




cluster-require-full-coverage配置大家还记得这个?
默认为yes:集群中的16384个槽全部可用时集群才可用,来保证集群的完整性,如果节点故障或者故障正在转移去操作集群会出现(error)CLUSTERDOWN The cluster is down无法操作集群,在大多数的业务下这样是不行的,建议这里设置为no。
二、带宽消耗
如果我们的Redis集群太大Redis节点之间是需要相互通信来确定数据和状态,节点多会造成带宽的压力,Redis官方建议我们一个Redis集群不要超过1000台。
有的朋友可能就会疑问,那如果我项目中业务很多,1000个节点不够用怎么办?就需要一个大集群来做,这个时候我们可以搭建多个Redis集群,分业务搭建Redis集群来解决这个问题。
三、发布订阅问题
我们知道Redis可以用来做消息队列,可以发布和订阅消息,如果我们使用集群再发布消息时该集群中所有的节点都会收到这个消息,如果你需要发布和订阅消息可以单独使用sentinel来实现,下边我们演示一个集群模式下发布订阅。

四、数据倾斜
数据倾斜是大数据中一个重要的问题,我们有多台节点来存储数据,但是数据存储不均匀,有的节点数据多,有的节点数据少,Redis发生数据倾斜主要有以下几个原因。
4.1、槽分配不均匀
Redis槽一共有16384个,如果有一个节点上分配了1000个槽,那么这个节点上的数据肯定是多余其他节点的,我们在搭建集群时第一种原生搭建方式是我们自己分配的槽,这个大家自己平均分配一下就可以避免这种情况,第二种快速搭建方式,Redis会自己帮我们平均分配槽到各个节点上,所以这个问题一般不会出现。
redis-cli --cluster info 192.168.11.101:8000 命令查看槽分配情况

redis-cli -a cc --cluster rebalance 192.168.11.101:8000平均槽,不建议使用,这里我没有运行,就没有截图了
4.2、不同槽对应的键值数量较大
我们的槽分配的比较均匀,但是可能有些槽数据比较多我,我们Redis根据CRC16算法计算key来分配槽,一般不会出现这种情况,可以通过cluster countkeysinslot {slotnumber}命令来查看对应槽的数据量
4.3、内存相关配置不一致
比如hash-max-ziplist-value、set-max-inset-entries等配置不一样,这样也可能导致不均匀,我们保证配置一样即可。这些配置是Redis采用哪种数据结构存储数据的配置,可以参考《Redis数据结构》
hash-max-ziplist-entries512 表示当hash项(field,value)数>512即ziplist项>1024的时候转为dict
hash-max-ziplist-value 64 表示当hash中的value长度超过64的时候转为dict。
ziplist是一个经过特殊编码的双向链表,提高存储效率,这个数据结构我们不在这里细说。
4.4、请求倾斜
我们熟知的新浪微博等,他们的很多数据就是缓存在Redis中的,如果有一些大V在特殊的节日发布了一些信息,那么这些数据会落到一个key上,请求这个热点key的频率是很高的。这个时候我们的热键就不要使用hash_tag了,至于什么是hash_tag不明白的朋友可以百度一下,说白了就是允许用key的部分字符串来计算hash,将key落在同一个节点上。当一个key包含 {} 的时候,就不对整个key做hash,而仅对 {} 包括的字符串做hash,例如:user:{user1}:id和user:{user1}:name两个key只对user1做hash那么他们的hash值是一样的!
4.5、RedisCluster读写分离
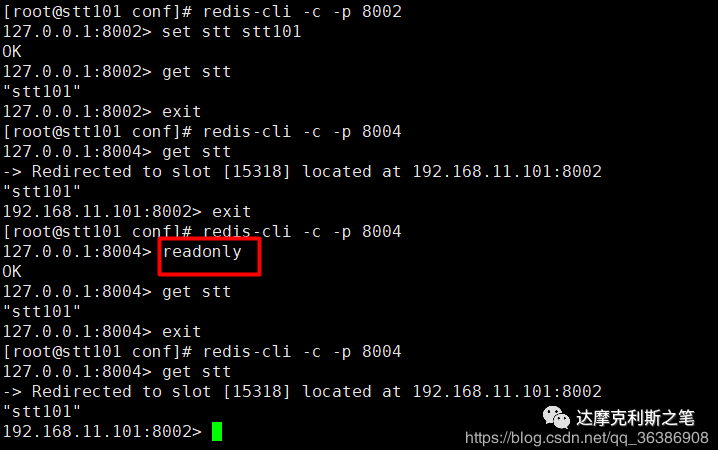
我们这里Redis集群默认的slave节点是不可能读写的,读写操作都会跳转到slave节点对应的主节点上去做,下图大家可以看出,8002为主节点,8004是8002的从节点,如果我们要从节点可以读数据则需要输入readonly命令,而且每次进来都需要输入是很麻烦的。我们并不建议使用Redis Cluster的读写分离操作,比较麻烦
五、Redis Cluster和单机版对比
5.1、集群的限制
key的批量操作支持有限,例如mget、mset等都必须在同一个slot中
key事务和Lua支持有限,操作的key必须在同一个节点上
数据分区只支持key不支持bigkey
不支持多个数据库,在集群模式下只有0号库
不支持树形结构复制
5.2、总结
总的来说不要为了追时髦去使用Redis Cluster,它虽然可以解决我们Redis的容量问题,但是在很多业务下是不需要的,其实很多场景我们使用Redis Sentinel就已经很好了。所以大家还是要看具体的业务场景,是否真的需要使用Redis Cluster。
六、Redis优化
6.1、Key设计
1、可读性和可管理性
以业务名(或数据库名)为前缀,防止key冲突,用冒号分割,比如业务名:表名:id,如:ugc:order:1
2、简洁性
保证语义的前提下,控制key的长度,当key较多时,内存占用也不容忽视。比如user:{id}:friends:message:{mid}可以简化为u:{uid}:f:msg:{mid}
3、不要包含特殊字符
反例:包含空格、换行、单双引号及其他转移字符
6.2、value设计
1、拒绝bigKey
保证string类型控制在10KB之内,hash、list、set、zset元素个数不要超过5000,比如一个包含了几百万个元素的list、hash等;一个巨大的json字符串是不建议使用的
会造成网络阻塞,集群节点数据不均匀,频繁序列化:应用服务器CPU消耗等
我们可以通过应用异常,redis-cli --bigkeys命令,网络流量监控等方案发现bigkey,使用设置过期时间来删除
2、过期设计
周期数据需要设置过期时间,但是过期时间不要集中,可能会引起缓存穿透和雪崩问题
求知并无捷径,如果有,那就是放弃这个幼稚的想法,静下心来多读书、总结
