




本文的主要从新学习整理Oracle11g RAC相关资料 --Firsouler
1.RAC体系结构
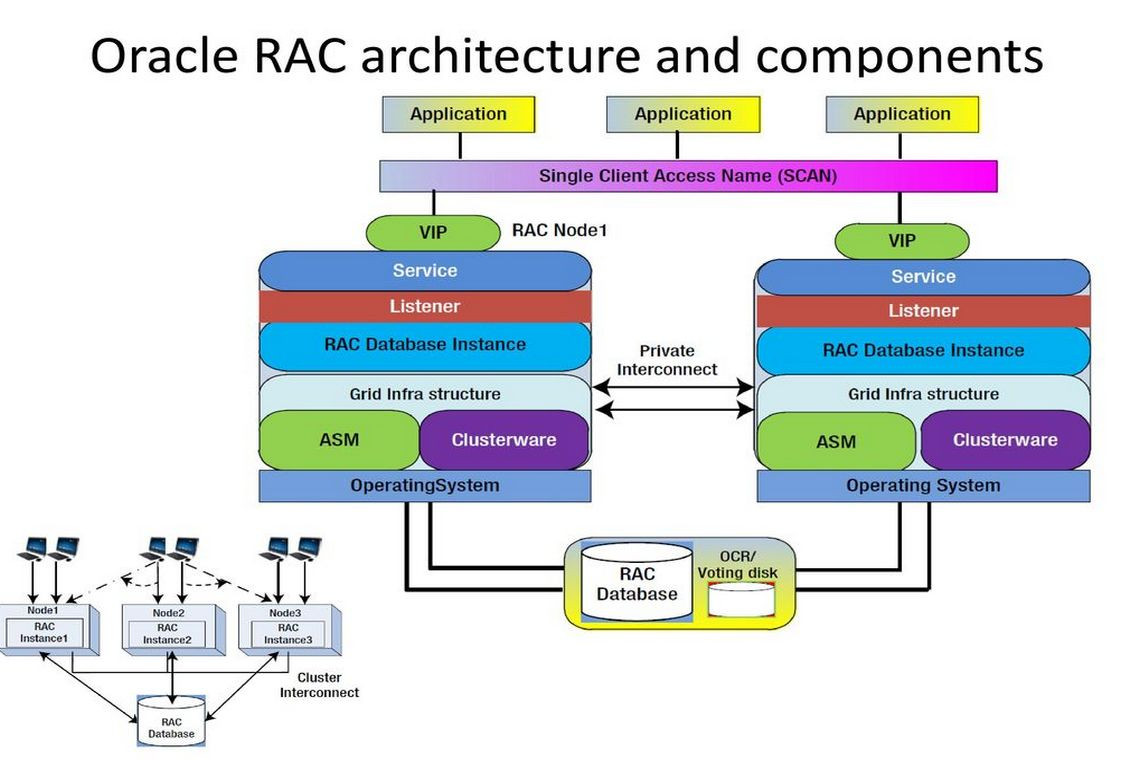
Oracle RAC主要结构和组件如上图所示,RAC相比较与单实例,主要组件多了集群软件及其他组件,如ASM、SCAN IP、及相关进程。 主要特点是多实例管理一个数据库,共享数据库相关文件。
CSS(Cluster Synchronization Service)
负责构建集群、维护集群的一致性.
ocssd启动顺序(Oracle11g init.ohasd)
- ocssd.bin守护进程被启动
- ocssd.bin和gpnpd通信,读取gpnp profile中VF的discovery string,并扫描VF
- 找到VF,获取集群基本配置信息,如misscount,reoot time,long I/O timeout,short I/O timeout
- ocssd.bin继续跟gpnpd通信,获取私网信息,以便跟其他节点通信
- ocssd.bin通过gipcd进程获得本地节点和远程节点具体私网连接信息
- 节点私网建立连接,集群重新配置开始
- 集群重新配置结束,集群成员列表被更新
CRS(Cluster Ready Service)
主要负责管理集群中的资源
OCR位置
cat /etc/oracle/ocr.loc
#查看ocr信息,可使用以下命令,root用户
./ocrdump /tmp/ocrdump
#检查
./ocrcheck
#查看备份
ls -lrt /u01/app/crs/cdata/crs
#恢复,前停止集群
./ocrconfig -resotre /u01/app/crs/cdaa/crs/backup00.ocr
OCR主要包含以下内容
- SYSTEM:包含集群CSS/CRS/EVM 三个组件的重要配置信息,如css层面的集群网络配置信息、VF等;CRS层面的安全和验证信息、CRSD之间的通信配置;EVM层面的通信配置。
- DATABASE:包含集群定义的资源的一部分配置信息,如VIPCA、dbca、netca等
- CRS :记录CRSD管理的所有资源的属性
集群套件
- voting disk : 表决盘,集群中每个节点定期评估自身的健康情况,然后会把它的状态信息放入到表决磁盘上。节点间互相查看运行状态,并把相关信息传送给其他节点进而写入表决磁盘,所以磁盘需要共享。
- OCR : Oracle Cluster Registry,集群注册服务,主要用于记录RAC中集群和数据库的配置信息。这些信息包括了集群节点的列表、集群数据库实例到节点的映射以及CRS应用程序资源信息。OCR使用两种方式验证节点状态,一个是表决盘,另一个是心跳。如果时间超出会造成节点驱逐。 查看时间设置命令如下:
#查看表决盘信息
crsctl query css votedisk
#网络心跳超时
crsctl get css misscount
#磁盘超时
crsctl get css disktimeout
集群启动顺序
集群大概可分为四个层次
- OHAS:负责集群的初始化资源和进程
- CSS :负责构建集群并保证集群的一致性
- CRS :负责管理集群的各种应用程序的资源
- EVM :负责在集群节点间传递集群事件
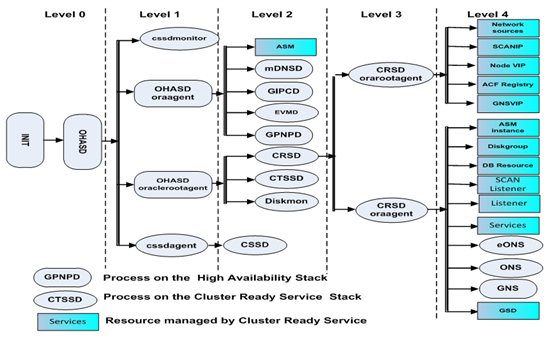
RAC并发
RAC主要通过Distributed Lock Management(DLM:分布式锁管理器) 来解决并发问题,RAC 的DLM 叫作 Cache Fusion,DLM中,根据资源数量、活动密集程度把资源分为两类:
- Cache Fusion :指数据块这种资源,包括普通数据库,索引数据库,段头块(Segment Header),undo 数据库
- Non-Cache Fusion : 是所有的非数据库块资源, 包括数据文件,控制文件,数据字典,Library Cache,share Pool的Row Cache等。Row Cache 中存放的是数据字典,它的目的是在编译过程中减少对磁盘的访问。(典型的Non-Cache Fusion资源是 Shared Pool中的 Row Cache 和 Library Cache中的内容。)
