





引入:多数据库适配-数据源Oracle->MySQL兼容切换
下文,小编主要以Oracle->MySQL适配为例->常见问答Q-A的方式阐述:

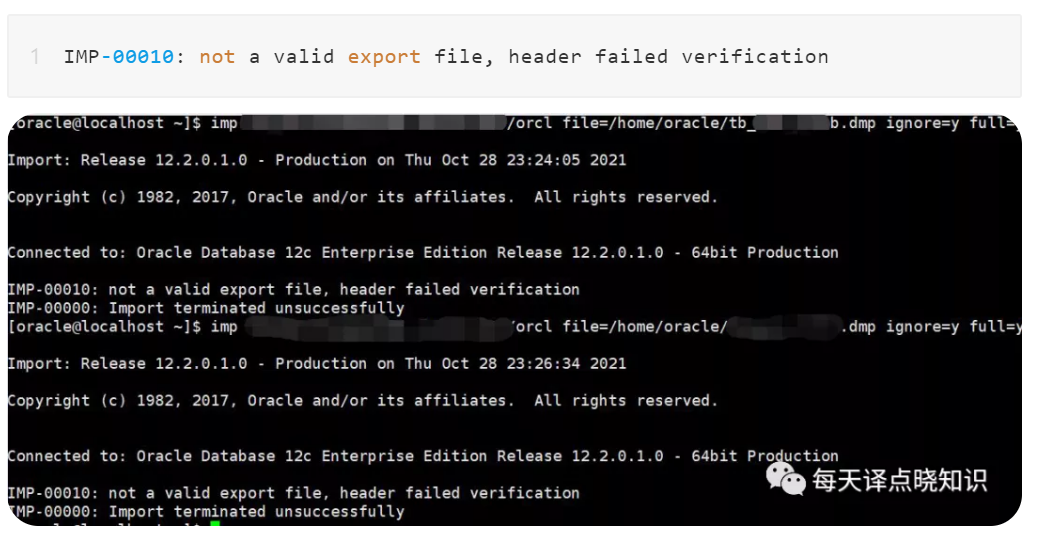
补充记录:从高版本->低版本,数据导出->导入会出现如下异常
接着,通过SQL查询当前Oracle版本,
select * from v$version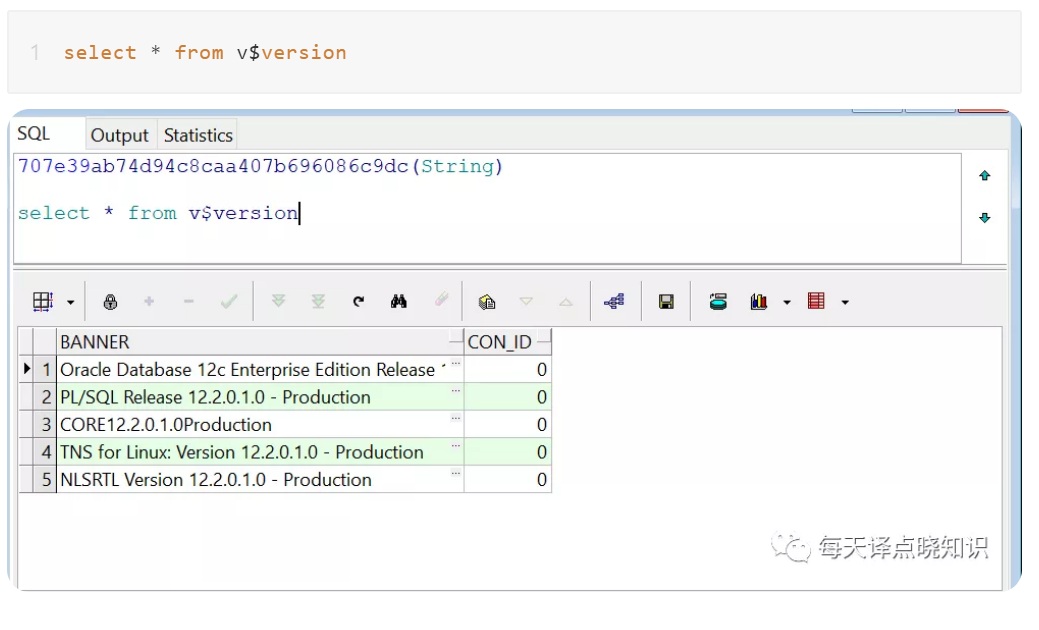
此时,通过Notepad++修改dmp文件中版本信息为

再次执行imp命令,
[oracle@localhost ~]$ imp yd_dev_tmp/user@ip/orcl file=/home/oracle/xxx.dmp ignore=y full=y;成功导入数据泵.dmp文件。(其中,可通过su - oracle进入oracle目录,dmp文件可上传到/home/oracle路径)


上述列举了部分常见的函数,
