




本文对达姆施塔特工业大学(Technical University of Darmstadt)的2024 SIGMOD论文《CAESURA: Language Models as Multi-Modal Query Planners》进行解读,文共3981字,预计阅读需要15至20分钟。
在大数据时代,传统查询规划器能将SQL查询转为关系型数据上的查询,但无法查询数据湖等现代数据系统中的图像、文本、视频等其他数据模态。本文提出语言模型驱动的查询规划,利用语言模型把自然语言查询转为可执行查询计划,生成的计划可含处理任意模态的复杂操作符。文中展示了基于GPT-4的原型系统CAESURA,并在两个数据集上验证该想法的可行性,最后还探讨了提升当前语言模型查询规划能力的思路。
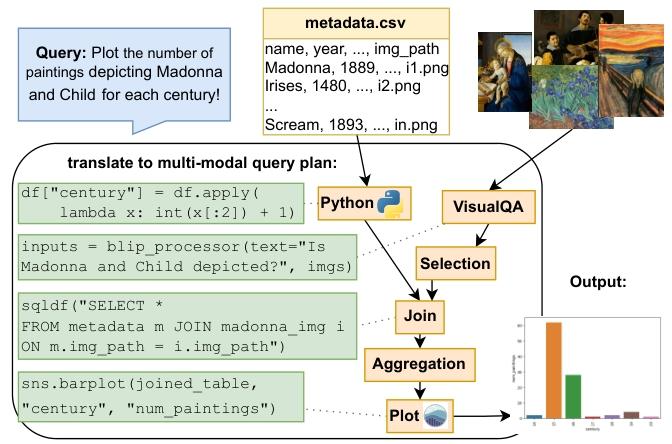
自然语言查询转化为多模态查询执行过程
1. 研究背景与动机
1.1 传统查询规划存在的不足
自1974年以来,查询规划的基本概念变化不大,在传统数据库管理系统中,查询规划是先解析 SQL 查询得到逻辑计划,优化后映射为物理计划再执行。然而,这样的传统方式存在两大局限:
1. 仅适用于SQL这类语义清晰,可解析规范查询计划的语言
2. 可查询的数据类型有限,只能查询结构化关系数据
1.2 新趋势带来的挑战
1.2.1 多模态数据
如今行业中,大量非关系型多模态数据需要存储和处理,如医疗机构的 MRI 扫描、患者报告和结构化元数据。这些数据难以在传统数据库中存储和查询,通常被存放在数据湖中。虽然有系统尝试解决多模态数据查询问题,但都存在局限性,如查询复杂度受限、支持的模态少等。理想的数据系统应能支持各种查询,并自动构建数据处理管道,方便用户跨模态获取数据洞察。
1.2.2 自然语言接口
SQL设计初衷是便于普通人理解,但编写复杂的SQL查询需要对该语言有深入了解。其过程繁琐,这使得数据库对领域专家和管理人员不够友好。近年来,为进一步方便非专业人士使用数据库,自然语言接口逐渐推广,大多将自然语言转换为 SQL。但同样存在两个问题:
1.仅局限于关系型数据
现有自然语言接口通常将自然语言翻译为SQL来实现数据库查询,这就导致其局限于关系型数据。SQL是专门为关系型数据库设计的查询语言,它基于关系代数和关系演算,针对的是结构化、以表格形式组织的数据。
2.问答系统查询表达能力不如SQL
问答系统主要聚焦于对简单问题提供直接答案,设计初衷并非像 SQL 那样进行复杂的数据操作和组。SQL 有严格且丰富的语法规则,能精确表达复杂的数据操作意图。
1.3 提出CAESURE的动机
因此,在本文中,我们提出了一个数据系统的愿景,该系统可以由外行使用自然语言使用,并且可以查询任意数据模态,同时支持超越传统 SQL 的复杂用户查询。具体满足以下三个需求:
1.3.1 满足非专业用户使用需求
期望构建一个能让非专业人士(laypersons)使用自然语言操作的数据系统,降低数据查询门槛,使更多人能够方便地进行数据查询操作
1.3.2 实现多模态数据查询
现有系统难以支持对任意数据模态(arbitrary data modalities)的查询,而实际应用中存在多模态数,需要新的数据系统来处理这些多模态数据的查询。
1.3.3 处理复杂用户查询
传统 SQL 无法满足复杂用户查询的需求,希望新的系统能够处理远超传统 SQL 的复杂用户查询,以应对更复杂的业务场景和用户需求。
2. CAESURA框架设计
2.1 CAESURE实现过程
为解决现有方法的局限性,让非专业人员能够方便地使用自然语言操作该系统,实现多模态数据的查询。CAESURA框架应运而生。CAESURA的核心思想是利用大模型(LLMs)实现多模态数据的查询规划。具体来说,CAESURA通过以下方式实现查询计划:
1. 输入:用户输入查询语句以及数据源文件。
2. 多阶段提示过程:采用多阶段编译策略,判别用户查询利用python将逻辑计划转换为物理操作实现查询。
3. 执行过程:根据prompt,告知模型扮演的CAESURA角色,判断观测结果并做出决策。
2.2 多阶段提示过程
