




我们在资源调度的文章中提到过,Spark在初始化driver和executor的SparkEnv的时候,构建了多个作业运行时的管理器,包括ShuffleManager、BroadcastManager、BlockManager、SerializerManager、MemoryManager等,本文将具体介绍内存管理器MemoryManager是如何管理Spark内存资源的,以及基于Tungsten钨丝计划的内存管理机制。
统一内存管理
内存管理器MemoryManager作为抽象类有StaticMemoryManager静态内存管理和UnifiedMemoryManager统一内存管理两种实现,静态内存管理器是初始的实现方式,从Spark1.6版本开始默认采用统一内存管理器来管理Spark的内存资源。
统一内存管理对比静态内存管理最重要的改进是支持执行内存和存储内存之间的动态抢占,从而提升了内存使用率;同时,内存管理器还可以统一管理堆内内存和堆外内存,当配置了spark.memory.offHeap.enabled=true和spark.memory.offHeap.size参数时则可以使用堆外内存。采用堆外内存Spark可以精确地在系统内存中申请和释放空间,但是对比由JVM来统一管理内存对象的申请和回收,采用堆外内存也增加了Spark内存管理的复杂度。
内存资源池
在统一内存管理器中,将存储内存和执行内存划分为不同的内存池MemoryPool来对内存进行管理,并且可以对内存资源池进行扩缩容。在MemoryManager的构造方法中创建了4个内MemoryPool: onHeapStorageMemoryPool堆内存储内存池、offHeapStorageMemoryPool堆外存储内存池、onHeapExecutionMemoryPool堆内执行内存池和offHeapExecutionMemoryPool堆外执行内存池:
@GuardedBy("this")
protected val onHeapStorageMemoryPool = new StorageMemoryPool(this, MemoryMode.ON_HEAP)
@GuardedBy("this")
protected val offHeapStorageMemoryPool = new StorageMemoryPool(this, MemoryMode.OFF_HEAP)
@GuardedBy("this")
protected val onHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.ON_HEAP)
@GuardedBy("this")
protected val offHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.OFF_HEAP)
内存池通过incrementPoolSize和decrementPoolSize方法维护各类内存空间的大小。其中,初始的堆内存储内存和堆内执行内存的大小为:( spark.executor.memory - RESERVED_SYSTEM_MEMORY_BYTES(默认300M))* spark.memory.fraction(默认0.6) /2;初始的堆外存储内存和堆外执行内存的大小为:spark.memory.offHeap.size /2;
堆内内存分布图:
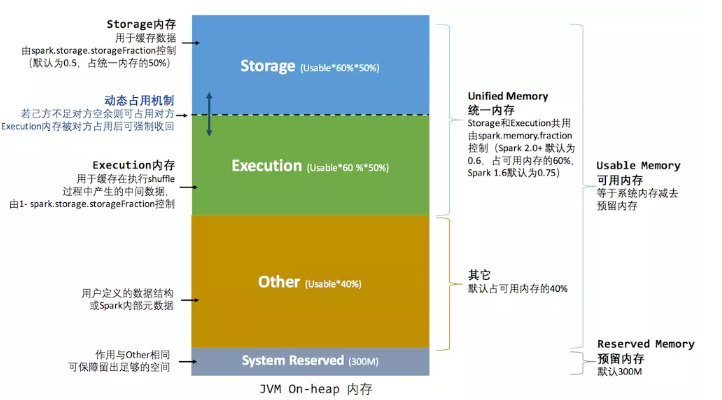
堆外内存分布图:
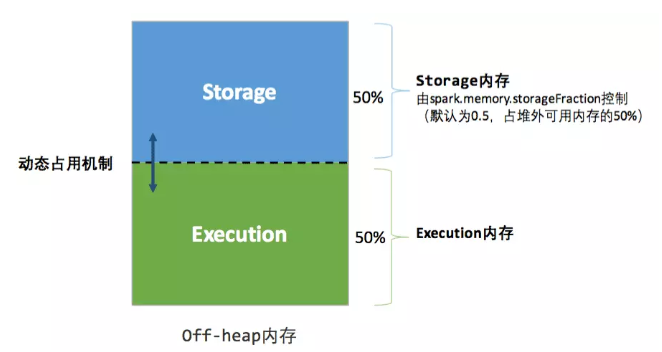
相关的代码逻辑如下:
onHeapStorageMemoryPool.incrementPoolSize(onHeapStorageMemory)
onHeapExecutionMemoryPool.incrementPoolSize(onHeapExecutionMemory)
protected[this] val maxOffHeapMemory = conf.get(MEMORY_OFFHEAP_SIZE)
protected[this] val offHeapStorageMemory =
(maxOffHeapMemory * conf.get(MEMORY_STORAGE_FRACTION)).toLong
offHeapExecutionMemoryPool.incrementPoolSize(maxOffHeapMemory - offHeapStorageMemory)
offHeapStorageMemoryPool.incrementPoolSize(offHeapStorageMemory)
申请执行内存
