




国内很多人对于AWS的SRD一张口就是这玩意做的不咋地延迟一坨屎. 可惜懂的人真的少啊,数通的年代,渣就拿着一个40Gbps 25us的路由器干翻了国内外一堆1Tbps 2us路由器(包括自家的ASR9K),讲真pps和延迟对于很多客户的业务都不是个事(即便是对延迟非常敏感的证券交易),而正如渣说的云IaaS环境现在20Mpps完全够了,比50Mpps或者30Mpps就是属于无聊,Nitro用ARM做RTC是智慧,只有真正体系架构里做过的人才懂,而魔鬼般的细节藏在
抖动
里...
只可惜有些人抄作业都抄错,最简单的out-of-order和抖动没学会,只学到了TCP over RDMA over TCP..
抖动的重要性
其实很多业务通过应用层的并行pipeline处理,但是一个抖动一来就打乱了整个流水线的,例如RoCEv2的PFC带来的影响,比较低俗的说法大家去了解一下肠梗阻
就好了.所以SRD on ENA发布的时候最重要的一点是tail latency

如果要量化的来看,首先一个例子大概就是老董前段时间测试过一个<神龙 vs Nitro>的报告[1],关于延迟和抖动对标AWS抖动远好于阿里, 标准差 6.604 vs 2.226, 特别注意测试结果的p99.9 latency,Nitro只有32us,而阿里神龙到了108us

测试结果的影响呢,就是ngnix在短流场景中QPS性能接近于神龙的两倍,注意到抖动的指标和p99延迟
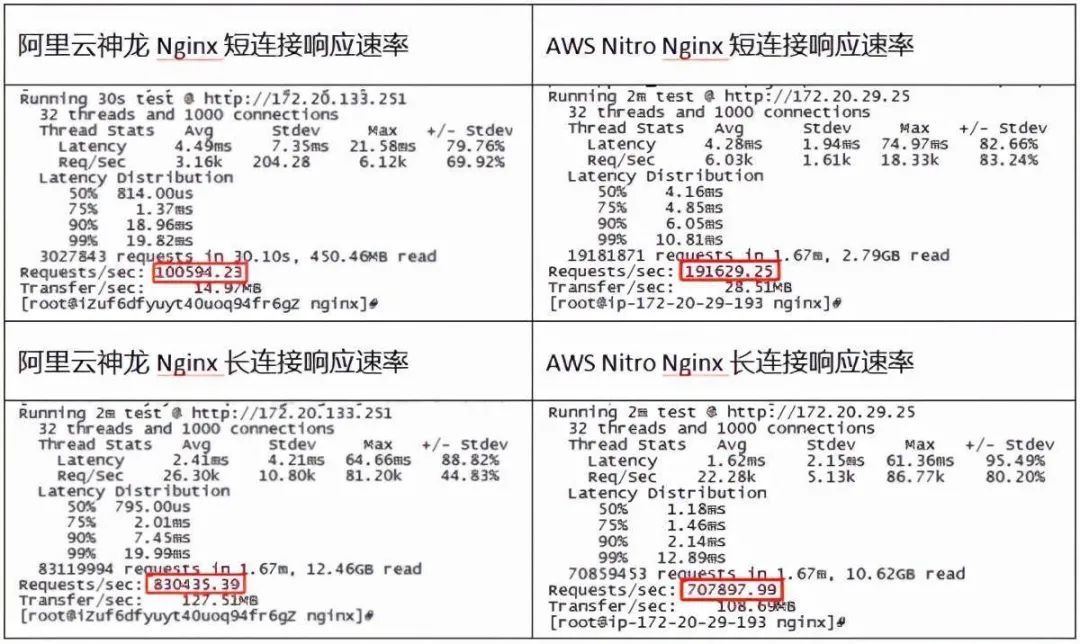
而长连接明显是因为一些overhead导致的,类似于两家对于千兆的定义不同,阿里刚好跑满(127.51MB/s),而Nitro是108.69MB/s,瓶颈在underlay ratelimit机制上.
但是有个灵魂拷问, 为什么阿里会有那么大的Jitter呢?FPGA实现理应远低于ARM RTC的抖动才对啊,那么问题出在哪呢? 底层的AIS交换机和神龙配合的问题?还是神龙自身的设计问题呢?
SRD 概述
SRD的实现方式国内也很多人在脑补,似乎都没有补对,渣这种把802.3和IBTA IB ArchSpec都认真研读过的人(两个累计起来一万多页), 再看了一下AWS的EFA驱动[2],再加上AWS Re:Invent的session和2019年AWS在OpenFabric的演讲[3],基本补全了.
首先SRD是一个基于以太网
的协议,然后基于第三代的Nitro芯片实现的,可惜很多人只读懂了Low-Latency,然后也只会喷low-latency而不知道Network-intensive的奥妙.