采用多阶段编译策略,包括发现阶段、规划阶段和映射交叉执行阶段。在发现阶段确定相关数据源,规划阶段生成逻辑计划,映射交叉执行阶段将逻辑步骤映射为物理操作符并逐步执行。
◆ 发现阶段:确定与查询相关的元数据,即识别出相关字段
◆ 规划阶段:根据元数据生成逻辑计划
◆ 映射交叉执行阶段:将逻辑计划转换为物理计划
最后通过实验证明,CAESURA 能够对用户查询、数据及可用操作符展开推理,将用户查询转化为准确的多模态查询计划。
2.3 存在挑战
尽管大语言模型具备各种能力,但在将其用于查询规划时仍存在许多挑战。接下来,我们将讨论一些主要的开放性研究挑战,并在后续章节中针对这些挑战提出一些我们认为可以如何应对的思路。
2.3.1 计划可执行性
LLMs生成的查询计划可能因操作符输入错误等原因无法执行。CAESURA整合并利用LLMs提供的替代计划修复错误的方法,虽然经过证明后该方法有一定效果,但仍不足以确保查询计划按用户预期顺利执行 。
2.3.2 计划正确性
由于大语言模型不会判断计划的正确性,所以即使LLMs生成的查询计划可执行,也可能存在逻辑缺陷导致结果错误。非专业人士难以判断结果正确性,目前的解决方案包括通过微调训练大语言模型来提高其推理能力。
2.3.3 计划可优化性
语言模型未经过优化的计划可能会导致巨大的运行开销。然而,优化多模态查询计划需要对复杂的多模态操作进行推理。这需要一定的模型学习成本,才能实现优化多模态查询计划。
3. CAESURA工作原理
3.1 CAESURA概述
CAESURA 参照传统查询规划的各个阶段开展工作。与传统数据库的不同在于CAESURA 的逻辑计划采用LLMs对各个步骤描述后转化为物理计划。步骤如下:首先确定相关的数据源,然后在规划阶段让大语言模型(LLM)生成逻辑计划,最后在映射阶段让大语言模型选择操作符以得到物理计划。
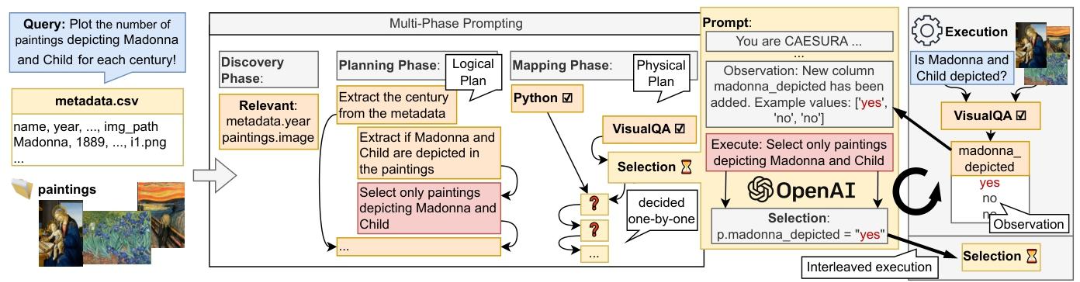
CAESURA 通过一系列提示将查询转换为多模态查询计划
3.2 查询计划的各个阶段
