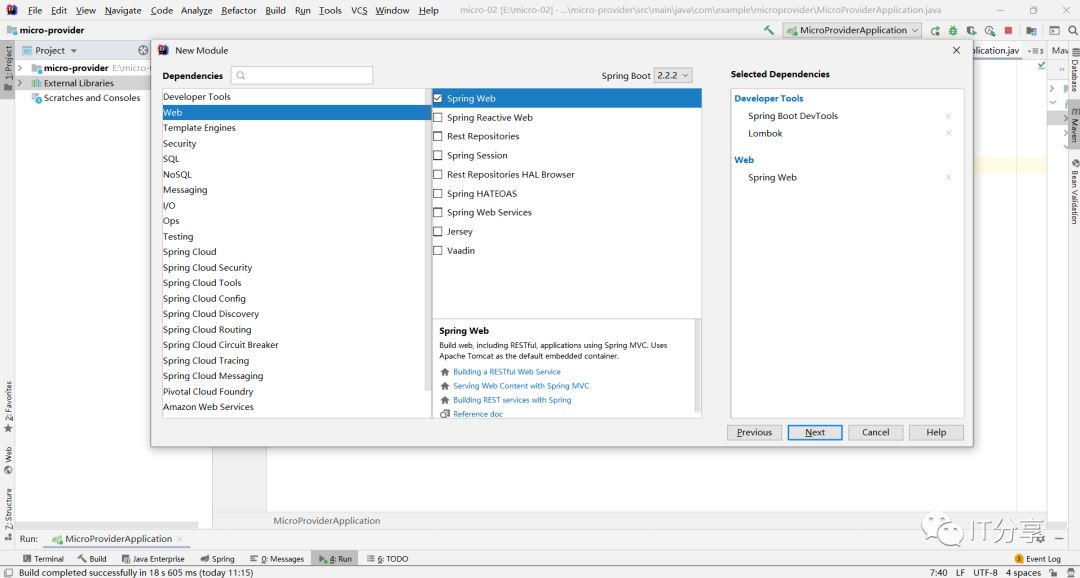
回顾上次写的内容:
1:如何构建 一个微服务及服务注册(是有问题的) 2:客户端如何调用服务端的API(写死,负载均衡(LoadBalanceClient,@LoadBalanced)
1.1: 先创建一个服务端的服务:
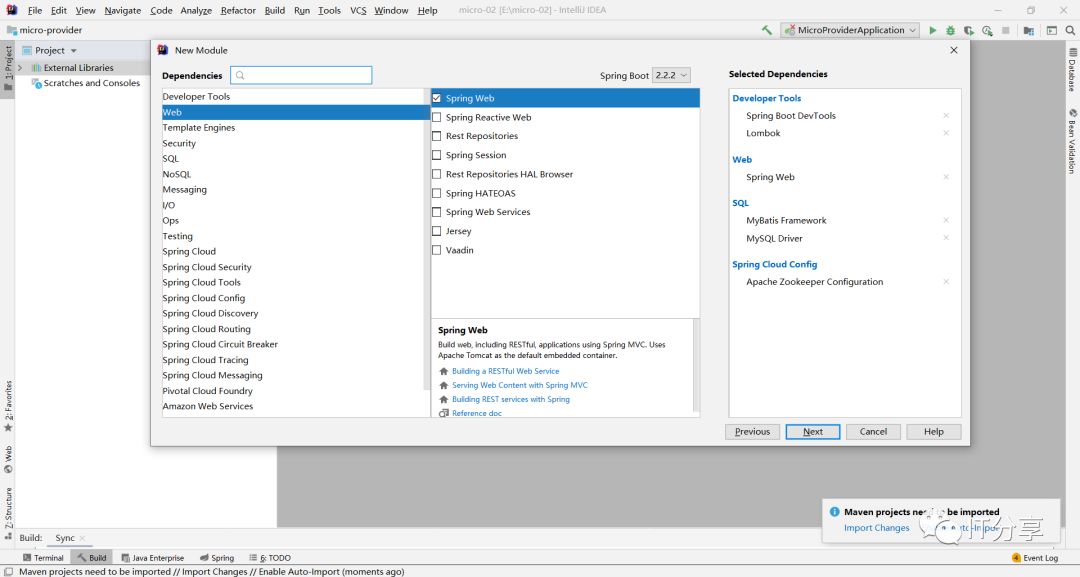
1.2:加一些依赖:
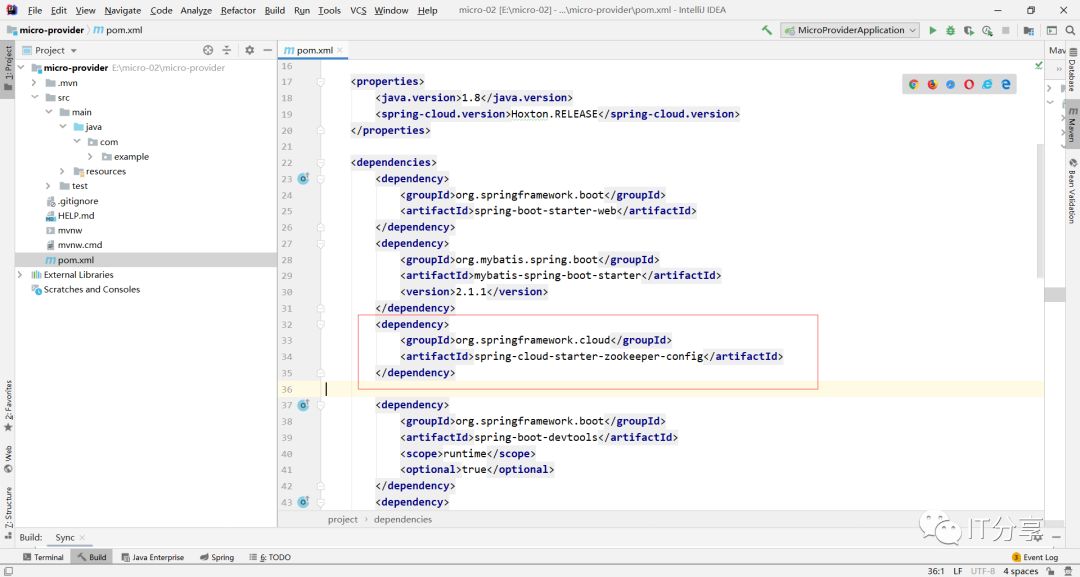
由于需要把这个服务注册到注册中心上去,所以说需要服务发现cloud Discovery->Zookeeper Discovery。上次写的内容不是这么写的。上次写的依赖是cloud config-> zookeeper configuration。这里先用下cloud config-> zookeeper configuration的依赖:
为了上次写的内容埋藏存在一个问题的话:用上次写zookeeper的依赖替换下zookeeper-config的依赖。
1.3:然后配置下数据源:
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
username: root
password: 123456
url: jdbc:mysql:///testdb?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8复制1.4:配置下驼峰的格式:
1.5:配置下控制台打印sql的日志信息:
mybatis:
configuration:
map-underscore-to-camel-case: true复制
