




本来很期待倚天710发布后有一个DeepDive Session,似乎除了那个跑分就没有后文了,66B晶体管128核+DDR5,似乎感觉Cache不会做到很大. 而昨天半夜AWS带来了Graviton3的DeepDive,下面我们就来看看它的内部结构吧

Annapurna
Annapurna或许算得上AWS最成功的收购,公司名让渣想起来以前登山的日子,渣开玩笑说以后自己要去创业一定把公司名叫做Qogir,去爬最难攀登的峰. Annapurna的任何一块芯片都可以堪称世界顶级之作.
吐槽:低延迟真的需要么?
说到Annapurna估计在国内最出名的还是DPU赛道的Nitro,国内有些人啊,总是想不明白张口怼人家Nitro是一个NP架构是过时的技术,FPGA才是最牛逼的?似乎另一方面又怼人家SRD延迟高,自己延迟低。Nitro System 和Nitro SSD的区别是什么?本质上还是没有了解workload的区别。渣可以很明确的告诉你们一般的架构师只能像个普通厨子用山珍海味学做菜,而最顶级的厨子总是根据最朴素的食材和客人的特点做出绝美的风味。
如果真要比低延迟,有些东西还在十微秒级徘徊,而渣参与了国内很多交易所和一些机构的超低延迟设计,早就把这些东西降到了纳秒级,不贴点数据不知道差距?
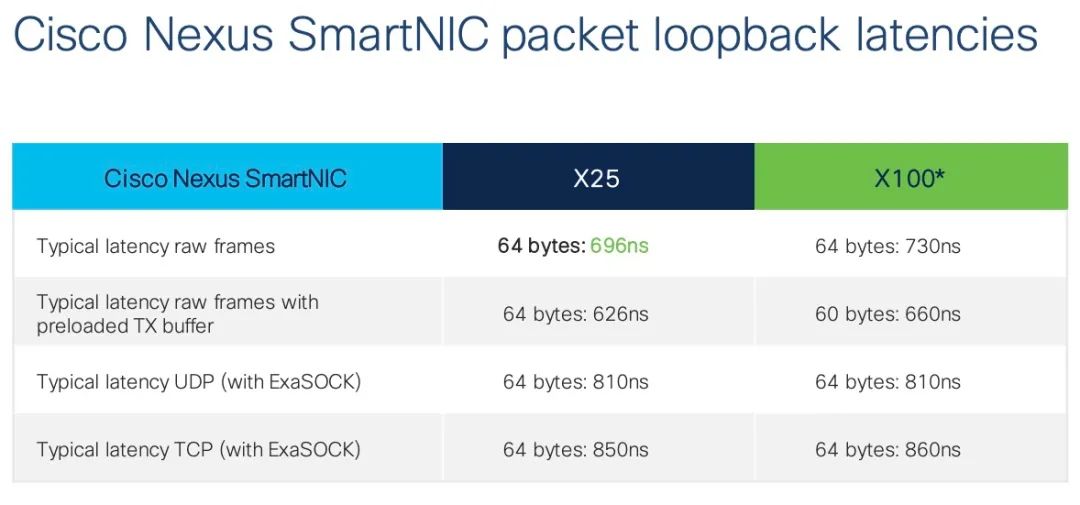
国内做高频交易的基本上人手一块Exablaze的卡,利用ExaSock下单交易,900ns的延迟不香么?

在微秒级有什么值得沾沾自喜的?把以太网控制器上省寄存器和AXIS协议上减信号,以及过分的将串行链路改并行降低延迟,延迟隐藏和压缩传输数据的骚操作多的去了,你才学会多少?
至于RTC的芯片就是NP了,NP就是过时的技术么?那么思科为啥要在最顶级的Silicon One上面回归到RTC架构,为啥Pensando要在P4上扩展PC和通用寄存器,为啥会有NanoPU这样的东西存在?人家都算NP?有些时候芯片面积、功耗、功能这三者之间的坑要填的东西太多,你不明我不语...
回到正题:Graviton3架构解析
Graviton3是一个Chiplet的设计,使用了DDR5、PCIe5.0,总共64个核,性能比Graviton2提升了25%以上,累计55B个晶体管:

CPU核心的架构如下所示,前端核后端都扩宽了很多
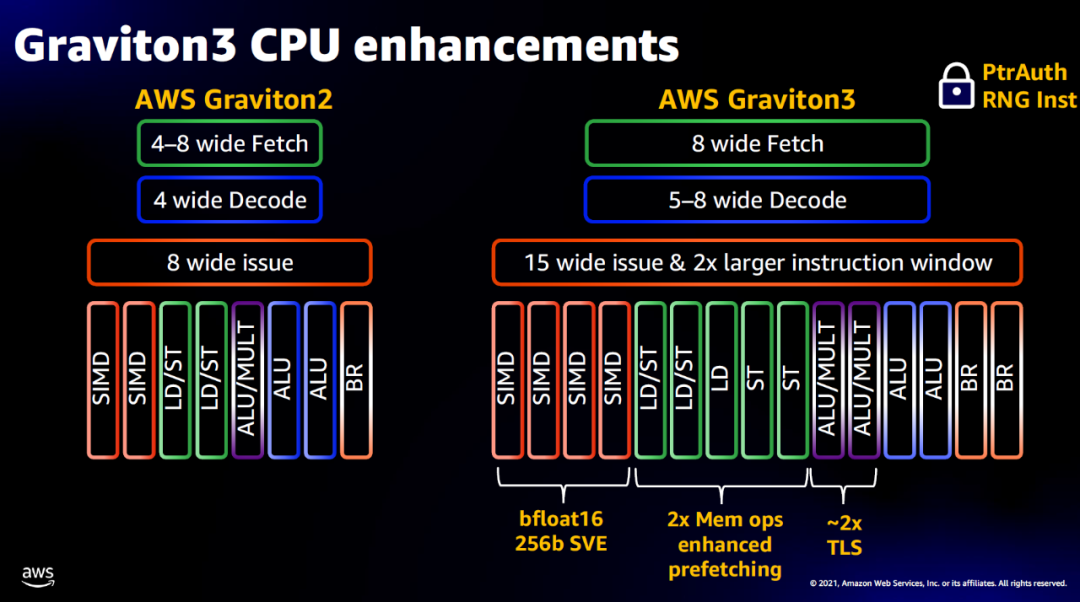
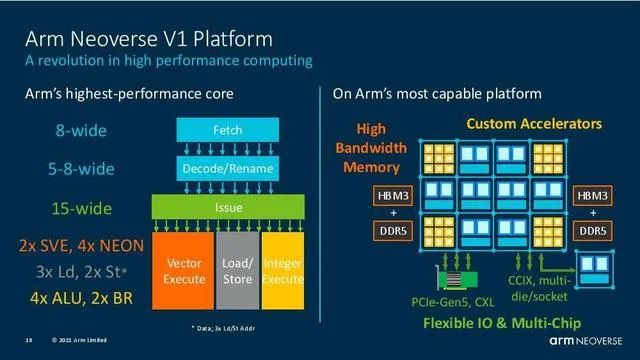
而这些特征都指向一个明显的东西ARM Neoverse V1核架构:
可以看到清晰大图由7个Chiplet构成,两个PCIe gen5,四个DDR5以及一个64 V1 Core构成的2DMesh核心,设计上把周边的I/O通过Chiplet连接到处理器的片上网络,做法非常巧妙,也为以后变种连接其它DSA提供了便利,例如阿里前几天发布的3D键合什么的封装的存算一体啥的...抱歉前缀太长记不清楚名字了..

而同样Intel Ponte Vecchio的创新国内几乎没人读得懂...