将查询规划过程总共划分为3个阶段,分别为:发现阶段,规划阶段,映射交叉执行阶段。根据每个阶段的特定决策来定制用于查询规划的提示。
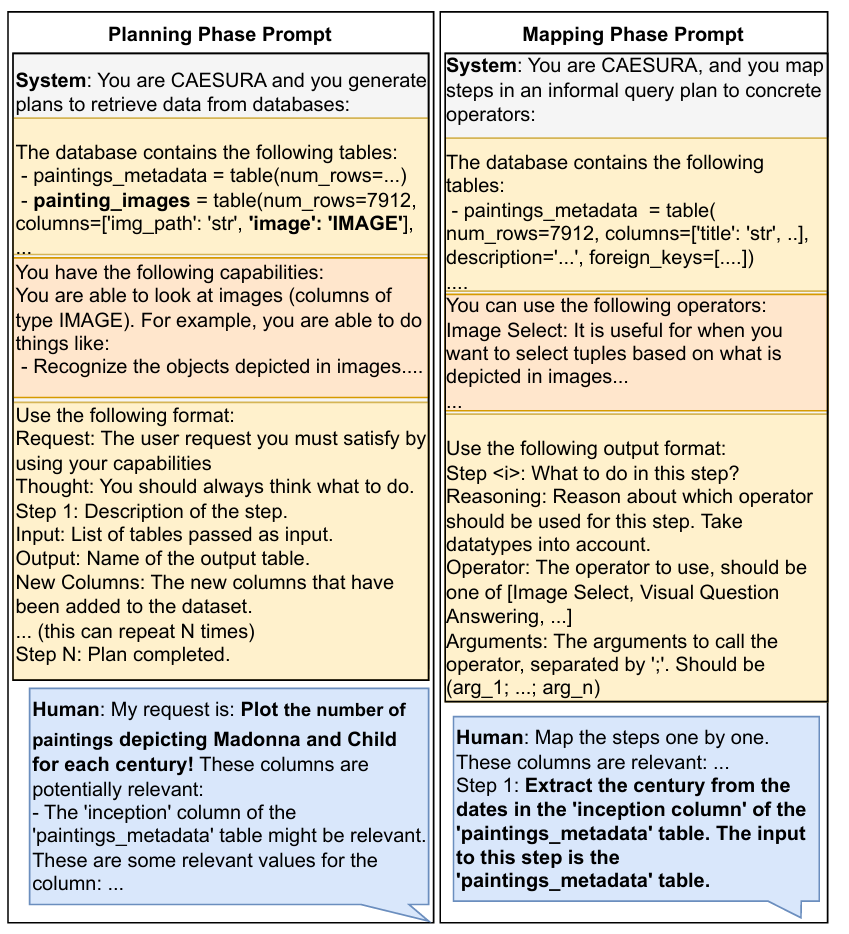
3.2.1 发现阶段
在该阶段中,CAESURA主要目标是确定能为当前的查询提供信息的数据源。首先,CAESURA通过密集检索法缩小相关多模态数据范围;其次,对于表格形式的数据源,大语言模型会判断已检索数据与用户查询的相关性。这些相关数据项会被做下一阶段的提示信息。
3.2.2 规划阶段
规划阶段是CAESURA的核心部分。在该阶段中 ,CAESURA的主要目标是向LLMs给出提示,让其提出能够满足用户需求的逻辑查询计划的自然语言描述。
提示由几个部分组成:
1)数据描述
2)CAESURA 的功能
3)输出格式描述
4)用户查询内容和指示模型提出计划的指令
然后将分类后的多模态数据建模为特殊的两列表格(一列标为图像)CAESURA 在可用操作符的帮助下,输出能够执行的逻辑操作提示。接下来,大语言模型会先生成分步(文本形式)的计划,后解析为逻辑计划。
3.2.3 映射交叉执行阶段
映射交叉执行阶段是CAESURA的最后一个阶段,在该阶段中,CAESURA主要目标是将之前确定的每个逻辑步骤映射到一个物理操作符(及输入参数)上。与传统查询规划不同的是,CAESURA实现交错执行映射操作,使得 CAESURA 能够对之前操作返回的结果做出反应,从而产生更多实际上可执行的计划。
3.3 错误处理
当CAESURA查询规划遇到错误时,采用将错误信息加入提示词让大语言模型处理的方式。但困难在于经常不知道错误的根源,因为这可能是前面任意阶段产生的,比如规划阶段选了不存在的列做筛选,到执行时才发现。
3.3.1错误处理的基本方法
错误处理的方法主要包含以下四个方面:
◆ 利用大语言模型先找出错误发生阶段,然后回溯。
◆ 借助包含特定问题的提示词引导大语言模型推理错误,如潜在原因、修复方法等。
◆ 对问题答案的分析判断回溯到规划阶段还是映射阶段出了问题