1、COALESCE函数 && NVL函数MySQL:COALESCE()Oracle:COALESCE()、NVL()COALESCE函数在MySQL跟Oracle都适用,NVL函数在Oracle中适用,COALESCE可替换NVL。
2、STR_TO_DATE函数 && TO_DATE函数MySQL:STR_TO_DATE(field,'yyyy-mm-dd')Oracle:TO_DATE(field,'yyyy-mm-dd hh24:mi:ss')
3、CONVERT函数 && TO_CHAR函数MySQL:CONVERT(field,CHAR)Oracle:TO_CHAR(field)
4、DATE_FORMAT函数 && TO_CHAR函数MySQL:DATE_FORMAT(field,'%Y-%m-%d')Oracle:TO_CHAR(field,'yyyy-MM-dd')
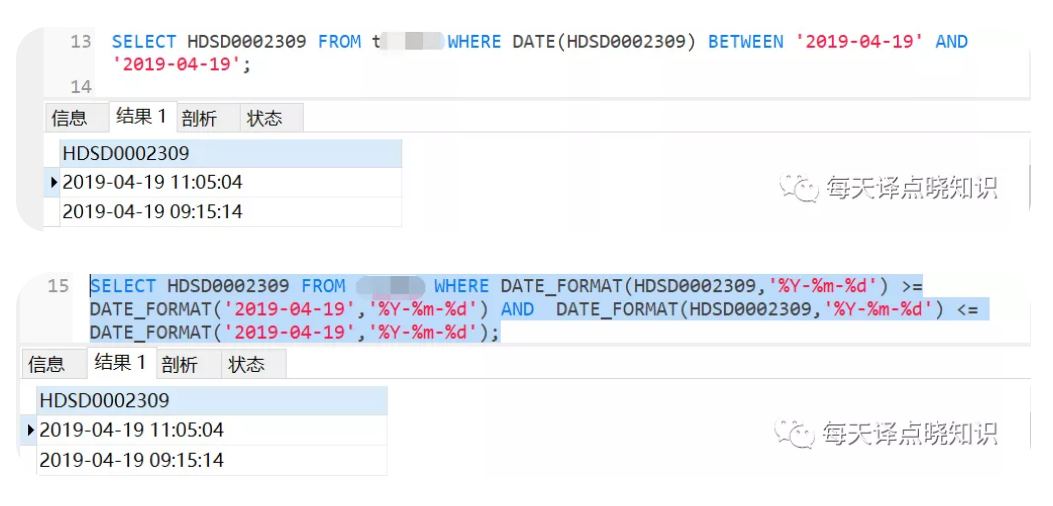
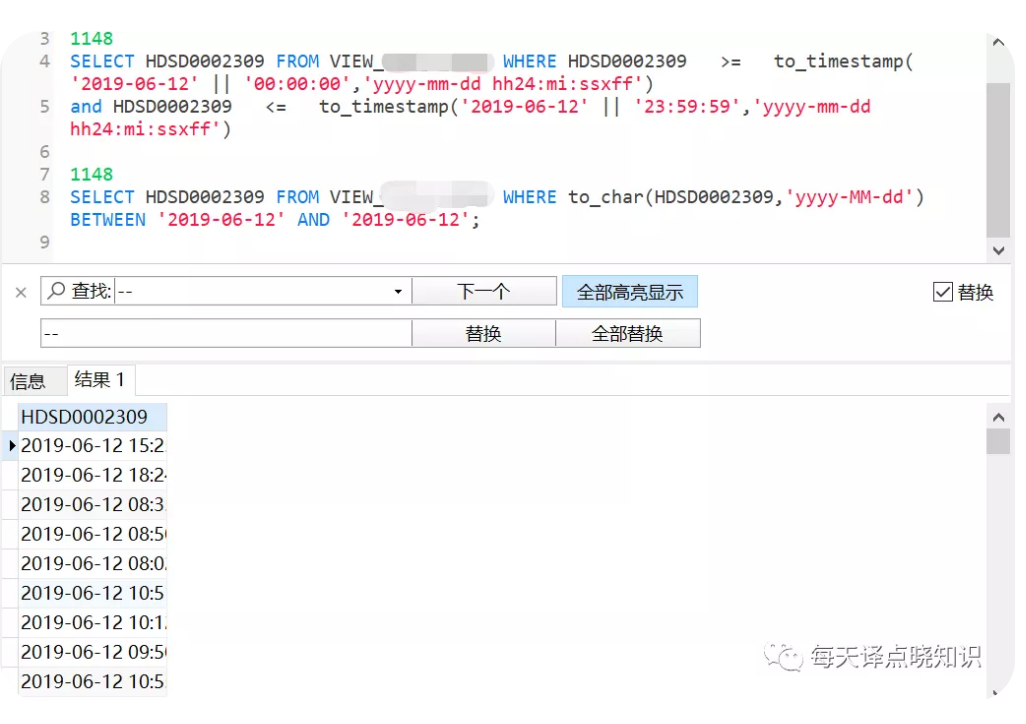
