




PolarDB PostgreSQL 版 CheckPoint机制
CheckPoint简介
PostgreSQL中用户执行事务操作时,发生的数据更改会先写到shared buffer pool中,并生成对应的WAL日志记录此次修改的数据。事务提交时仅需保证将对应的WAL日志落盘,而无需将shared buffer pool中的dirty buffers落盘,数据库崩溃或重启时通过回放之前已落盘的WAL日志实现数据恢复。为避免崩溃恢复时需要回放的WAL日志过多导致恢复时间长,PostgreSQL中的CheckPoint机制会将某个LSN之前的脏数据全部落盘,该LSN也称为Redo点。Redo点之前的数据已经持久化,因此崩溃恢复时仅需从Redo点之后开始回放WAL日志进行数据恢复,从而缩短了崩溃恢复时间。
CheckPoint类型
内核通过ckpt_flags描述checkpoint的类型,如下(以下代码均基于PostgreSQL 14版本):
/*
* OR-able request flag bits for checkpoints. The "cause" bits are used only
* for logging purposes. Note: the flags must be defined so that it's
* sensible to OR together request flags arising from different requestors.
*/
/* These directly affect the behavior of CreateCheckPoint and subsidiaries */
#define CHECKPOINT_IS_SHUTDOWN 0x0001 /* Checkpoint is for shutdown */
#define CHECKPOINT_END_OF_RECOVERY 0x0002 /* Like shutdown checkpoint, but
* issued at end of WAL recovery */
#define CHECKPOINT_IMMEDIATE 0x0004 /* Do it without delays */
#define CHECKPOINT_FORCE 0x0008 /* Force even if no activity */
#define CHECKPOINT_FLUSH_ALL 0x0010 /* Flush all pages, including those
* belonging to unlogged tables */
/* These are important to RequestCheckpoint */
#define CHECKPOINT_WAIT 0x0020 /* Wait for completion */
#define CHECKPOINT_REQUESTED 0x0040 /* Checkpoint request has been made */
/* These indicate the cause of a checkpoint request */
#define CHECKPOINT_CAUSE_XLOG 0x0080 /* XLOG consumption */
#define CHECKPOINT_CAUSE_TIME 0x0100 /* Elapsed time */复制
CHECKPOINT_IS_SHUTDOWN:数据库实例进行smart shutdown和fast shutdown时都会创建一个shutdown checkpoint,shutdown checkpoint会将当前实例的所有脏数据落盘;immediate shutdown模式下实例会立即退出,不会尝试做shutdown checkpoint,因此该种模式下退出速度也会更快。
CHECKPOINT_END_OF_RECOVERY:数据库实例崩溃恢复回放完所有的WAL日志之后,会创建一个end_of_recovery的checkpoint。CHECKPOINT_END_OF_RECOVERY与CHECKPOINT_IS_SHUTDOWN均为shutdown checkpoint,其生成的checkpoint WAL类型为XLOG_CHECKPOINT_SHUTDOWN,其他场景下的checkpoint均为online checkpoint,对应的WAL类型为XLOG_CHECKPOINT_ONLINE。
CHECKPOINT_IMMEDIATE:请求立即创建一个checkpoint,如create db和drop db等场景下会使用。
CHECKPOINT_FORCE:请求强制创建一个checkpoint,当内核判断上次checkpoint结束到该次checkpoint之间系统未产生重要WAL时,则会跳过该次checkpoint。添加CHECKPOINT_FORCE表明即使内核判断当前系统空闲,仍会继续创建一个checkpoint,CHECKPOINT_IS_SHUTDOWN和CHECKPOINT_END_OF_RECOVERY默认为force类型的checkpoint。
CHECKPOINT_FLUSH_ALL:表明checkpoint过程中需将所有脏页落盘,否则仅会落盘BM_PERMANENT类型的 dirty buffers。CHECKPOINT_IS_SHUTDOWN和CHECKPOINT_END_OF_RECOVERY下默认会将所有脏页落盘,与CHECKPOINT_FLUSH_ALL效果一致。