logging:
level:
com.example.microprovider.mapper: debug复制1.6:把服务注册到注册中心上去:默认的是Localhost,我这里写127.0.0.1,其实和上次写的是一样的。
1.7:加下应用服务的名称:
spring:
cloud:
zookeeper:
connect-string: 127.0.0.1:2181复制1.8:创建一个实体类:
spring:
application:
name: provider复制
package com.example.microprovider.domain;
import lombok.Getter;
import lombok.Setter;
import java.util.Date;
@Getter
@Setter
public class UserInfo {
private Integer userId;
private String userName;
private int userAge;
private Date userBirth;
}复制1.9:提供一个UserMapper接口中返回UserInfo对象的方法:
2.0:用@MapperScan注解去扫描mapper接口的包的全路径,把接口中的方法的代理实现类注入到Spring容器中去,交给Spring容器管理。
package com.example.microprovider.mapper;
import com.example.microprovider.domain.UserInfo;
public interface UserMapper {
public UserInfo getUserInfo(Integer userId);
}复制
package com.example.microprovider;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.example.microprovider.mapper")
public class MicroProviderApplication {
public static void main(String[] args) {
SpringApplication.run(MicroProviderApplication.class, args);
}
}复制2.1:第一次写的是用注解的方式来写的,现在用xml的方式来写下,建个文件夹:mapper->UserInfoMapper.xml文件,由于传的参数只有一个,所以参数的名字可以随便写。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.microprovider.mapper.UserMapper">
<select id="getUserInfo" resultType="com.example.microprovider.domain.UserInfo">
select user_id,user_name,user_age,user_birth from t_user where user_id=#{userId}
</select>
</mapper>复制2.2:如果想要用xml方式的话:需要还配置下配置文件,这就可以启动整个mapper文件了。mybatis与整个mapper文件进行绑定。
