




Dropout: A Simple Way to Prevent Neural Networks from Overfitting
研究背景
深度神经网络包含多个非线性隐含层,这使得网络具有非常强大的学习能力,能拟合输入和输出之间复杂的关系。但是我们数据是真实分布的抽样,并且带有一定的采样噪声,网络过度的学习这种映射关系,会导致过度拟合现象,即在训练数据上表现完美,但在测试数据差强人意。为解决过拟合问题,在机器学习中常用的方法主要有正则化、数据增强和权重惩罚机制等。
受到有性繁殖中基因的随机突变的现象启发,该篇论文提出一种解决深度网络过拟合的方案,称其为Dropout。其基本思想是在训练阶段,通过随机丢弃网络隐含层部分节点,在前向传播和反向传播过程中都不考虑其对网络的学习的贡献;在测试阶段,将神经网络的权重按随机丢弃概率p来缩放。论文在图像、语音、文本和生物数据集进行实验,对之前的神经网络增加Dropout机制。实验结果发现Dropout机制有效的避免了过拟合,提高了在测试集上的正确率。
问题描述
随着神经网络的层数不断增加,网络所拥有的学习能力就越强,但是网络的参数会急剧增加,导致网络出现过拟合现象,降低网络模型的泛化性。在解决过拟合问题方面,模型组合是一种有效方法,但是这种方法对于深度网络来说是比较困难的,这是因为深度网络的训练成本较大,多个不同结构的深度网络训练需要大量的计算时间,其次深度网络训练需要大量数据,可能会出现没有足够数据子建来训练不同的网络。