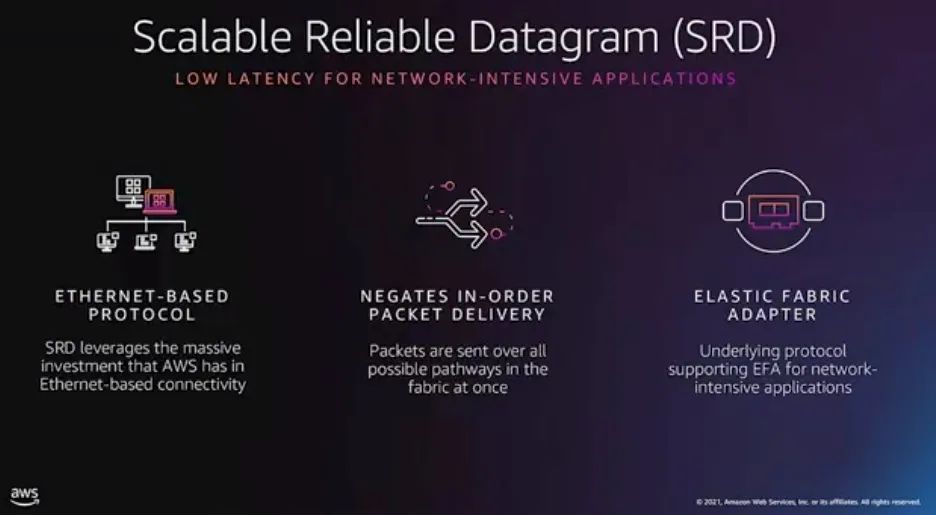
它受到Infiniband Reliable Datagram的启发,主要改进是outstanding message 和packet-order上,至于拥塞控制并不是增加吞吐或者像国内很多人研究的FCT(流完成时间)而是控制抖动和丢包:

然后我们来看看IB ArchSpec Vol1 Chapter 9 Transport Layer中的描述,基本传输层头格式如下:
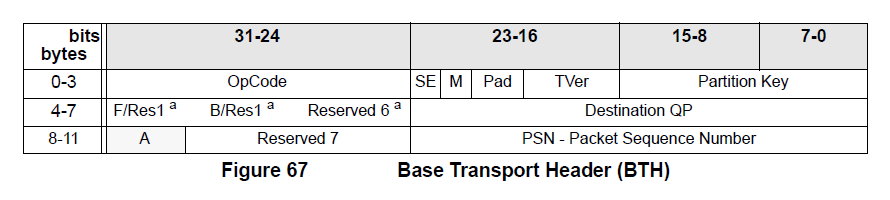
针对一个Reliable Datagram (RD)的传输,我们来看SEND原语的实现,它分为SEND First、SEND Middle、 SEND Last 或者单个包SEND Only.

也就是说,在QP传输时,单次只允许一个Outstanding Message,这个Message可以有多个SEND 消息组成,但是要有明确的SEND First和SEND Last作为消息的起始和终结,并且由于保序列的原因导致了一系列缺陷,这就是SRD要解决的问题:
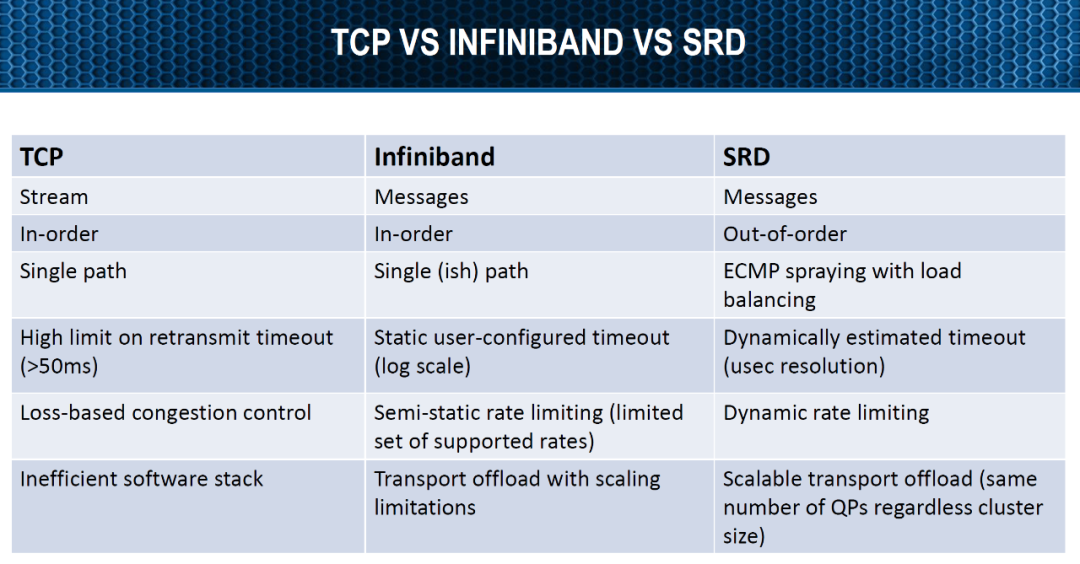
最关键的问题是一旦实现了Out-Of-Order和Multiple Outstanding Message那么就完成了多路径的支持,这也是今年AWS Re:Invent上强调的:
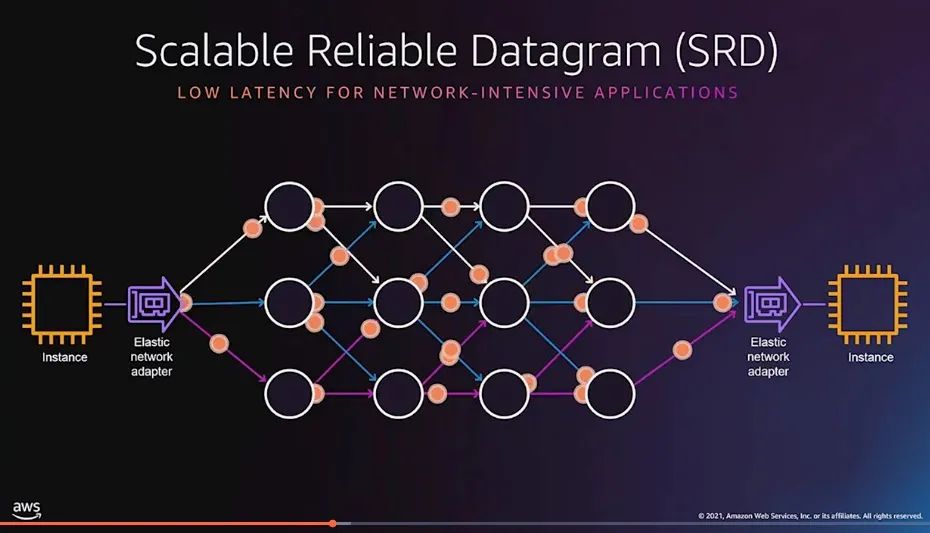
当然针对Out-Of-Order,本质上是通信算子满足交换律,这个本文最后会给大家再讲一遍一个名叫半格
(Semi-Lattice)的代数结构
接下来我们继续看SRD实现的最大Message Size是8KB,这个数据对于研究SRD实现非常重要,请留意

然后我们继续留意到driver里的信息:

很简单的一个理解就是,它通过创建Address Handle(AH)来构建了local Queue和Remote Queue的对应关系,同时也利用这种关系避免了Reliable Connected (RC) 那样的Fullmesh QP带来的Scale的问题。但至少你可以看到,它的传输还是基于两个队列的,源有一个TXQ,目的有一个RXQ,利用SEND WR带AH来调度。然后我们进一步分析EFA为了支持SRD的commit到rdma-core的代码:
int efa_query_device(struct ibv_context *uctx, struct ibv_device_attr *attr);
int efa_query_port(struct ibv_context *uctx, uint8_t port,
struct ibv_port_attr *attr);
int efa_query_device_ex(struct ibv_context *context,