2.3:然后写Service层:
mybatis:
mapper-locations: classpath:mapper/*Mapper.xml复制
package com.example.microprovider.service;
import com.example.microprovider.domain.UserInfo;
public interface UserInfoService {
public UserInfo getUserInfo(Integer UserId);
}复制2.4:在写Controller:
package com.example.microprovider.service;
import com.example.microprovider.domain.UserInfo;
import com.example.microprovider.mapper.UserMapper;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class UserInfoServiceImpl implements UserInfoService {
@Resource
private UserMapper userMapper;
@Override
public UserInfo getUserInfo(Integer UserId) {
return userMapper.getUserInfo(UserId);
}
}复制2.5:现在改下注册服务的名称(就是实例的名称),注册成功之后就可以得到这个名字,上次写的时候是注册的名字是由一段UUID生成的,写p1方便等会去查找。
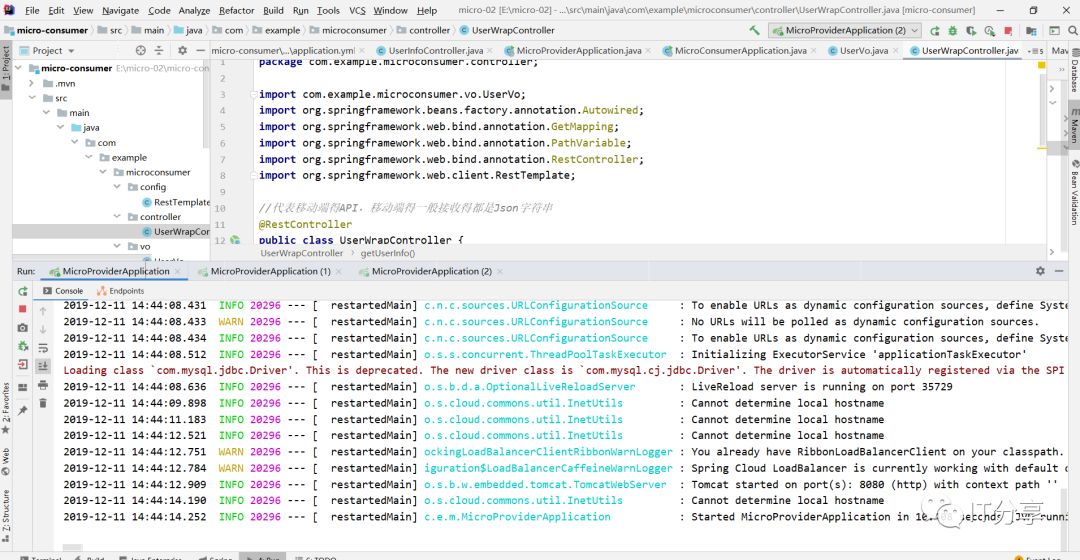
package com.example.microprovider.controller;
import com.example.microprovider.domain.UserInfo;
import com.example.microprovider.service.UserInfoService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class UserInfoController {
@Autowired
private UserInfoService userInfoService;
@GetMapping("user/{id}")
public UserInfo getUserInfo(@PathVariable("id") Integer userId){
return userInfoService.getUserInfo(userId);
}
}复制现在的整个后端的服务就写好了。因为它是服务的注册端,不是服务的发现端,不是客户端,所以说不用写发现的注解
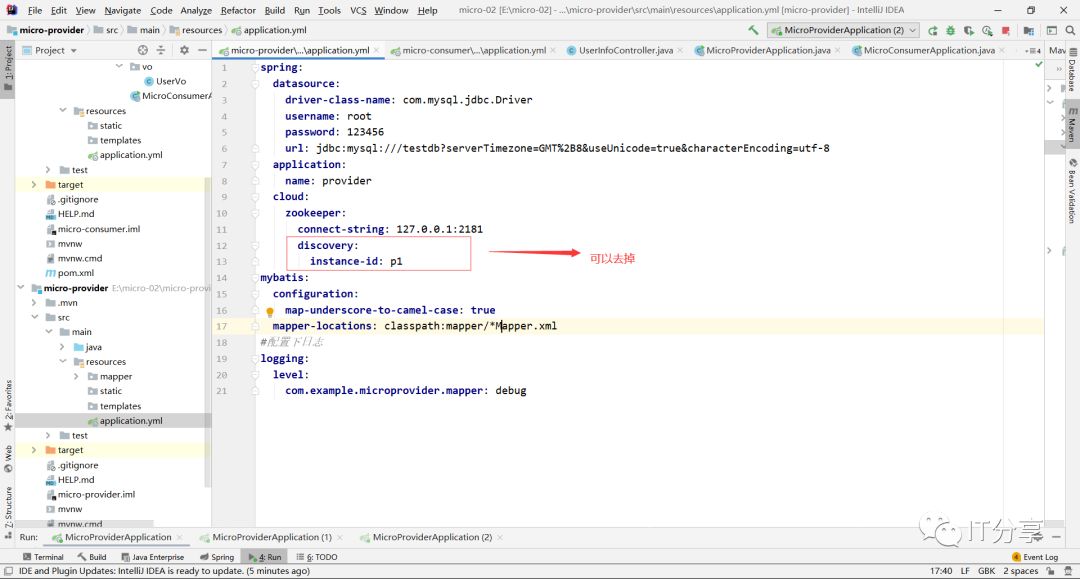
spring:
cloud:
zookeeper:
discovery:
instance-id: p1复制2.6:启动本地的zookeeper的服务:
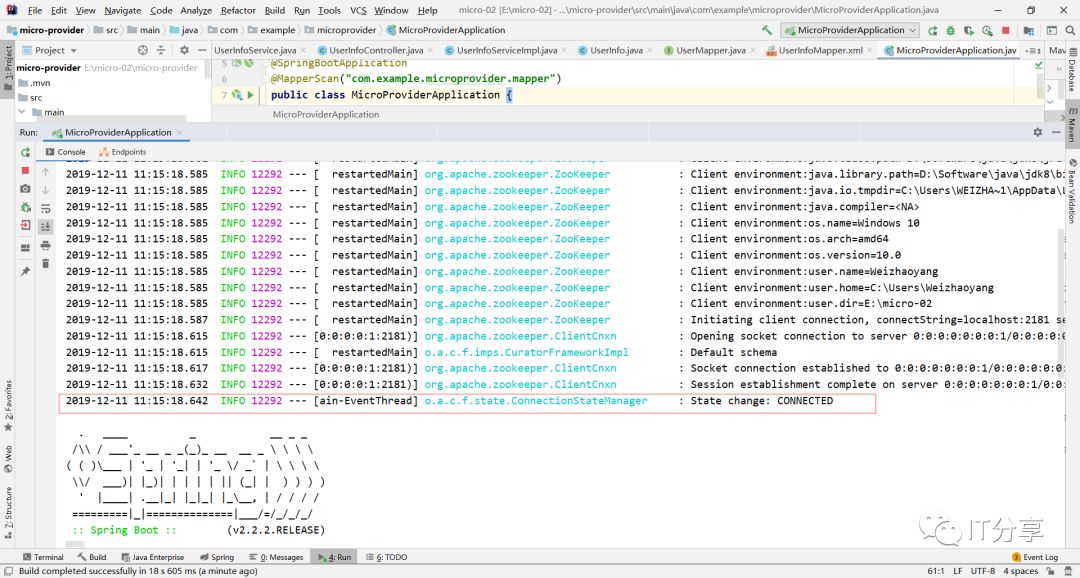
2.7:然后运行启动类/主类:
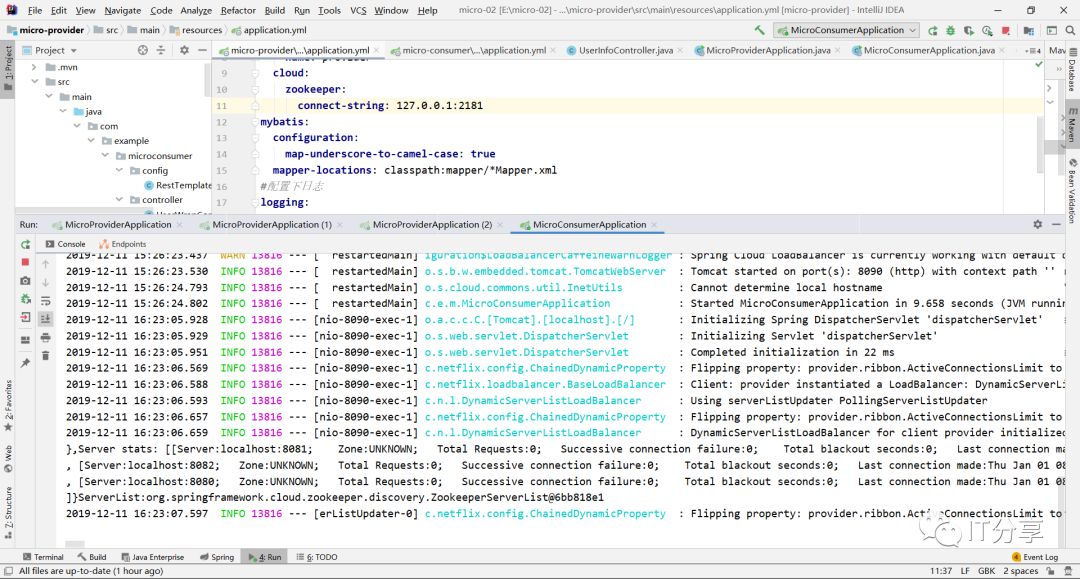
