




其实,坑蛮深,尤其是对新手来说,没有走从陌生到熟悉的过程,所以很多时候都是迷迷糊糊,但是从不懂到懂的过程,就是从迷糊中走出来的过程,重点是:不要怕犯错,不要怕拒绝,这才是懂的关键。
1:版本问题
这个可能是从接触spark开始最烦的问题了,版本不匹配,导致中间各种包冲突,冒出很多莫名其妙的问题。此处我们用的spark是2.0.0,从官网上我们可以看到支持的kafka是0.8的。千万不要看网上说支持0.10的,就是因为这个导致一直取不到kafka里面的数据。记住:对于spark2.0.0,我们选择的kafka版本是0.8.2.1.
1.1:maven配置
由于用的是maven进行的项目管理,我们的开发工具选择intellij IDEA,所以这里我的pom.xml文件中的配置是这样的:
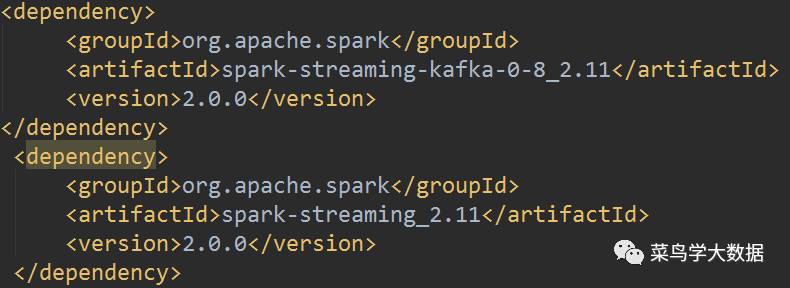
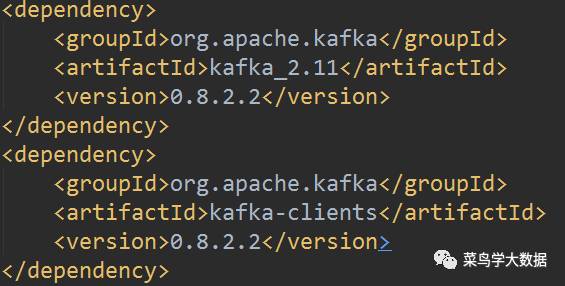
配置完成后,maven会自动在网络中下载我们配置的jar包,在本地的C:\Users\li\.m2\repository\[这里li换成自己的用户名]文件目录下,我们需要将kafka-streaming相关的jar包放到spark的jar包的目录下。
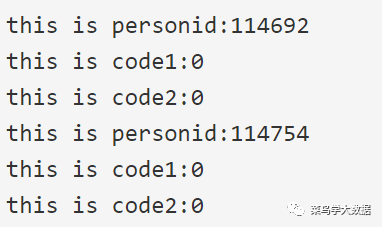
这样之后,我们可以从kafka中取到相应的数据。我的测试数据的输出结果如下:这只是很简单的一个测试。
1.2:json问题由于版本的问题导致的第二个问题就是json读不出来。说我们取得的数据不是{开头的。
1.3:cycle in the hierarchy这个问题也是由于版本问题导致的,将kafka修改为0.8版本,问题解决。
明天会将测试的源代码贴出来。
第一篇文章。你的鼓励是我写下去的动力,多谢关注。
文章转载自奶啤配炸鸡,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