CHECKPOINT_WAIT:表明请求checkpoint的进程需要等待该次checkpoint完成。
CHECKPOINT_REQUESTED:内核调用RequestCheckpoint()时会加上该flag,超级用户执行CHECKPOINT命令最终也是通过RequestCheckpoint()实现。
CHECKPOINT_CAUSE_XLOG:表明上次checkpoint开始后产生的WAL日志超过了CheckPointSegments,系统判断产生的WAL日志量超过阈值,需要创建一个新的checkpoint。
CHECKPOINT_CAUSE_TIME:上次checkpoint结束后经过的时间超过了CheckPointTimeout,需要创建一个新的checkpoint。
上述checkpoint flag可同时出现在一个checkpoint中,内核请求checkpoint时会对checkpoint flag执行OR操作,从而可将来自不同进程的checkpoint请求进行汇聚,最终执行一个checkpoint。
CheckPoint实现
checkpointer和backend的交互
PostgreSQL通过辅助进程checkpointer来周期性地创建checkpoint,checkpointer进程与backend进程通过CheckpointerShmemStruct中的相关变量进行交互,对应结构如下:
typedef struct
{
pid_t checkpointer_pid; /* PID (0 if not started) */
slock_t ckpt_lck; /* protects all the ckpt_* fields */
int ckpt_started; /* advances when checkpoint starts */
int ckpt_done; /* advances when checkpoint done */
int ckpt_failed; /* advances when checkpoint fails */
int ckpt_flags; /* checkpoint flags, as defined in xlog.h */
ConditionVariable start_cv; /* signaled when ckpt_started advances */
ConditionVariable done_cv; /* signaled when ckpt_done advances */
uint32 num_backend_writes; /* counts user backend buffer writes */
uint32 num_backend_fsync; /* counts user backend fsync calls */
int num_requests; /* current # of requests */
int max_requests; /* allocated array size */
CheckpointerRequest requests[FLEXIBLE_ARRAY_MEMBER];
} CheckpointerShmemStruct;复制
checkpointer进程和backend进程的交互包含两个方面:1)backend进程request创建checkpoint和checkpointer进程创建checkpoint;2)backend进程request sync操作和checkpointer进程处理sync操作。
request checkpoint的交互
如下,checkpointer进程首先依据ckpt_flags 判断当前是否有checkpoint请求:在有checkpoint请求,或上次checkpoint完成后经过的时间超过设定的阈值CheckPointTimeout的场景下,均需创建一个新的checkpoint,具体地:
获取CheckpointerShmem->ckpt_flags,作为该轮checkpoint的flags;
递增CheckpointerShmem->ckpt_started,表明该轮checkpoint开始;
进行checkpoint的主要操作,若当前处于正常运行非recovery状态,则通过CreateCheckPoint函数完成具体的操作;若当前在recovery过程中,则通过CreateRestartPoint函数完成具体的操作;
该轮checkpoint完成后,设置CheckpointerShmem->ckpt_done为CheckpointerShmem->ckpt_started,backend进程可据此了解等待的checkpoint操作是否已完成;若执行checkpoint过程中出错,则会递增CheckpointerShmem->ckpt_failed;
更新checkpoint完成时间,再次判断CheckpointerShmem->ckpt_flags是否为空,不为空则说明有新的checkpoint请求,则再次进入循环创建一个新的checkpoint,否则sleep设定的时间后再创建一个新的checkpoint。
for (;;)
{
bool do_checkpoint = false;
int flags = 0;
pg_time_t now;
int elapsed_secs;
int cur_timeout;
// 省略......
// 处理backend的的sync请求
AbsorbSyncRequests();
// 省略......
