




ClickHouse特性分析
| 存储结构
LSM-Tree是业内存储时序数据的常用数据结构,它的核心思路其实非常简单,每次有数据写入时并不将数据实时写入到磁盘,而是先缓存在内存的memTable中并使用归并排序的方式将内存中的数据合并,等到积累到一定阈值之后,再追加到磁盘中,并按照一定的频率与触发阈值将磁盘存储的数据文件进行合并。
这种方案利用了硬盘顺序写性能远大于随机写的特性,降低了硬盘的寻道时间,对于物联网设备所产生时序数据这种写远大于读的场景来说有非常好的优化效果。
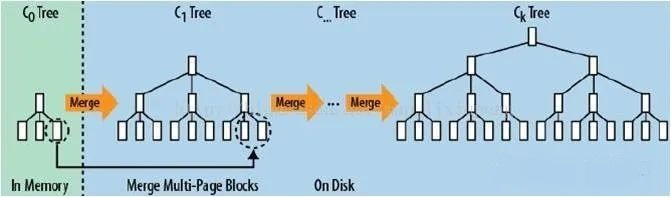
由下图可以看到,硬盘的顺序IO性能与随机IO性能有着巨大的差距。
传统的LSM-Tree
- 1.由于数据需要buffer在内存之中,为了保证瞬时停机例如断电时数据不丢失,因此所有内存里的数据都需要记录一份WAL(Write Ahead Log),用于在极端时刻进行数据恢复。
- 2.后台进行数据文件
合并时是一个先读取再写入的过程,这个行为同样会造成写放大。 - 3.当数据库发生数据查询操作时,由于LSM-Tree写数据的方式会生成较多的小文件,读请求往往需要跨越内存与硬盘的多个memTable与数据文件才能获取到正确的结果。
相比其他使用LSM-Tree的数据库,ClickHouse在设计上直接取消了memTable的内存聚合阶段,只对同一写入批次的数据做排序并直接落盘。因此,完全不需要传统的写WAL的过程,减少了数据的重复写入。
同时,ClickHouse也限制了数据的实时修改,这样就减少了合并时产生的读写放大,这个思路相当于限缩了数据库的使用场景,但却换取了更强大的读写性能。
对于物联网设备产生的数据来说,写入时本来就是一定间隔的批量写入,同时极少有数据修改的场景,与ClickHouse的优化方向正好一致。
| 列式存储带来的极高压缩比
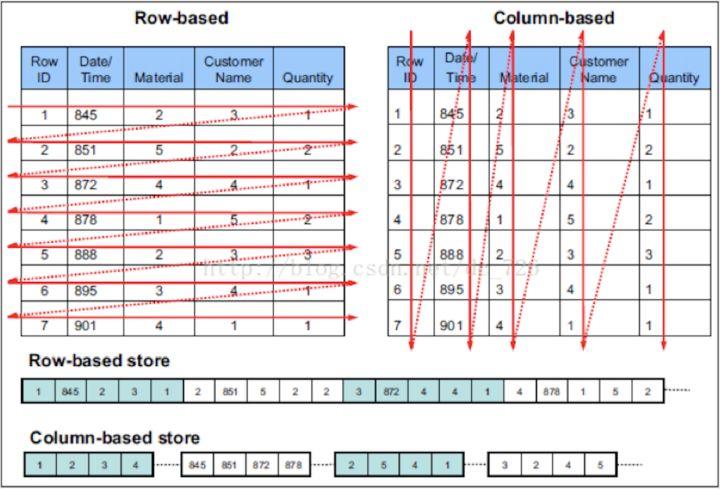
相比于传统的行存储数据库(例如MySQL),ClickHouse采用列式存储的方式存储数据,而列式存储,能够带来更极致的压缩比。
压缩的本质是按照一定步长对数据进行匹配扫描,当发现重复部分的时候就进行编码转换。数据中的重复项越多,则压缩率越高,举一个简单的例子:
压缩前:12345678_2345678
压缩后:12345678_(8,7)
上述示例中的 (8,7),表示如果从下划线开始向前移动8个字节,并向前匹配到7个字节长度的重复项,即这里的2345678,真实的压缩算法肯定比这个简单的例子复杂,但本质是一样的。显而易见,同一个列字段的数据,因为它们拥有相同的数据类型和现实语义,重复项的可能性自然就更高,在大数据量的场景下,更高的压缩比,会给我们带来更大的性能和成本优势。
- 1.分析场景中往往有需要读大量行但是少数列的情况。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式
下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。 - 2.更高的压缩比意味着更小的文件,从磁盘中读取相应数据耗时更短。
- 3.高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
- 4.同样更高的压缩比下,相同大小的硬盘可以存储更多的数据,大大地降低了存储成本。
| 极低的查询延迟
在索引正确的情况下,ClickHouse可以说是世界上最快的OLAP分析引擎之一。这里快指的就是查询延迟,简单说就是用户发起一次查询到用户获取到结果的时间,这种快很大的原因也来自于ClickHouse极端的设计思路与优秀的工程实现。
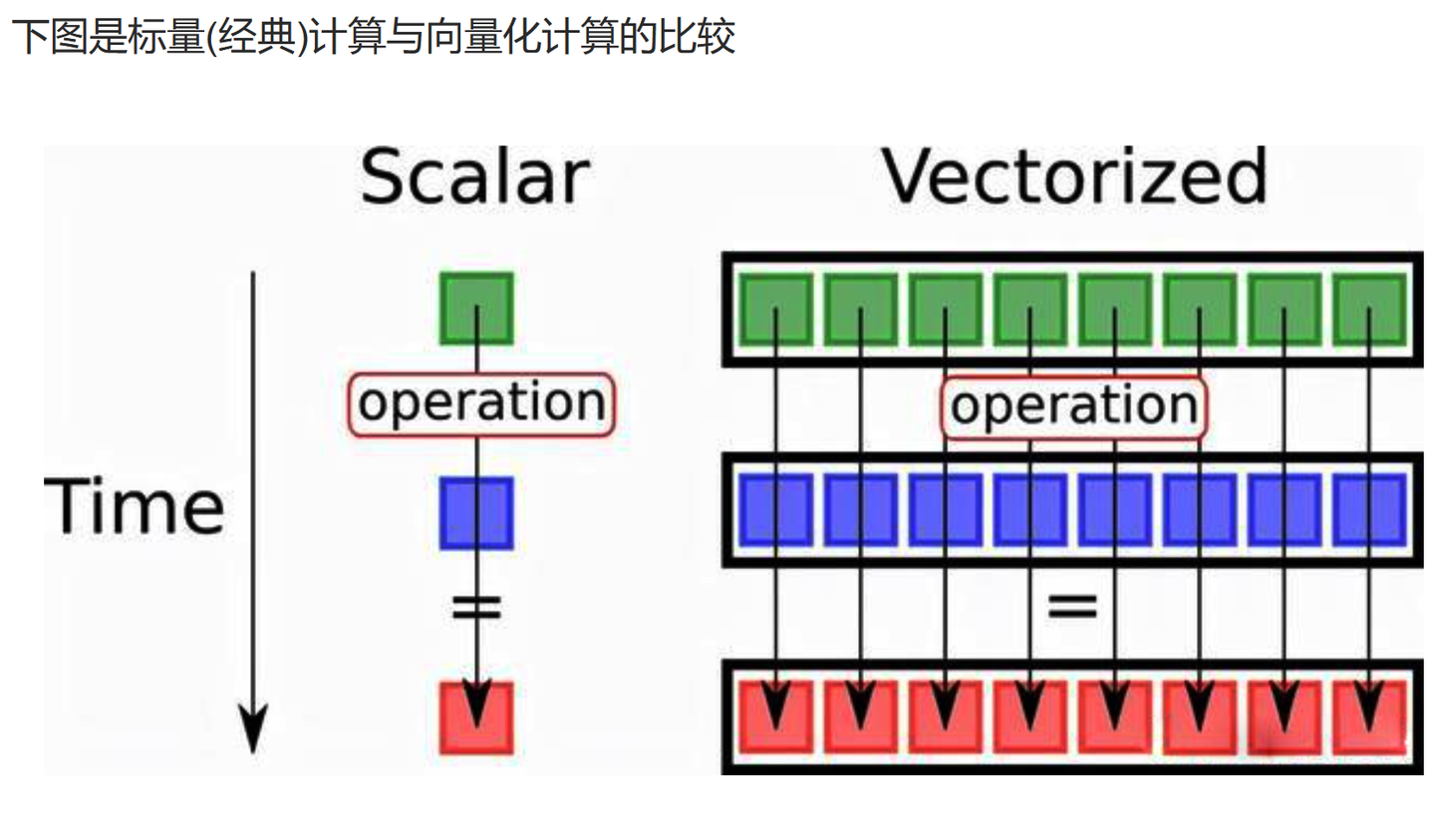
ClickHouse的大部分计算操作,都基于CPU的SIMD指令,SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据,它的原理是在CPU寄存器层面实现数据的并行操作,例如一次for循环每次处理一条数据,有8条数据则需要循环8次,但使用SIMD指令可以让这8条数据并行处理,从而在一次就得到结果,这种方式被称为向量化计算。
ClickHouse的每一次查询或统计分析操作,都会尽可能的使用所有的CPU资源来进行并行处理,这种方式能够让廉价的服务器同样拥有极低的查询延迟,从而在海量数据的场景下保证平台产品的流畅与快速,而快速和流畅就是最好的用户体验。
