




作为拥有一定实战经验的Oracle DBA,我们都深知Redo Log在数据库恢复与事务一致性中的核心作用。在日常运维中,Redo Log的损坏虽不常见,但一旦发生却可能引发灾难性后果,尤其是当损坏涉及Active或Current状态的日志文件时。
对于非Current且处于Inactive状态的Redo Log损坏,处理通常较为直接;若数据库处于Open状态,可通过CLEAR LOGFILE命令清理后再通过DROP并重新创建日志组来解决问题。这一过程对业务影响较小,且不会导致数据丢失。然而,当损坏的Redo Log处于Active或Current状态时,问题复杂度将急剧上升——尤其当数据库运行在非归档模式且缺乏有效备份的情况下,DBA可能面临数据丢失的严峻挑战。此时,常规恢复手段失效,如何在不依赖归档日志与备份的前提下最小化损失并快速恢复数据库运行,成为DBA的一项关键技能。
下面我们将以实战视角,模拟在非归档模式且无备份的环境中,因Active状态Redo Log损坏导致的数据库故障场景,逐步解析应急处理思路与操作步骤。通过这一案例,我们不仅探讨如何在高风险场景下挽救数据库,也将深入理解Redo Log工作机制中的潜在风险点,为DBA的日常防护与故障预案提供参考。
1、环境介绍
|
操作系统 |
redhat7.9 |
|
数据库版本 |
19.14.0.0.0 |
|
数据库架构 |
单机+文件系统 |
2、模拟redo log丢失
通过dd命令破坏active状态的重做日志文件,来模拟故障;如下是我的模拟过程:
|
---查看数据库及pdb的状态 -bash-4.2$
sqlplus / as sysdba SQL*Plus:
Release 19.0.0.0.0 - Production on Mon Apr 28 11:44:06 2025 Version
19.14.0.0.0 Copyright (c)
1982, 2021, Oracle. All rights
reserved. SQL> show
pdbs; CON_ID CON_NAME OPEN
MODE RESTRICTED ----------
------------------------------ ---------- ---------- 2 PDB$SEED READ ONLY
NO 3 PDB1 READ WRITE NO ---查看重做日志组的状态信息 SQL> set line
200 SQL> col
member for a30 SQL> select *
from v$logfile; GROUP# STATUS TYPE
MEMBER IS_ CON_ID ----------
------- ------- ------------------------------ --- ---------- 1 ONLINE
/oradata/DB19C/redo01.log NO 0 2 ONLINE
/oradata/DB19C/redo02.log NO 0 3 ONLINE
/oradata/DB19C/redo03.log NO 0 SQL> select *
from v$Log; GROUP#
THREAD# SEQUENCE# BYTES
BLOCKSIZE MEMBERS ARC STATUS FIRST_CHANGE#
FIRST_TIM NEXT_CHANGE# NEXT_TIME CON_ID ----------
---------- ---------- ---------- ---------- ---------- --- ----------------
------------- --------- ------------ --------- ---------- 1 1 13
209715200 512 1
NO INACTIVE 1249941
02-AUG-23 1477461 25-APR-25 0 2 1 14
209715200 512 1
NO INACTIVE 1477461
25-APR-25 1577816 28-APR-25 0 3 1 15
209715200 512 1
NO CURRENT 1577816
28-APR-25 9.2954E+18 0 ---做一次日志切换,产生active状态的日志组 SQL> alter
system switch logfile; System altered. SQL> select *
from v$log; GROUP#
THREAD# SEQUENCE# BYTES
BLOCKSIZE MEMBERS ARC STATUS FIRST_CHANGE#
FIRST_TIM NEXT_CHANGE# NEXT_TIME CON_ID ----------
---------- ---------- ---------- ---------- ---------- --- ----------------
------------- --------- ------------ --------- ---------- 1 1 16
209715200 512 1
NO CURRENT 1579306
28-APR-25 9.2954E+18 0 2 1 14
209715200 512 1
NO INACTIVE 1477461
25-APR-25 1577816 28-APR-25 0 3 1 15
209715200 512 1
NO ACTIVE
1577816 28-APR-25 1579306 28-APR-25 0 ---使用dd命令模拟active状态的日志文件损坏 dd if=/dev/zero
of=/oradata/DB19C/redo03.log bs=512 count=10 ---此时重启数据库时报错 SQL> shutdown
abort ORACLE instance
shut down. SQL> startup ORACLE instance
started. Total System
Global Area 1191178320 bytes Fixed Size
9134160 bytes Variable Size
738197504 bytes Database Buffers
436207616 bytes Redo Buffers
7639040 bytes Database