解决方案
Dropout模型数学描述
考虑具有L个隐含层的神经网络,设为网络隐含层的索引,设表示输入到第层的向量,表示第层的输出向量,和是第层的权值和偏置。标准神经网络的前馈操作可以描述为
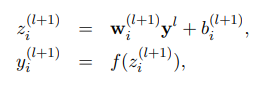
在考虑Dropout后,可表达为:
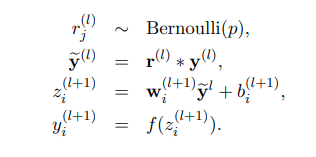
Dropout模型流程描述(前向)
下图即为标准的神经网络(a)和Dropout神经网络(b)的前向传播过程。
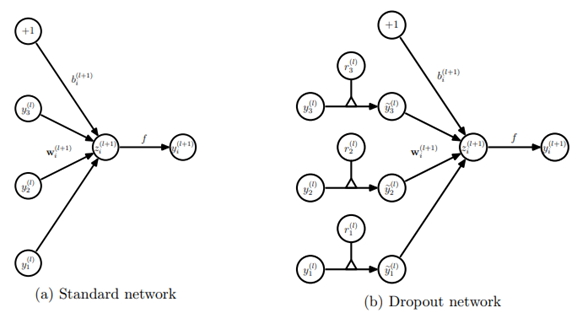
在Dropout数学表达中,对于任何层是独立的伯努利随机变量的向量,其中每个随机变量具有概率p为0,有概率1-p为1,该向量与该层的输出相乘得到,然后接着输入到神经元,得到激活值,再将输出作为下一层输入。
这个过程在每一层都执行,相当于从一个更大的网络中抽取一个子网络。
简单理解为就是相当于就是激活函数指,以概率p变为0。比如某一层神经元的个数为1000,激活函数输出值为,若p=0.4,那么就有大约400个神经元输出为0。
Dropout模型流程描述(反向)
在前向传播后,得到误差值,通过子网络进行反向传播,计算损失梯度,对于被丢弃的神经元对权重更新无贡献,即梯度为0。
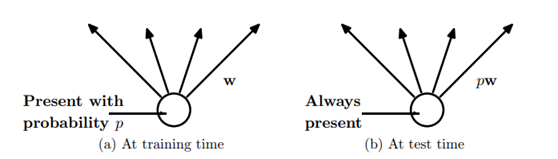
在Dropout模型测试时,每个神经元权重需要按照进行缩放,即模型预测的时候,每一个神经单元的权重参数要乘以概率p。
实验分析
该篇论文在图像、语音、文本和生物基因的标准数据集上训练带有dropout机制的网络,同没有dropout机制的网络相对比,来分析dropout给网络性能带来的优化。下表展示各个数据集详情。
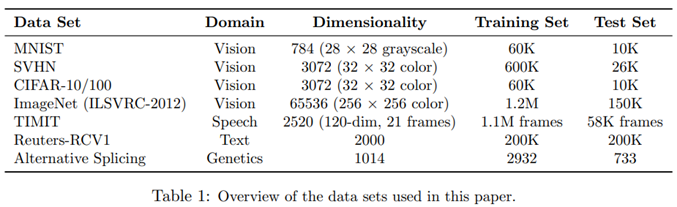
MNIST:手写体数据集
CIFAR-10和CIFAR-100:小尺度小类别的自然图像
SVHN:谷歌街景收集的房屋号码图像
ImageNet:大尺度多类别的自然图像
TIMNIT:语音识别数据集
Reuters-RVC1:路透社的新闻文章的数据子集
Alternative Splicing:用于预测替代基因剪接的RNA特征
图像数据集
MNIST
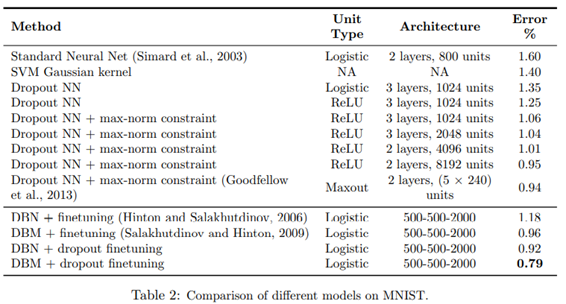
MNIST数据集是由28×28像素的手写数字灰度图像组成,共10类(0~9)。不使用dropout机制的标准神经网络和SVM方法,错误率分别为1.6%和1.4%,在使用dropout后,错误率降低到1.35%,再用ReLU代替Logistic,错误率再降低到1.25%,接着配合max-norm constraint,错误率降低到1.06%,增加网络的大小后,错误率降低至0.95%。在预训练的深度玻尔兹曼机基础上,使用dropout,错误率能达到0.79%。
SVHM
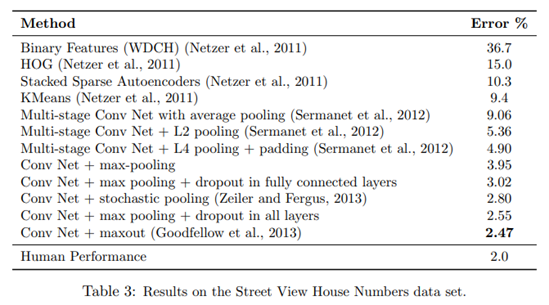
SVHM数据集由谷歌街景收集的32×32的房屋号码的彩色图像,分类任务是为了确认这些号码数字。传统的特征提取方法Binary Features和HOG,错误率分别为36.7%和15.0%;采用卷积神经网络,在不同池化策略下(均匀池化、L2池化、L4池化和最大池化)分别取得9.06%、5.36%、4.90%和3.95%错误率;在全连接层添加dropout,能使得错误率降低为3.02%,在每层添加dropout,错误率降低至2.47%,人工表现为2%,仅差0.47%。

CIFAR-10和CIFAR-100
CIFAR-10和CIFAR-100数据集分别由10个和100类别的32×32个彩色图像组成。采用卷积神经网络,在CIFAR-10错误率为15.60%,在CIFAR-100错误率43.48%;仅对全连接层采用dropout,CIFAR-10错误率降为14.32%,CIFAR-100错误率降为41.25%;对每层采用dropout,CIFAR-10错误率降低到12.61%,CIFAR-100错误率降低到37.20%。