ClickHouse在工程实现上也同样坚持了快这个原则,可以看到在ClickHouse源码中不断地给函数或者算子的局部逻辑增加更多的变种实现,以提升在特定情形下的性能,根据不同数据类型、常量和变量、基数的高低选择不同的算法。
例如ClickHouse的hash agg,用模板实现了30多个版本,覆盖了最常见的group key的类型,再比如去重计数函数uniqCombined函数,当数据量较小的时候会选择Array保存,当数据量中等的时候会选择HashSet保存,当数据量很大的时候,则使用HyperLogLog算法等等,Clickhouse的性能,就是大量类似的工程优化堆积起来的。
| 那么代价是什么呢?
然而,世界上并没有完美无缺的方案,方案设计更像是一场trade-off
为了更极致的写入性能,ClickHouse去掉memtable缓存数据再写入的机制以及实时修改的能力,前者需要客户端进行额外的攒批操作,而后者限缩了数据库的使用场景。ClickHouse其实更像一个单机的数据库,极致的单表性能优化,非常轻量的安装部署流程,这些给我们带来了非常低的离线部署成本,但在大规模分布式场景下却有着一些缺陷。
在分布式查询的场景上,ClickHouse使用Distributed Table来实现分布式处理,查询Distributed Table相当于对不同节点上的单机Table进行一个UNION ALL,这种办法对付单表查询还可以,但涉及多表Join就有点力不从心了,在分布式多表Join的场景下,由于没有Data shuffling之类的功能,ClickHouse需要耗费更多的内存和带宽来缓存和迁移数据,造成了性能的严重下降,大部分人不得不使用大宽表的方式来规避这个问题。
另外,运维一个分布式ClickHouse集群也是非常头疼的一个点。ClickHouse并不具备数据均衡功能,提供的Distributed Table由于写入性能太差形同虚设,往往需要通过业务层来保证分发的数据足够均匀,开源的ClickHouse并没有集中的元数据管理
作为从标准的计算存储一体的Shared-nothing结构发展而来的数据库,ClickHouse对于云原生和存算分离的支持也比较一般,目前社区正在朝这个方向努力,只能说还算是未来可期。
