




“ 受苦的人,没有悲观的权利。——尼采”

1、业务需求
文件上传功能在业务系统里面是非常常见的,基本上每个系统都涉及到上传功能,但是如果光实现简单的文件上传是没有什么难度的,我们需要考虑很多文件上传的细节以及性能方面的优化,我们的上传功能需要满足以下需求:
支持文件的秒传,如果文件系统已经存在相同的文件,那么没必要再往后端上传,直接实现秒传功能,提高用户体验同时节约服务器的磁盘资源。
不支持重复上传,如果多个人都上传同一份文件,那么如果文件系统保存多份相同文件的话,浪费了服务器的磁盘资源的。
满足超大文件的上传,大文件上传最常见的就是由于内存溢出等问题导致上传失败,因此我们需要开发一个满足大文件上传的上传功能
为了保护系统,灵活限制单文件最大值
实现效果如下:
2、功能设计
2.1、基本功能分析
在我们拿到需求时,切记不要一上来就开始撸代码,先把需求拆分成多个部分去分析,每个部分的难点是什么,具体的解决方案是什么,尤其是在设计数据库表结构的时候需要考虑是否会出现需求变更,可能变更的点在哪里,等等这些问题搞清楚之后,再来代码的实现,很多时候往往我们思路都不是很清晰的情况下去写业务代码,最坏的结果就是需求变更之后之前写的都得大改,相信做开发的同学都有过类似的经历。
第一: 针对上面的需求,我们会发现其实秒传
和不重复上传
的实现原理应该都是一样的,需要去后台识别该文件是否存在;那么应该如何识别文件是否存在呢?
方案一:通过
文件名称
去数据库查询其是否存在?显然不合适,如果两份文件名称不一样,但是内容一样的情况,那么去数据库查询就会被标识为两个不用的文件,但是对于文件存储系统来说,其实只要保留一份文件就好了。方案二:其实可以通过计算
文件md5
,通过 md5 去数据库查询其是否存在;因为文件名称不一样只要文件内容一样,那么计算的 md5 都是一样的。
第二: 如何才能支持大文件上传呢?文件的上传首先需要把文件转换成流的形式传输到我们的后台系统,后台系统再对其进行处理,如果用户在页面选择一个大文件(比如:10G)上传的话,那么可能会出现两种可能,第一是传输失败;第二是内存溢出。为了避免这个问题的出现,如何设计呢?
第一:可以在前端实现文件的 md5 计算,这样话就可以拿到文件的唯一标识,可以基于 md5 去实现秒传和不重复上传了。
第二:前端实现文件的切块,并且给每个切块标好顺序,然后上传切块;控制好每个切块不要太大,那么对于网络的传输和后台处理起来速度都是很快的,并且处理完成之后 JVM 会自动回收垃圾,不会出现内存溢出的情况。
第三:后台要不要合并切块呢?其实是不要的,如果后台合并切块,那么还是耗费服务器内存;同时下载的时候完整的大文件根本下载不了;所以最好的做法就是切块上传、切块存储、下载的时候按顺序输出切块即可。
第三: 当然,为了保护系统,我们可以控制单个文件的最大值不能超过多少,避免恶意攻击,最好是在上传之前就判断文件大小是否超过设置的阀值。
上传流程图如下所示: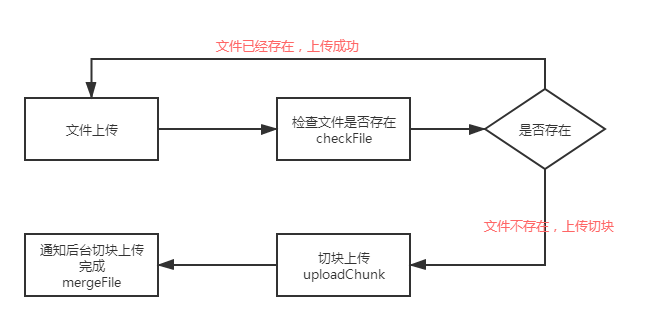
由流程图我们可以清晰的知道,整个上传功能其实是分成三步(三个接口)执行,分别是检查文件是否存在(checkFile)、切块上传(uploadChunk)、切块合并(mergeFile)。checkFile 主要是通过 md5 去校验是否存在,逻辑很简单;重点是切块上传和切块合并两个接口,它的流程到底是怎么样的呢?
2.2、切块上传流程分析
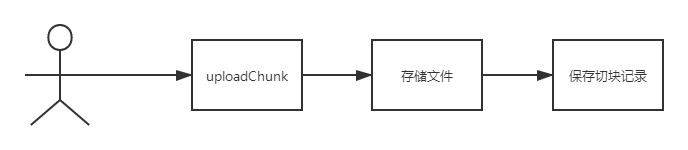
其实切块上传接口(uploadChunk)的核心功能就是两个,存储切块文件、保存切块记录;等到所有切块都上传完成,然后再去通知切块合并接口。
试一下,切块上传的时候我们的切块文件
到底存哪里呢?切块记录
到底保存在哪里呢?
