




在当今这个互联网高速发展的时代,用户对于在线服务的可用性和响应速度有着极高的期待。作为运维人员,我们肩负着保障网站和应用7x24小时不间断运行的责任。而在众多实现高可用性架构的技术中,HAProxy以其出色的性能、灵活性以及稳定性脱颖而出,成为许多企业的首选负载均衡解决方案。但是,仅仅部署了HAProxy并不意味着万事大吉,有效的监控是确保其健康运行不可或缺的一环。今天,就让我们深入探讨如何对HAProxy进行高效的监控,以保证我们的服务像瑞士钟表一样精确无误地运转。
frontend prometheus
bind *:8405
mode http
http-request use-service prometheus-exporter if { path metrics }
no log
Tip:重启haproxy服务
1、Prometheus采集Nacos数据
$ kubectl-nkube-systemeditcmprometheus
-job_name:'haproxy'
static_configs:
-targets:
-"172.139.20.3:8405"
- "172.139.20.92:8405"
2、验证是否采集成功
$ curl -u admin -s $(kubectl -n kube-system get svc prometheus -ojsonpath='{.spec.clusterIP}:{.spec.ports[0].port}')/prometheus/api/v1/query --data-urlencode 'query=up{job=~"haproxy"}' | jq '.data.result[]'
Enter host password for user 'admin':
{
"metric": {
"__name__": "up",
"instance": "172.139.20.92:8405",
"job": "haproxy"
},
"value": [
1744104389.303,
"1"
]
}
{
"metric": {
"__name__": "up",
"instance": "172.139.20.3:8405",
"job": "haproxy"
},
"value": [
1744104389.303,
"1"
]
}
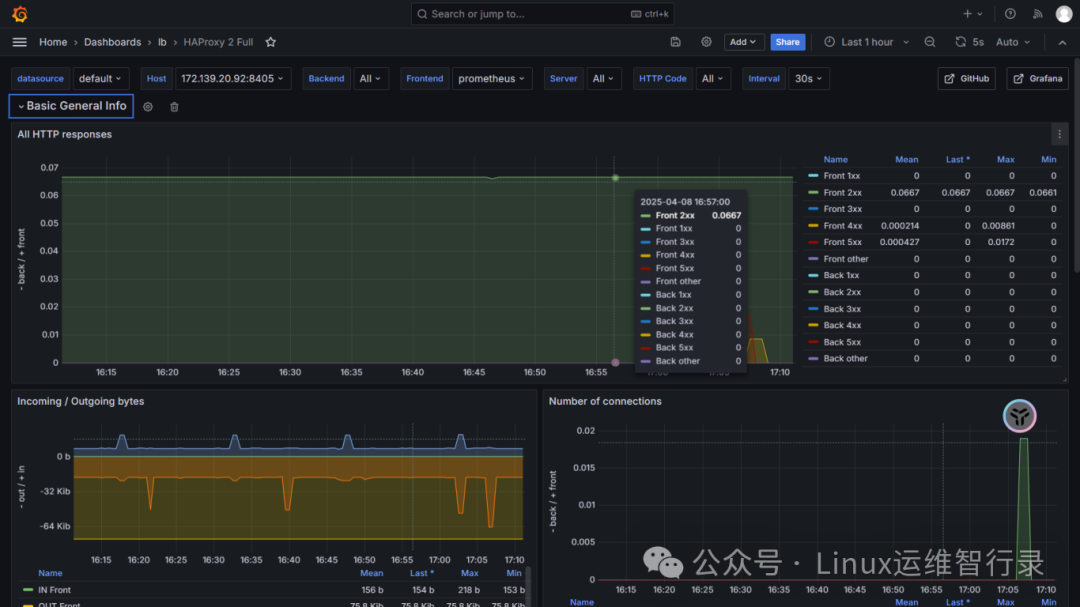
grafana上导入以下 dashboard ID号:12693
通过构建全面而细致的HAProxy监控体系,我们不仅能够及时发现并解决潜在问题,还能为优化系统性能提供数据支持。记住,监控不是一次性任务,而是持续的过程,需要不断地调整和完善。在这个过程中,每一个细节都不应被忽视,因为它们可能就是决定服务质量的关键所在。让我们携手共进,通过精心设计的监控策略,守护好每一台服务器、每一条链路,确保我们的服务永远在线,为用户提供最优质的体验。毕竟,在数字世界里,稳定与效率是我们给予用户的最好承诺。
【推荐阅读】点击下方蓝色标题跳转至详细内容!
别忘了,关注我们的公众号,获取更多关于容器技术和云原生领域的深度洞察和技术实战,让我们携手在技术的海洋中乘风破浪!

文章转载自Linux运维智行录,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
