





点击上方蓝字关注我们

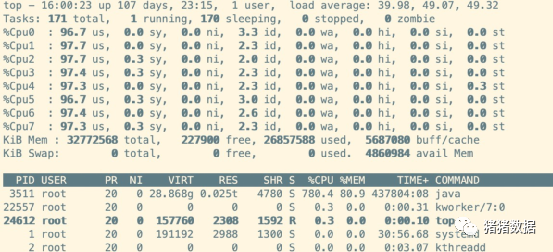
大家好 ,我是猪猪。最近遇到一个问题,图数据库对应的服务器总是报 Processor load is too high,【如下图所示】,cpu和内存都使用过高。
由于我们图数据库使用的是社区版本neo4j,单节点部署,我们现在唯一解决办法就是增加机器配置,遇到问题都比较慌,没有备份的机器可用。我们业务存储上万学生对应海量K12阶段全部知识点的掌握度,实时更新和写入学生对知识点的掌握度,还有海量查询第三级知识点,业务上直接提供给推荐系统使用。业务如此重要,所以,我们一直想寻找一个分布式的图数据库,能满足我们业务需求,但是我们又不想花钱用商业版本,于是我们开启图数据库的选型工作。


2. 我们希望
这个图数据库具备以下几个能力
2.1.分布式,支持横向扩展,高可用
2.2.开源项目,不收费
2.3.社区人员活跃,交流频繁,相互解决问题
2.4.可以支持hive导批量数据到图数据库
2.5.支持flink/spark实时写入数据
3.1 DB-Engines网站上看看
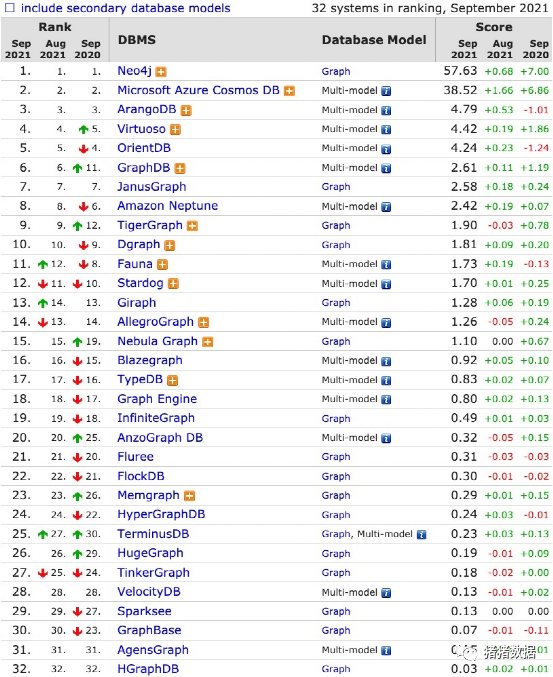
排名前30的图数据库产品,发现多数知名的图数据库开源版本只支持单节点,不能横向扩展存储,无法满足大规模图谱数据的存储需求,例如:Neo4j、ArangoDB、Virtuoso、TigerGraph、RedisGraph。于是搜罗各个大厂测评的结果,推荐三款:NebulaGraph(原阿里巴巴团队创业开发)、Dgraph(原Google团队创业开发)、HugeGraph(百度团队开发)。
3.2 评测结果
3.2.1 分别 从 三个 方面 进行 评测
a.批量数据导入
b.实时数据写入
c.数据查询
批量数据导入
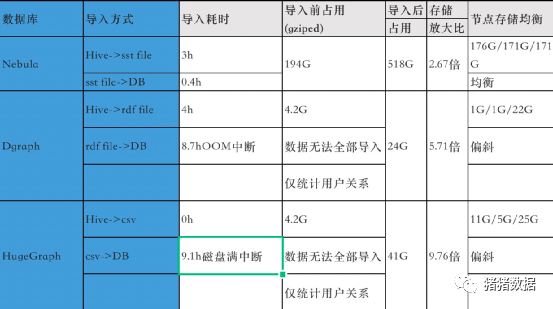
Nebula:数据存储分布方式是主键哈希,各节点存储分布基本均衡。导入速度最快,存储放大比最优。
实时数据写入
Nebula的写入请求可以由多个存储节点分担,因此响应时间和吞吐量均大幅领先。
数据查询