mounted. ORA-00313: open
failed for members of log group 3 of thread 1 ORA-00312:
online log 3 thread 1: '/oradata/DB19C/redo03.log' ORA-27048:
skgfifi: file header information is invalid Additional
information: 2 |
3、尝试打开数据库
我们通过清理损坏的重做日志组并删除重建的方式进行尝试打开数据库,此时发现通过这样的手段无法打开数据库,下面是尝试的步骤记录:
|
---清理损坏的日志组文件,发现清理报错,无法执行此操作 SQL> alter database clear logfile group 3; alter database clear logfile group 3 * ERROR at line 1: ORA-01624: log 3
needed for crash recovery of instance db19c (thread 1) ORA-00312:
online log 3 thread 1: '/oradata/DB19C/redo03.log' ---删除损坏的重做日志组,同样无法删除 SQL> alter database drop logfile group 3; alter database drop logfile group 3 * ERROR at line 1: ORA-01624: log 3
needed for crash recovery of instance db19c (thread 1) ORA-00312:
online log 3 thread 1: '/oradata/DB19C/redo03.log' ---尝试对数据库进行recover操作,发现无法找到相应的归档日志信息,无法进行 SQL> recover
database until cancel; ORA-00279:
change 1577817 generated at 04/28/2025 11:44:21 needed for thread 1 ORA-00289:
suggestion :
/home/db/oracle/app/product/19.0.0/dbhome_1/dbs/arch1_15_1143817258.dbf ORA-00280:
change 1577817 for thread 1 is in sequence #15 Specify log:
{<RET>=suggested | filename | AUTO | CANCEL} auto ORA-00308:
cannot open archived log '/home/db/oracle/app/product/19.0.0/dbhome_1/dbs/arch1_15_1143817258.dbf' ORA-27037:
unable to obtain file status Linux-x86_64
Error: 2: No such file or directory Additional
information: 7 ORA-00308:
cannot open archived log '/home/db/oracle/app/product/19.0.0/dbhome_1/dbs/arch1_15_1143817258.dbf' ORA-27037:
unable to obtain file status Linux-x86_64
Error: 2: No such file or directory Additional
information: 7 ORA-01547:
warning: RECOVER succeeded but OPEN RESETLOGS would get error below ORA-01194: file
1 needs more recovery to be consistent ORA-01110: data
file 1: '/oradata/DB19C/system01.dbf' ---尝试打开数据库,打开失败 SQL> alter database open; alter database open * ERROR at line 1: ORA-01589: must
use RESETLOGS or NORESETLOGS option for database open SQL> alter database open resetlogs; alter database open resetlogs * ERROR at line 1: ORA-01194: file
1 needs more recovery to be consistent ORA-01110: data
file 1: '/oradata/DB19C/system01.dbf' |
4、无法打开原因分析
通过上面的一些列尝试后,数据库依然无法正常打开,这里我们思考一下,为什么会这样呢?
这就需要我们通过Oracle数据库重做日志的作用以及原理来分析了。
4.1重做日志的作用
Oracle使用重做日志记录所有数据库变更操作(如DML、DDL),确保数据的持久性和一致性。在以下场景中需要重做日志:
l 实例恢复:数据库异常崩溃后重新启动时,Oracle会通过重做日志前滚(Roll
Forward)未提交的事务到崩溃前的状态,再回滚(Roll Back)未提交的事务。
l 介质恢复:从备份恢复数据文件后,需通过归档日志和在线重做日志恢复到最新状态。
l 数据一致性:保证提交的事务被持久化,未提交的事务可回滚。
4.2重做日志状态的含义
l unused: 从未对该联机日志写入任何内容,一般为新增加联机日志文件或是使用resetlog 后的状态
l current:当前重做日志文件,表示该重做日志文件为活动状态,能够被打开和关闭
l active:处于活动状态,不属于当前日志,崩溃恢复需要该状态,可用于块恢复,可能归档,也可能未归档。
l clearing:表示在执行 alter database clear logfile 命令后正将该日志重建为一个空日志,重建后状态变为
unused