执行内存是Spark作业在执行计算操作(包括shuffles、joins、sorts和aggregations等操作)时所需的内存空间。
当需要申请执行内存时,首先由TaskMemoryManager调用UnifiedMemoryManager的acquireExecutionMemory 方法来申请指定大小的执行内存,并通过UnifiedMemoryManager调用执行内存池ExecutionMemoryPool的acquireMemory方法来实现执行内存池的扩容:
1、根据所需申请的执行内存大小和当前执行内存池中所剩余的空间来判断是否需要扩展执行内存池;
2、如果需要则获取当前存储内存池的空闲空间和存储内存池抢占执行内存池的空间的大小,选择两者的最大值作为执行内存最多可以从存储内存中获取的内存空间;
3、如果所需申请的内存大小小于第2步中获取的存储内存池可以让出的最大内存空间,则存储内存池会出让所需要申请的空间给执行内存;否则,存储内存池需要让出最大可缩小的内存空间给执行内存,从而实现执行内存池的扩容:
if (extraMemoryNeeded > 0) {
// There is not enough free memory in the execution pool, so try to reclaim memory from
// storage. We can reclaim any free memory from the storage pool. If the storage pool
// has grown to become larger than `storageRegionSize`, we can evict blocks and reclaim
// the memory that storage has borrowed from execution.
val memoryReclaimableFromStorage = math.max(
storagePool.memoryFree,
storagePool.poolSize - storageRegionSize)
if (memoryReclaimableFromStorage > 0) {
// Only reclaim as much space as is necessary and available:
val spaceToReclaim = storagePool.freeSpaceToShrinkPool(
math.min(extraMemoryNeeded, memoryReclaimableFromStorage))
storagePool.decrementPoolSize(spaceToReclaim)
executionPool.incrementPoolSize(spaceToReclaim)
}
}
由上面的策略也可以看出,虽然存储内存可以抢占执行内存的空间,但是当执行内存不足的时候则存储内存需要及时地归还所借用的空间。
4、计算当前实际可申请到的内存,取当前执行内存所剩余空间和所申请空间值的最小值:
val maxToGrant = math.min(numBytes, math.max(0, maxMemoryPerTask - curMem))
val toGrant = math.min(maxToGrant, memoryFree)
5、根据第4步得到当前实际可申请到的执行内存,如果当前该task可获取的内存小于一个task的最小执行内存(执行内存池大小/2N,N为当前的task数),则继续等待下次分配;否则为该task分配内存,并更新哈希列表memoryForTask中该task的内存使用量:
if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName pool to be free")
lock.wait()
} else {
memoryForTask(taskAttemptId) += toGrant
return toGrant
}
申请存储内存
存储内存用于存储broadcast广播变量以及通过persist或者cache产生的缓存数据,是由TaskMemoryManager调用UnifiedMemoryManager的acquireStorageMemory方法来进行申请的,主要的处理逻辑如下:
1、判断当前存储内存池所剩余的空间如果小于所需申请的内存,首先尝试从执行内存抢占一部分空间来扩容存储内存:
if (numBytes > storagePool.memoryFree) {
// There is not enough free memory in the storage pool, so try to borrow free memory from
// the execution pool.
