




一、DDP介绍
首先单机多卡训练有如下几种方式:
DataParallel:实现简单方便,batch单进程控制多 GPU,但是只能用于单机,而且训练时间长。
DistributedDataParallel(DDP):多进程控制多 GPU,一起训练模型,能大幅度降低训练时间,也可以用于多级多卡。
Horovod:是Uber开源的跨平台的分布式训练工具,主要是环境不好配,也能大幅度降低训练耗时(和DDP差不多)。
综上所述,本文主要讲解DDP来实现单机多卡的训练任务。
二、相关概念说明
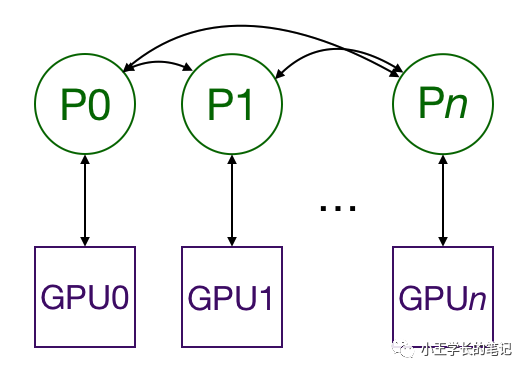
rank、local_rank、node等的概念
rank:用于表示进程的编号/序号(在一些结构图中rank指的是软节点,rank可以看成一个计算单位),每一个进程对应了一个rank的进程,整个分布式由许多rank完成。
node:物理节点,可以是一台机器也可以是一个容器,节点内部可以有多个GPU。
rank与local_rank:rank是指在整个分布式任务中进程的序号;local_rank是指在一个node上进程的相对序号,local_rank在node之间相互独立。
nnodes、node_rank与nproc_per_node:nnodes是指物理节点数量,node_rank是物理节点的序号;nproc_per_node是指每个物理节点上面进程的数量。
word size :全局(一个分布式任务)中,rank的数量。
三、两种实现方式
1、本地实现单机多卡训练代码
# main.py
import torch
import argparse
import torch.distributed as dist
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
args = parser.parse_args()
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)
train_dataset = ...
#每个进程一个sampler
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
在使用时,调用 torch.distributed.launch 启动器启动:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
2、基于slurm GPU集群上实现单机多卡训练代码
# 第二种 torch.nn.parallel.DistributedDataParallel(module, device_ids=None,output_device=None) 参数很多,我这里只给出了三个主要的参数# 方法介绍local_rank = torch.distributed.get_rank() # 返回当前进程组的排名,rank是分布式进程组中每个进程的唯一id。torch.cuda.set_device(i) # 配置i进程的GPUos.environ['SLURM_NTASKS'] #可用作world sizeos.environ['SLURM_NODEID'] #node idos.environ['SLURM_PROCID'] #可用作全局rankos.environ['SLURM_LOCALID'] #local_rankos.environ['SLURM_STEP_NODELIST'] #从中取得一个ip作为通讯ip#------------------------------------ start ------------------------------------------# 首先,初始化import osfrom torch.utils.data import Dataset, DataLoaderfrom torch.utils.data.distributed import DistributedSamplerfrom torch.nn.parallel import DistributedDataParalleltorch.multiprocessing.set_start_method('spawn')rank = int(os.environ['SLURM_PROCID'])local_rank = int(os.environ['SLURM_LOCALID'])world_size = int(os.environ['SLURM_NTASKS'])ip = get_ip(os.environ['SLURM_STEP_NODELIST']) # 确保所有任务的获取的ip一致 (自己实现)host_addr = 'tcp://' + ip + ':' + str(port) # 主机的ip地址和端口号 (自己配置到ip和端口)torch.distributed.init_process_group(backend="nccl", init_method=host_addr, rank=rank, world_size=world_size) # 注:这里的backend表示通信后端,非常多,如NCCL、MPI、Gloo,最快的应该还是ncclnum_gpus = torch.cuda.device_count()torch.cuda.set_device(local_rank)assert torch.distributed.is_initialized()device = torch.device('cuda',local_rank) # 配置GPU设备# 获取数据和采样器dataset = your_dataset()datasampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)dataloader = DataLoader(dataset, batch_size=batch_size_per_gpu, sampler=source_sampler)# 配置模型model = your_model() #也是按自己的模型写model.to(device) # 先把模型放到当前进程的GPU中去model = DistributedDataPrallel(model, device_ids=[local_rank], output_device=local_rank)if num_gpus >1: model = torch.nn.parallel.DistributedDataParallel(model,device_ids=[local_rank],output_device=local_rank) # 再将模型分发到其他各个GPU
在使用时,调用slurm 命令启动:
# 此后训练就应该与之前的无异了# 运行时输入以下指令,这里这么设置,是为了让os.environ获取到相应的信息srun -n 8 --gres=gpu:4 --ntasks-per-node=4 python train.py # 单机多卡,一台机子,共4张GPUsrun -n 12 --gres=gpu:4 --ntasks-per-node=4 python train.py # 多级多卡,3台设备,每台4张GPU

微信号 | sagewang666
微信公众号 | 小王学长的笔记
文章转载自小王学长的笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
