





前言
根据所有用户对物品或者信息的评价,发现物品和物品之间的相似度,然后根据用户的历史偏好信息将类似的物品推荐给该用户.
1
基于物品协同过滤的思想
■ 核心思想
根据所有用户对物品或者信息的评价,发现物品和物品之间的相似度,然后根据用户的历史偏好信息将类似的物品推荐给该用户。
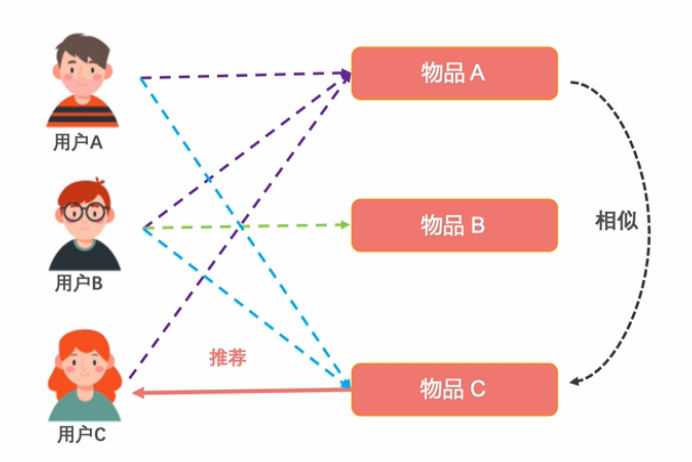
■ 基于物品协同过滤的原理
在基于物品的协同过滤出现之前,信息过滤系统最常使用的是基于用户的协同过滤。基于用户的协同过滤首先计算相似用户,然后再根据相似用户的喜好推荐物品,这个算法有这么几个问题:
用户数量往往比较大,计算起来非常吃力,成为瓶颈;
用户的口味其实变化还是很快的,不是静态的,所以兴趣迁移问题很难反应出来;
数据稀疏,用户和用户之间有共同的消费行为实际上是比较少的,而且一般都是一些热门物品,对发现用户兴趣帮助也不大。
和延于用户的不同,基于物品的协同过滤首先计算相似物品,然后再根据用户消费过、或者正在消费的物品为其推荐相似的,基于物品的算法怎么就解决了上面这些问题呢?
首先,物品的数量。或者严格的说可以推荐的物品数量往往少于用户数量;所以一般计算物品之间的相似度就不会成为瓶颈。
其次,物品之间的相似度比较静态,它们变化的速度没有用户的口味变化快;所以完全解耦了用户兴趣迁移这个问题。
最后,物品对应的消费者数量较大,对于计算物品之间的相似度稀疏度是好过计算用户之间相似度的。
■ 基于物品协同过滤的构建过程
协同过滤最最依赖的是用户物品的关系矩阵,基于物品的协同过滤算法也不能例外,它的基本步骤是这样的:
构建用户物品的关系矩阵,矩阵元素可以是用户的消费行为,也可以是消费后的评价,还可以是对消费行为的某种量化如时间、次数、费用等;
产生推荐结果,根据推荐场景不同,有两种产生结果的形式。一种是为某一个物品推荐相关物品,另一种是在个人首页产生类似“猜你喜欢”的推荐结果。