在Cache Fusion中,每一个数据块都被映射成一个Cache Fusion资源,Cache Fusion 资源实际就是一个数据结构,资源的名称就是数据块地址(DBA)。每个数据请求动作都是分步完成的。首先把数据块地址X转换成Cache Fusion 资源名称,然后把这个Cache Fusion 资源请求提交给DLM, DLM 进行Global Lock的申请,释放活动,只有进程获得了PCM Lock才能继续下一步,即:实例要获得数据块的使用权。
Cache Fusion要解决的首要问题就是:数据块拷贝在集群节点间的状态分布图, 这是通过GRD 实现的。
GRD(Global Resource Directory)
Cache Fusion要对数据块进行管理,首要解决的问题是, 数据块拷贝在集群节点间的状态分布图,而这是通过GRD来实现的。GRD 是一个内存结构,在所有的实例中分配。GRD里面记录着每个数据块在集群间的分布图,位于每个实例的SGA中。每个实例都是部分GRD,所有实例的GRD 汇总在一起才是一个完整的GRD。RAC会给每一个资源(数据块)选择一个节点作为它的Master Node,而其他节点作为Shadow Node。 可以通过以下sql查询数据块的master node。
--可以通过以下sql查询数据块的master node
select b.dbablk, r.kjblmaster master_node
from x$lel, x$kjblr, x$bhb
where b.obj = <DataObjectId>
and b.le_addr= l.le_addr
and l.le_kjbl = r.kjbllockp;
2.内存融合技术
共享池主要保存与内存融合相关的资源管理信息,如gcs(global cache service) 和GES(global enqueue service)资源的定义信息和他们相关的锁信息以及其他信息.如
select count(block_count) from v$gc_element;
RAC主要进程
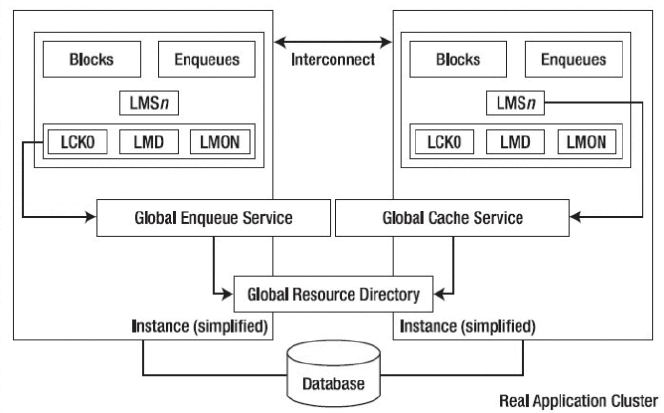
如上图所示,RAC中多出需要进程,主要有:
- LMSn : 这个进程是Cache Fusion的主要进程,负责数据块在实例间的传递,对应的服务叫作GCS(Global Cache Service), 这个进程的名称来源与Lock Manager Service。
- LMD : 这个进程负责的是Global Enqueue Service(GES),具体来说,这个进程负责在多个实例之间协调对数据块的访问顺序,保证数据的一致性访问。 它和LMSn进程的GCS服务还有GRD共同构成RAC最核心的功能Cache Fusion。
- LCK : 这个进程负责Non-Cache Fusion 资源的同步访问,每个实例有一个LCK 进程
- LMON :各个实例的LMON进程会定期通信,以检查集群中各个节点的健康状态,当某个节点出现故障时,负责集群重构,GRD恢复等操作,它提供的服务叫作:Cluster Group Services(CGS)。 其主要借助节点间心跳网络(定期ping检测各节点)和控制文件的磁盘心跳(每个节点CKPT进程每3秒更新一次控制文件的一个块,块叫Checkpoint Progress Record,实例间相互检查对方是否及时更新来判断)来完成健康检查。
- DIAG : DIAG 进程监控实例的健康状态,并在实例出现运行错误时手机诊断数据记录到alert.log 文件
- GSD : 为客户端提供管理接口,如srvctl 接收用户命令
- LMHB :Global cache/Enqueue Service Heartbeat Monitor,作用监控LMS/LMD/LMON/LCK等于rac相关的主要后台进程
Cache Fusion,GCS,GES关系