const struct ibv_query_device_ex_input *input,
struct ibv_device_attr_ex *attr, size_t attr_size);
struct ibv_pd *efa_alloc_pd(struct ibv_context *uctx);
int efa_dealloc_pd(struct ibv_pd *ibvpd);
struct ibv_mr *efa_reg_mr(struct ibv_pd *ibvpd, void *buf, size_t len,
int ibv_access_flags);
int efa_dereg_mr(struct verbs_mr *vmr);
struct ibv_cq *efa_create_cq(struct ibv_context *uctx, int ncqe,
struct ibv_comp_channel *ch, int vec);
int efa_destroy_cq(struct ibv_cq *ibvcq);
int efa_poll_cq(struct ibv_cq *ibvcq, int nwc, struct ibv_wc *wc);
struct ibv_qp *efa_create_qp(struct ibv_pd *ibvpd,
struct ibv_qp_init_attr *attr);
int efa_modify_qp(struct ibv_qp *ibvqp, struct ibv_qp_attr *attr,
int ibv_qp_attr_mask);
int efa_query_qp(struct ibv_qp *ibvqp, struct ibv_qp_attr *attr, int attr_mask,
struct ibv_qp_init_attr *init_attr);
int efa_destroy_qp(struct ibv_qp *ibvqp);
int efa_post_send(struct ibv_qp *ibvqp, struct ibv_send_wr *wr,
struct ibv_send_wr **bad);
int efa_post_recv(struct ibv_qp *ibvqp, struct ibv_recv_wr *wr,
struct ibv_recv_wr **bad);
struct ibv_ah *efa_create_ah(struct ibv_pd *ibvpd, struct ibv_ah_attr *attr);
int efa_destroy_ah(struct ibv_ah *ibvah);
可以看到有创建和删除QP、AH的代码,然后收发原语以及一个poll_cq的函数.
