




如果在任务执行过程中,看到反压警告,这意味着上游产生数据的速度快于下游处理数据的速度。以source->sink job为例,sink消费数据的速度慢于source产生数据的速度,sink向source反向施压。
许多情况会导致反压。例如垃圾回收停顿可能会导致流入的数据快速堆积,或者遇到大促或秒杀活动导致流量陡增。如果没有正确处理反压,可能会导致资源耗尽,最坏的情况下,可能导致数据丢失、系统崩溃。
举个例子。假设数据流pipeline(抽象为Source,Streaming job 和 Sink)在稳定状态下以每秒500万个元素的速度处理数据(如下图每一个黑色条代表100万个元素),下图为1秒内的数据处理快照。

如上图这种情况,source产生的数据与sink消费数据的速度相同或小于sink处理数据的速度,不会产生反压。

如上图所示,如果Sink消费数据的速度保持不变,而source端产生数据的速度增大,这种情况下会出现消息拥堵,系统运行不畅。如何处理这种情况?
1)可以去掉这些元素,但对于应用程序来说,意味着将丢失一部分数据,这是不可接受的。
2)将拥堵的数据进行缓存,并告知消息发送者减缓发送速度,数据缓存必须是持久化的,可以在发生故障时进行数据恢复。

反压监测
反压监测通过反复获取正在运行的任务堆栈跟踪的样本来工作,JobManager对作业重复调用Thread.getStackTrace().
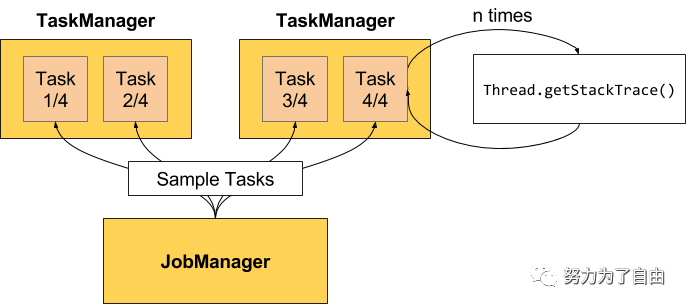
如果采样显示任务线程卡在某个内部方法调用中,则表示该任务存在反压。
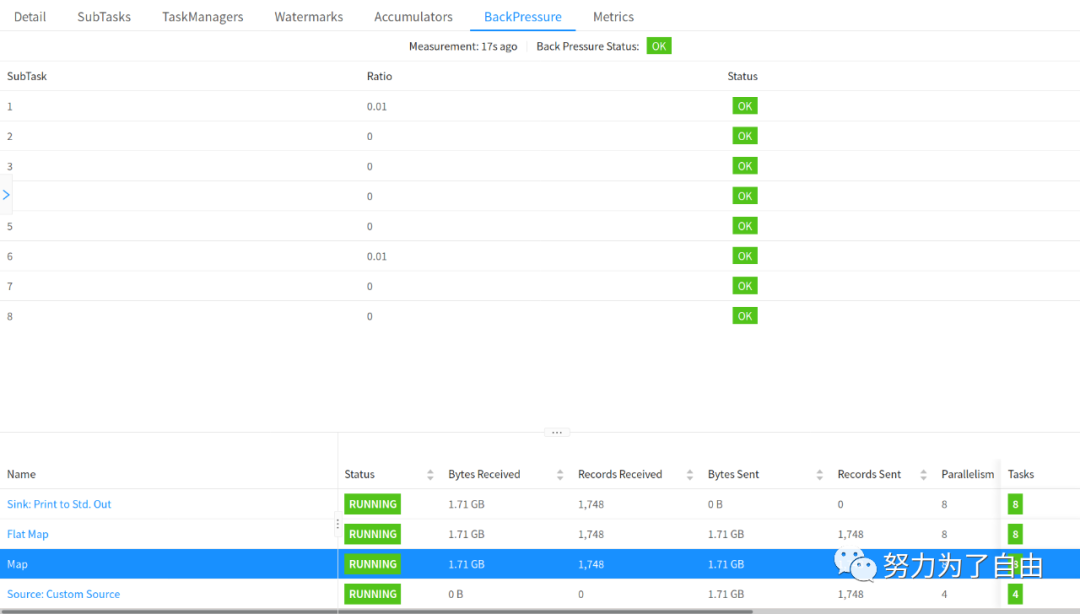
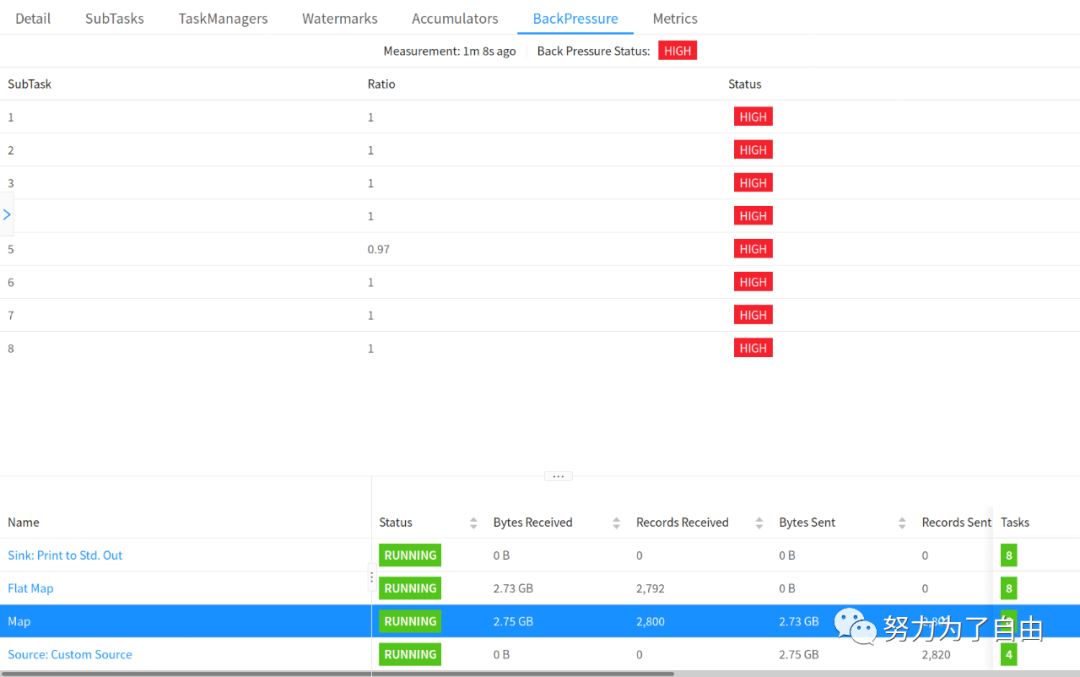
默认情况下,JobManager每50ms为每个任务触发100个堆栈跟踪,来确定反压。在web界面中看到的比率表示在内部方法调用中有多少堆栈跟踪被阻塞,例如0.01表示该方法只有一个被卡住。
为了不使堆栈跟踪样本对TaskManager负载过高,每60秒会刷新采样数据。
配置
可以使用以下配置JobManager的采样数:
web.backpressure.refresh-interval:统计数据被废弃重新刷新的时间(默认为60000,1分钟)