Cache Fusion(内存融合)是通过高速的Private Interconnect,在实例间进行数据块传递,它是RAC 最核心的工作机制,它把所有实例的SGA虚拟成一个大的SGA区。每当不同的实例请求相同的数据块时,这个数据块就通过Private Interconnect 在实例间进行传递。
整个Cache Fusion 有两个服务组成:GCS(LMS)和GES(LMD)。 GCS 负责数据库在实例间的传递,GES负责锁管理。
需要了解几个名词 CR(读一致性)/ DRM(Dynamic Remastering)
3.RAC心跳机制
网络心跳
网络心跳主要是确保节点间的连通性, ocssd.bin进程每秒向其他节点发送网络心跳,确认连通性。
ocssd.bin进程包含以下线程:
- 发送线程(clssnmSending Thread) : 每秒向其他节点发送网络心跳信息
- 分析线程(clssnmPolling Thread) : 分析处理,如发现某节点持续丢失心跳,就会通知集群进行重配。
- 集群重配线程(clssnmRcfgMgr Thread) : 该进程负责重配
- 派遣进程(clssnmClusterListener): 接收远端消息,根据消息种类发给相关进程
磁盘心跳
解决脑裂问题,投票决定节点去留。每个节点每秒都会向表决盘注册本地节点的磁盘心跳信息,相关进程
- 磁盘心跳线程(clssnmvDiskPing Thread): 负责向集群的表决盘发送磁盘心跳,也负责读取表决盘中的kill block信息,以确定本地节点是否需要重新启动
- 磁盘心跳监控线程(clssnmvDiskPingMonitor Thread) : 监控磁盘心跳线程能是否正常工作
- kill block线程(clssnmv KillBlock Thread) : 负责监控VF的KILL BLOCK信息
本地心跳
本地心跳的作用是监控ocssd.bin进程以及本地节点的状态。
cssdagent和cssdmonitor的功能就是监控本地节点的ocssd.bin进程状态和本地节点的状态,对于ocssd.bin进程的监控是通过本地心跳来实现的,Oracle会在每一秒钟,在发送网络心跳的同时向cssdagent和cssdmonitor发送本地ocssd.bin进程的状态(本地心跳)。如果本地心跳没有问题,cssdagent就认为ocssd.bin进程正常。如果ocssd.bin进程持续丢失本地心跳(到达misscount的时间)ocssdagent就会认为本地节点的ocssd.bin进程出现了问题,并重启该节点
心跳丢失日志信息
丢失网络心跳
丢失网络心跳,自11.2.0.2开始,只会重启GI,节点不会重启
#彼此不能访问
node1: at 50% heartbeat fatal,eviction in 15.919 seconds seedhbimpd 0
node2: at 50% heartbeat fatal,eviction in 15.919 seconds seedhbimpd 0
#互相宣称驱逐
node1: eviction started for node2,flags 00x04od,state 3,wt4c 0 seedhbimph
node2: eviction started for node1,flags 00x04od,state 3,wt4c 0 seedhbimph
#根据磁盘心跳判断
node1: node 2 is alive
node2: node 1 is alive
丢失磁盘心跳
21L22:333 [CSSD][1236798432] clssseExit:CSSD aborting from thread clssnmvDiskPingMonitorThread
丢失本地心跳
(:CLSN00111:) clsnproc_needreboot:Impending reboot at 90% of limit 27945;disk timeout 27742,
network timeout 27945,last heartbeat from CSSD at epoch seconds...