ImageNet
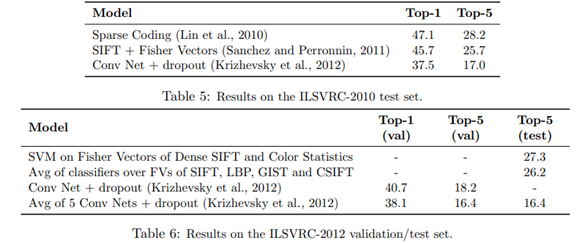
ImageNet是一个具有1500万标记的高分辨率图像数据集,包含22000类别。从2010年开始,每年举办ILSVRC挑战,其数据集选择ImageNet的一个子集,共1000类别,每类由1000张图片组成。卷积神经网络和dropout的模型取得了ILSVRC-2012的冠军,在top-1和top-5错误率分别降低到38.1%和16.4%,相比人工提取特征方式,降低将近10%(top-5 27.3%);在ILSVRC-2010测试集上表现(top-1 37.5%,top-5 17.0%)错误率也低于其他模型8%左右。

语音数据集
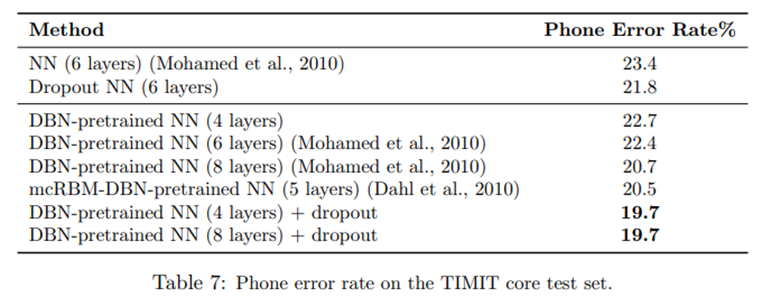
TIMIT数据集,由680位志愿者录音组成,在无噪音环境下阅读10个句子,包含美国英语8种主要方言。对于6层的标准神经网络,错误率为23.4%,使用dropout后,错误率降低21.8%。采用预训练的DBN,在4层和8层情况下,错误率为22.7%和22.4%,使用dropout后,错误率降低为19.7%。
文本数据集
Reuter-RCV1数据集,由来自路透社的800000篇文章,涵盖各种主题,分类的任务是将文章划分为相应的主题。在没有使用dropout的神经网络,错误率为31.05%;在使用dropout的神经网络,错误率降低到29.62%。相比于视觉和语音,dropout在文本上改进较小。
生物基因数据集
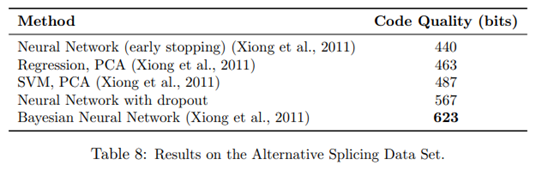
Alternative Splicing数据集来自遗传学领域,任务是根据RNA特征来预测选择性剪接的发生。评估指标是代码之类,它是目标与预测概率分布之间的负KL散度的量度(越高越好)。在这类数据集上贝叶斯神经网络表现效果最佳(623),dropout的神经网络其次(567),不带dropout的神经网络最差(440),说明dropout还是起到一定的作用。
总结与展望
总结
Dropout是一种有效减少神经网络过拟合的技术,且在图像、文本、语音和计算生物数据上都得到验证,这证明Dropout是通用技术,不特定于某个领域。
展望
Dropout的缺点之一就是增加了训练时间,通常其训练时间是一般的2-3倍,这是由于参数更新非常随机,因为每次都要对不同的子网络进行训练,而正在计算的梯度并不是最终测试的网络结构的梯度。但是同时这种随机性可能会防止出现过拟合。未来可能在如何加速Dropout方面进行进一步的研究。
论文:Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1), 1929-1958.
这一篇是补上周缺席的文献阅读打卡。