l clearing_current:当前日志处于关闭线程的清除状态。如日志某些故障或写入新日志标头时发生
i/o 错误
l inactive:实例恢复不在需要联机重做文件日志组
4.3丢失ACTIVE或CURRENT日志的影响
1)CURRENT日志丢失
l 原因:CURRENT日志是数据库正在使用的日志,包含最新的未提交或已提交但未写入数据文件的事务。
l 后果:数据库无法完成实例恢复(缺少最新的事务记录);数据文件与日志文件的一致性被破坏,Oracle无法保证数据完整性;数据库启动到OPEN阶段时,会因无法找到CURRENT日志而报错。
2)ACTIVE日志丢失
l 原因:ACTIVE日志包含尚未通过Checkpoint写入数据文件的事务记录。
l 后果:实例恢复时无法前滚到崩溃前的完整状态,导致部分已提交事务丢失;数据库启动时检测到日志不连续,拒绝打开。
4.4解决思路
1)常规恢复方法
l 从备份恢复:使用最近的备份和归档日志进行不完全恢复(可能丢失部分数据)。
l 清除日志(不推荐):使用ALTER DATABASE CLEAR UNARCHIVED LOGFILE强制清除日志(需在MOUNT状态下操作,可能导致数据丢失)。
2)紧急场景(无备份)
隐含参数强制打开(风险极高):
*._allow_resetlogs_corruption=true
*._allow_error_simulation=true
5、修改隐含参数
由于我们模拟的是在没有备份场景下的active状态的重做日志文件损坏的情况,所以这里我们就尝试使用调整隐含参数后强制启动数据库的方式来open数据库,如下是操作信息:
|
---创建pfile SQL> create
pfile='/home/db/oracle/db19c.ora' from spfile; File created. ---修改pfile,添加隐含参数 *._allow_resetlogs_corruption=true *._allow_error_simulation=true ---使用pfile启动数据库的mount状态 SQL> shutdown
immediate ORA-01109:
database not open Database
dismounted. ORACLE instance
shut down. SQL> startup
mount pfile='/home/db/oracle/db19c.ora'; ORACLE instance
started. Total System
Global Area 1191178320 bytes Fixed Size
9134160 bytes Variable Size
738197504 bytes Database Buffers
436207616 bytes Redo Buffers
7639040 bytes Database
mounted. ---尝试打开数据库 SQL> alter database open; alter database open * ERROR at line 1: ORA-01589: must
use RESETLOGS or NORESETLOGS option for database open SQL> alter database open resetlogs; alter database open resetlogs * ERROR at line 1: ORA-00603:
ORACLE server session terminated by fatal error ORA-01092:
ORACLE instance terminated. Disconnection forced ORA-00600:
internal error code, arguments: [kcvfdb_pdb_set_clean_scn: cleanckpt], [3],
[1377456], [1577821], [2], [], [], [], [], [], [], [] Process ID: 3968 Session ID: 379
Serial number: 63921 ---数据库告警日志信息: alter database
open 2025-04-28T11:49:02.759060+08:00 Smart fusion
block transfer is disabled: instance mounted in exclusive mode. 2025-04-28T11:49:02.763739+08:00 Errors in file
/home/db/oracle/app/diag/rdbms/db19c/db19c/trace/db19c_ora_3968.trc: ORA-01589: must
use RESETLOGS or NORESETLOGS option for database open ORA-1589
signalled during: alter database
open... 2025-04-28T11:49:04.512182+08:00 alter database open resetlogs 2025-04-28T11:49:04.515163+08:00 RESETLOGS is
being done without consistancy checks. This may result in a corrupted
database. The database should be recreated. RESETLOGS after
incomplete recovery UNTIL CHANGE 1577817 time Resetting
resetlogs activation ID 2271864298 (0x8769e5ea) 2025-04-28T11:49:06.279969+08:00 Setting recovery
target incarnation to 2 2025-04-28T11:49:06.285400+08:00 Smart fusion
block transfer is disabled: instance mounted in exclusive mode. 2025-04-28T11:49:06.287570+08:00 Crash Recovery