4.ASM介绍
ASM功能和架构
ASM可以存放的文件
- 控制文件
- 数据文件
- 重做日志文件、归档文件、闪回日志文件
- RMAN备份集
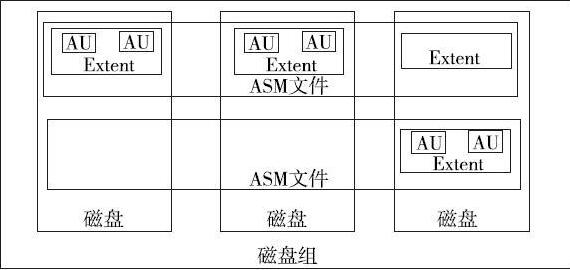
名词解释
- AU(Allocate Unit): 分配单元,是ASM分配最小单位,类似数据块,默认1MB,可指定。AU大小需要是db_block_size的整数倍。
- Extent:扩展,若干个AU构成的集合,每个Extent只能保存在同一个磁盘中,且只能属于一个ASM文件,Extent是ASM磁盘组分配空间的单位。ASM层面的Extent大小固定。 如下:
| Extent 数量 | Extent大小 |
|---|---|
| <20 000 | 1个AU |
| 20000-39999 | 4个AU |
| 40000 | 16个AU |
磁盘冗余
-
不指定故障组时:每个磁盘作为故障组,普通冗余,允许损坏一个磁盘;高冗余允许损坏两块磁盘
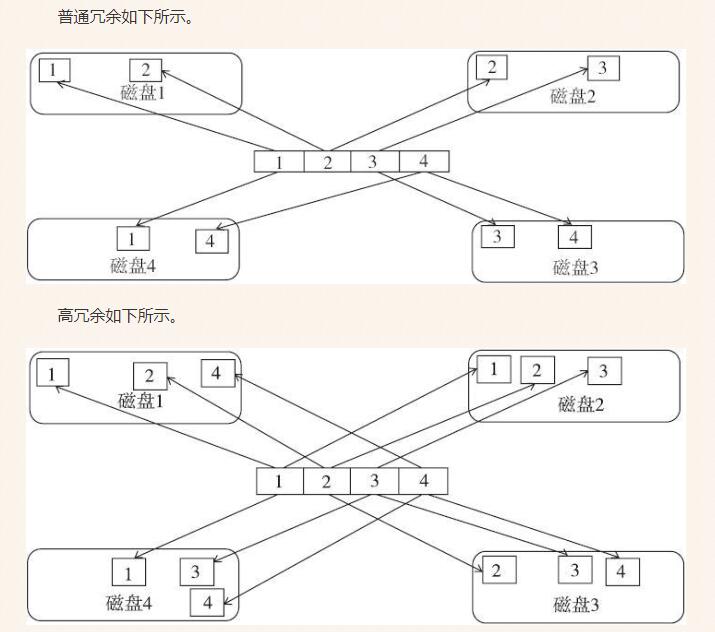
-
指定故障组:普通冗余,允许损坏一个故障组不丢失数据;高冗余,允许损坏两个故障组不丢失数据
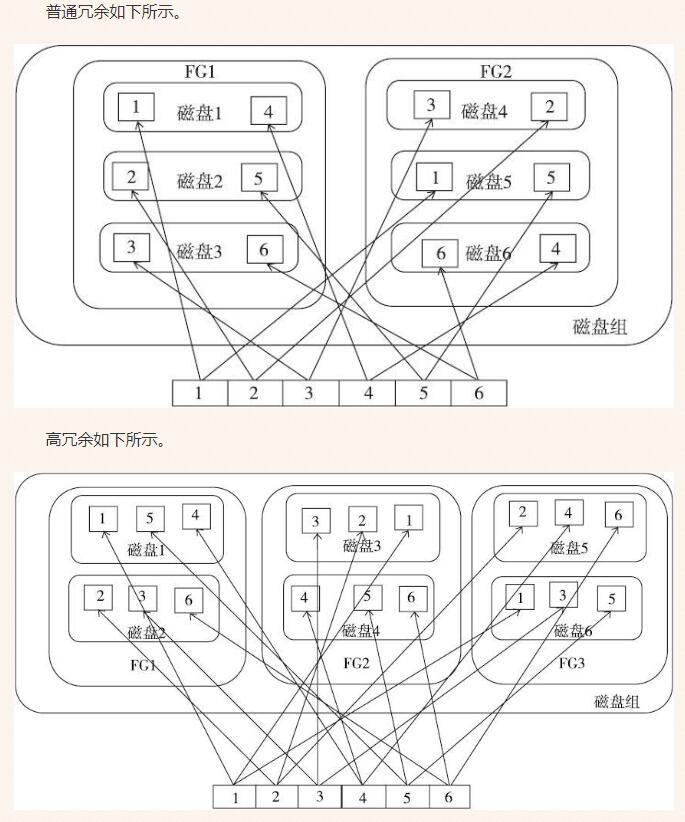
ASM实例
初始化参数位置 : gpnptool get
特有的进程
- GMON(asm disk group monitor) :维护磁盘组各个磁盘状态一致性
- RBAL(ASM rebalance Master) : 负责磁盘组的Rebal-ance操作
- ASMB : 负责和ASM实例进行通信
数据库和ASM通信
- RBAL : 数据库上的进程,负责数据库层面管理磁盘组。如打开、创建等
- ASMB:ASM实例上的ASMB进程负责启动asm后和css的gm部分进行连接,获得连接asm实例锁需要的连接串,所有的asm实例的客户端都需要通过这个连接串和asm进行连接。数据库实例的asm负责和asm实例的asmb进行通信,完成客户端发送到asm实例的第一种请求。
--检查ocr文件名称
select f.group_number,f.file_number,a.name,f.type,f.redundancy from v$asm_file f,v$asm_alias a
where a.file_number=f.file_number and a.group_number=f.group_number and
f.type='OCRFILE';
--ocr包含的具体AU
select k.number_kffxp,d.name,k.au_kffxp from x$kffxp k ,v$asm_disk d
where k.disk_kffxp=d.number and d.group_number=2
and k.number_kffxp=255 order by k.au_kffxp;
5.RAC性能
相关的等待事件