val memoryBorrowedFromExecution = Math.min(executionPool.memoryFree,
numBytes - storagePool.memoryFree)
executionPool.decrementPoolSize(memoryBorrowedFromExecution)
storagePool.incrementPoolSize(memoryBorrowedFromExecution)
}
和申请执行内存不同的是,可抢占的空间memoryBorrowedFromExecution受制于执行内存所剩余的空间,如果执行内存没有剩余空间,则无法从执行内存池抢占;由此可见,执行内存的优先级高于存储内存。
2、如果尝试扩容后的存储内存空间小于所需要申请的内存,则从当前存储内存中驱逐部分缓存:
if (numBytesToFree > 0) {
memoryStore.evictBlocksToFreeSpace(Some(blockId), numBytesToFree, memoryMode)
}
3、经过第2步的内存驱逐过程,如果当前的存储内存池可以满足内存申请需求,则申请成功,否则申请失败:
val enoughMemory = numBytesToAcquire <= memoryFree
if (enoughMemory) {
_memoryUsed += numBytesToAcquire
}
基于Tungsten钨丝计划的内存管理
钨丝计划是由Databricks公司提出的以大幅度提升Spark应用程序的内存和CPU利用率为目标的项目,旨在最大程度上压榨新时代硬件性能。在内存优化方面,采用内存页的方式来组织内存存储,将数据以二进制字节数组的方式存储在内存页中,并通过sun.misc.Unsafe的API直接操作内存中的数据,从而大大减少了内存对象的创建,提升了内存使用率,也减轻了JVM内存管理的压力。
在Tungsten机制中采用MemoryBlock表示一个内存页,MemoryBlock继承自MemoryLocation类,具有obj、offset、length属性:
public MemoryBlock(@Nullable Object obj, long offset, long length) {
super(obj, offset);
this.length = length;
}
当tungstenMemoryMode为ON-HEAP模式时,数据作为对象存储在JVM的堆上,obj代表内存页中存储数据的二进制数组的引用;当tungstenMemoryMode为为OFF_HEAP模式时,直接操作系统内存,未创建二进制数组,obj为null,通过offset来表示内存页的地址;length属性表示申请到的内存页的大小。
根据tungsten内存模式的不同,在Spark中分别通过HeapMemoryAllocator和UnsafeMemoryAllocator来加载内存页:
1、通过HeapMemoryAllocator加载堆内内存页
在堆内内存页中通过一个long[]类型的数组array来存储数据,这样在JVM内存中就只需要创建少量的array对象即可,shuffle记录则采用二进制字节的方式写入到array数组中,而不再是创建一个个java对象,缓解了JVM的内存压力:
MemoryBlock memory = new MemoryBlock(array, Platform.LONG_ARRAY_OFFSET, size);
if (MemoryAllocator.MEMORY_DEBUG_FILL_ENABLED) {
memory.fill(MemoryAllocator.MEMORY_DEBUG_FILL_CLEAN_VALUE);
}
2、通过UnsafeMemoryAllocator加载堆外内存页
堆外的内存页构建则是直接在系统内存中开辟一块特定大小的内存空间:
@Override
public MemoryBlock allocate(long size) throws OutOfMemoryError {
long address = Platform.allocateMemory(size);
MemoryBlock memory = new MemoryBlock(null, address, size);
if (MemoryAllocator.MEMORY_DEBUG_FILL_ENABLED) {
memory.fill(MemoryAllocator.MEMORY_DEBUG_FILL_CLEAN_VALUE);
}
return memory;
}
下面我们以tungsten在Spark中的实际应用场景为例来阐述基于Tungsten的内存申请和使用机制。
Tungsten在UnsafeShuffleWriter中的应用
在前一篇文章中我们详细阐述了SortShuffleWriter在shuffle map阶段将shuffle记录写入内存,当内存空间无法扩容后溢写到磁盘文件中的过程;而采用UnsafeShuffleWriter的情况下也是类似的过程,只是用于执行shuffle的内存是通过Tungsten机制来管理的。
申请内存页
我们知道,ShuffleWriter在排序和聚合内存空间不足时会尝试扩容内存空间, 在采用SortShuffleWriter的情况下扩容内存尝试扩大执行内存池的大小,而采用UnsafeShuffleWriter的情况下使用到了tungsten的内存管理机制,首先判断当前内存页的空间是否足够,如果当前页的空间不足则尝试通过前面讲到的MemoryManager扩容执行内存池,然后通过调用MemoryAllocator的allocate方法来申请新的内存页,并将新申请的内存页登记到内存页表中:
public MemoryBlock allocatePage(long size, MemoryConsumer consumer) {
...