SRD实现
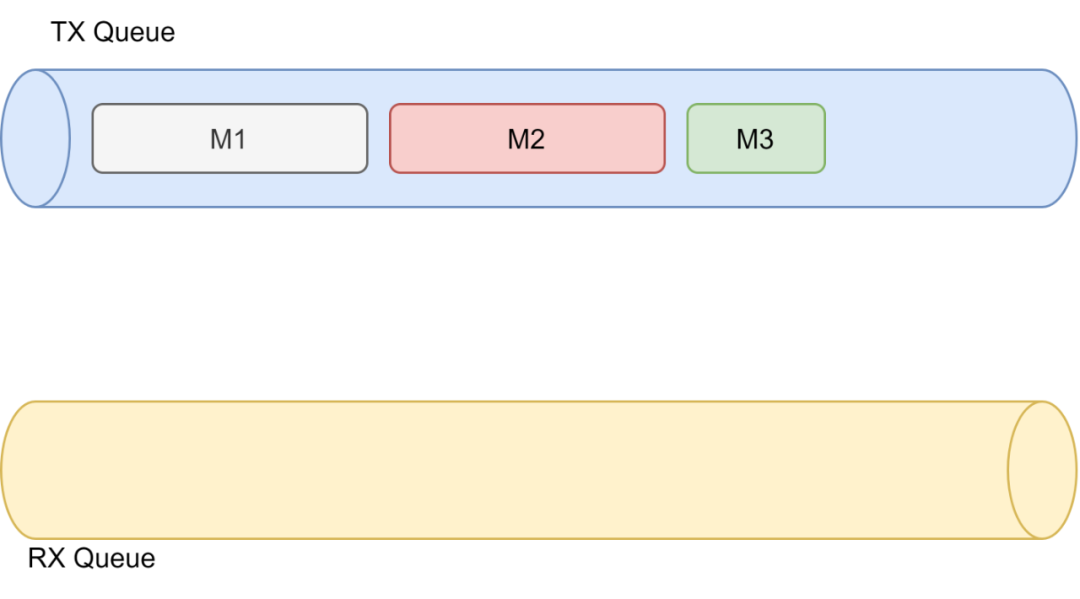
由于Nitro是基于ARM的,然后本身又是以太网,再加上互联网厂商的节奏,最简单的方法就是找个Software ROCE的协议栈来改,既然是改协议,而本质上由于AH关联了一个本地和远端队列的Association,那么我们就来看如何实现Out-Of-Order以及为什么SRD会在延迟和抖动中取舍选择抖动的原因了,整个传输过程中肯定是多个队列实现的,可以参考源代码中poll_cqs里面还有sub_cq的结构,这也就是前几天我在一文中说NetAnts、FlashGet的原因,根据不同的Overlay Flow构建不同的Sub_queue实现并行传输.
当然简单起见我们以一个队列对为例:
发送报文时,为了降低抖动,其实可以天然的想到QUIC的Frame实现方式和ATM信元的实现方式,将报文拆分成更小的block传输会得到更加一致的延迟
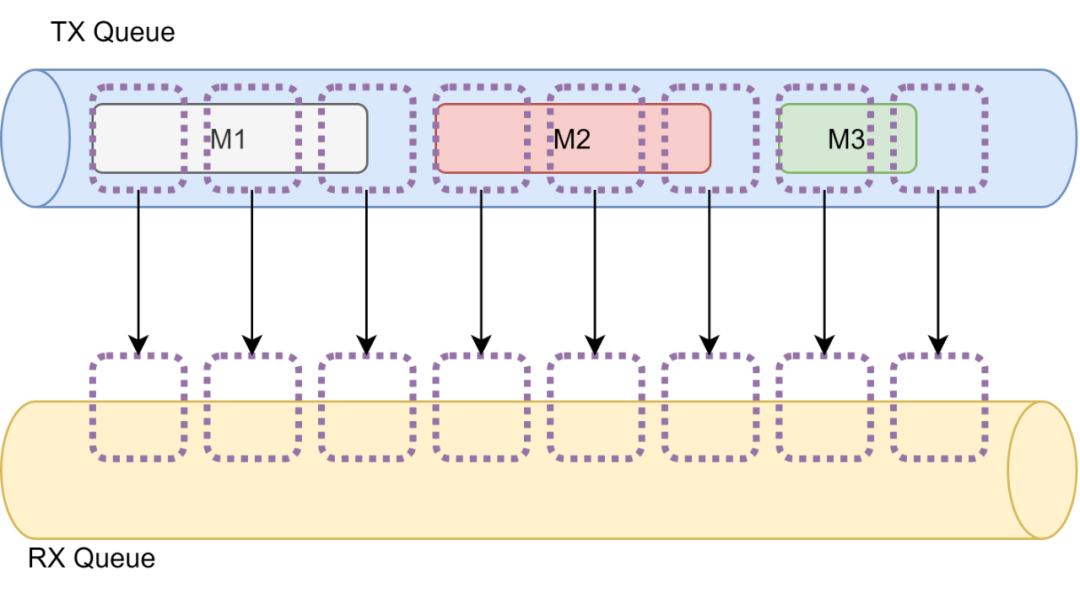
然后分块去ACK实现可靠传输,但是具体实现的过程中又需要考虑几个关键的问题:
分成的块需要多大合适 ACK机制如何设计 拥塞控制和重传如何设计
分块大小 = 512B
首先我们来看分块大小,其实很简单的就推测出来了,很多数据中心交换机在小于256B时不会做到线速转发,然后根据TCP单性能提升了3倍,那么很显然 1500B /3 向上取整为512B, 而前面让大家留意了最大8KB,证明刚好16个包,所以可以推导出下面的BitMap ACK机制
ACK机制(Bitmap SACK)
注意到SRD提到EE Context没有用了,但是EE Context字段有24bit,那么我们是否可以把PSN变成Message Seq Number(MSN),然后利用EE Context 构建一个16bits的bitmap的结构呢?