TX enqueue:这个排队代表进程在等待以下的情况之一
- 情况1:进程等待其他的事务(Transaction)提交或者回滚,对应的等待事件是enq:TX-row lock contention。这种情况的产生绝大部分是由应用程序设计导致的
- 情况2:进程在等待需要操作的索引块分裂。对应的等待事件是enq:TX-indexcontention。这种情况的产生大部分是由于对包含有单向增长的主键索引(或者唯一索引)的表进行大量的并发的插入操作。另外,很多时候读者会发现这个等待事件会与gc相关的等待事件同时出现
- 情况3:进程等待在数据块中分配新的事务槽位(ITL)对应的等待事件是enq:TX-allocate ITL entry。这种情况的产生大部分是由于数据块比较大,数据行长度小,这导致了大量并发事务集中到了少量的数据块中.
SQ enqueue
SQ enqueue:这个排队是和序列(Sequence)相关的,它表示某个进程需要持有一个序列,以便从中获得一个值(nextval)。对于RAC系统,如果多个实例同时使用相同序列,而且使用的频率很高,就会出现这个等待。另外,每当序列产生一组新的cache值时都需要更新序列的定义信息,所以这个排队经常与rowcache lock一起出现,而解决办法如下
- 加大序列的cache值
- 修改序列的排序属性为noorder
- 为不同的实例创建不同的序列
gc相关的等待事件
PCM资源(也就是数据块资源)对应的等待事件大部分都是以gc开头的,而且等待事件的名称与之前介绍的统计信息的名称是相对应的。gc相关的等待事件是由以下的部分构成的:
- 标识符:一定是gc(global cache)
- buffer的类型:可能是当前或者CR
- 完成的阶段:如果是块,表示已经获得了PCM锁,要去访问buffer了;如果是grant,表示还处在获得PCM锁的过程中,还没有开始访问buffer
- 性能提示(或者叫可能出现性能问题的地方):如果是2-way或者3-way,表明问题出现在网络层面或者主机层面;如果是busy,说明问题出现在buffer上;如果是congested,说明问题出现在LMS进程上。
p1表示文件编号,p2表示数据块编号,p3表示申请模式、持有模式和数据块类型
常见的gc相关的等待事件
- 1.gc current/cr block request:这个等待事件表示当前的进程要申请一个当前块或CR块,但是资源主节点的LMS进程还没有响应它的请求,也就是说,这个等待事件是一个placeholder等待事件,因为真正的消息传输和数据传输还没有开始
- 2.gc current/cr block 2 way:这个等待事件表示当前进程通过一个2路通信,向远程实例申请了一个current或者CR块,而这个申请请求在整个申请过程中并没有出现过超时
- 3.gc current/cr block 3 way:这个等待事件和gc current/cr block 2 way基本一致,只不过这个请求需要经过3个实例.