// 如果ckpt_flags不为空,说明有进程请求创建checkpoint
if (((volatile CheckpointerShmemStruct *) CheckpointerShmem)->ckpt_flags)
{
do_checkpoint = true;
BgWriterStats.m_requested_checkpoints++;
}
// 如果上次checkpoint完成后经过的时间超过CheckPointTimeout,则flags再加上CHECKPOINT_CAUSE_TIME
now = (pg_time_t) time(NULL);
elapsed_secs = now - last_checkpoint_time;
if (elapsed_secs >= CheckPointTimeout)
{
if (!do_checkpoint)
BgWriterStats.m_timed_checkpoints++;
do_checkpoint = true;
flags |= CHECKPOINT_CAUSE_TIME;
}
//创建checkpoint
if (do_checkpoint)
{
bool ckpt_performed = false;
bool do_restartpoint;
// 如果当前处于recovery状态,则创建restartpoint
do_restartpoint = RecoveryInProgress();
// 从共享内存中获取ckpt_flags,作为该轮checkpoint的flag,同时递增ckpt_started,表明checkpoint开始
SpinLockAcquire(&CheckpointerShmem->ckpt_lck);
flags |= CheckpointerShmem->ckpt_flags;
CheckpointerShmem->ckpt_flags = 0;
CheckpointerShmem->ckpt_started++;
SpinLockRelease(&CheckpointerShmem->ckpt_lck);
ConditionVariableBroadcast(&CheckpointerShmem->start_cv);
// 省略......
ckpt_active = true;
if (do_restartpoint)
ckpt_start_recptr = GetXLogReplayRecPtr(NULL);
else
ckpt_start_recptr = GetInsertRecPtr();
ckpt_start_time = now;
ckpt_cached_elapsed = 0;
//checkpoint的主要操作,若在正常运行过程中,通过CreateCheckPoint完成具体操作;若在recovery过程中,则通过CreateRestartPoint完成具体操作
if (!do_restartpoint)
{
CreateCheckPoint(flags);
ckpt_performed = true;
}
else
ckpt_performed = CreateRestartPoint(flags);
// 省略......
// checkpoint完成后,设置ckpt_done
SpinLockAcquire(&CheckpointerShmem->ckpt_lck);
CheckpointerShmem->ckpt_done = CheckpointerShmem->ckpt_started;
SpinLockRelease(&CheckpointerShmem->ckpt_lck);
ConditionVariableBroadcast(&CheckpointerShmem->done_cv);
if (ckpt_performed)
{
// 更新checkpoint完成时间
last_checkpoint_time = now;
}
else
{
last_checkpoint_time = now - CheckPointTimeout + 15;
}
// 省略......
}
// 省略......
// 若ckpt_flags不为0,说明有checkpoint request, 则再次创建checkpoint
if (((volatile CheckpointerShmemStruct *) CheckpointerShmem)->ckpt_flags)
continue;
// 省略......
// sleep直到有checkpoint请求,或超过CheckPointTimeout阈值
(void) WaitLatch(MyLatch,
WL_LATCH_SET | WL_TIMEOUT | WL_EXIT_ON_PM_DEATH,
cur_timeout * 1000L/* convert to ms */ ,
WAIT_EVENT_CHECKPOINTER_MAIN);
}复制
backend进程通过RequestCheckpoint()函数请求checkpointer进程创建新的checkpoint,具体地:
backend进程先获取当前的CheckpointerShmem->ckpt_failed值和CheckpointerShmem->ckpt_started值,并更新CheckpointerShmem->ckpt_flags,通过kill(CheckpointerShmem->checkpointer_pid, SIGINT)通知checkpointer进程有新的checkpoint请求;
如果flags中包含CHECKPOINT_WAIT,说明backend需要等待请求的checkpoint完成。前面说到,checkpointer进程开始创建checkpoint之前,会递增CheckpointerShmem->ckpt_started,checkpoint结束后会将CheckpointerShmem->ckpt_done置为CheckpointerShmem->ckpt_started。因此backend进程可根据CheckpointerShmem->ckpt_started的值是否发生变化得知其请求的checkpoint是否开始,根据CheckpointerShmem->ckpt_done与CheckpointerShmem->ckpt_started的差值得知其请求的checkpoint是否已完成。
void
RequestCheckpoint(int flags)
{
int ntries;
int old_failed,
old_started;
// 省略......