◆ 将关于错误原因和修复思路的信息添加到回溯点提示词中,再重新执行。
3.3.2 错误处理方法的局限性
该处理方法能可以修复大多数不可执行的计划,但还是存在一些特殊错误情况,同时无法判断可执行计划本身的结果是否正确。
4. 测试结果分析
4.1 实验案例
实验中,主要目标是关注 CAESURA 是否能够构建正确的查询计划。分别构建了两个多模态数据集进行测试:罗托威篮球数据集(包含表格和文本),艺术品数据集(包含表格和图像)。
4.1.1 篮球赛事分析示例
查询1:“对于每支球队,他们在一场比赛中得分的最高值是多少?”
CAESURA 的执行步骤:
1.首次表连接:将name列连接teams表与team_to_games表,合并两表数据。
2.二次表连接:再次使用 SQL 的 JOIN 操作,基于 “game_id” 列连接两表,生成final_joined_table。
3.文本信息提取:借助 Text QA 操作符提取每支球队的单场得分,新增points_scored列记录。
4.分组聚合计算:通过 SQL 聚合操作,team_name列分组,计算每组 points_scored的最大。
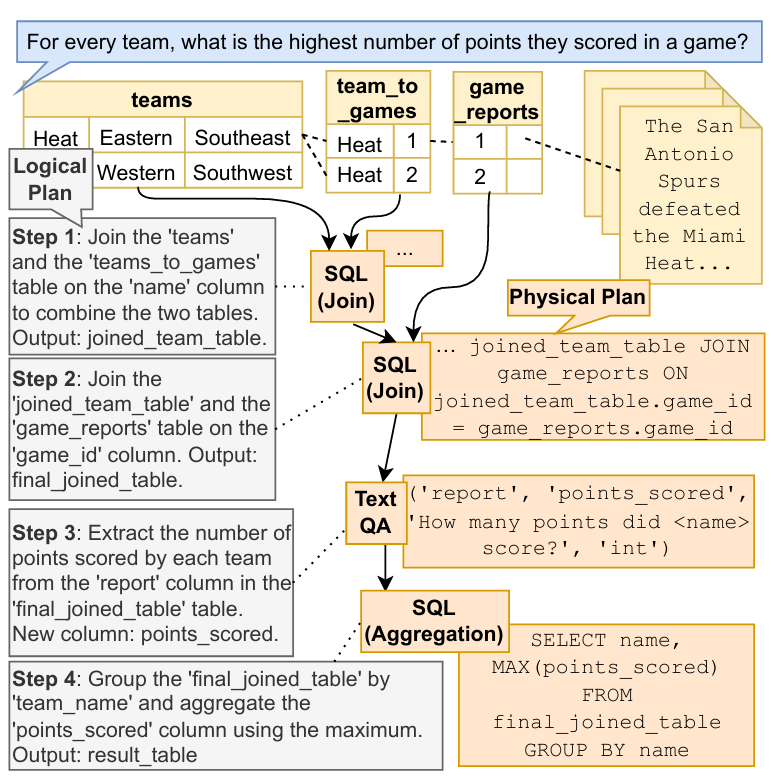
GPT-4 下 CAESURA文本问答(TextQA)
4.1.2 艺术作品查询示例
查询2:“绘制每个世纪绘画作品里所描绘剑的最大数量”
CAESURA 的执行步骤:
1.视觉信息提取:使用VisualQA提取图像中描绘的剑的数量。
2.时间转世纪处理:利用Python提取inception列的创作时间添加century列。
3. SQL 聚合操作:按century列对joined_table分组,计算每组num_swords的最大值,生成max_num_swords列。
4.绘制图表:分别以century为 X 轴、max_num_swords为 Y 轴绘制柱状图
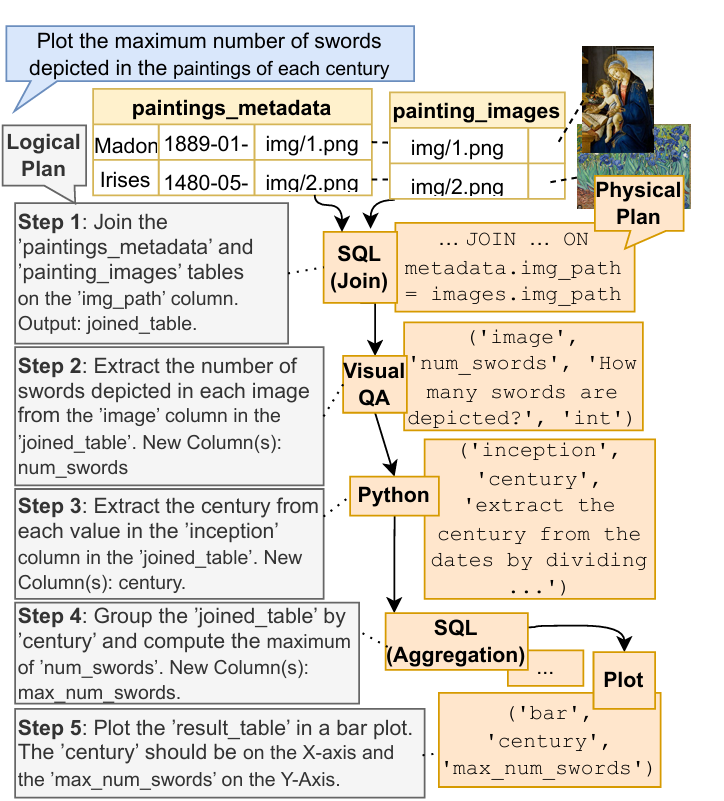