- 4.gc current/cr block busy:这个等待事件说明本地进程向远程实例申请一个当前块或者CR块,而远程实例在发送这个数据块时发现它正在被其他进程使用(或者被其他进程pin住)。注意,因为在申请当前块的时候可能会发生redoflush,这部分时间也是要计算在gc current block busy等待时间之内的。同样,对于CR块的请求,服务实例需要构建CR块,而且也可能会发生redo flush,这两部分时间也是要计算在gc cr block busy等待时间之内的。当发现gc currentblock busy等待出现了很多次,而且产生了很长的等待时间的话,需要查看一下相关信息去进一步分析。
- 5.gc current/cr grant 2-way:这个等待事件说明当前实例向主节点申请了一个current或者CR块,而且这个申请已经被主节点响应,其中并没有出现过超时。但是,这个等待事件与gc current/cr block 2/3-way的区别在于,这个被申请的数据块不包含在任何实例的数据库缓冲区(buffer cache)中,它是需要申请实例从数据文件读取出来的,所以不会有等待事件gc current/cr grant 3-way存在,因为这时只有申请者实例和主实例,没有持有者实例。而在等待事件gc current/cr block2/3-way中,申请者实例获得的数据块是远程实例发送过来的,也就是说申请者实例、主实例和持有者实例可能是3个不同的实例。
- 6.gc current grant busy:这个等待事件说明当前实例申请了一个当前块,而且主节点也已经确认申请者实例可以持有这个数据块,但是申请者在等待其他申请者完成它们的申请请求。这个等待事件说明申请者是以独占(X)的方式申请数据块的,但是其他实例上还有一些申请者以共享(S)的方式申请这个块,所以独占的申请请求要等待比它先到达的共享请求
- 7.gc current/cr block congested:这个等待事件说明本地进程向远程实例申请了一个current或者CR块,而远程实例也已经收到了请求,但是LMS进程并没有及时响应这个请求——将数据发送给申请者实例
- 8.gc current/cr grant congested:这个等待事件说明本地进程向远程实例申请一个当前块或者CR块,而远程实例也已经收到了请求,但是LMS进程并没有及时响应——将反馈消息(acknowledge message)发送给申请者实例。
- 9.gc cr failure/gc current retry:这个等待事件说明申请者实例没有收到一个CR块或者当前块。绝大部分情况下,这种问题都是由网络问题或者UDP参数设置问题导致的
- 10.gc current/cr multi block request:这个等待事件说明申请者实例需要向远程实例(可能是多个)申请多个(具体的数据块数量取决于参数db_file_mulitblock_read_count的设置)current或者CR块。这个等待事件只有在申请的所有数据块都被成功返回之后才会结束,也就是说,如果其中的一个数据块因为某种原因没有被成功接收的话,就需要重新申请所有的数据块。这也是为什么gc current/cr multi block request经常和等待事件gc cr failure/gc current retry同时出现的原因。对于大部分的系统,少量的gc current/cr multi block request等待事件不会影响系统的性能
如果在数据库性能出现2/3等待次数很多且耗时,可能会出现以下问题
- 私有网络带宽出现了问题。
- UDP层面出现了问题。如果使用了RDS的话,可能表示RDS层面出现了问题。
- 系统资源出现了问题。例如:CPU出现了竞争、过长的run queue。
- 应用角度:热点块、少量数据块并发读写频繁、如果CR块,过多事务被指定到了少量的回滚段
需要检查:AWR报告中的Global Cache andEnqueue Services-Workload Characteristics
如果出现4问题,需要检查
- 信息1:远程实例的AWR的Global Cache and Enqueue Services-WorkloadCharacteristics一节中Avg global cache current block pin time(ms)和Avgglobal cache current block flush time(ms)部分的统计值。如果没有AWR的信息,也可以查看视图V$INSTANCE_CACHE_TRANSFER中与当前块相关的列
- 远程实例的LGWR进程的跟踪日志文件和log file sync的等待时间、次数
- 远程实例的DBWR的性能和checkpoint incomplete的次数
- 应用角度:热点块、相同表大量并发的DML、带有主键的表大量并发insert
如果出现5中问题等待事件多且耗时,可能原因如下
- 网络带宽
- 系统工作负载
- 应用角度:某些sql执行计划问题,导致大量数据块被访问;数据块缓冲区被设置太小,频繁写入数据文件;检查点过于频繁
如果出现6特别多且耗时,可能原因
- 网络带宽
- 系统负载
- 应用角度:某一个实例不断修改一些数据块,二其他实例不断读取对应的数据块
如果出现8特别多,可能原因
- LMS进程出现了问题。例如:实例之间的LMS进程数量不同;LMS进程优先级不够而导致不能及时获取CPU时间