切块存储
方案一:把切块文件存储到本地的临时目录,等切块合并的时候,再上传到分布式文件系统
优点:这种方案的优点是文件保存本地临时目录,速度非常的快。
缺点:集群模式下,每次处理切块的服务器可能不同,导致最终无法获取所有的切块信息
方案二:直接存储到正式的文件系统,合并的时候不用再上传了
优点:可以解决集群模式下切块散乱的问题;合并切块的时候无需再上传分布式文件系统
缺点:可能导致垃圾文件,比如,切块最终合并失败,那么文件系统就会存在垃圾切块
那么到底应该使用哪种方案呢?不着急我们再看下面这张图: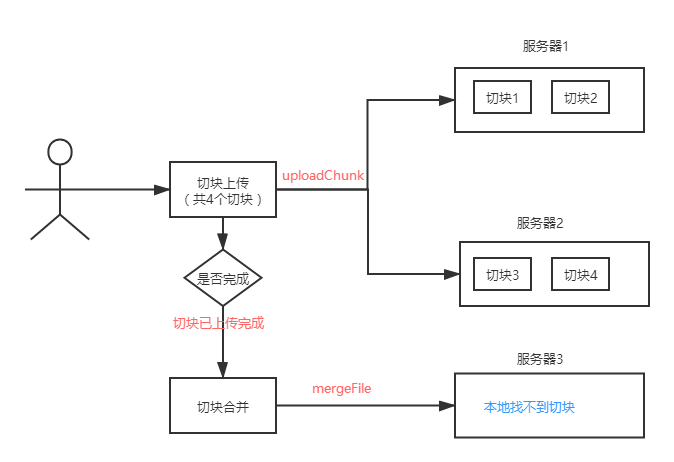
上面的图是集群模式下,每次请求都是不同的服务器进行处理,导致了合并切块的时候,本地磁盘找不到临时切块记录。因此,我们只能放弃方案一,选择方案二了。
切块记录保存
注意的是,切块上传成功不代表整个文件是上传成功的,比如:好多个切块,其中一个切块丢失了,那么最后校验文件是缺失的,那么最后整个文件上传是失败的。所以我们需要注意的是切块记录千万不要保存到正式表里面,可以新建一张临时表,等最后确认上传成功才完全转到正式表也是可以的的。但是使用 MySQL 新增一张临时表存储切块记录真的合适吗?
第一:10G 文件,如果切块标准是 5M,那么整个文件就会被切分成 2048 块,也就是需要调用 2048 次 uploadChunk 接口,需要保存 2048 次数据库。如果多个人同时上传 10G 文件呢?那么并发量还是很高的,对数据库的冲击很大。因此,最好不需要 MySQL 存储。
第二:建议使用 Redis 来存储,Redis 的吞吐量非常的高,除此之外,可以设置过期时间(比如:1h),如果整个文件最后上传失败了,那么切块记录最后自动失效。
那么,如果切块记录存储 Redis,那么它的 key 的规则如何设置呢?
这里什么意思呢?切块合并的时候,必须能从 Redis 完整取出所有切块记录,因此我们需要一个合理的 key 规则。
方案一: key=userid−{md5}-${chunknum} 【用户 id - 文件 md5 - 切块序号】,通过 userid-md5-* 去 Redis 就能取出某个文件的所有切块记录了。userid 的目的是区分不同人的记录;md5 是区分同一个人上传不同文件的记录。
WebUploader.js 如果设置 threads>1 的时候,会导致文件的 md5 和切块记录匹配不对的情况。什么意思?同时上传多个文件的时候,需要计算每个文件的 md5 值,还得切分文件,如果是单线程的情况下,每个文件排队处理则正常。如果多线程情况下,线程 A 计算文件 1 的 md5,线程 B 切分文件 2,那么此时就会搞乱完了。
因此,这种模式存在缺陷。
方案二: key=userid−{uuid}-fileid−{filename}-${chunknum}
userid,上传人的 id,主要是用来区分是谁上传的,避免不同的人上传同一份文件,导致数据错乱
uuid,前端每次打开上传窗口的时候生成 uuid,做唯一标识。避免同一个账号同时登陆不同浏览器上传同一份文件,导致数据错乱
fileid,前端生成的,它的规则 WU_FILE_x,x 是列表的序号,它其实就是上传列表的序号
filename,上传的文件名称
chunknum,切块序号
思考:为什么需要同时加 fileid 和 filename 呢?