因为多路径的out-of-order到达,如果单纯的对分块再构建seq会比较低效,构建bitmap会更加简单一些,一个简单的set操作就搞定了,然后每次扫描到这个block只要是0xFFFF简单的就可以认为传完了,而且这样的bitmap也适合做高性能的Selective ACK机制,降低逐包ACK的代价。
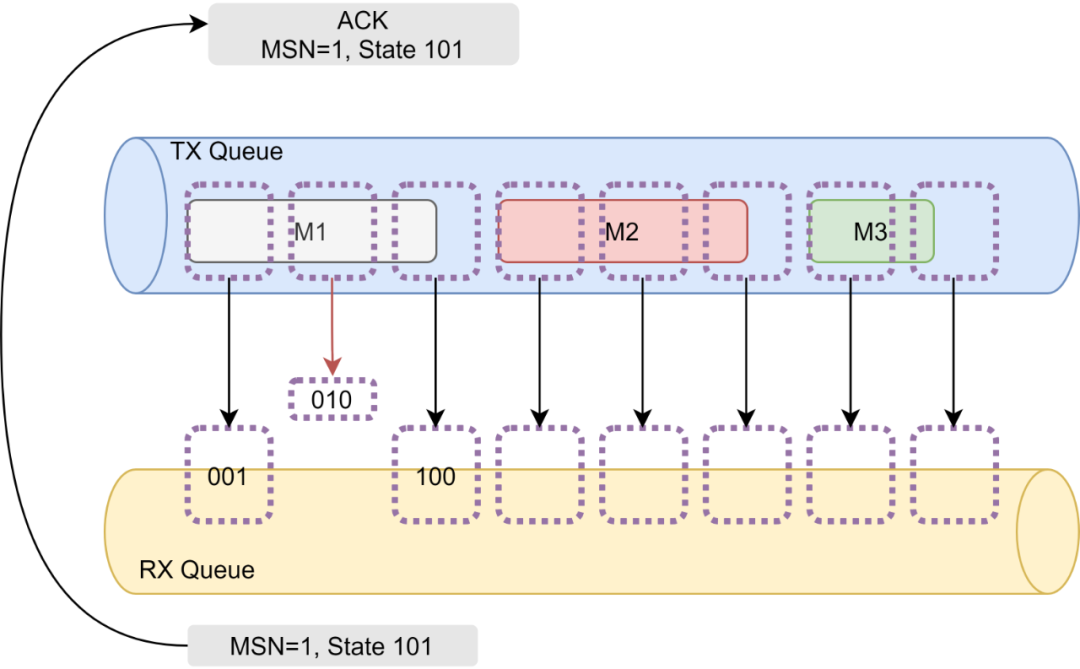
例如上图所示,第一个Block Bitmap为001,第二个为010,第三个为100,当收到包后Set相应的bit就好。例如第二个包丢了,那么收端的bitmap就是101,而对于ACK可以定期的selective ack,把整个queue里面收到的MSN和State ACK到源端,然后源端可以根据丢掉的bit或者触发自己的RTO机制重传即可,当源端收到全0xFFFF ACK可以shift自己的head指针然后free memory,而收端也可以同样的提取报文,不过收端机制也可以通过poll机制实现,poll的原理就是看state-bitmap.