- 过多的实例间消息和数据传输使LMS进程过载
- 操作系统出现了资源竞争。例如:CPU利用率过高、出现了swap、内存耗尽等
- UDP层面的参数设置不正确或者私网性能问题
如果出现10特别多,可能原因
- 网络带宽
- UDP参数设置问题
- 应用角度:sql语句使用不正常执行计划,如full table scan
注意:由于内部限制,内存融合每次最多只能发送16个数据块
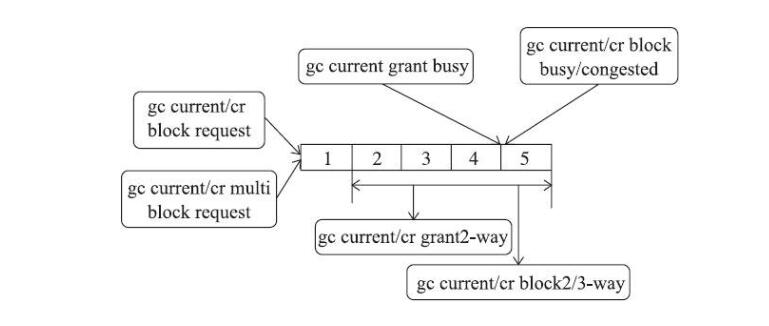
gc请求的5个阶段
- 阶段1:申请者进程发送一个请求
- 阶段2:主节点的LMS进程收到请求并响应
- 阶段3:主节点发送请求给持有者实例的LMS进程
- 阶段4:持有者实例的LMS进程响应申请者的请求
- 阶段5:持有者实例的LMS进程将需要的数据发送给申请者进程
各个等待事件出现的阶段:
常见的性能问题
序列
--eg noorder 方式
create sequence seq_test start with 1 increment by 1 cache 2 nomaxvalue nocycle noorder;
--查看,两个实例单独,实例1 1-20,实例2 21-40;
select seq_test.nextval from dual;
--order 方式 每个节点循环,1,2,3 注意这种方式争用会多,性能会变差
create sequence seq_test1 start with 1 increment by 1 cache 20 maxvalue 999999999999999 nocycle order;
对于RAC数据库,每个实例都会产生对于的cache值。cache+order的组合在RAC数据库中是被支持的,但是这同时也代表序列默认会被当作nocache来进行处理,也就是说,每次从序列获取一个新的值时就要访问一次数据字典信息。
注意事项(引起"row cache lock"/“DFS lock handle”):
- 尽量使用大的cache值来减少对数据字典信息的访问
- 尽量避免使用order选项
HW序列(“HW-contenttion”)
HW序列是进程在升高数据库对象(例如:表或者索引)高水位(High WaterMark)值时需要持有的资源,它的作用是防止多个进程同时修改高水位。下面场景出现最多
- 表空间的存储参数设置有问题,导致数据库对象频繁地申请空间
- 大量并发的parallel DML语句或者bulk insert语句
--eg 通过表空间存储参数缓解多实例并发引起的HW排队
create tablespace test1 datafile '+data' size 100m reuse extent management local uniform size 10M;
索引争用
同时多个实例会争用相同的索引(或者表)块,经常出现的等待事件有gcbuffer busy、enq:TX-index contention、gc current block busy、gc currentsplit等。 出现上述问题,建议如下:
- 使用hash或者range的方式对表进行分区
- 如果索引的列值是被顺序插入的(例如是通过序列产生的),可以考虑使用反向索引(Reverse Index),或者调整应用,使得插入进来的索引值能够被分布到更多的叶子块中。
- 考虑调整应用来避免将连续的键值插入表和索引当中
缓存尺寸导致的性能问题
内存融合在实例之间的通信是通过UDP来实现的,UDP协议,由于它是应用层到IP层的数据发送,而且不建立连接,也没有数据重发和超时机制,所以网络的性能和操作系统层面的UDP缓存参数设置也就显得非常重要。举例如下:
- 1.节点1的LMS进程需要发送一个数据块(db_block_size=8k,MTU=1500)给节点2,并把该请求通知OS
- 2.节点1操作系统需要将这个数据块切成大概6个数据分片,并放入节点1相应端口的UDP以发送缓存(Send Buffer)
- 3.数据分片通过网络被陆续发送给节点2
- 4.节点2的操作系统收到了发送过来的数据包,并将其保存到对应的UDP以接收缓存(Recevie Buffer)
- 5.节点2开始组装数据分片,当所有的6个数据分片都被成功组装之后,OS将组装过的数据包发送给相应的接收进程
- 6.节点2的接收进程处理收到的数据包
UDP问题时"gc currentblock 2-way"等待事件耗时多,linux相关参数如下:
net.core.wmem_max = 1048576 net.core.rmem_max = 4194304 net.core.wmem_default = 262144 net.core.rmem_default = 262144
11gR2新特性之HW
挂起(hang)是指某一个进程由于无法获得需要申请的资源而进入的等待状态,这种等待状态只有在获得申请的资源后才能够被解除。因此,hang的情况有两种:死锁(Dead Lock)和等待链(Wait Chain)。对于死锁,在RAC数据库中LMD进程会进行相应的处理,等待链会造成数据库缓慢。
基于此,Oracle在11g R2推出新特性Hang Manager(HW),来实现对hang(等待链)的管理,其中包括了对于hang的监控、分析、记录和解决,11.2.0.2版本才真正起作用。它能够主动发现数据库中存在的等待链,并从多个角度对它们分析。 相关文件
