、persist 或 unknown)。第二个字段是计时器到期的时间。第三个字段是重传的次数。有关详细信息,请参阅 man 8 ss。
示例输出
使用默认端口、用户名和数据库名建立本地TCP连接到PostgreSQL:
psql 'host=localhost keepalives_idle=60 keepalives_interval=15 keepalives_count=3'复制
之后,可以使用 ss 在数据库端口(5432或默认的 postgresql)上观察它:
% watch -t ss -o dport postgresqlNetid State Recv-Q Send-Q Local Address:Port Peer Address:Port Processtcp ESTAB 0 0 [::1]:58044 [::1]:postgresql timer:(keepalive,12sec,0)复制
在健康的连接中,重传计数保持为0,计时器在60秒到0秒和15秒到0秒之间反复波动,因为套接字在等待空闲时间或keepalive间隔(一次),然后返回到空闲时间。
在不健康的连接中,计时器从60秒倒计时一次,然后从15秒倒计时三次,增加重传计数,直到连接终止。
关于公司
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!
 |  |
Elastic 微信群 | EDB 微信群 |
发现“分享”和“赞”了吗,戳我看看吧