拥塞控制
在这种基于block的传输机制下,本质上看到丢包就是慢慢的降低rate-limit的发包速率就好了,流控做的可以非常简单。而重传由于数据中心延迟是相对固定的,一个简单的固定RTO就可以搞定。由于收端逻辑也很简单set bit-map然后固定时间ACK,所以本质上比Swift而言有了更加确定性的延迟。
NetDAM传输层设计
昨天看到夏老师的一篇文章[4] 有一段感受很深:
在这个推演过程中,你不仅仅获得了逻辑,有些时候,获得的是惺惺相惜。我很喜欢火凤燎原的一句话: “计谋分三层,第一种计谋,单发,第二种计谋,双向互发,第三种计谋,融汇贯通。” 在地球的另一半,有人和你想得一样呢。
NetDAM的传输层设计和SRD惊人的一致,这也是我一开始就特别喜欢SRD的原因, 在设计NetDAM传输层时,我们的原则是在提供超低延迟和超大带宽的同时尽量减少对硬件的依赖,其实简单来说就是避免使用IB或者特殊的串行结构和特殊的可编程交换机,当然可编程交换机可以辅助NetDAM实现分布式的MMU和内存安全访问控制,这个在后续的章节会详细介绍。结论 :我们采用了标注的IP/UDP over Ethernet的方式来承载主机间的NetDAM通信。
确定性延迟: NetDAM具有固定的硬件流水线处理报文的读写,由于在主机间采用MPI的通信方式,因此可以避免像PCIe那样需要DMA和监听维持缓存一致性带来的长尾延迟缺陷。我们测试了线-线(wire-to-wire)使用NetDAM从远端SIMD读32个32位浮点数的操作,平均延迟618纳秒
,抖动39纳秒
,最大延迟也就920ns
(注意,我才不会用什么P99延迟麻痹自己). 这种确定性延迟对于拥塞控制非常有用,例如SWIFT就不用去测试主机处理延迟了,都固定的,underlay链路选择好了整个路径延迟就固定了,简单的流控加上去就够了。
可靠传输:在NetDAM设计中,可靠传输是可选的,因为一方面实现无丢包的以太网非常难,特别是在一些虚拟化环境中,而另一方面很多分布式系统应用层接口都具有幂等性,因此我们没有在NetDAM设计中把可靠传输作为必选,同时我们在后续的MPI Allreduce操作中也使用了幂等的处理方式来简化故障恢复,也就是满足半格的代数结构。但是正如前文所述,由于确定性延迟的存在,可靠传输实现非常容易。
保序: 在很多并行计算中,如果算子具有可交换性,因此就可以乱序执行。由于我们在NetDAM中放置了地址和数据段长度的信息在地址空间上隔离了不同的内存,因此在传输过程中的操作是完全可交换的。当然报文头部也提供了序列号的支持,用户也可以根据自己的计算任务构建相应的排序和顺序执行器件。