web.backpressure.num-samples:用于确定反压的堆栈跟踪样本数(默认100)
web.backpressure.delay-between-samples:堆栈跟踪样本之间的延迟以确定反压(默认为50,50ms)
如何处理反压
目前主流的流处理系统 Storm/JStorm/Spark Streaming/Flink 都已经提供了反压机制,不过其实现各不相同。
Storm 是通过监控 Bolt 中的接收队列负载情况,如果超过高水位值就会将反压信息写到 Zookeeper ,Zookeeper 上的 watch 会通知该拓扑的所有 Worker 都进入反压状态,最后 Spout 停止发送 tuple。
JStorm 认为直接停止 Spout 的发送太过暴力,存在大量问题。当下游出现阻塞时,上游停止发送,下游消除阻塞后,上游又开闸放水,过了一会儿,下游又阻塞,上游又限流,如此反复,整个数据流会一直处在一个颠簸状态。所以 JStorm 是通过逐级降速来进行反压的,效果会较 Storm 更为稳定,但算法也更复杂。另外 JStorm 没有引入 Zookeeper 而是通过 TopologyMaster 来协调拓扑进入反压状态,这降低了 Zookeeper 的负载。
那么 Flink 是怎么处理反压的呢?答案非常简单:Flink 没有使用任何复杂的机制来解决反压问题,因为根本不需要那样的方案!它利用自身作为纯数据流引擎的优势来优雅地响应反压问题。下面我们会深入分析 Flink 是如何在 Task 之间传输数据的,以及数据流如何实现自然降速的。
Flink 在运行时主要由 operators 和 streams 两大组件构成。每个 operator 会消费中间态的流,并在流上进行转换,然后生成新的流。对于 Flink 的网络机制一种形象的类比是,Flink 使用了高效有界的分布式阻塞队列,就像 Java 通用的阻塞队列(BlockingQueue)一样。还记得经典的线程间通信案例:生产者消费者模型吗?使用 BlockingQueue 的话,一个较慢的接受者会降低发送者的发送速率,因为一旦队列满了(有界队列)发送者会被阻塞。Flink 解决反压的方案就是这种感觉。