//通过MemoryManager扩容执行内存池
long acquired = acquireExecutionMemory(size, consumer);
if (acquired <= 0) {
return null;
}
final int pageNumber;
synchronized (this) {
pageNumber = allocatedPages.nextClearBit(0);
if (pageNumber >= PAGE_TABLE_SIZE) {
releaseExecutionMemory(acquired, consumer);
throw new IllegalStateException(
"Have already allocated a maximum of " + PAGE_TABLE_SIZE + " pages");
}
allocatedPages.set(pageNumber); //登记该task所有的内存页id
}
MemoryBlock page = null;
try {
//通过MemoryAllocator加载新的内存页
page = memoryManager.tungstenMemoryAllocator().allocate(acquired);
} catch (OutOfMemoryError e) {
...
page.pageNumber = pageNumber;
//记录所有内存页表的地址,可以根据记录的内存地址调用getPage方法获取内存页
pageTable[pageNumber] = page;
if (logger.isTraceEnabled()) {
logger.trace("Allocate page number {} ({} bytes)", pageNumber, acquired);
}
return page;
}
写入shuffle记录
UnsafeShuffleWriter通过ShuffleExternalSorter的insertRecord方法将序列化后shuffle记录先写到内存页中,首先获取该数据记录所需占用的空间,如果当前内存页空间不足则申请新的内存页;接下来通过sun.misc.Unsafe API将shuffle数据记录写到内存页中;然后将该记录在内存页中的起始地址、偏移量以及partitionId编码成一个组合地址存放在ShuffleInMemorySorter的LongArray数组中:
public void insertRecord(Object recordBase, long recordOffset, int length, int partitionId)
throws IOException {
...
// Need 4 or 8 bytes to store the record length.
final int required = length + uaoSize;
acquireNewPageIfNecessary(required);
assert(currentPage != null);
final Object base = currentPage.getBaseObject();
final long recordAddress = taskMemoryManager.encodePageNumberAndOffset(currentPage, pageCursor);
UnsafeAlignedOffset.putSize(base, pageCursor, length);
pageCursor += uaoSize;
Platform.copyMemory(recordBase, recordOffset, base, pageCursor, length);
pageCursor += length;
inMemSorter.insertRecord(recordAddress, partitionId);
LongArray数组其实是在内存中开辟的一块初始大小为 spark.shuffle.sort.initialBufferSize(默认4096)的内存页,用于存放缓存在内存中的shuffle记录的地址信息;该数组的容量会随着shuffle记录数的增加而扩展,然而在内存空间不足而无法扩展的时候就会将缓存中的记录溢写到磁盘文件中:
private void growPointerArrayIfNecessary() throws IOException {
assert(inMemSorter != null);
if (!inMemSorter.hasSpaceForAnotherRecord()) {
long used = inMemSorter.getMemoryUsage();
LongArray array;
try {
// could trigger spilling
array = allocateArray(used / 8 * 2);
} catch (TooLargePageException e) {
// The pointer array is too big to fix in a single page, spill.
spill();
其中,每个数据记录的地址占用8个字节,编码方式为前24位存放patitionId,中间的13位存放pageNumber,剩下的27位存放页内的地址,可见每个task最多可以获取2^13个内存页,每个内存页最大为2^27=128MB:
final long pageNumber = (recordPointer & MASK_LONG_UPPER_13_BITS) >>> 24;
final long compressedAddress = pageNumber | (recordPointer & MASK_LONG_LOWER_27_BITS);
return (((long) partitionId) << 40) | compressedAddress;
将内存数据溢写到磁盘:
UnsafeShuffleWriter在将数据写入到内存缓冲区的过程中,如果缓冲区中写入的记录达到阈值上限spark.shuffle.spill.numElementsForceSpillThreshold后也会将数据溢写到磁盘中:
if (inMemSorter.numRecords() >= numElementsForSpillThreshold) {
logger.info("Spilling data because number of spilledRecords crossed the threshold " +
numElementsForSpillThreshold);
spill();
}
spill方法通过writeSortedFile方法将内存缓存的shuffle记录溢写到磁盘中,首先根据LongArray中的记录地址信息,解析partitionId将待溢写的记录根据partitionId排序;然后遍历所有排序后的记录,并在spillInfo.partitionLengths数组中登记各个partition的记录的数量;最后根据记录在内存页的起始地址和偏移量获取具体的数据记录,并将其写到输出缓冲区中:
//将待溢写的数据在内存中排序
final ShuffleInMemorySorter.ShuffleSorterIterator sortedRecords =
inMemSorter.getSortedIterator();
...