多路径: 许多数据中心都采用Fat-Tree的架构,当然也有很多超算也采用了2D-Torus和3D-Torus的架构,相对于超算而言,Torus的架构扩展性和经济性都会好很多。因此NetDAM提供了基于Ruta的SegmentRouting over UDP方式,并且支持Service-Chaining的方式来实现分布式计算。
本质上NetDAM就是一个更偏向硬件化实现的SRD,不过考虑的比SRD更多的就是一个半格的结构,相对于SRD只有SEND原语,NetDAM实现了WRITE、READ,当然针对更上层的MPI还实现了REDUCE_SCATTER、ALL_WRITE的原语,这些是渣做超大规模计算的精髓。
简单来说吧,阿里搞了一个EFLOPS的论文,一个网卡配一个GPU,一顿操作猛如虎,性能刚好30G.
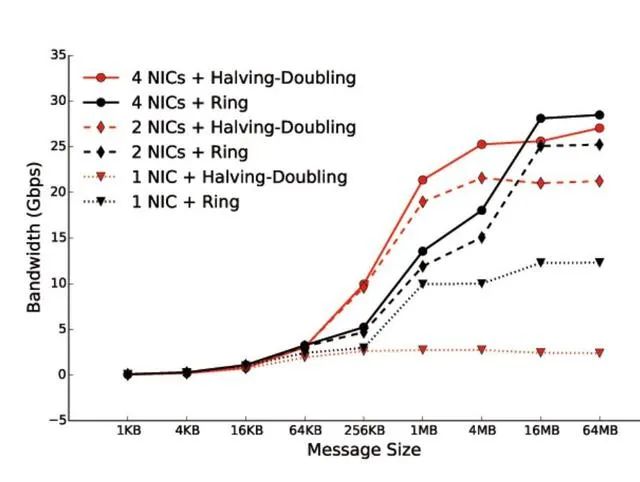
最关键的问题就在链式计算中抑制抖动,而渣能够实现基本线速的转发,本质上就在下图,消除了大量的Jitter, RoCE本身要经过多次PCIe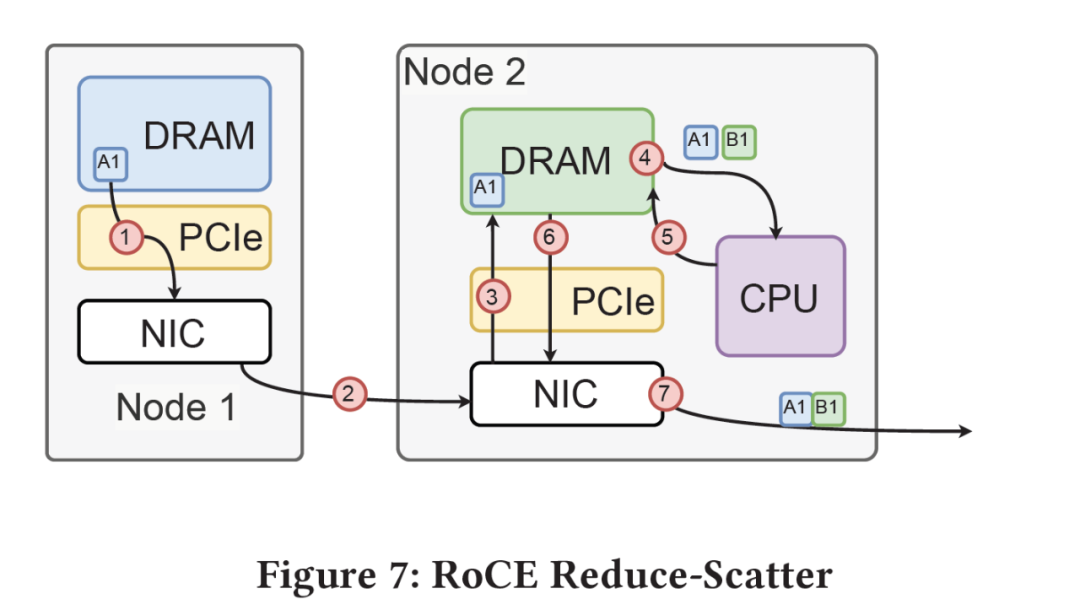 在allreduce整个链条上就放大了抖动,这也是他们放弃Ring-Allreduce采用tree sharp的原因:
在allreduce整个链条上就放大了抖动,这也是他们放弃Ring-Allreduce采用tree sharp的原因: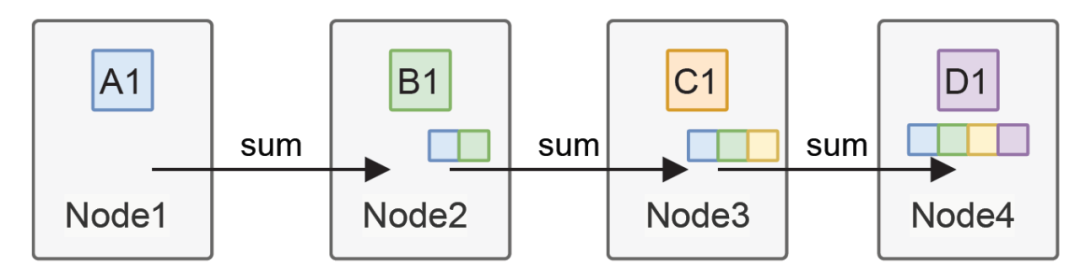
而渣直接把DRAM接到网卡上,然后计算直接在收包buffer的SRAM上计算,抖动自然小了很多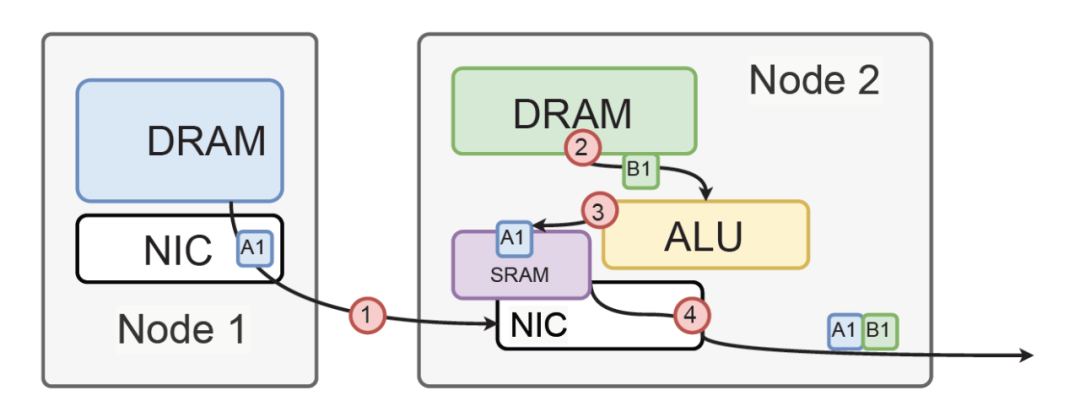
简单的说吧,NetDAM能跑到线速,性能是RoCE做Allreduce的几倍,但是就这么简单的问题,买螺丝怎么会想不到呢?这正如夏老师昨天另一句话:
经验之谈,有时候你真的能发现机会,最佳的可能是友商架构师的FC网络有遗漏(极其稀少),其次最让人开心的是友商公司的组织形式导致(大公司的组织总有毛病),这种机会最美滋滋的(当然友商也能找到我司的毛病),但大多数时候,你会发现友商的困难是你也无法迈过的,那应该做得就是记录、孵化、耐心等待了。
组织形式导致的漏洞,商业形态导致的它们放弃RDMA本身是一件极难实现的事情,毕竟靠着IB躺着赚钱的日子谁会自己革命呀?