解答:如果有两个文件,它们的文件名称一样,但是里面的内容不一样,如果只有 filename 的话,那么就会出问题。
好了,切块上传分析到这里,大家应该都能理解了吧,需要把文件的存储和记录的存储设计好,否则后期很麻烦。
2.3、切块合并流程分析

上面是切块合并的需要处理的大体业务逻辑点,整个流程还是比较清晰的,带大家把其中一些复杂的点给解析清楚。
问题 1:如何校验文件的完整性呢?
合并切块接口(mergeChunk)里校验了切块的数量和总文件的大小是否一致,其实这样就能保证了文件的完整性了。
问题 2:为什么需要判断文件是否存在呢?
如果高并发情况下,两个人同时上传同一份文件(md5 一样),上传之前,两个根据 md5 查询都发现为空,则两人都往服务器上传切块,切块合并的时候,如果不再判断一次是否存在的话,就会出现重复上传的情况。
问题 3:是否需要手工去删除 Redis 里面的切块记录呢?
其实不用,可以给切块记录的 key 设置过期时间(比如:1h),到期之后,监听到过期记录,如果它是
无效的
则把它对应的切块文件删除,注意,这里可以很好的解决上面提到的垃圾切块的问题了
。
3、表结构图
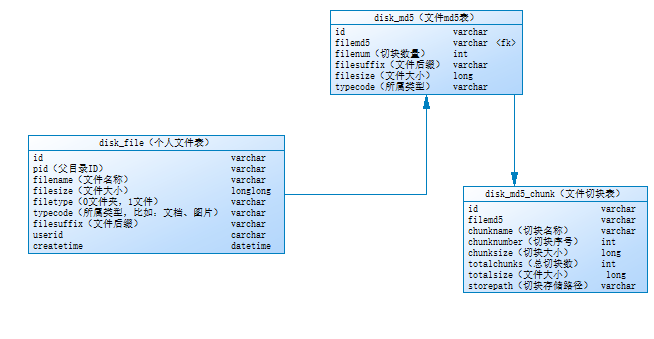
文件上传主要分为三张表,分别是 disk_file(个人文件表)、disk_md5(md5 表)、disk_md5_chunk(切块表),三张表通过 filemd5
来进行关联。
disk_file 主要是管理个人文件的,每个文件所属目录结构,每个人互不影响
disk_md5 保证文件的唯一性,即使多个人上传同一份文件,则数据库和文件系统都只保留一份
disk_md5_chunk 主要是存储文件的切块,它和文件系统进行关联,
storepath
表示切块在文件系统的存储位置
注意,很多人在做类似上传功能的时候(包括网上这方面的开源项目),往往只建一张 disk_file
表,不考虑 disk_md5
和 disk_md5_chunk
表。
4、技术准备
根据上面的分析,相信大家对文件上传的流程都比较了解了,了解整体的需求和流程,接下来就是代码实现了,但是别着急马上进入撸代码阶段,我们应该做技术选型,实现起来技术难点在哪里?需要哪些技术去实现?
首先,需要计算文件的 md5 和对文件进行切块,但是这应该放在前端去实现,前面已经分析过了原因。接下来,我们一起看看到底还需要准备哪些技术?
技术点:切块合并的时候,
第二次判断文件是否存在
,为了保证安全,需要保证线程排队执行。
方案一:基于 Jdk 内部锁去实现,但是它的作用范围是单个进程,如果多个进程(集群模式)则它是失效的。
方案二:使用分布式锁,如果上传同一个文件,那么基于文件的 md5 作为锁的名称,让线程排队执行,从而保证数据的安全性。
分布式锁,有哪些技术方案呢?
基于 Redis 去实现分布式锁
基于 Zookeeper 去实现分布式锁
Redis 的性能虽然比 Zookeeper 的高,但是基于 Java 去实现 Redis 分布式锁的话,数据的可靠性相比没有 Zookeeper 的高。(可以参考后面分布式锁的章节)
技术点:Solr,为了提高搜索性能,集成 Solr 做全文检索引擎
技术点:Redis,上面也分析到了使用 Redis 存储切块记录
技术点:FastDFS,分布式文件系统
概念普及:很多同学可能会想不通
网盘系统
和分布式文件系统
之间的概念问题,首先网盘系统
属于面向用户的应用程序,分布式文件系统
面向开发人员的中间件。两者结合才是完整的网盘系统,之所以普及一下,主要是预防没有项目经验的同学容易搞混。
5、小结
本节主要对文件上传进行了全面的分析,包括:几个流程的分析、还有里面一些细节的考虑等等,希望对大家有启发的作用。
纸上得来终觉浅,绝知此事要coding...