while (sortedRecords.hasNext()) {
sortedRecords.loadNext(); //逐条获取记录
final int partition = sortedRecords.packedRecordPointer.getPartitionId();
assert (partition >= currentPartition);
if (partition != currentPartition) {
// Switch to the new partition
if (currentPartition != -1) {
final FileSegment fileSegment = writer.commitAndGet();
spillInfo.partitionLengths[currentPartition] = fileSegment.length(); //记录各个分区的长度
}
currentPartition = partition;
}
final long recordPointer = sortedRecords.packedRecordPointer.getRecordPointer();
final Object recordPage = taskMemoryManager.getPage(recordPointer); //从页表中获取内存页
final long recordOffsetInPage = taskMemoryManager.getOffsetInPage(recordPointer); //获取记录的页内偏移量
int dataRemaining = UnsafeAlignedOffset.getSize(recordPage, recordOffsetInPage);//记录的长度
long recordReadPosition = recordOffsetInPage + uaoSize;
while (dataRemaining > 0) {
final int toTransfer = Math.min(diskWriteBufferSize, dataRemaining);
//将待溢写的数据写道输出缓冲区中
Platform.copyMemory(
recordPage, recordReadPosition, writeBuffer, Platform.BYTE_ARRAY_OFFSET, toTransfer);
writer.write(writeBuffer, 0, toTransfer);
recordReadPosition += toTransfer;
dataRemaining -= toTransfer;
}
writer.recordWritten();
}
内存中的数据写入到磁盘文件之后,在spill方法中调用freeMemory()方法释放内存缓存中的内存页所占用的空间:
private long freeMemory() {
updatePeakMemoryUsed();
long memoryFreed = 0;
for (MemoryBlock block : allocatedPages) {
memoryFreed += block.size();
freePage(block);
}
allocatedPages.clear();
Tungsten在HashJoin中的优化应用
在SparkSQL中当发生broadcast hash join以及Shuffle hash join的情况下,分别会将小表的全量数据或者分区数据在内存中构建一个hashmap,用于实现快速的数据查找,这个hashmap在tungsten机制中是通过BytesToBytesMap实现的。
在SparkSQL的物理计划中,ShuffledHashJoinExec和BroadcastExchangeExec节点通过UnsafeHashedRelation来表示待处理的数据源,而UnsafeHashedRelation就是通过将数据源的所有InternalRow写入到BytesToBytesMap来构建的:
private[joins] object UnsafeHashedRelation {
def apply(
input: Iterator[InternalRow],
key: Seq[Expression],
sizeEstimate: Int,
taskMemoryManager: TaskMemoryManager,
isNullAware: Boolean = false,
allowsNullKey: Boolean = false): HashedRelation = {
...
val pageSizeBytes = Option(SparkEnv.get).map(_.memoryManager.pageSizeBytes)
.getOrElse(new SparkConf().get(BUFFER_PAGESIZE).getOrElse(16L * 1024 * 1024))
val binaryMap = new BytesToBytesMap(
taskMemoryManager,
// Only 70% of the slots can be used before growing, more capacity help to reduce collision
(sizeEstimate * 1.5 + 1).toInt,
pageSizeBytes)
// Create a mapping of buildKeys -> rows
val keyGenerator = UnsafeProjection.create(key)
var numFields = 0
while (input.hasNext) {
val row = input.next().asInstanceOf[UnsafeRow]
numFields = row.numFields()
val key = keyGenerator(row)
if (!key.anyNull || allowsNullKey) {
val loc = binaryMap.lookup(key.getBaseObject, key.getBaseOffset, key.getSizeInBytes)
val success = loc.append(
key.getBaseObject, key.getBaseOffset, key.getSizeInBytes,
row.getBaseObject, row.getBaseOffset, row.getSizeInBytes)
...