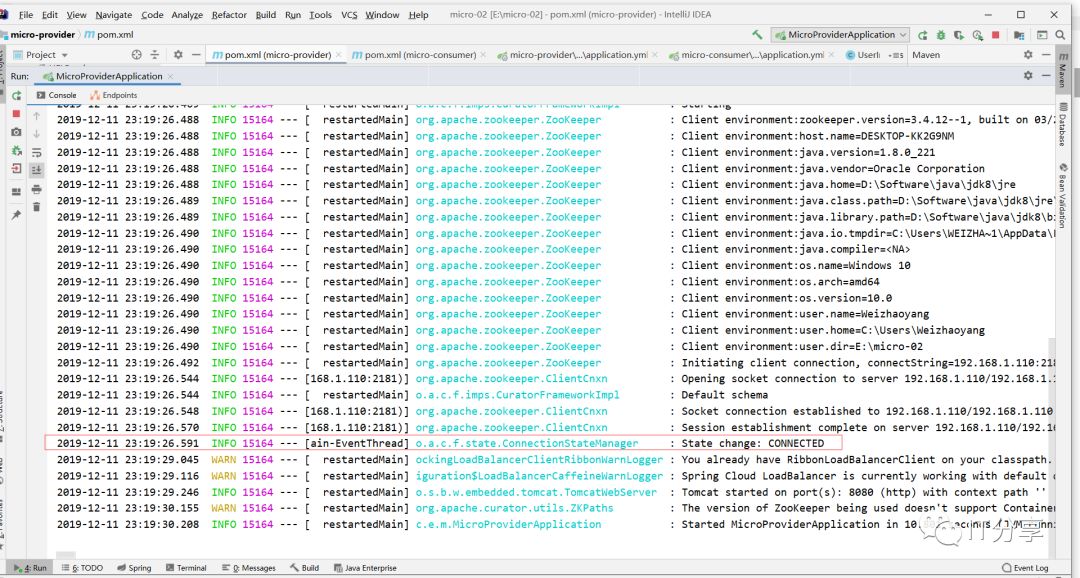
这句话代表连上了zookeeper。然后我们把数据注册到zookeeper里面去。到现在已经注册成功了。
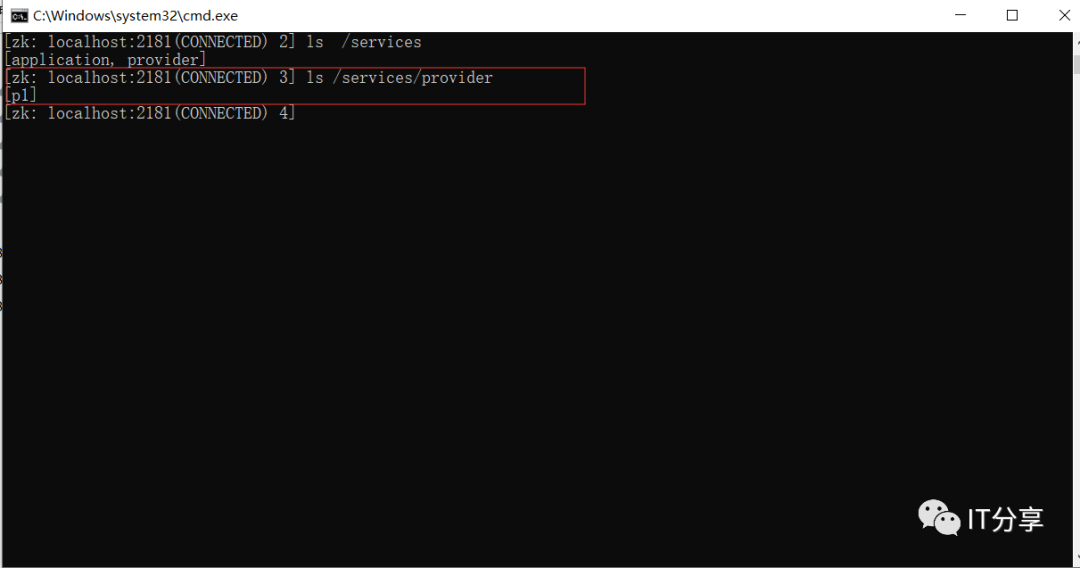
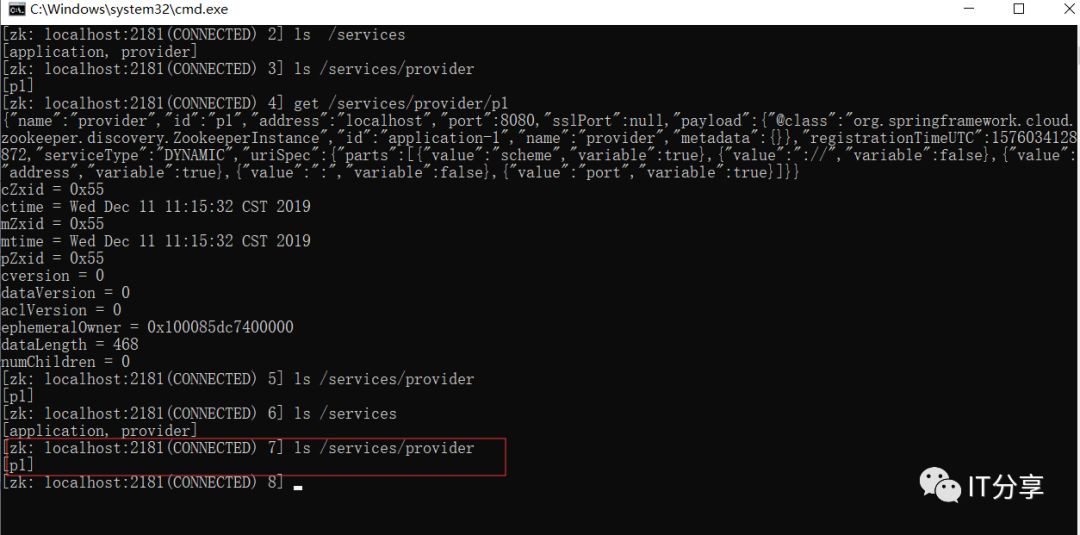
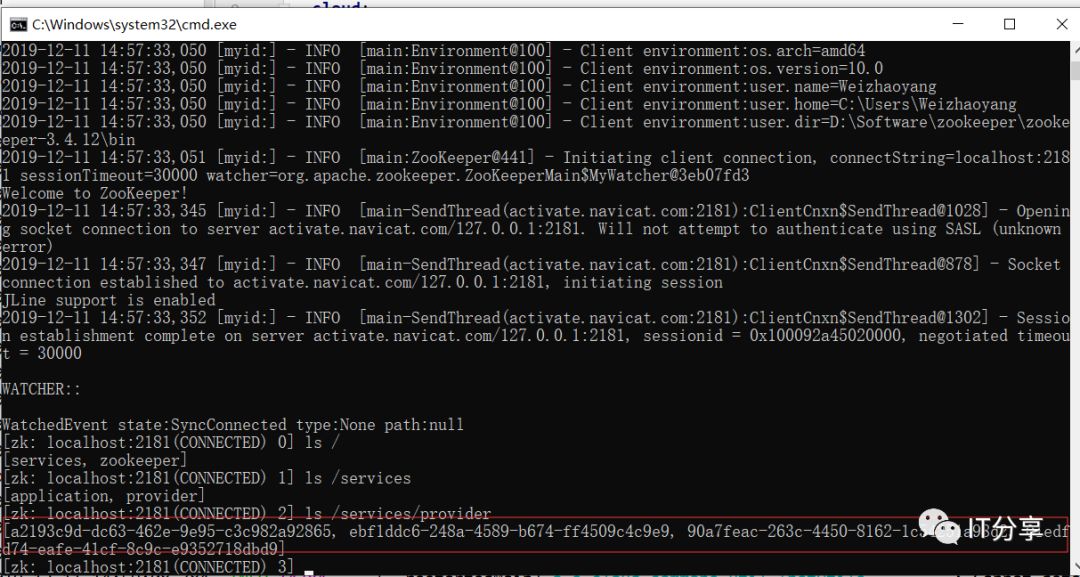
2.8:启动客户端zookeeper:上次是这里查到的是一串临时的服务列表,而现在变成了p1。p1就是为这个生成的实例的节点生成的名字。
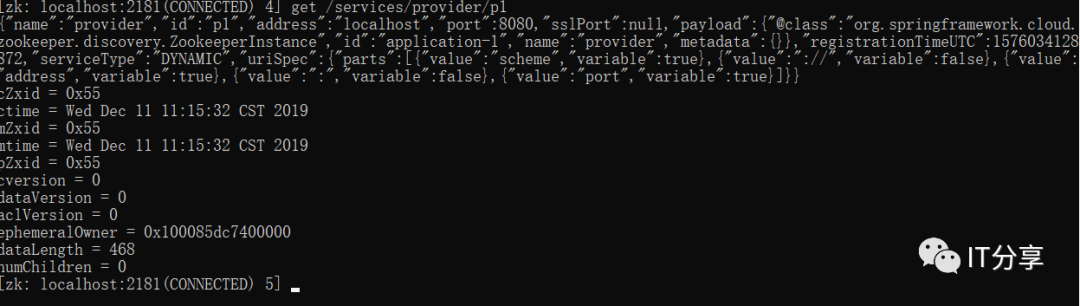
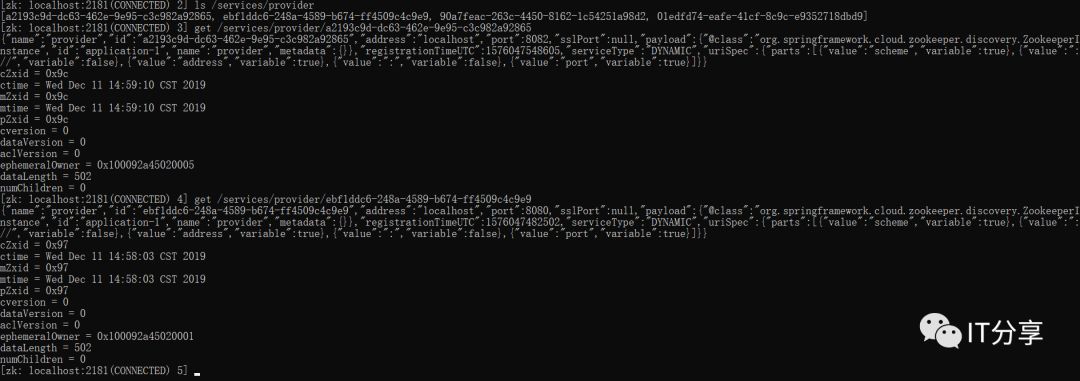
看下p1里面的内容:上次的id是原有的一段UUID,而这里变成成了p1,这个实例的名称是不能重复的,现在为了看到它,所以暂时取了这个名字p1,但是在开发中,如果定义了这个名字,这个名字必须要有约定的,通常这个名字是以当前的项目名称作为包路径的后缀,也就是包的名字+项目的名字来命名,否则这里就会出现问题,就会重名。应用服务名称还是provider。address为localhost。
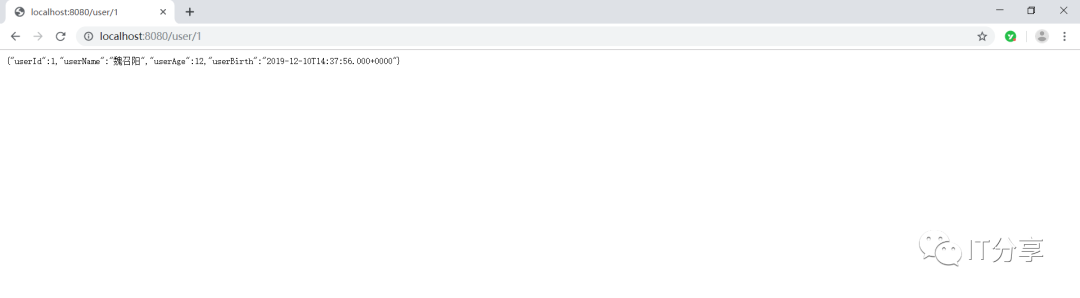
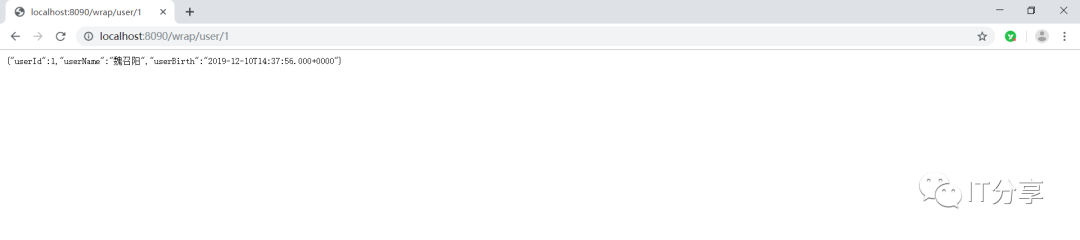
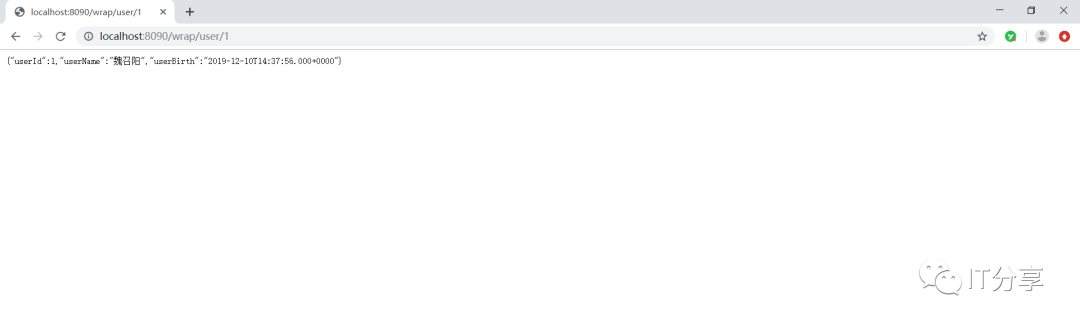
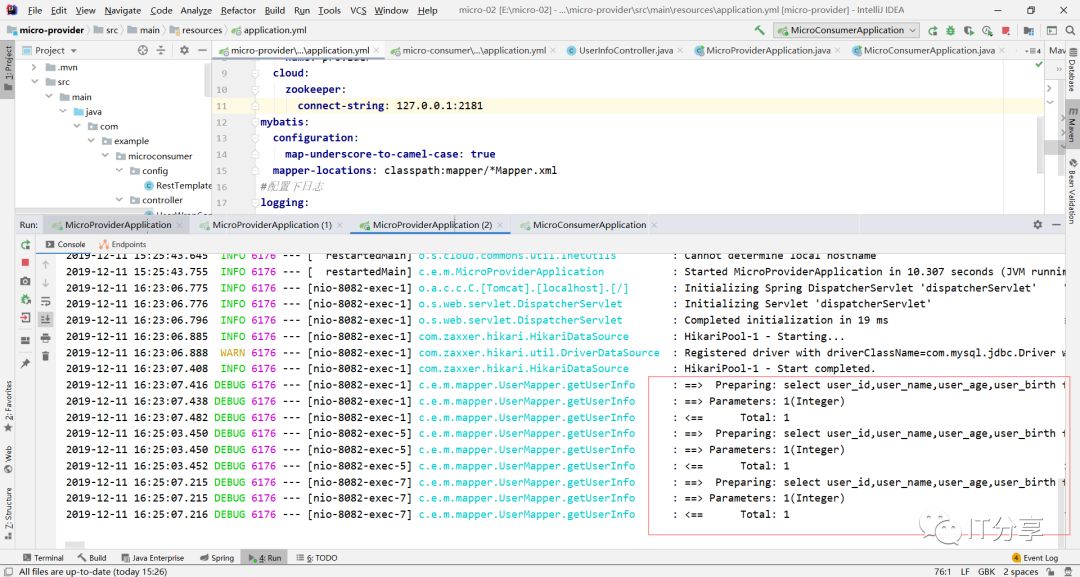