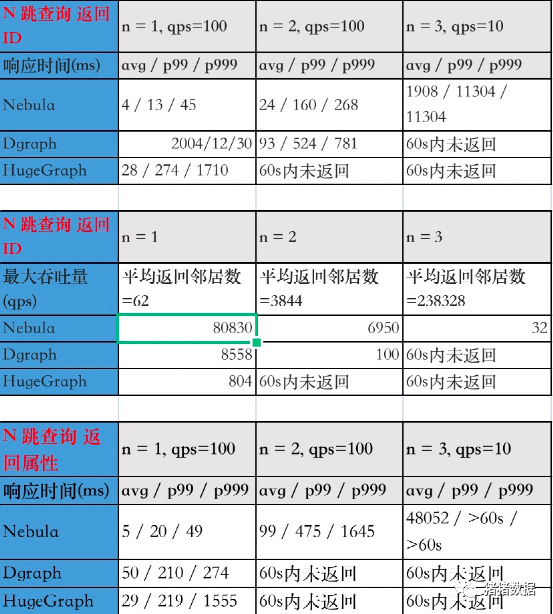
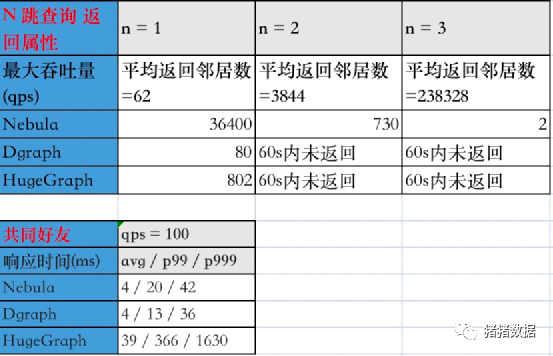
在1跳查询返回ID「最大吞吐量」结果 中,DGraph集群节点的CPU负载主要落在存储关系的单节点上,造成集群CPU利用率低下,因此最大吞吐量仅有Nebula的11%。
在2跳查询返回ID「响应时间」结果 中,DGraph在qps=100时已经接近了集群负载能力上限,因此响应时间大幅变慢,是Nebula的3.9倍。
最终 比较了多款业内主要使用的开源数据库后,从性能,学习成本和与业务的贴合程度多个角度考虑,最终选择了性能出众,上手简单,能大幅提高业务效率的Nebula Graph图数据库。
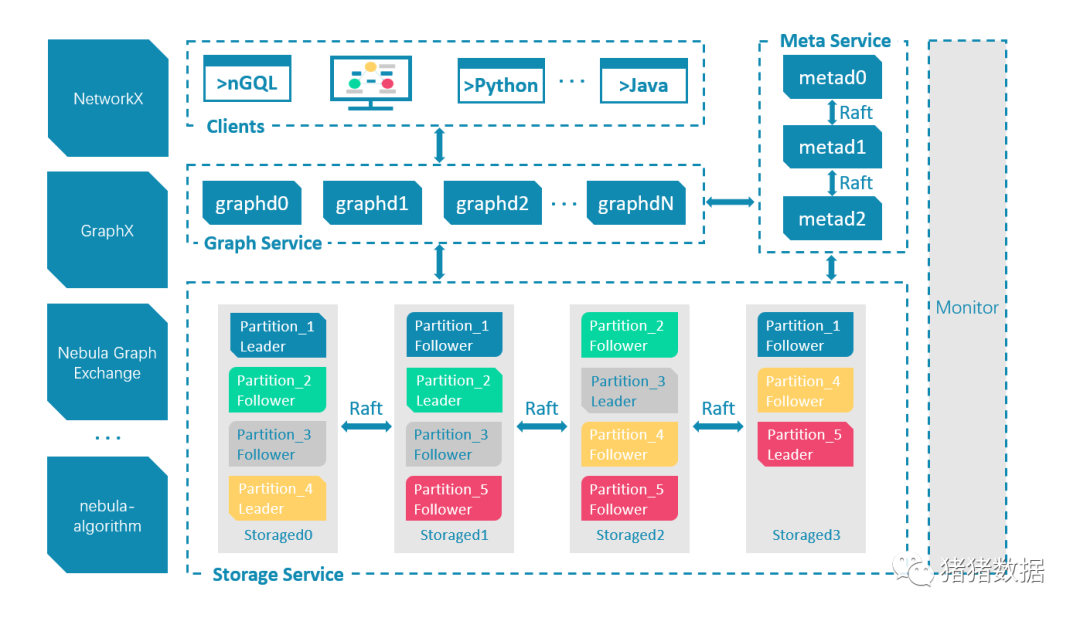
Nebula Graph是一款开源的、分布式的、易扩展的原生图数据库,能够承载数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。Nebula Graph 由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。每个服务都有可执行的二进制文件和对应进程,用户可以使用这些二进制文件在一个或多个计算机上部署 Nebula Graph 集群。如下 架构图 :
Nebula Graph的优势:
4.1 开源,在Apache 2.0条款下开发的
4.2 高性能,可以提供毫秒级查询,数据规模越大,Nebula Graph优势就越大
4.3 易扩展,可以 横向 扩展
4.4 易开发,Nebula Graph提供Java、Python、C++和Go等流行编程语言的客户端
4.5 高可靠访问控制, 支持严格的角色访问控制和LDAP(Lightweight Directory Access Protocol)等外部认证服务
4.6 。。。。
这也是一个国产图数据库,啥话也不说 ,支持一下,准备把生产的neo4j换成nebula-graph,开始自己安装体验一下吧,详细安装步骤:请点击话题“数据平台/图数据库”

点个在看你最好看