}
new UnsafeHashedRelation(key.size, numFields, binaryMap)
}
}
BytesToBytesMap通过一个登记数据存储地址和hashcode的longArray,以及对应页表的集合结构LinkedList
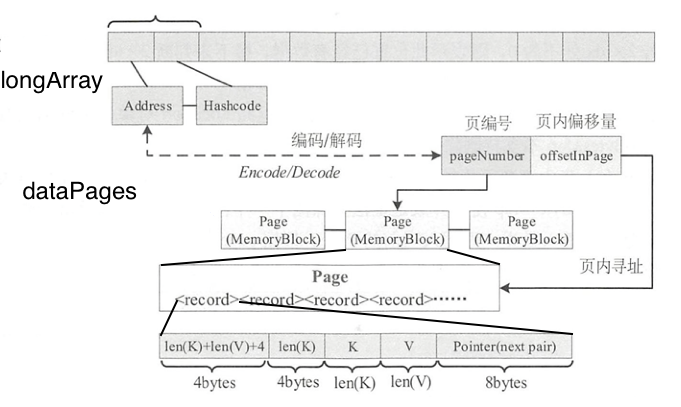
接下来介绍一下向BytesToBytesMap插入数据的主要过程:
1、首先计算记录占用的空间大小,如果当前页空间不足则申请一个新的内存页(申请内存页的过程在前面已经介绍过,此处不再赘述):
final long recordLength = (2L * uaoSize) + klen + vlen + 8;
if (currentPage == null || currentPage.size() - pageCursor < recordLength) {
if (!acquireNewPage(recordLength + uaoSize)) {
return false;
}
}
2、根据记录在内存页中的组织形式,将该记录的长度、key的长度、key和value等信息通过Unsafe API写到内存页中:
final Object base = currentPage.getBaseObject();
long offset = currentPage.getBaseOffset() + pageCursor;
final long recordOffset = offset;
UnsafeAlignedOffset.putSize(base, offset, klen + vlen + uaoSize);
UnsafeAlignedOffset.putSize(base, offset + uaoSize, klen);
offset += (2L * uaoSize);
Platform.copyMemory(kbase, koff, base, offset, klen);
offset += klen;
Platform.copyMemory(vbase, voff, base, offset, vlen);
offset += vlen;
// put this value at the beginning of the list
Platform.putLong(base, offset, isDefined ? longArray.get(pos * 2) : 0);
3、更新当前页表的偏移量:
pageCursor += recordLength;
4、在longArray登记新增的记录的信息:
首先根据内存页的起始地址和新增记录在内存页中的偏移量得到该记录在内存中的存储地址,并将该地址作为longArray下标pos*2的值;然后将记录的哈希值作为longArraypos * 2 + 1下标的值,用于实现新增记录的寻址:
final long storedKeyAddress = taskMemoryManager.encodePageNumberAndOffset(
currentPage, recordOffset);
longArray.set(pos * 2, storedKeyAddress);
updateAddressesAndSizes(storedKeyAddress);
numValues++;
if (!isDefined) {
numKeys++;
longArray.set(pos * 2 + 1, keyHashcode);
...
总结
通过本文的介绍,我们主要了解到如下内容:
1、Spark通过统一内存管理机制实现了执行内存和存储内存之间的互相抢占,从而提高了内存使用效率;同时,执行内存的优先级高于存储内存,当执行内存不足的时候,存储内存池需要最大限度的归还所抢占内存空间;而当存储内存空间不足的情况下,存储内存通过驱逐部分数据记录来获取内存,如果此时存储内存池的空间仍然不足则需要等待执行内存释放出内存后才能继续扩容存储内存池的空间;
2、在部分内存消耗较高的场景,例如unsafe shufflewrite以及shuffleHashJoin等,Spark引入了Tungsten内存管理机制,将数据对象序列为字节数组并存放在内存页中,这样不仅可以节约内存空间,也大量减少了对象的创建,从而极大缓解了JVM对象管理的压力,有效地提升了Spark的处理性能。
作者简介
焦媛,主要负责民生银行Hadoop大数据平台的生产运维工作,并负责HDFS和Spark相关开源产品的技术支持,以及Spark云原生技术的支持和推广工作。