GPT-4 下 CAESURA视觉问答(VisualQA)python操作符
CAESURA 借助两个多模态操作符(Python 和 VisualQA 操作符,之后是绘图操作符)来正确翻译该查询。
4.2 查询计划质量
分别采用了GPT-3.5和GPT-4模型对两个数据集进行逻辑和物理规划的正确率评估。结果表明:
◆ 在所有场景的平均准确率(逻辑 93.8%,物理 87.5%)显著高于 ChatGPT-3.5(逻辑 64.6%,物理 56.2%)
◆ 逻辑规划的正确率高于物理规划。
◆ GPT-4模型的正确率在艺术品数据集中实现双 100%,表明其在多模态、图表生成等复杂任务中优势突出。
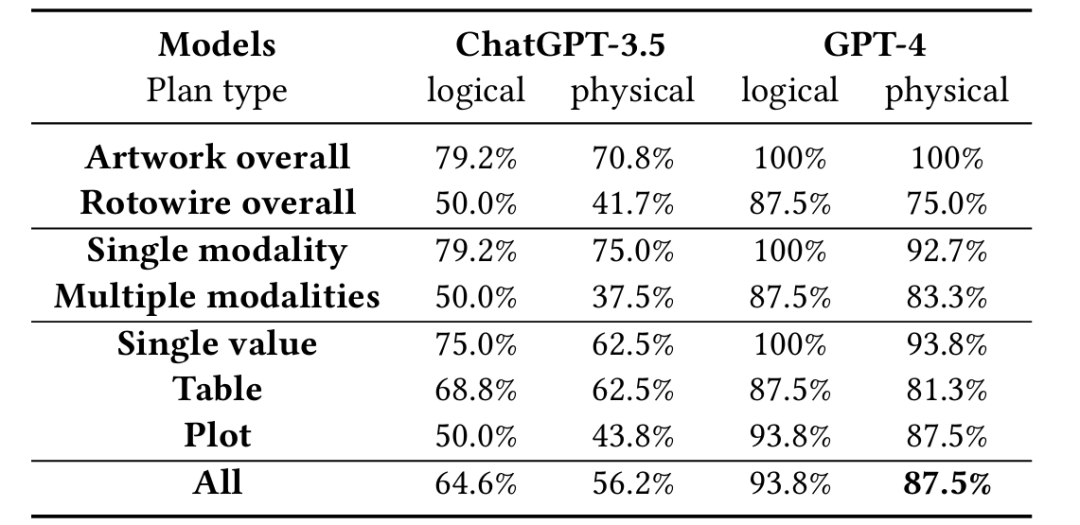
不同数据集、模态和输出格式下正确生成的逻辑,物理计划百分比
4.3 错误分析
在逻辑层面上GPT-3.5多次错误理解数据模态或类型,也出现多次不符合逻辑以及不可能的决策。GPT-4的表现结果较好,仅出现1次数据误解。GPT-4中常见的错误发生在物理操作过程中选择了错误的输入参数。
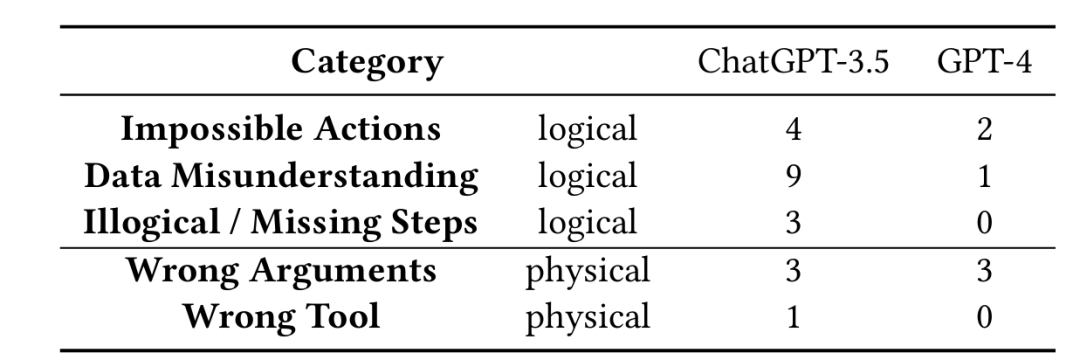
CAESURA 在查询规划过程中产生的具体错误类型数量
5. 结论与未来展望
5.1 结论
CAESURA通过引入大模型以及多阶段提示过程,既能够根据自然语言查询自动生成处理流程,还实现了处理复杂的多模态数据。测试结果表明CAESURA在处理不同格式和模态下的数据集结果表现良好,准确率较高,有一定的应用可行性。
5.2 未来展望
未来研究中,仍存在诸多挑战如大模型幻觉,推理能力不足等。CAESURA将会进一步提高其准确率与可行性。除此,CAESURA将进一步优化多模态操作符运行效率,减少查询计划崩溃的情况。最后,为防止LLMs被恶意攻击造成数据泄露情况发生,提升数据库安全性的工作同样至关重要。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