// 获取当前的ckpt_failed和ckpt_started值,并设置ckpt_flags
SpinLockAcquire(&CheckpointerShmem->ckpt_lck);
old_failed = CheckpointerShmem->ckpt_failed;
old_started = CheckpointerShmem->ckpt_started;
CheckpointerShmem->ckpt_flags |= (flags | CHECKPOINT_REQUESTED);
SpinLockRelease(&CheckpointerShmem->ckpt_lck);
// 省略...
// 如果flags中标明了需要等待请求的checkpoint完成,则持续等待并判断checkpoint是否完成
if (flags & CHECKPOINT_WAIT)
{
int new_started,
new_failed;
// 再次获取ckpt_started值,如果与此前获取的不相同,说明新一轮的checkpoint在进行中
ConditionVariablePrepareToSleep(&CheckpointerShmem->start_cv);
for (;;)
{
SpinLockAcquire(&CheckpointerShmem->ckpt_lck);
new_started = CheckpointerShmem->ckpt_started;
SpinLockRelease(&CheckpointerShmem->ckpt_lck);
if (new_started != old_started)
break;
ConditionVariableSleep(&CheckpointerShmem->start_cv,
WAIT_EVENT_CHECKPOINT_START);
}
ConditionVariableCancelSleep();
// 判断checkpoint是否完成,以及是否成功执行
ConditionVariablePrepareToSleep(&CheckpointerShmem->done_cv);
for (;;)
{
int new_done;
SpinLockAcquire(&CheckpointerShmem->ckpt_lck);
new_done = CheckpointerShmem->ckpt_done;
new_failed = CheckpointerShmem->ckpt_failed;
SpinLockRelease(&CheckpointerShmem->ckpt_lck);
if (new_done - new_started >= 0)
break;
ConditionVariableSleep(&CheckpointerShmem->done_cv,
WAIT_EVENT_CHECKPOINT_DONE);
}
ConditionVariableCancelSleep();
if (new_failed != old_failed)
ereport(ERROR,
(errmsg("checkpoint request failed"),
errhint("Consult recent messages in the server log for details.")));
}
}复制
request sync的交互
PostgreSQL中backend进程和bgwriter进程都会通过FlushBuffer() -> smgrwrite() -> mdwrite() -> FileWrite() -> pg_pwrite()将脏页落盘,但backend进程自身并不执行fsync操作,fsync操作通过mdwrite() -> register_dirty_segment() -> RegisterSyncRequest()转发给checkpointer进程,最终由checkpointer进程执行实际的fsync操作,从而避免了多个backend进程对同一个文件的重复fsync操作,以及多个backend同时fsync相同文件带来的锁争抢。RegisterSyncRequest()函数中backend进程通过调用ForwardSyncRequest()实现sync request的转发,具体地:
如果checkpointer进程未启动,则直接返回false,表明转发sync请求失败,backend进程需要自己进行sync操作或持续等待直到满足条件。sync request内容包含两个部分:
request type:表示请求类型,具体可查看SyncRequestType定义,包括fsync请求,unlink请求等。需要注意的是:对于fsync请求,若转发失败backend进程可直接返回并自行进行fsync操作;但对于unlink等请求,则需 backend持续等待直到forward成功,若backend自行执行unlink操作可能导致后续checkpointer进程执行对应文件的fsync等操作时出错;
request file tag:标识具体的文件和处理函数类型,具体可查看FileTag定义。
若checkpointer进程运行正常,则查看对应的requests数组是否已满,若已满则通过函数CompactCheckpointerRequestQueue()尝试删除重复的request,找到空闲entry后则将当前request保存至CheckpointerShmem->requests数组中。
对于checkpointer进程自身,则不会调用该函数,而是直接通过RememberSyncRequest()记录sync request,后续会对该函数进行分析。
bool
ForwardSyncRequest(const FileTag *ftag, SyncRequestType type)
{
CheckpointerRequest *request;
bool too_full;
// 省略......
