背景
谓词下推(Predicate Pushdown)是SQL优化中常用的技术,其核心思想是将过滤条件下推到更接近数据源的查询层(本文专注在下推至子查询),减少后续处理的数据量,从而提升查询性能。本文基于PawSQL优化器中谓词下推重写优化算法的实现,分析各种场景下的谓词下推策略。

场景一:基本子查询的谓词下推
PawSQL对基本子查询谓词下推的核心是识别外层查询中引用子查询结果的过滤条件,并将其转换为子查询的WHERE子句。当SQL具有形如SELECT * FROM (SELECT...) t WHERE t.column > value
的结构时,优化器会将外层谓词条件映射到子查询中。
优化前:
SELECT t1.*FROM (SELECT id, name, age FROM employee) t1WHERE t1.age > 30;
优化后:
SELECT t1.*FROM (SELECT id, name, age FROM employeeWHERE age > 30) t1;
这种重写使过滤条件在数据源层面应用,减少了中间结果的传输和处理量。
场景二:组合查询的谓词下推
在处理UNION/INTERSECT/EXCEPT等组合查询时,PawSQL会确保谓词条件对所有组合分支都有效,并将谓词分别下推到各分支查询中,同时保持组合操作的语义正确性。
优化前:
SELECT *FROM (SELECT id, department, salaryFROM employee_currentUNIONSELECT id, department, salaryFROM employee_history) combinedWHERE combined.salary > 5000;
优化后:
SELECT *FROM (SELECT id, department, salaryFROM employee_currentWHERE combined.salary > 5000UNIONSELECT id, department, salaryFROM employee_historyWHERE combined.salary > 5000) combined;
这种重写显著减少了需要执行UNION操作的数据量,提高查询效率。
场景3:连接查询的谓词下推
连接查询的谓词下推需要考虑连接类型和谓词条件的性质。PawSQL会分析连接操作中各表达式的来源,识别谓词所属的具体子查询,并根据连接类型评估下推的可行性。对于外连接,还需分析谓词是否为非空过滤条件,必要时转换连接类型以保持语义。
优化前:
SELECT *FROM (SELECT id, dept_id, nameFROM employee) eJOIN (SELECT id, location, department_nameFROM department) dON e.dept_id = d.idWHERE d.location = 'New York';
优化后:
SELECT *FROM (SELECT id, dept_id, nameFROM employee) eJOIN (SELECT id, location, department_nameFROM departmentWHERE location = 'New York') dON e.dept_id = d.id;
通过将过滤条件下推到相应的表中,优化器减少了参与连接操作的数据量。
场景四:聚合查询的谓词下推
聚合查询的谓词下推需要区分针对聚合结果的过滤和针对原始数据的过滤。PawSQL会分析谓词中引用的表达式类型,将涉及聚合结果的谓词转换为HAVING子句条件,将基于原始列的谓词转换为WHERE子句条件。
优化前:
SELECT t.dept_id, t.avg_salaryFROM (SELECT dept_id, AVG(salary) as avg_salaryFROM employeeGROUP BY dept_id) tWHERE t.avg_salary > 6000;
优化后:
SELECT t.dept_id, t.avg_salaryFROM (SELECT dept_id, AVG(salary) as avg_salaryFROM employeeGROUP BY dept_idHAVING AVG(salary) > 6000) t;
通过将过滤条件转换为HAVING子句,优化器能够在聚合操作的同时应用过滤条件。
常见数据库支持情况(大模型生成/供参考)

技术实现关键点
PawSQL的谓词下推实现依赖于表达式克隆与替换、递归查询分析、非空过滤条件识别、智能限制机制和连接类型转换等技术,确保了谓词下推的正确性和有效性,使其能够适应各种复杂的查询场景。
优化限制条件
为确保查询语义的正确性,PawSQL在存在LIMIT子句、窗口函数和排名函数、全外连接操作,以及某些复杂表达式或特殊函数时,会限制谓词下推。这些限制确保了优化后的查询与原始查询具有相同的语义和结果。
结论
PawSQL优化器的谓词下推实现通过将过滤条件下推至最优位置,显著提升查询性能。PawSQL优化器共支持35种重写优化算法,其在各种查询场景中的智能重写策略,为复杂SQL查询提供了高效的性能优化方案。
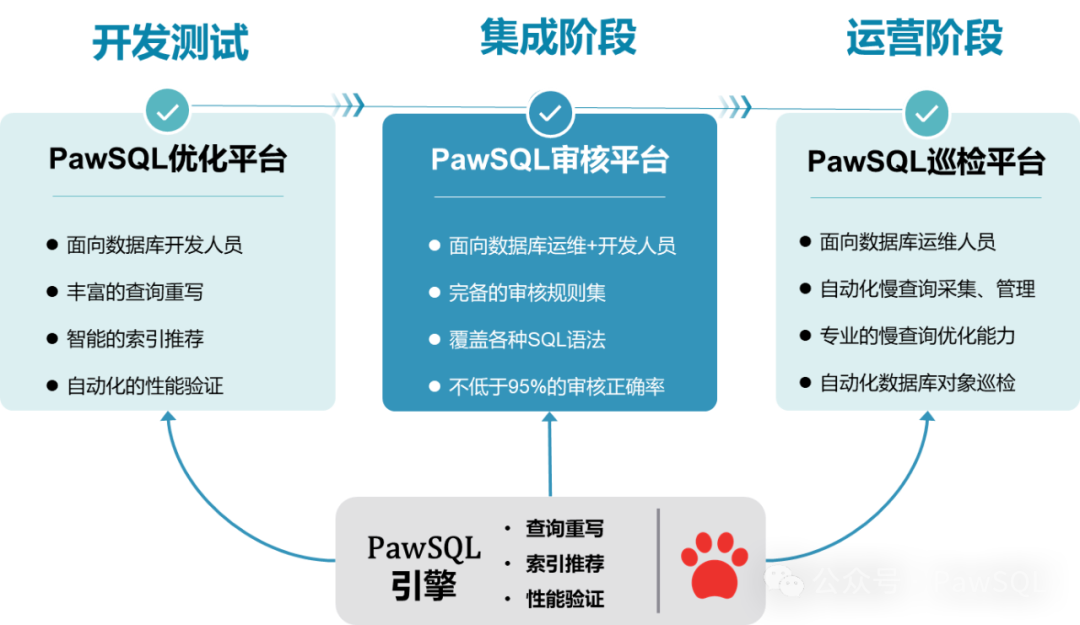
关于PawSQL
PawSQL专注于数据库性能优化自动化和智能化,提供的解决方案覆盖SQL开发、测试、运维的整个流程,广泛支持包括MySQL/PostgreSQL/Oracle/openGauss/TDSQL/Oceanbase/达梦DM/金仓等各种主流商用和开源数据库,为开发者和企业提供一站式的创新SQL优化解决方案。