在 Flink 中,这些分布式阻塞队列就是这些逻辑流,而队列容量是通过缓冲池(LocalBufferPool)来实现的。每个被生产和被消费的流都会被分配一个缓冲池。缓冲池管理着一组缓冲(Buffer),缓冲在被消费后可以被回收循环利用。这很好理解:你从池子中拿走一个缓冲,填上数据,在数据消费完之后,又把缓冲还给池子,之后你可以再次使用它。
大的原理,上游的task产生数据后,会写在本地的缓存中,然后通知JM自己的数据已经好了,JM通知下游的Task去拉取数据,下游的Task然后去上游的Task拉取数据,形成链条。
但是在何时通知JM?这里有一个设置,比如pipeline还是blocking,pipeline意味着上游哪怕产生一个数据,也会去通知,blocking则需要缓存的插槽存满了才会去通知,默认是pipeline。
虽然生产数据的是Task,但是一个TaskManager中的所有Task共享一个NetworkEnvironment,下游的Task利用ResultPartitionManager主动去上游Task拉数据,底层利用的是Netty和TCP实现网络链路的传输。
那么,一直都在说Flink的背压是一种自然的方式,为什么是自然的?
当下游的process逻辑比较慢,无法及时处理数据时,他自己的local buffer中的消息就不能及时被消费,进而导致netty无法把数据放入local buffer,进而netty也不会去socket上读取新到达的数据,进而在tcp机制中,tcp也不会从上游的socket去读取新的数据,上游的netty也是一样的逻辑,它无法发送数据,也就不能从上游的localbuffer中消费数据,所以上游的localbuffer可能就是满的,上游的operator或者process在处理数据之后进行collect.out的时候申请不能本地缓存,导致上游的process被阻塞。这样,在这个链路上,就实现了背压。
如果还有相应的上游,则会一直反压上去,一直影响到source,导致source也放慢从外部消息源读取消息的速度。一旦瓶颈解除,网络链路畅通,则背压也会自然而然的解除。
参考:
http://wuchong.me/blog/2016/04/26/flink-internals-how-to-handle-backpressure/
https://www.jianshu.com/p/bae101ec7bcf
https://www.cnblogs.com/029zz010buct/p/10156836.html
