





前言
调整后的余弦相似度更能反应用户的真实喜好,本文将介绍如何进行中心化处理。
相似度计算升级与优化
■ 相似度计算升级与优化(调整余弦相似度)
为什么调整余弦相似度?
基于余弦的相似度计算方法未考虑用户的差异性打分情况,每个人标准不一样,有的标准严苛,有的宽松,所以减去用户的均值可以在一定程度上仅仅保留了偏好,去掉了主观成分。
调整的余弦相似度计算就是用用户均值中心化后的向量进行余弦相似度计算,因为中心化后的值才相对真实反映用户的喜好,即把矩阵中的分数,减去对应用户分数的均值;先计算每一个用户的评分均值,然后把他打过的所有分数都减去这个均值——用户中心化。
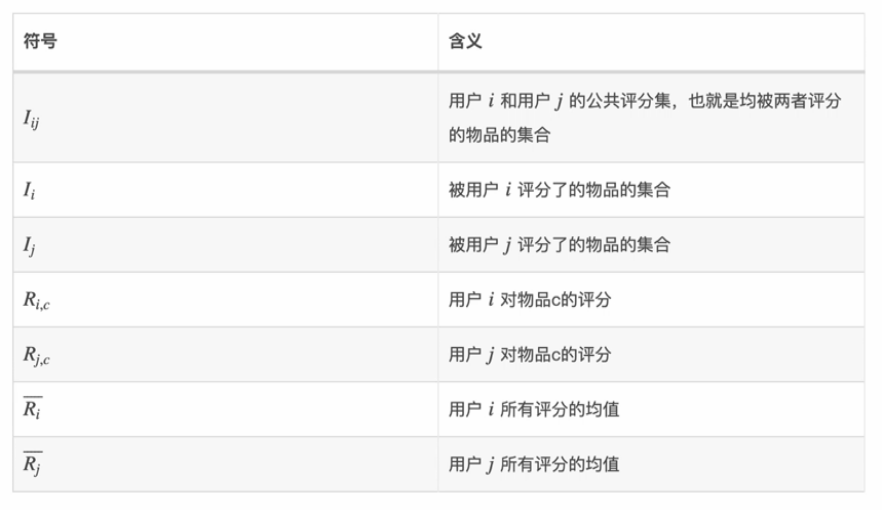
调整余弦相似度计算公式:

修正的余弦系数分子是两个用户共同(因为余弦缺省值为0,向量相乘因为0而结果为共同评分集)的评分集,分母是两个用户各自的评分集。
调整余弦相似度计算公式说明:
利用上公式计算平均值为:

重新计算User_3与其他用户两两计算之间的相似度:

代码验证相似度并预测分值
1、spark程序验证,将表格数据转换成向量数据。这里验证正常的余弦相似度计算。
import org.apache.spark.ml.recommendation.ALS.Ratingimport org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry}import org.apache.spark.sql.{Row, SparkSession}object CosUser {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[5]").getOrCreate()import spark.implicits._val movelRating = spark.read.textFile("/Users/zhangjingyu/Desktop/ES学习/utou_main.csv").map(line => {val fileds = line.split(",")Rating(fileds(0).toInt,fileds(1).toInt,fileds(2).toFloat)}).toDF("user","item","rate")val matrixRdd = movelRating.rdd.map{//这里将用户与物品减缓是因为后续相似度计算是以列(用户)来计算的case Row(user : Int ,item : Int , rate : Float) => {MatrixEntry(item.toLong,user.toLong,rate.toDouble)}}val coordinateMatrix = new CoordinateMatrix(matrixRdd)// val result = coordinateMatrix.entries/*** MatrixEntry(1,1,7.0)* MatrixEntry(1,2,6.0)* MatrixEntry(1,3,7.0)* MatrixEntry(1,4,5.0)* MatrixEntry(1,5,5.0)*/val res_entr = coordinateMatrix.toIndexedRowMatrix().columnSimilarities().entriesval res_df = res_entr.map(x => {(x.i , x.j ,x.value)}).toDF("user_id","sim_user_id","score")//查看与用户3相似的用户以及相似度res_df.where("user_id = 3 or sim_user_id = 3").sort(res_df("score").desc).show()}}
打印结果比对发现符合:

2、这里验证调整的余弦相似度计算
import org.apache.spark.ml.recommendation.ALS.Ratingimport org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry}import org.apache.spark.sql.SparkSessionimport org.apache.spark.sql.Rowobject CosUserOpt {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[5]").getOrCreate()import spark.implicits._val movieRating = spark.read.textFile("/Users/zhangjingyu/Desktop/ES学习/utou_main.csv").map(line => {val field = line.split(",")Rating(field(0).toInt,field(1).toInt,field(2).toFloat)}).toDF("user_id","movie_id","rate")//按用户分组,求rate的平均数val movieRatingMean = movieRating.groupBy("user_id").mean("rate").toDF("user_id","m_rate")//将两张表关联val movietable = movieRating.join(movieRatingMean,"user_id").toDF("user_id","movie_id","rate","m_rate")//创建临时表movietable.createOrReplaceTempView("ratings")//求中心化val res_movieRating = spark.sql("select user_id,movie_id,(rate - m_rate) as rate from ratings")// res_movieRating.show(false)//这里的输入要与上面select信息一致val matrixRdd = res_movieRating.rdd.map{case Row(user_id : Int , movie_id : Int , rate : Double) => {//输出把用户作为列值,因为要统计相似用户MatrixEntry(movie_id.toInt,user_id.toInt,rate.toDouble)}}val coordinateMatrix = new CoordinateMatrix(matrixRdd)val res_entr = coordinateMatrix.toIndexedRowMatrix().columnSimilarities().entriesval res_df = res_entr.map(x => {(x.i , x.j , x.value)}).toDF("user_id","similary_user_id","score")res_df.where("user_id = 3 or similary_user_id = 3").sort(res_df("score").desc).show(false)}}
打印结果比对发现符合:

3、User_3用户产生推荐结果,通过均值中心化重新对R31和R35进行评分预测,与之对应的预测公式为:

4、通过公式,我们可以预测出User_3对Movie_1和Movie_5的评分,从用户的相似值来看,User_3与User_1和User_2相似度最高,所以我们通过User_1和User_2的评分值和相似值来预测:


扫描二维码 关注我们
微信号 : BIGDT_IN
文章转载自数据信息化,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