当大家还在说Graviton3核心只有倚天一半的时候,又一个骚操作来了,AWS直接在一个标准服务器上搞了3路Graviton

然后三路Graviton同时共享一个Nitro卡,问题来了,PCIe怎么接的,笑而不语~
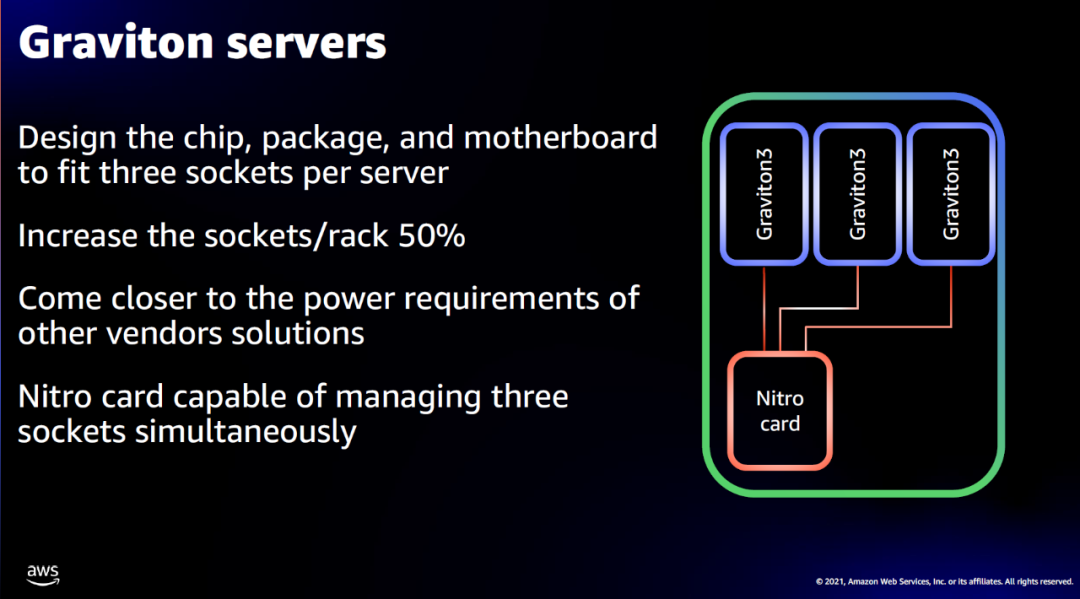
未来很多竞争在片上网络(NOC)和Chiplet的设计上...
Graviton3性能
比较阿里只有一个模糊的跑分提升比例,Graviton3直接贴出了图来:
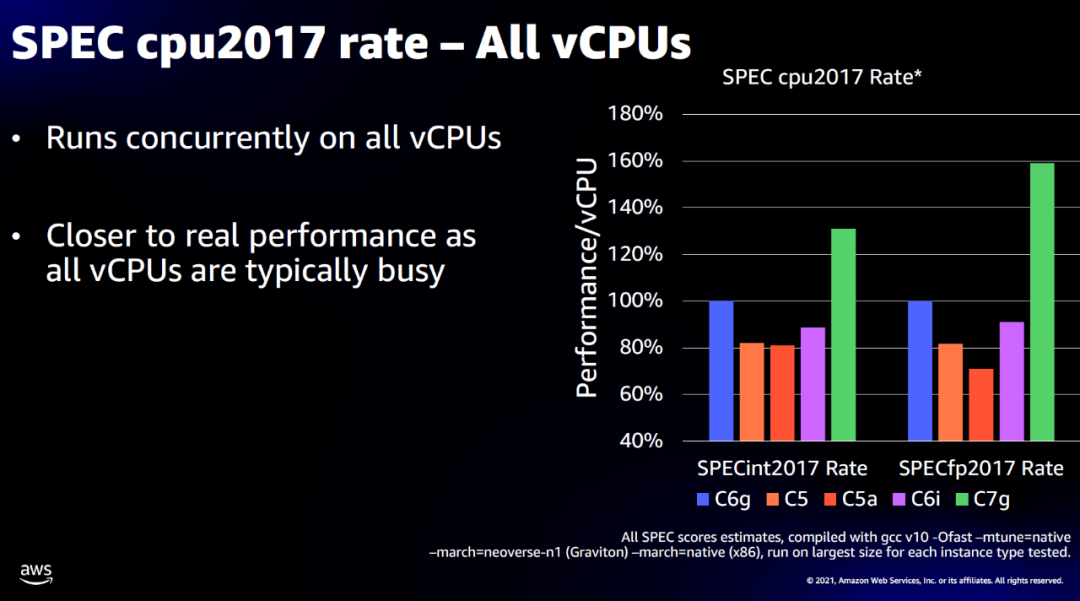
针对常见的负载均衡场景性能也提升了一倍:

这下领教了新的Neoverse V1核的性能了吧,这也是渣一开始就苦口婆心让某个国内的用N1的DPU厂商一定要上N2的原因,毕竟渣是在最早期就跟国外某个做N2的DPU在合作的..
而同样Video编码这些业务性能也提升了60%,基本上针对抖音这样的客户都可以抛弃一些GPU的视频编码纯CPU做了

而针对一些F1的流体力学计算场景也提升了40%

bfloat16的加持,ML性能也翻倍了:

ARM migration
Re:invent最诚意的部分是会叫上客户一起来看怎么adopt新的技术,这也是收获最大的部分,这次选择了DirectTV,它是一个典型的云原生企业,基于K8S实现的微服务架构,在Graviton以前都是用X86的架构, 310个golang的微服务、435个SpringBoot、25个NodeJS还有35个Platform Service,当然由于Go的跨平台能力比较好,渣自己常常用go也是为了在ARM和X86上共享,所以Migration以go平台最先:

后面具体的内容就自己去听直播了吧,毕竟AWS人家有版权的,全文翻译会带来麻烦...(不要戳穿我因为懒嘛....