// checkpointer进程不会调用该函数,而是直接通过RememberSyncRequest()记录sync request
if (AmCheckpointerProcess())
elog(ERROR, "ForwardSyncRequest must not be called in checkpointer");
LWLockAcquire(CheckpointerCommLock, LW_EXCLUSIVE);
// 记录backend自身刷脏次数
if (!AmBackgroundWriterProcess())
CheckpointerShmem->num_backend_writes++;
// 当共享内存中的request队列满时,可能需要backend进程自身执行sync操作
if (CheckpointerShmem->checkpointer_pid == 0 ||
(CheckpointerShmem->num_requests >= CheckpointerShmem->max_requests &&
!CompactCheckpointerRequestQueue()))
{
/*
* Count the subset of writes where backends have to do their own
* fsync
*/
if (!AmBackgroundWriterProcess())
CheckpointerShmem->num_backend_fsync++;
LWLockRelease(CheckpointerCommLock);
returnfalse;
}
// 保存sync请求至共享队列中
request = &CheckpointerShmem->requests[CheckpointerShmem->num_requests++];
request->ftag = *ftag;
request->type = type;
// 省略......
returntrue;
}复制
backend进程通过ForwardSyncRequest()将请求保存至共享队列中,checkpointer进程则通过AbsorbSyncRequests()处理共享队列中的请求。AbsorbSyncRequests()先拷贝共享内存CheckpointerShmem->requests中的所有请求,将CheckpointerShmem->num_requests置空后,再循环调用RememberSyncRequest()处理每一个请求。RememberSyncRequest()将sync请求保存至pendingOps哈希表中,将unlink请求保存至pendingUnlinks列表中,后续分别通过ProcessSyncRequests()和SyncPostCheckpoint()执行真正的sync操作和unlink操作。
void
AbsorbSyncRequests(void)
{
CheckpointerRequest *requests = NULL;
CheckpointerRequest *request;
int n;
if (!AmCheckpointerProcess())
return;
LWLockAcquire(CheckpointerCommLock, LW_EXCLUSIVE);
// 省略......
// 拷贝所有request,清空共享内存request数组
n = CheckpointerShmem->num_requests;
if (n > 0)
{
requests = (CheckpointerRequest *) palloc(n * sizeof(CheckpointerRequest));
memcpy(requests, CheckpointerShmem->requests, n * sizeof(CheckpointerRequest));
}
START_CRIT_SECTION();
CheckpointerShmem->num_requests = 0;
LWLockRelease(CheckpointerCommLock);
// 调用RememberSyncRequest保存至pendingOps中
for (request = requests; n > 0; request++, n--)
RememberSyncRequest(&request->ftag, request->type);
END_CRIT_SECTION();
// 省略......
}复制
创建检查点的具体实现
正常运行状态下,检查点的创建主要通过CreateCheckPoint()完成,recovery状态下则通过CreateRestartPoint()完成,两者实现略有区别。本文以CreateCheckPoint()为例详细说明创建检查点的具体过程,CreateCheckPoint()包含以下几个关键步骤:
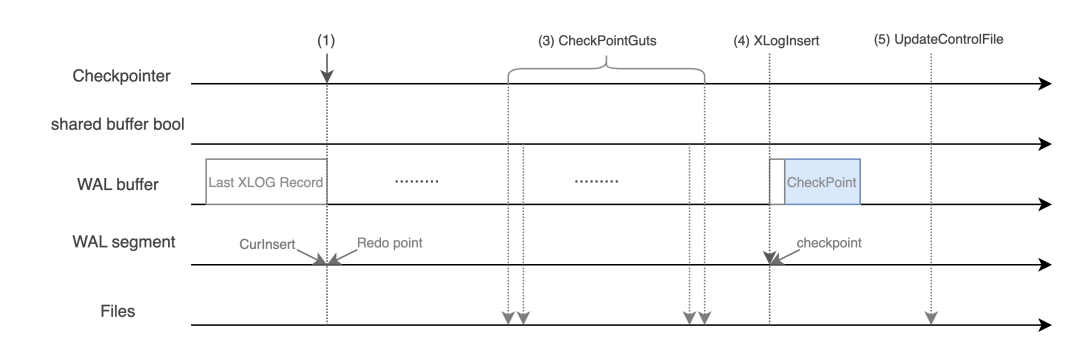
获取当前的xlog insert位点作为该轮checkpoint的Redo位点;
判断从上次checkpoint结束后,到该轮checkpoint开始时,系统是否有生成相关WAL日志,若没有则直接返回,避免在系统空闲时期生成重复的checkpoint;
通过CheckPointGuts()将Redo位点之前的所有脏数据落盘,此后可认为Redo位点之前的数据均已持久化;