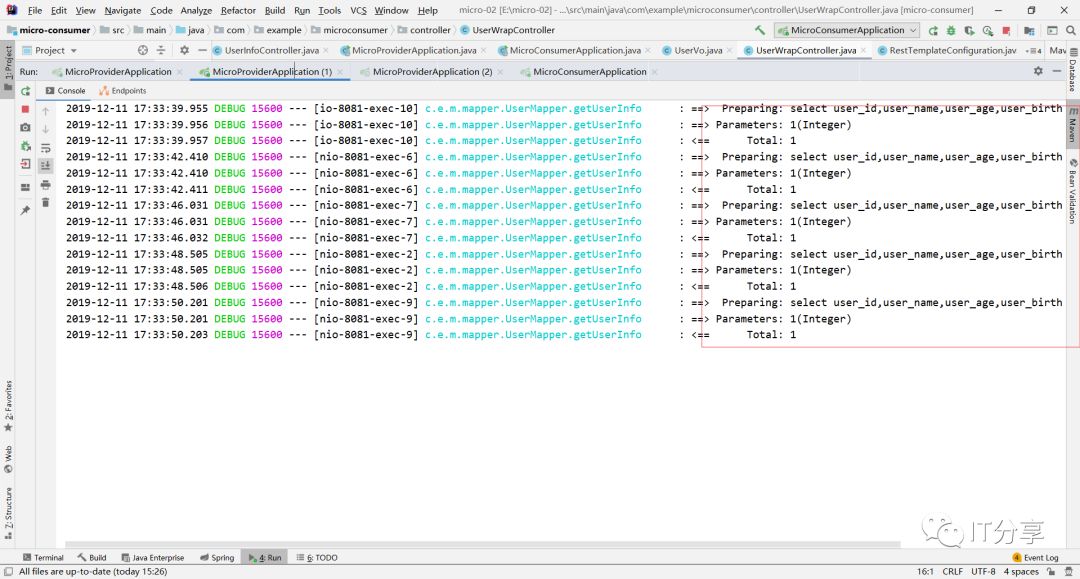
2.9:现在访问下:可以把数据提取出来是没有问题的,这就是一个json的字符串。
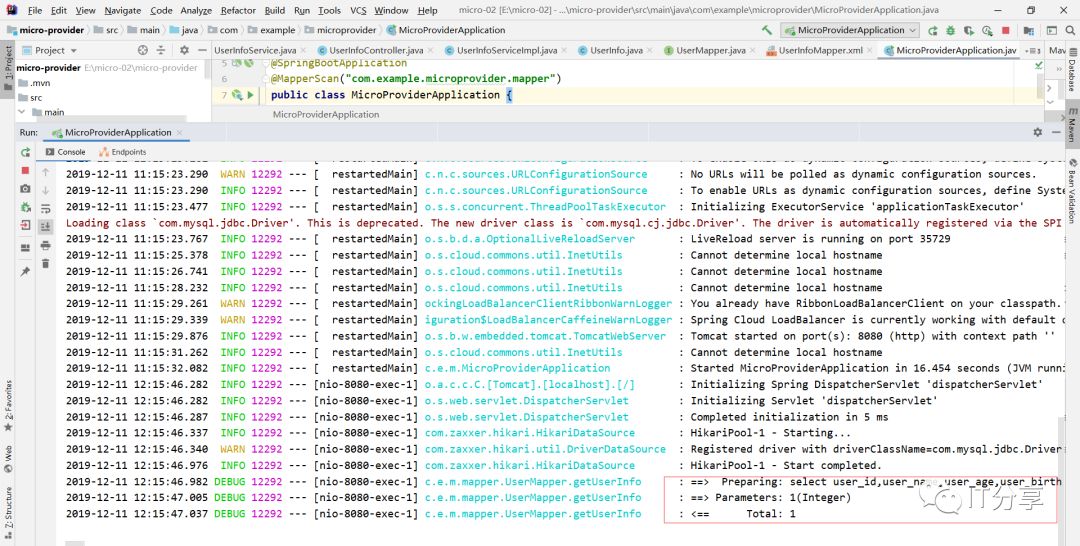
这里也有对应的sql语句,说明刚刚的配置是没有问题的,这就相当于独立部署的微服务。
那么这个微服务是如何去调用呢?新建一个服务的消费端:
1.1:消费端的暂时依赖是web:
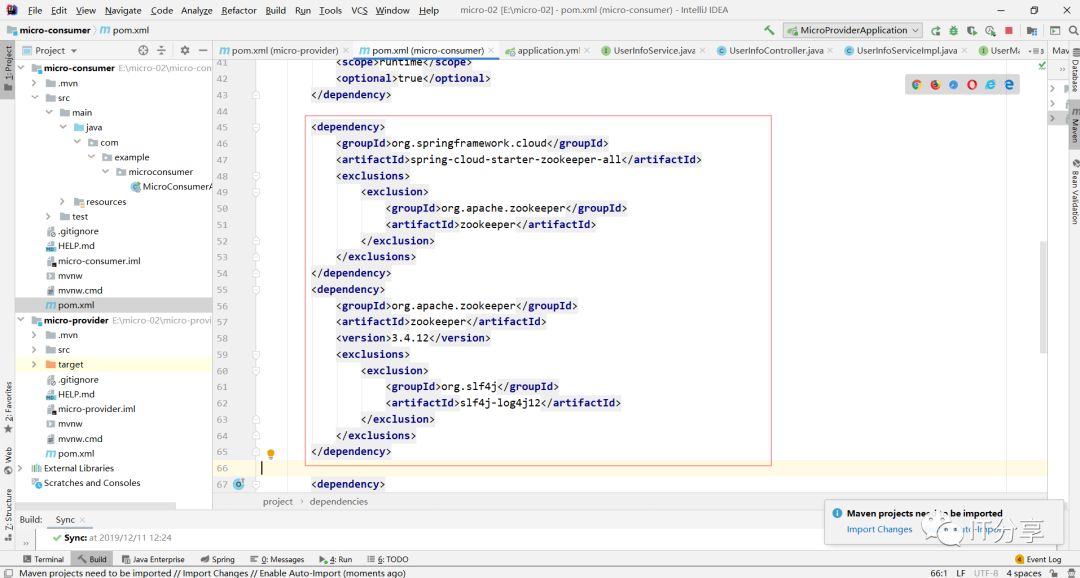
1.2:把zookeeper对应的依赖引进来,这里需要配置一个常量。
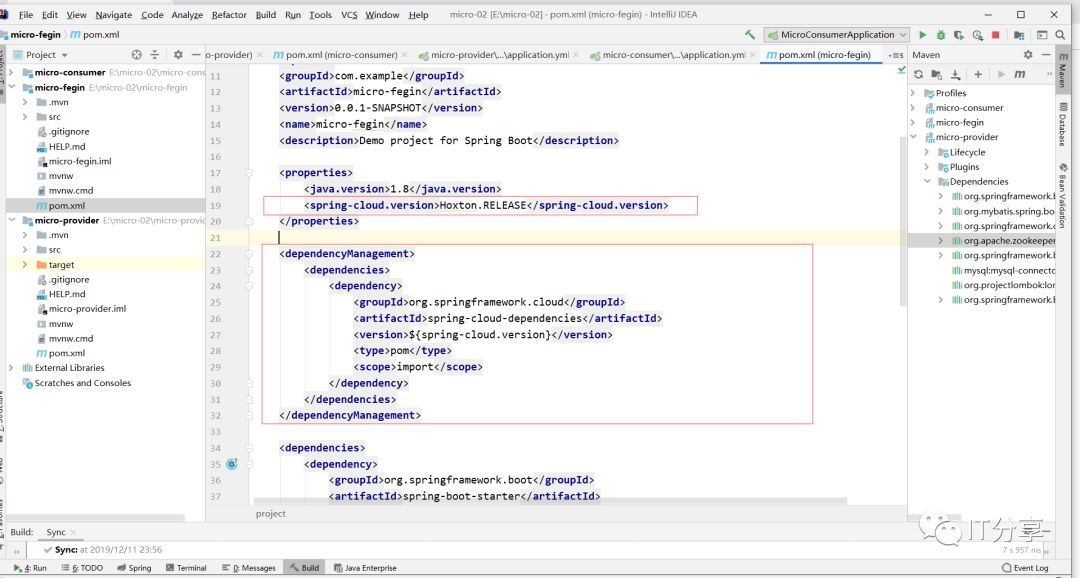
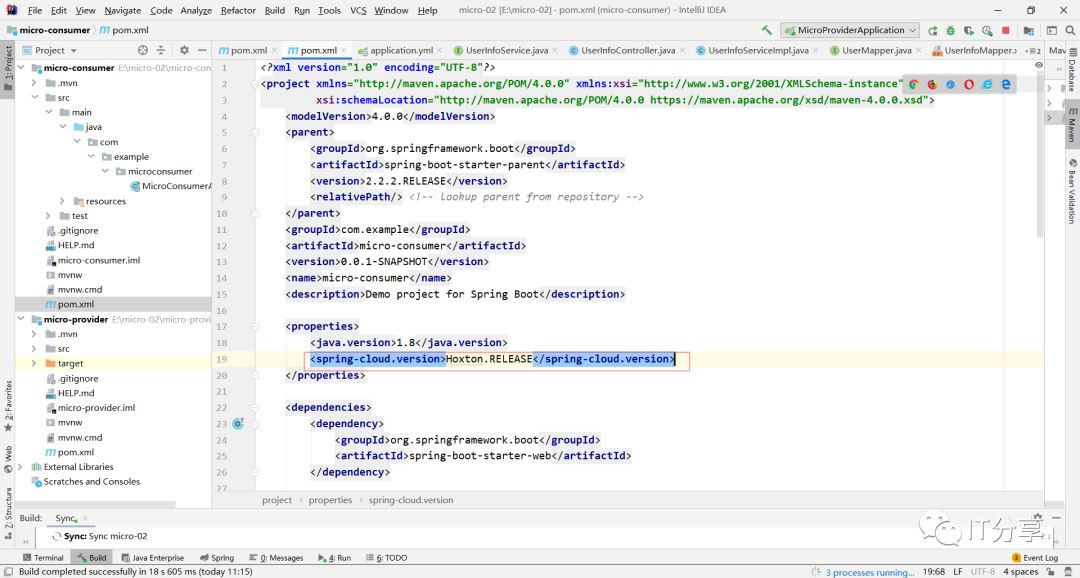
1.3:在把cloud的版本依赖管理加进来:
1.4:在把zookeeepr的依赖引进来,这时的消费端也差不多就搞定了。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>复制
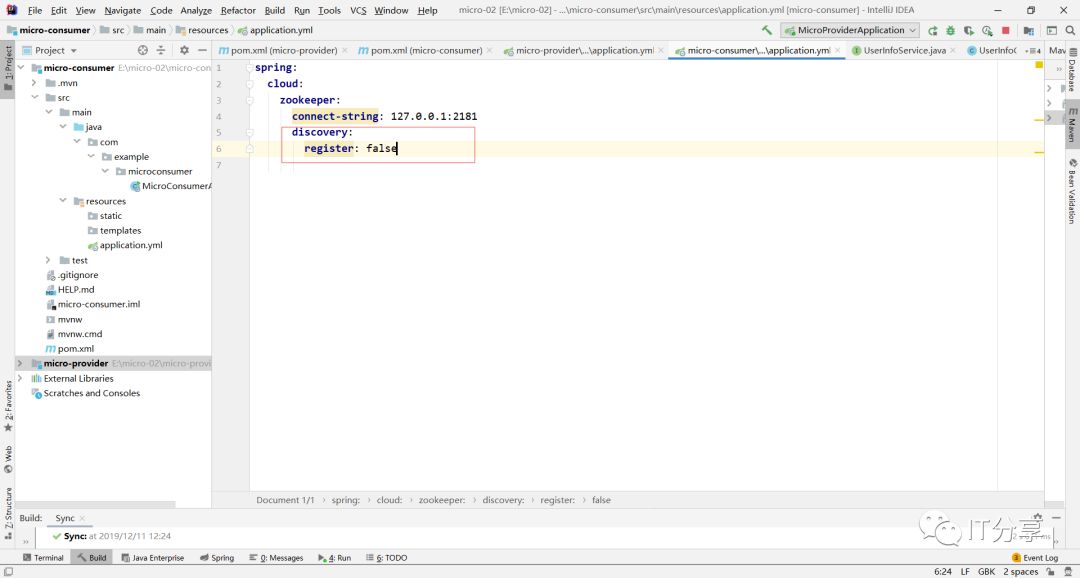
我们所有的客户端是从注册中心的上面去拉取数据的,而不是直接的去调用,所以在配置文件中需要配置,先配置zookeeeper的配置。
消费端没有必要把服务注册成服务,所以为false,默认是true的。
1.5:在客户端调用的时候,需要发现服务列表,所以这里需要加上相应得注解,服务发现得客户端。
1.6:这个消费端就作为前端得服务提供者,提供一个实体类:
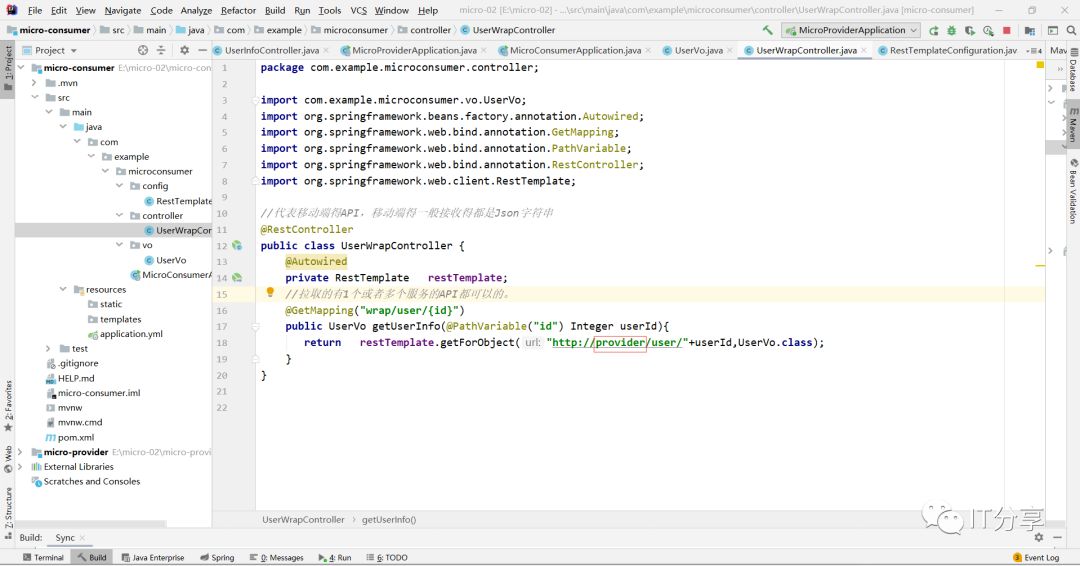