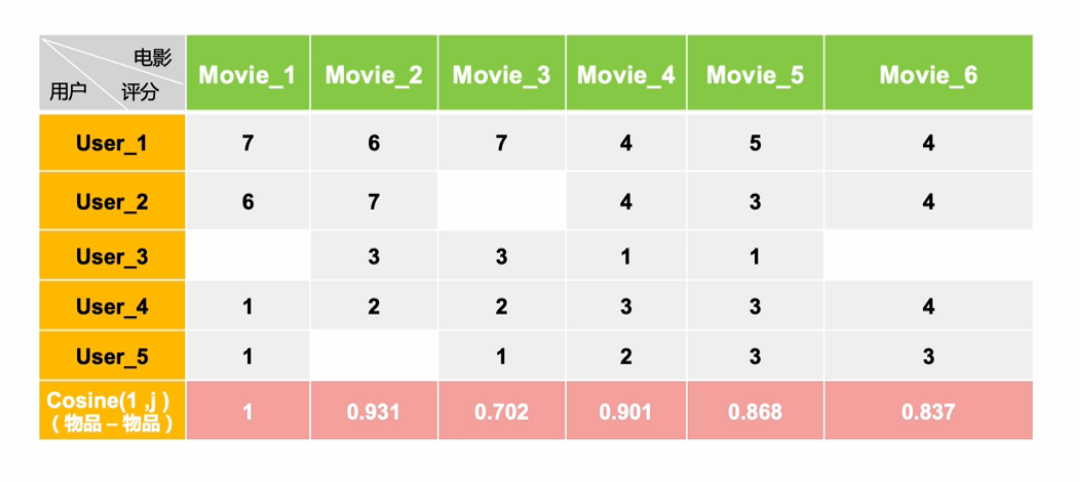
■ 物品相似度计算
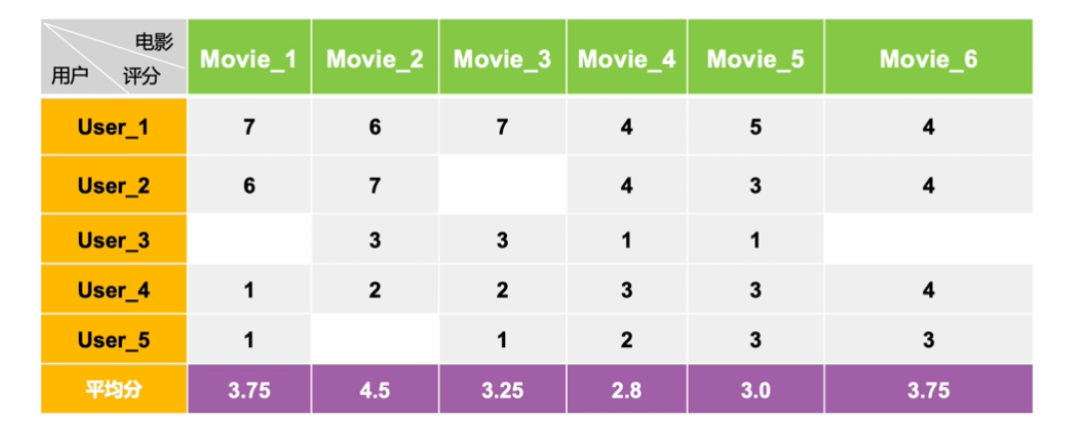
从用户物品关系矩阵中得到的物品向量如下:
它是一个稀疏向量;
向量的维度是用户,一个用户代表向量的一维,这个向量的总共维度是总用户数量;
向量各个维度的取值是用户对这个物品的消费结果,可以是行为本身的布尔值,也可以是消费行为量化如时间长短、次数多少、费用大小等,还可以是消费的评价分数;
没有消费过的就不再表示出来, 所以说是一个稀疏向量。
■ 物品相似度计算
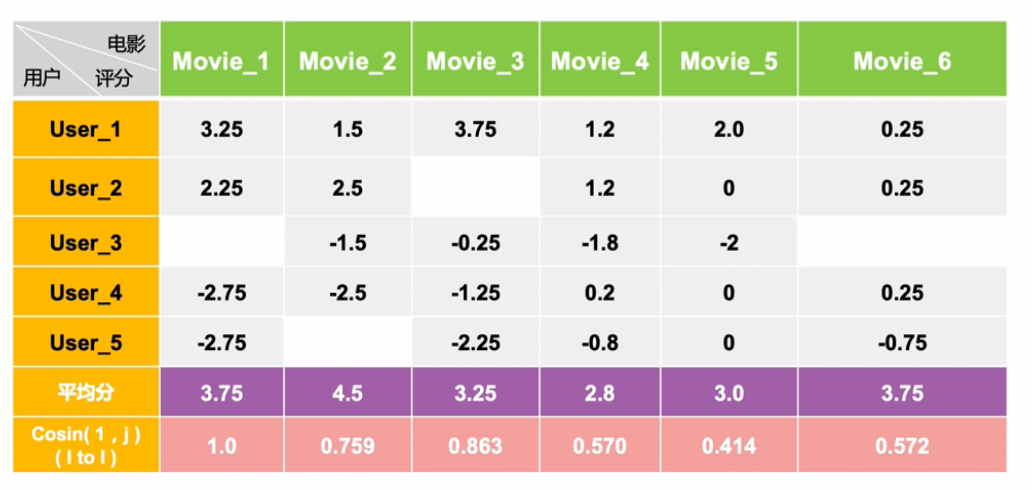
接下来就是如何两两计算物品的相似度了,一般选择余弦相似度,当然还有其他的相似度计算法方法也可以。计算公式如下:
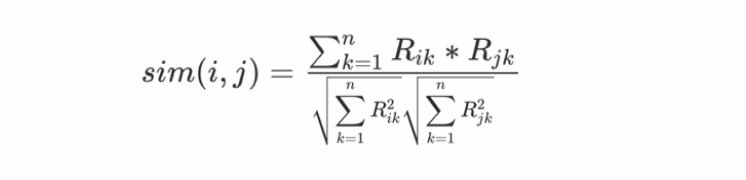
分母是计算两个物品向量的长度,求元素值的平方和再开方。分子是两个向量的点积,相同位置的元素值相乘再求和。
■ 物品相似度计算_升级与优化(调整余弦相似度)
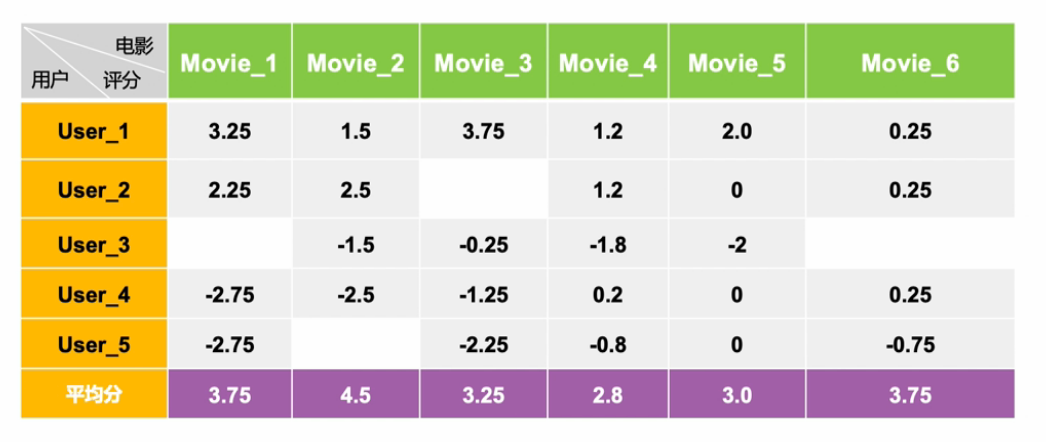
首先进行物品中心化。把矩阵中的分数减去的是物品分数的均值;先计算每一个物品收到评分的均值,然后再把物品向量中的分数减去对应物品的均值。这样做的目的是什么呢?去掉物品中铁杆粉丝群体的非理性因素,例如一个流量明星的电影,其脑残粉可能会集体去打高分,那么用物品的均值来中心化就有一定的抑制作用。
计算公式:
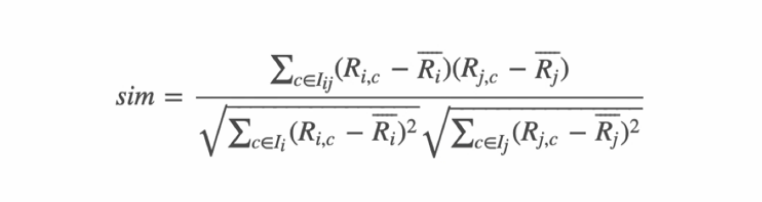
求平均分:
均值化之后的分数:
计算相似度值:
2
计算推荐方式
■ 计算推荐结果
在得到物品相似度之后,接下来就是为用户推荐他可能会感兴趣的物品了,基于物品的协同过滤,有两种应用场景。
■ 方式一 :相似度加权汇总(离线计算场景)
汇总和“用户已经消费过的物品相似”的物品,按照汇总后分数从高到低推出。