MySQL日期区间计算,
对应Java中常用ORM映射框架Mybatis中XML写法-SQL,其中MySQL方言可指定databaseId为mysql,Oracle方言可指定databaseId为oracle。
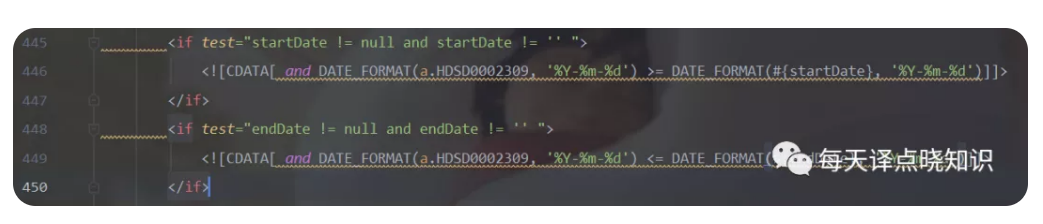
Oracle日期区间计算,
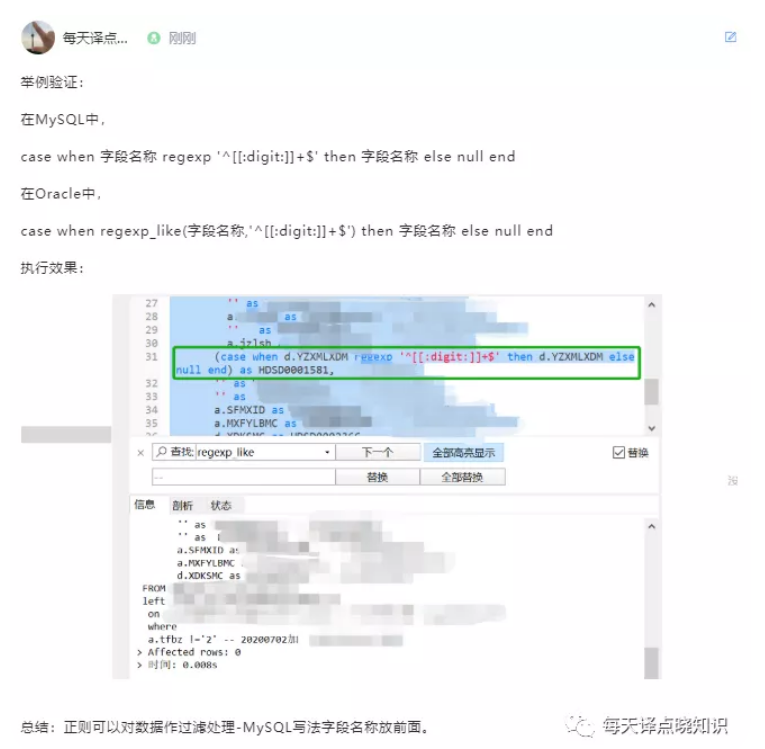
MySQL与Oracle正则表达式,可参考之前在墨天轮问答-给出正则regexp的解答,
Oracle函数DECODE,
DECODE(A.KLX,'01','居民身份证','02','居民户口簿','03','护照','04','军官证','05','驾驶证','06','港澳居民来往内地通行证','07','台湾居民来往内地通行证','其他')MySQL函数IF可实现Oracle中DECODE效果,