生成checkpoint对应的WAL日志,并将WAL日志落盘;
将该轮checkpoint对应的WAL日志位点及相关数据更新至控制文件pg_control中,后续实例崩溃恢复则可基于pg_control中记录的checkpoint WAL日志位点,读取checkpoint WAL获取Redo位点,从Redo位点开始回放WAL日志进行数据恢复;
通过SyncPostCheckpoint()进行相关文件的删除操作;
删除Redo位点之前不再需要的WAL日志文件。
checkpoint过程中脏页的落盘主要由CheckPointGuts()完成,如下CheckPointGuts()会调用对应函数将replication slot、clog、 committs等脏数据落盘,通过CheckPointBuffers()遍历shared buffer pool将dirty buffers落盘,最后通过ProcessSyncRequests()处理上述过程中产生的sync请求,从而实现Redo位点之前所有数据的持久化。
static void
CheckPointGuts(XLogRecPtr checkPointRedo, int flags)
{
CheckPointRelationMap();
CheckPointReplicationSlots();
CheckPointSnapBuild();
CheckPointLogicalRewriteHeap();
CheckPointReplicationOrigin();
/* Write out all dirty data in SLRUs and the main buffer pool */
TRACE_POSTGRESQL_BUFFER_CHECKPOINT_START(flags);
CheckpointStats.ckpt_write_t = GetCurrentTimestamp();
CheckPointCLOG();
CheckPointCommitTs();
CheckPointSUBTRANS();
CheckPointMultiXact();
CheckPointPredicate();
// dirty buffers落盘
CheckPointBuffers(flags);
/* Perform all queued up fsyncs */
TRACE_POSTGRESQL_BUFFER_CHECKPOINT_SYNC_START();
CheckpointStats.ckpt_sync_t = GetCurrentTimestamp();
// 执行fsync操作
ProcessSyncRequests();
CheckpointStats.ckpt_sync_end_t = GetCurrentTimestamp();
TRACE_POSTGRESQL_BUFFER_CHECKPOINT_DONE();
/* We deliberately delay 2PC checkpointing as long as possible */
CheckPointTwoPhase(checkPointRedo);
}复制
值得注意的是,在CheckPointGuts()之前及之后,分别判断了是否需要进行对应的delay操作,此处分别举例说明为什么需要进行delay:
假设在CheckPointGuts()之前,有backend进程在并发执行commit操作,其生成的commit WAL lsn < Redo point,但其尚未完成对clog事务文件的更新操作。若此时checkpointer进程通过CheckPointGuts()将clog文件落盘后发生崩溃,系统将会从Redo point开始进行数据恢复,因此不会回放该backend产生的commit WAL,磁盘上该事务对应的clog状态也未被更新,导致后续获取到非预期的事务状态,从用户视角而言即为发生了数据丢失。因此在执行CheckPointGuts()将脏数据落盘之前需要等待此类事件结束,保证Redo位点之前所有数据的持久化;
在CheckPointGuts()之后,若不进行delay操作,如下场景可能导致后续的崩溃恢复失败:
假设存储上page1为空,在创建checkpoint之前,有backend进程执行insert into page1 lp1;
获取checkpoint Redo位点之后,backend进程继续执行delete all rows on page1,此后autovacuum进程对该page进行truncate操作,buffer pool中对应的 dirty buffer会被invalid,CheckPointGuts()不会对该buffer执行落盘操作,因此存储上page1依旧为空;
若在truncate文件操作真正执行之前,节点发生崩溃,系统会从Redo point开始进行数据恢复,在full_page_writes关闭的场景下,当回放delete操作对应的wal日志时,由于存储上的page1为空,此时回放会因数据不一致而报错,系统恢复失败。如果checkpoint操作等待truncate文件操作完成,则后续回放delete对应的wal日志时,会跳过该日志的回放而不是报错,系统仍能正常恢复成功。因此CheckPointGuts()之后需要等待此类事件结束,以保证后续系统崩溃后仍能正常恢复。
// 等待clog等文件的更新完成,再将脏数据持久化
vxids = GetVirtualXIDsDelayingChkpt(&nvxids);