- dia0进程的主跟踪文件(DIA0.trc):这个日志会记录dia0进程工作的详细信息,包括发现、分析、处理hang的过程
- dia0进程的历史跟踪日志(_DIA0__n.trc): 定期刷新
- Incident日志文件:如果HM通过终止进程来解决hang的话,会首先在alert.log中记录一个ORA-32701错误
- 也可以通过视图:VHANG_INFO;VHANG_SESSION_INFO 相关的会话信息;V$HANG_STATISTICS 数据库统计信息
6.RAC管理
数据库层面脑裂
- 两个实例之间心跳网络出现问题,一段时间之后(默认300s),两个实例都无法和对方通信
- 每个实例都尝试获得RR锁(抢表决盘),获得RR锁的实例访问控制文件中的实例状态,并决定新的集群实例列表
数据库连接
参数说明
- local_listener :指定了数据库的PMON进程需要将本实例提供的服务注册到哪个endpoint,如果没设置,PMON默认将数据库的服务注册到本地节点的1521端口,这也是很多用户发现如果在默认位置创建了监听程序,数据库服务会被自动注册的原因
- remote_listener :将本地实例的数据库服务注册到集群其他节点的监听程序或者SCAN监听程序上
- listener_networks :在用户定义了多个集群公网时才需要设置,它的作用是将本地实例的数据库服务注册到多个公网的监听程序上
负载均衡
11g以后使用scan, 之前的版本tnsnames配置两个ip,并添加参数"LOAD_BALANCE=yes"
--查看负载均衡
select service_name,begin_time,end_time,goodness,delta,intsize_csec from v$servicemetric
where service_name='racdb';
已存在的连接故障
当前连接的数据库实例或服务出现问题时,把已经存在的数据库连接(会话)透明地迁移到其他数据库实例中。Oracle实现的方式主要有TAF(Transparent ApplicationFailover)和FCF(Fast Connection Failover)
TFA
TAF针对使用OCI方式连接到数据库的会话。它可以在客户端或者服务器端进行配置,如果用户在两端都进行了配置,服务器端的配置会覆盖客户端的配置,也就是说,服务器端的配置具有更高的优先级。TAF目前可以做到
- 使用相同数据库的用户在正常实例中创建一个会话
- 在原有服务出现问题之前已经执行过的操作不会被重复执行
- 对于正在执行的操作,如果是select语句,切换后会继续运行,但是对DML语句,它们会被自动回滚,用户需要重新运行。
说明:Oracle 12C推出的application continuity和transaction guard特性可以使TAF能够支持DML语句在会话切换后继续运行,但是本书并不会介绍这个的新特性
配置TAF有以下类型可以选:
- session:表示在故障切换发生后,新的连接会被创建到正常实例,问题出现时正在运行的操作不会被继续执行
- select:表示在故障切换发生后,新的连接会被创建到正常实例,问题出现时正在运行的select语句会被继续执行
- none:不会有故障切换发生,也就是禁用TAF
配置方式
srvctl add service -d ora11g -s test -r ora11g1 -a ora11g2 -P basic -e SESSION -m basic -w 5 -z 3
--查看
srvctl config service -d ora11g -s test
- -d :db_unique_name
- -s :数据库服务名
- -r :默认运行的数据库实例列表
- -a : 故障切换的目标实例
- -e : TAF类型
- -w :每次切换的时间间隔
- -z :切换次数
客户端FAT配置是通过参数FAILOVER_MODE方式,不建议客户端,如果服务端、客户端都配置了,优先服务端
FCF
FCF是针对非OCI连接的特性,例如:jdbc thin client连接,它需要和ONS、FAN(Fast ApplicationNotification)进行协作才能够正常工作。
相关概念:
- ONS:Oracle集群的事件发布组件,它负责在集群的某些组件发生变化时向外发布事件信息
- FAN:ONS实现事件发布的方式,换句话说,ONS负责向外发布FAN事件。FAN事件大致可以分为HA事件和负载均衡事件,HA事件是指集群的某个组件状态发生了变化,例如:节点宕掉、数据库实例被关闭或启动、数据库服务被停止或启动;负载均衡事件是指数据库服务的工作负载以及统计信息变化(这种事件需要对服务设置LBA相关的属性)
参考
- http://blog.itpub.net/29487349/viewspace-2751618/
参考资料
- RAC并发架构(https://www.cnblogs.com/youngerger/p/8996855.html)
- 《Oracle RAC核心技术详解》 - 高斌(微信读书)
- 部分命令参考(https://gitee.com/firsouler/my_db_scripts/blob/master/Oracle11g%E9%87%8D%E7%82%B9%E5%8A%9F%E8%83%BD%E4%BB%8B%E7%BB%8D.md)