excluding pdb 2 which was cleanly closed. Endian type of
dictionary set to little 2025-04-28T11:49:06.293304+08:00 Assigning
activation ID 2327663332 (0x8abd52e4) Redo log for
group 1, sequence 1 is not located on DAX storage Thread 1 opened
at log sequence 1 Current log# 1 seq# 1 mem# 0:
/oradata/DB19C/redo01.log Successful open
of redo thread 1 2025-04-28T11:49:06.306585+08:00 MTTR advisory is
disabled because FAST_START_MTTR_TARGET is not set Stopping change
tracking 2025-04-28T11:49:06.313801+08:00 TT00 (PID:3981):
Gap Manager starting 2025-04-28T11:49:06.560787+08:00 Undo
initialization recovery: Parallel FPTR failed: start:441642 end:441645 diff:3
ms (0.0 seconds) Undo
initialization recovery: err:0 start: 441642 end: 441662 diff: 20 ms (0.0
seconds) [3968]
Successfully onlined Undo Tablespace 2. Undo
initialization online undo segments: err:0 start: 441662 end: 441724 diff: 62
ms (0.1 seconds) Undo
initialization finished serial:0 start:441642 end:441731 diff:89 ms (0.1
seconds) Dictionary check
beginning Dictionary check
complete Database
Characterset is AL32UTF8 No Resource
Manager plan active 2025-04-28T11:49:07.399009+08:00 joxcsys_required_dirobj_exists:
directory object exists with required path /home/db/oracle/app/product/19.0.0/dbhome_1/javavm/admin/,
pid 3968 cid 1 replication_dependency_tracking
turned off (no async multimaster replication found) LOGSTDBY:
Validating controlfile with logical metadata LOGSTDBY:
Validation complete Starting
background process AQPC 2025-04-28T11:49:07.881493+08:00 AQPC started
with pid=41, OS id=3990 2025-04-28T11:49:07.979169+08:00 PDB$SEED(2):Pluggable
database PDB$SEED opening in read only PDB$SEED(2):Autotune
of undo retention is turned on. PDB$SEED(2):Endian
type of dictionary set to little PDB$SEED(2):Undo
initialization finished serial:0 start:443411 end:443411 diff:0 ms (0.0
seconds) PDB$SEED(2):Pluggable
database PDB$SEED dictionary check beginning PDB$SEED(2):Pluggable
Database PDB$SEED Dictionary check complete 2025-04-28T11:49:08.403974+08:00 PDB$SEED(2):Database
Characterset for PDB$SEED is AL32UTF8 PDB$SEED(2):SUPLOG:
Set PDB SUPLOG SGA at PDB OPEN, old 0x0, new 0x0 (no suplog) PDB$SEED(2):Opening
pdb with no Resource Manager plan active PDB1(3):Pluggable
database PDB1 pseudo opening 2025-04-28T11:49:09.080386+08:00 PDB1(3):SUPLOG:
Initialize PDB SUPLOG SGA, old value 0x0, new value 0x18 PDB1(3):Autotune
of undo retention is turned on. Errors in file
/home/db/oracle/app/diag/rdbms/db19c/db19c/trace/db19c_ora_3968.trc (incident=13081) (PDBNAME=CDB$ROOT): ORA-00600:
internal error code, arguments: [kcvfdb_pdb_set_clean_scn: cleanckpt], [3],
[1377456], [1577821], [2], [], [], [], [], [], [], [] Incident details
in:
/home/db/oracle/app/diag/rdbms/db19c/db19c/incident/incdir_13081/db19c_ora_3968_i13081.trc 2025-04-28T11:49:09.534196+08:00 QPI: opatch file
present, opatch QPI:
qopiprep.bat file present 2025-04-28T11:49:10.665227+08:00 ***************************************************************** An internal
routine has requested a dump of selected redo. This usually
happens following a specific internal error, when analysis of the
redo logs will help Oracle Support with the diagnosis. It is
recommended that you retain all the redo logs generated (by all the
instances) during the past 12 hours, in case additional redo dumps are
required to help with the diagnosis. ***************************************************************** Use ADRCI or
Support Workbench to package the incident. See Note 411.1
at My Oracle Support for error and packaging details. PDB1(3):Error
600 during pluggable database PDB1 pseudo opening 2025-04-28T11:49:10.795041+08:00 PDB1(3):Errors
in file /home/db/oracle/app/diag/rdbms/db19c/db19c/trace/db19c_ora_3968.trc: ORA-00600:
internal error code, arguments: [kcvfdb_pdb_set_clean_scn: cleanckpt], [3],
[1377456], [1577821], [2], [], [], [], [], [], [], [] 2025-04-28T11:49:10.795250+08:00 Errors in file
/home/db/oracle/app/diag/rdbms/db19c/db19c/trace/db19c_ora_3968.trc: ORA-00600:
internal error code, arguments: [kcvfdb_pdb_set_clean_scn: cleanckpt], [3],
[1377456], [1577821], [2], [], [], [], [], [], [], [] PDB1(3):Pluggable
database PDB1 pseudo close cleaning up PDB1(3):JIT: pid
3968 requesting stop 2025-04-28T11:49:10.797281+08:00 Dumping
diagnostic data in directory=[cdmp_20250428114910], requested by (instance=1,
osid=3968), summary=[incident=13081]. 2025-04-28T11:49:10.893448+08:00 PDB1(3):Buffer
Cache flush deferred for PDB 3 2025-04-28T11:49:10.904410+08:00 Errors in file
/home/db/oracle/app/diag/rdbms/db19c/db19c/trace/db19c_ora_3968.trc: ORA-00600:
internal error code, arguments: [kcvfdb_pdb_set_clean_scn: cleanckpt], [3],
[1377456], [1577821], [2], [], [], [], [], [], [], [] 2025-04-28T11:49:10.904495+08:00 Errors in file
/home/db/oracle/app/diag/rdbms/db19c/db19c/trace/db19c_ora_3968.trc: ORA-00600:
internal error code, arguments: [kcvfdb_pdb_set_clean_scn: cleanckpt], [3],
[1377456], [1577821], [2], [], [], [], [], [], [], [] Error 600
happened during db open, shutting down database Errors in file
/home/db/oracle/app/diag/rdbms/db19c/db19c/trace/db19c_ora_3968.trc (incident=13082) (PDBNAME=CDB$ROOT): ORA-00603:
ORACLE server session terminated by fatal error ORA-01092:
ORACLE instance terminated. Disconnection forced ORA-00600:
internal error code, arguments: [kcvfdb_pdb_set_clean_scn: cleanckpt], [3],
[1377456], [1577821], [2], [], [], [], [], [], [], [] Incident details
in:
/home/db/oracle/app/diag/rdbms/db19c/db19c/incident/incdir_13082/db19c_ora_3968_i13082.trc 2025-04-28T11:49:12.409824+08:00 opiodr aborting