if (nvxids > 0)
{
do
{
pg_usleep(10000L); /* wait for 10 msec */
} while (HaveVirtualXIDsDelayingChkpt(vxids, nvxids));
}
pfree(vxids);
// 将checkPoint.redo之前的脏数据持久化
CheckPointGuts(checkPoint.redo, flags);
// 等待truncate等操作完成之后,再生成checkpoint对应的wal日志
vxids = GetVirtualXIDsDelayingChkptEnd(&nvxids);
if (nvxids > 0)
{
do
{
pg_usleep(10000L); /* wait for 10 msec */
} while (HaveVirtualXIDsDelayingChkptEnd(vxids, nvxids));
}
pfree(vxids);复制
CheckPointGuts()完成脏数据的持久化操作后,会生成对应的checkpoint wal日志,wal日志中记录了该轮checkpoint的相关信息,包括该轮checkpoint的Redo点及timeline等信息。
typedef struct CheckPoint
{
XLogRecPtr redo; /* next RecPtr available when we began to
* create CheckPoint (i.e. REDO start point) */
TimeLineID ThisTimeLineID; /* current TLI */
TimeLineID PrevTimeLineID; /* previous TLI, if this record begins a new
* timeline (equals ThisTimeLineID otherwise) */
bool fullPageWrites; /* current full_page_writes */
FullTransactionId nextXid; /* next free transaction ID */
// 省略......
} CheckPoint;复制
此后会将该轮checkpoint的信息更新到ControlFile中,并通过UpdateControlFile()将其持久化到pg_control文件中。pg_control中记录了checkpoint wal日志对应的LSN,之后崩溃恢复则可基于此LSN读取checkpoint wal日志,从checkpoint wal中获取Redo位点,从Redo位点之后回放wal日志进行数据恢复。
typedef struct ControlFileData
{
uint64 system_identifier;
uint32 pg_control_version; /* PG_CONTROL_VERSION */
uint32 catalog_version_no; /* see catversion.h */
DBState state; /* see enum above */
pg_time_t time; /* time stamp of last pg_control update */
XLogRecPtr checkPoint; /* last check point record ptr */
CheckPoint checkPointCopy; /* copy of last check point record */
// 省略......
pg_crc32c crc;
} ControlFileData;复制
CreateRestartPoint()与CreateCheckPoint()整体流程类似,区别为Redo点的获取方式不同。recovery阶段回放XLOG_CHECKPOINT_ONLINE及XLOG_CHECKPOINT_SHUTDOWN类型的wal日志时,会将对应的CheckPoint lsn及CheckPoint内容记录下来,创建restartpoint时直接获取回放时记录的CheckPoint,以CheckPoint.redo作为该轮restartpoint的Redo点,同样调用CheckPointGuts()将该Redo点以前的脏数据持久化,并更新pg_control文件。类似地,若recovery阶段发生崩溃,则后续同样基于pg_control获取回放的起始点,而无需从最初的起点开始进行recovery,从而缩短了恢复时间。
总结
本文主要介绍了PostgreSQL的CheckPoint机制,包括CheckPoint的触发时机、CheckPoint的类型,checkpointer进程与backend进程之间的交互流程,以及创建checkpoint的具体流程。CheckPoint机制的主要目的是周期性地将当前buffer pool中的脏数据持久化,从而降低系统崩溃恢复的时间;同时checkpoint刷脏还能减少backend进程自身的刷脏次数,提升backend的查询效率;此外还可将不再需要的WAL日志进行回收清理,降低系统存储空间的占用。周期性地创建checkpoint对系统的持久稳定运行及快速恢复十分重要,但同时也需注意太过频繁的checkpoint也会带来十分频繁的fsync操作,可能会造成系统IO阻塞降低其稳定性,因此checkpoint也不能过于频繁。