当然还有一些可能是通信业的通病数学功底不好,最后来讲一下一个叫半格的代数结构
Semi-Lattic 半格
SRD的Out-Of-Order是表象,其实内部蕴含着一个半格的代数结构.
A commutative idempotent semi-group,然后又来个Partially ordered set,然后很多通信多路径又要Out-Of-Order才能提高吞吐量,其实本源就在如何理解和定义偏序集,放在通信线路上由于多路径的需求,保序带来了极大的压力。那么是不是可以另辟蹊径,放在内存上呢?前文所有的辩证关系都是为了抛出这一点:
首先我们来看内存的分布,其实它就是以内存地址为序列的一个偏序集(Partially ordered set),对内存上进行的操作如果满足可交换(Commutative)、幂等(idempotent)并且满足半群(Semi-Group)中定义的封闭性和结合律。那么这个对内存的操作就是一个半格(Semi-lattice).而简单的内存读写操作是满足幂等的,至于结合律取决于这个操作里的幺元是什么,也就是说是以消息为原子,还是以Byte为原子进行操作,因为内存例如 Write 和 Read之间操作的地址空间有冲突则不满足结合律了,而消息的语义则很好的隔离开了这两者,所以你也就会看到分布式并行程序设计里常见的Actor模型和CSP模型.
所以只要我们对于消息的语义的内存使用作为幺元,然后把内存操作的地址和指令和消息绑定在一起,那么就能够实现Semi-lattice的代数结构了,进而就解决了大规模通信的难题。交换律(Commutative)决定了Out-of-order可以随便用多路径解决拥塞,幂等(idempotent)决定了丢包可以随便重传,结合律(associative)使得多个操作可以代数上merge好了再传远端,并且可以实现Transactional Memory的访问,保证Transaction的原子性。
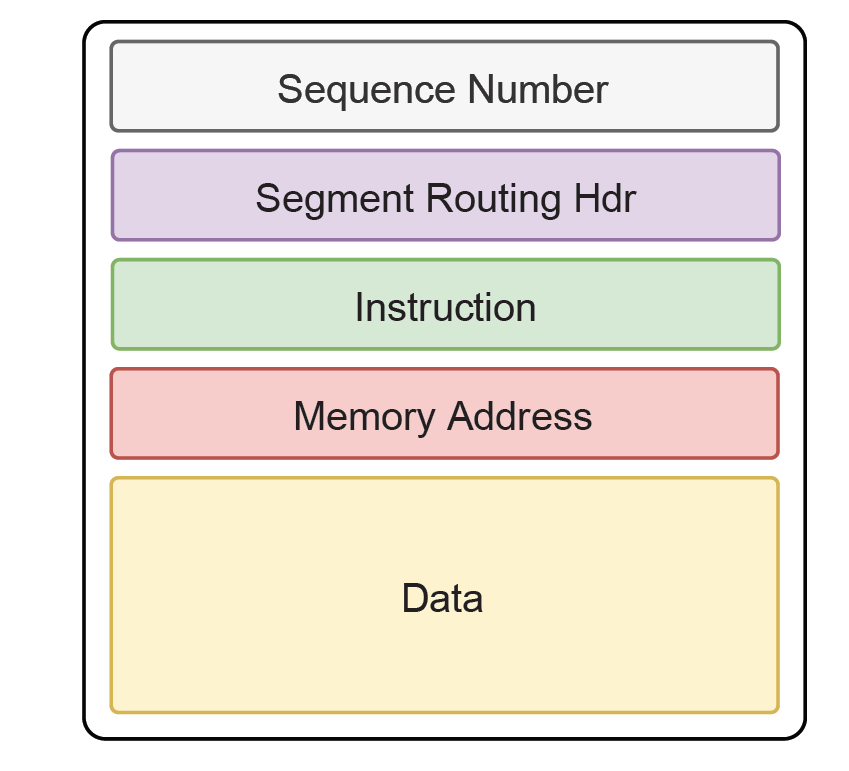
通信方式上引入Semi-Lattice,辩证的看待通信和计算的本源,这一点本质上不亚于当年大数据时代引入的map-reduce,而reduce对算子的要求也是要满足交换律,这是分布式系统提升容量的最关键的地方.
Reference
追求极致性能的巅峰对决 阿里云 vs AWS : https://www.sohu.com/a/496608603_121118998
[2]SRD documentation: https://github.com/amzn/amzn-drivers/blob/master/kernel/linux/efa/SRD.txt
[3]Amazon EFA:anatomy,capabilities and the road ahead: https://www.openfabrics.org/wp-content/uploads/2019-workshop-presentations/205_RRaja.pdf
[4]我理解的创新之路: https://zhuanlan.zhihu.com/p/441253643?utm_source=wechat_timeline&utm_medium=social&utm_oi=32290759507968