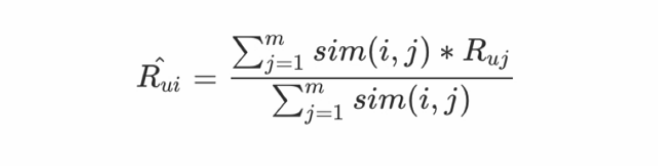
这个公式描述一下,核心思想就和基于用户的推荐算法一样,用相似度加权汇总。要预测一个用户u对一个物品i的分数,遍历用户u评分过的所有物品,假如一共有m个,每一个物品和待计算物品i的相似度乘以用户的评分,这样加权求和后,除以所有这些相似度总和,就得到了一个加权平均评分,作为用户u对物品i的分数预测。
和基于物品的推荐一样,我们在计算时不必对所有物品都计算一边,只需要按照用户评分过的物品,逐一取出和它们相似的物品出来就可以了。这个过程都是离线完成后,去掉那些用户已经消费过的,保留分数最高的k个结果存储。当用户访问首页时,直接查询出来即可。
■ 方式二: Slope One相关推荐算法实时计算场景)
场景:
这类推荐不需要提前合并计算,当用户访问一个物品的详情页面时,或者完成一个物品消费的结果面,直接获取这个物品的相似物品推荐,就是“看了又看”或者“买了又买”的推荐结果了。
经典的基于物品推荐,相似度矩阵计算无法实时更新,整个过程都是离线计算的,而且还有另一个问题,相似度计算时没有考虑相似度的置信问题。例如,两个物品,他们都被同一个用户喜欢了,且只被这一个用户喜欢了,那么余弦相似度计算的结果是1,这个1在最后汇总计算推荐分数时,对结果的影响却最大。
Slope One算法针对这些问题有很好的改进。在2005年首次问世,Slope One算法专门针对评分矩阵,不适用于行为矩阵。Slope One算法计算的不是物品之间的相似度,而是计算的物品之间的距离,相似度的反面。该算法适用于物品更新不频繁,数量相对较稳定并且物品数目明显小于用户数的场景。依赖用户的用户行为日志和物品偏好的相关内容。
优势:
算法很简单,易于实现,执行效率高,同时推荐的准确性相对较高。Slope One算法是基于不同物品之间的评分差的线性算法,预测用户对物品评分的个性化算法。


扫描二维码 关注我们
微信号 : BIGDT_IN