process unknown ospid (3968) as a result of ORA-603 2025-04-28T11:49:12.409992+08:00 Errors in file
/home/db/oracle/app/diag/rdbms/db19c/db19c/trace/db19c_ora_3968.trc: ORA-00603:
ORACLE server session terminated by fatal error ORA-01092:
ORACLE instance terminated. Disconnection forced ORA-00600:
internal error code, arguments: [kcvfdb_pdb_set_clean_scn: cleanckpt], [3],
[1377456], [1577821], [2], [], [], [], [], [], [], [] 2025-04-28T11:49:12.413397+08:00 ORA-603 : opitsk
aborting process License high
water mark = 1 USER(prelim)
(ospid: 3968): terminating the instance due to ORA error 600 2025-04-28T11:49:13.445801+08:00 Instance
terminated by USER(prelim), pid = 3968 |
6、启动报错分析
从上面的操作来看,我们通过调整隐含参数后,强制启动数据库报了一个ora-600的内部错误,一般情况下,通过这种方式就可以正常启动数据库了,但是我们这里却出乎意料的报了一个内部错误,触发Oracle的BUG了?????
于是,通过报错信息,在MOS上进行了搜索,果然,我们这次的模拟操作好巧不巧的就触发了BUG,这个BUG我们可以参考官方文档,文档号为Doc ID
31686545.8;小伙伴如果没有MOS账号,我把文档信息在这里也展示出来:
官方关于这个BUG的描述信息如下:
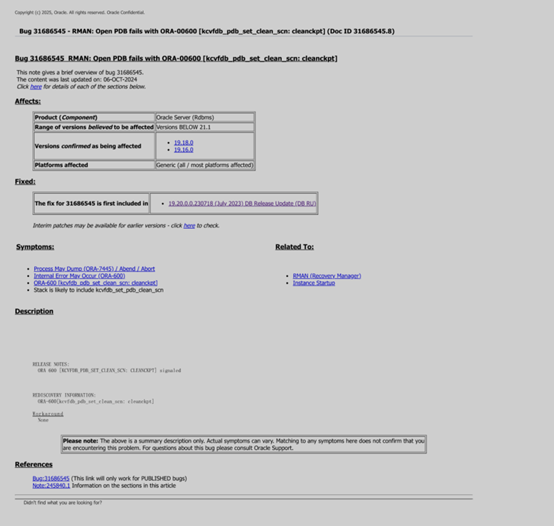
可以看到,如果将数据库的补丁打到19.20及以上,理论上就可以规避这个BUG了。
7、补丁升级
通过前面的分析,此BUG需要将数据库补丁打到19.20及以上就可以规避,所以,这里我直接将我的环境打到了19.27这个版本上,由于是单机环境,具体的打补丁过程这里就不再赘述了。
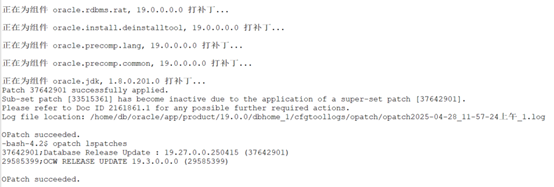
8、强制启动数据库
通过前面的一系列分析和操作之后,这里我们就可以打开数据库了,以下是打开数据库的步骤:
|
-bash-4.2$
sqlplus / as sysdba SQL*Plus:
Release 19.0.0.0.0 - Production on Mon Apr 28 14:36:28 2025 Version
19.27.0.0.0 Copyright (c)
1982, 2024, Oracle. All rights
reserved. Connected to an
idle instance. SQL> startup mount
pfile='/home/db/oracle/db19c.ora'; ORACLE instance
started. Total System
Global Area 1191180432 bytes Fixed Size
9177232 bytes Variable Size
738197504 bytes Database Buffers
436207616 bytes Redo Buffers
7598080 bytes Database
mounted. SQL> alter
database open resetlogs; Database altered. SQL> alter
pluggable database all open; Pluggable
database altered. SQL> show
pdbs; CON_ID CON_NAME OPEN
MODE RESTRICTED ----------
------------------------------ ---------- ---------- 2 PDB$SEED READ ONLY
NO 3 PDB1 READ WRITE NO SQL> alter
system switch logfile; System altered. SQL> alter
system switch logfile; System altered. SQL> / System altered. SQL> alter
system checkpoint; System altered. SQL> / System altered. |
9、验证数据字典
最后,我们通过官方的hcheck脚本来验证以下数据字典的一致性,如果检查正常,那么基本上就可以保证后期数据库运行的稳健性,下面的检查过程:
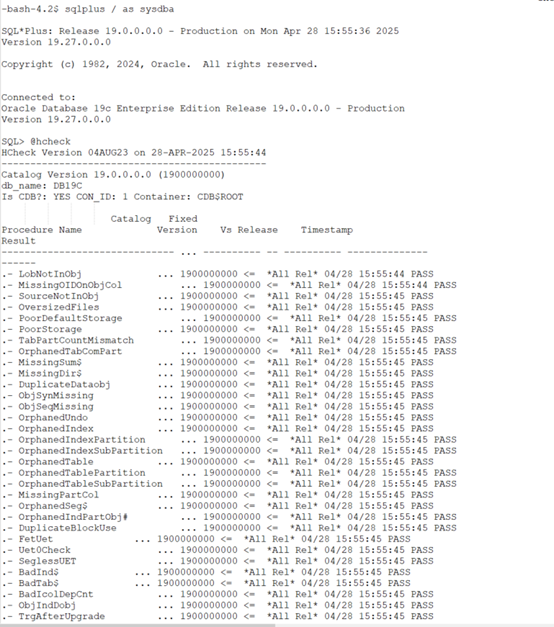
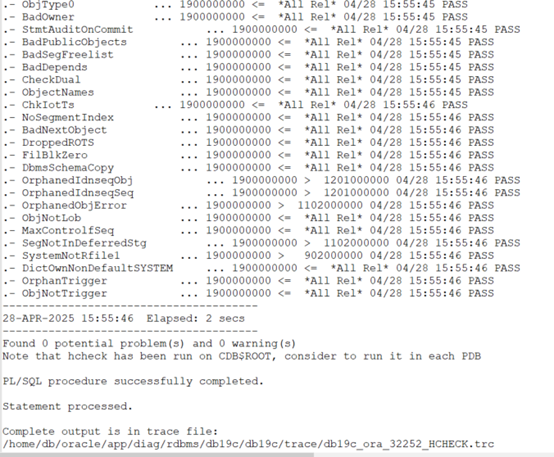
补充一下,对于数据字典的一致性检查,数据库版本是10.2.0.5以上才可以通过hcheck.sql来校验,对于之前版本,Oracle有专门对应的脚本;从19.22开始,我们可以使用Oracle内置的包DBMS_DICTIONARY_CHECK来进行校验了,有兴趣的小伙伴可以通过这个包来验证一下。
另外,hcheck.sql这个脚本可以通过MOS去下载:https://support.oracle.com/epmos/faces/SearchDocDisplay?_adf.ctrl-state=e70g6klls_4&_afrLoop=246906897476946
关于包的操作可以参考官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/19/arpls/dbms-dictionary-check.html