IF(A.KLX='01','居民身份证',IF(A.KLX='02','居民户口簿',IF(A.KLX='03','护照',IF(A.KLX='04','军官证',IF(A.KLX='05','驾驶证',IF(A.KLX='06','港澳居民来往内地通行证',IF(A.KLX='07','港澳居民来往内地通行证','其他')))))))MySQL视图中函数,
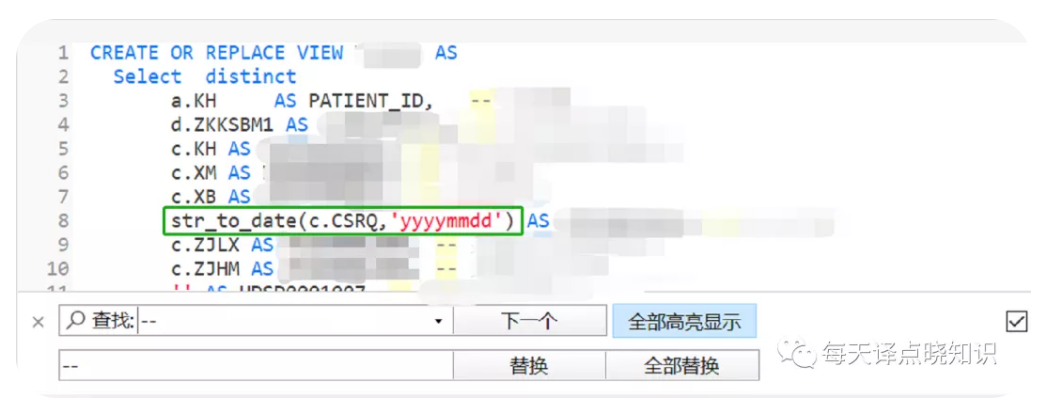
Oracle视图中函数,
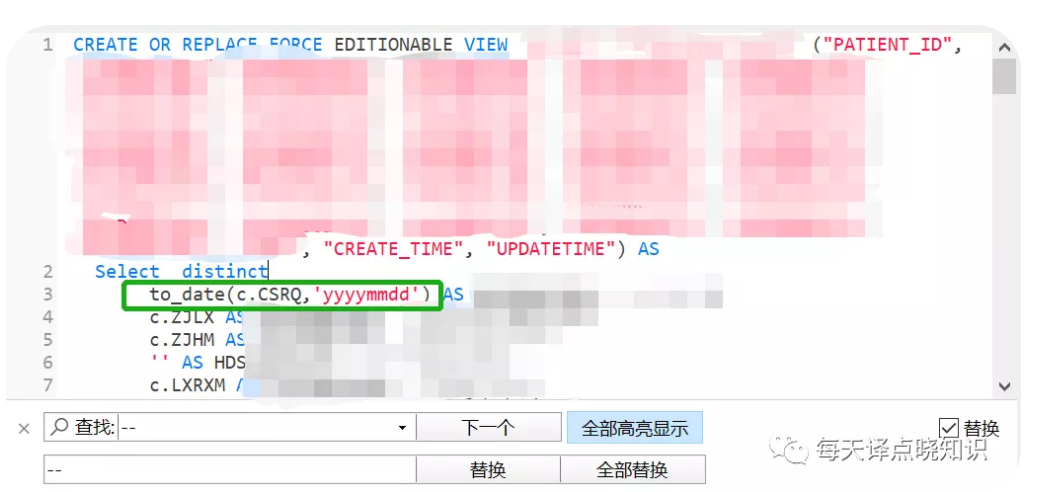


基于Mybatis插件的思想,根据当前数据库databaseId,拦截SQL,加入各自数据库的SQL方言函数兼容,无需多套数据库XML中SQL写法。后续考虑在GitHub上开源一款SQL插件,支持插拔式-需要时开启。
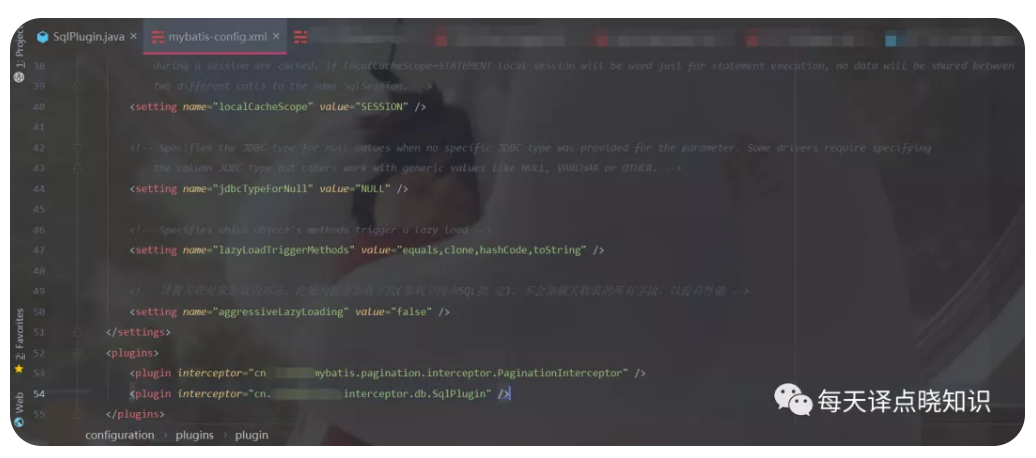
可自动将复杂SQL填充参数,打印SQL语句,
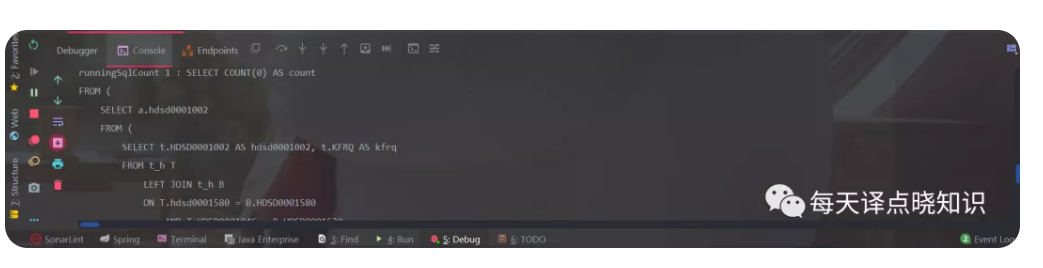
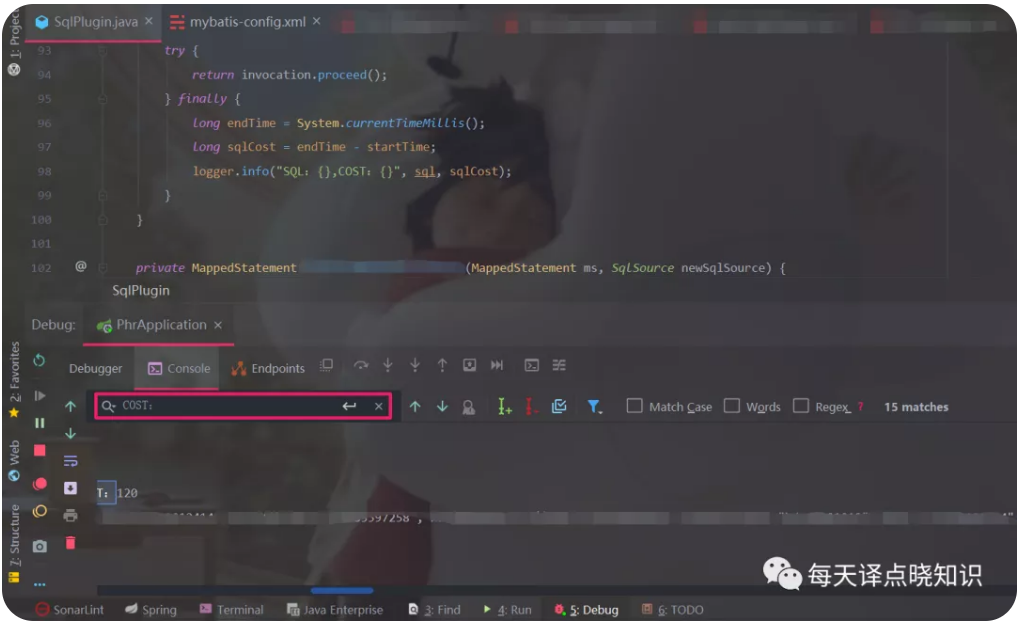
并打印其执行计划及耗时,助力于生产环境分析SQL,排查问题,性能优化。
引出这样一个小场景-思考:当你需要作多数据库兼容适配的时候,想提前预估需要改动的一个数量级,这时若需要对数据库层中各个SQL方言编写测试用例,作成功或失败率评估,那么如何拥有一个Java版本,单元测试用例-代码自动生成器,根据类名配置,即可知晓当前类中所有SQL方言的成功或失败率?^_^
当然,我们也可以在工作之余去看看其他的开发语言,Php,Python,Go......
文末:
回顾更多精彩请点击^_^,记一次基于鲲鹏欧拉操作系统openGauss实践过程
「 往期文章 」
Elasticsearch读写数据工作原理 | MySQL的重复数据插入处理
Elasticsearch进阶篇 | 记kibana执行dsl脚本实战过程
Kafka | 记一次修复Kafka分区所在broker宕机故障-引发当前分区不可用的思考过程
序列化 | Google的Gson与Alibaba的FastJson机制

评论

 0 点赞 0 点赞
0 点赞 0 点赞