1.7:最终我们把拉取过来得数据变成上面得vo,需要建个Controller,用RestTemplate来通信,在Spring容器中需要装配这个对象进去。
package com.example.microconsumer.vo;
import lombok.Getter;
import lombok.Setter;
import java.util.Date;
//返回三个结果给客户端
@Getter
@Setter
public class UserVo {
private Integer userId;
private String userName;
private Date userBirth;
}复制
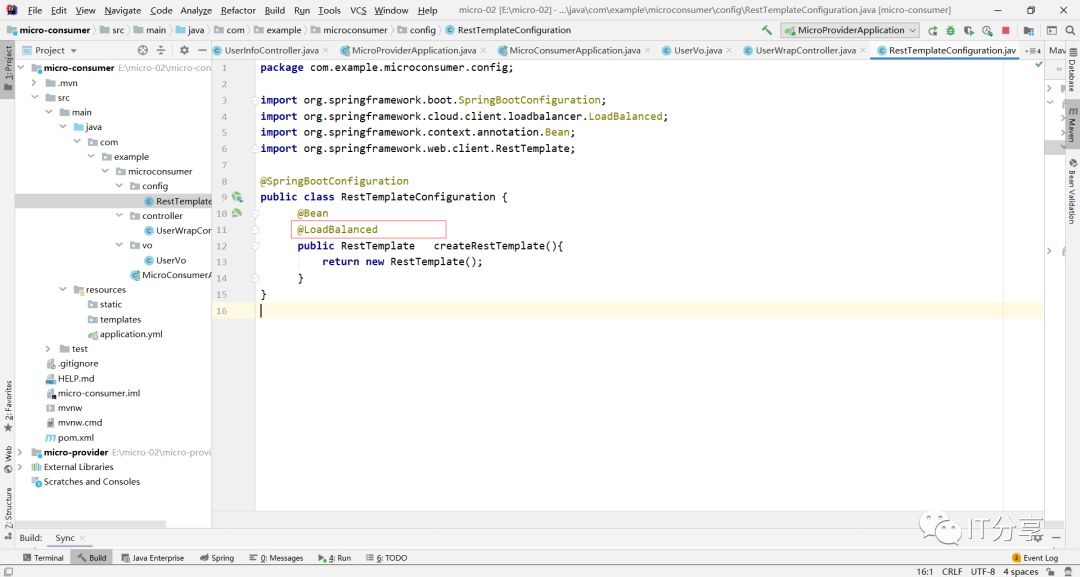
package com.example.microconsumer.config;
import org.springframework.boot.SpringBootConfiguration;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@SpringBootConfiguration
public class RestTemplateConfiguration {
@Bean
@LoadBalanced
public RestTemplate createRestTemplate(){
return new RestTemplate();
}
}复制
1.8:最终是消费端是从zookeeper上拉取服务列表得,这个url中的ip地址和端口号可以用服务名称provider替代。
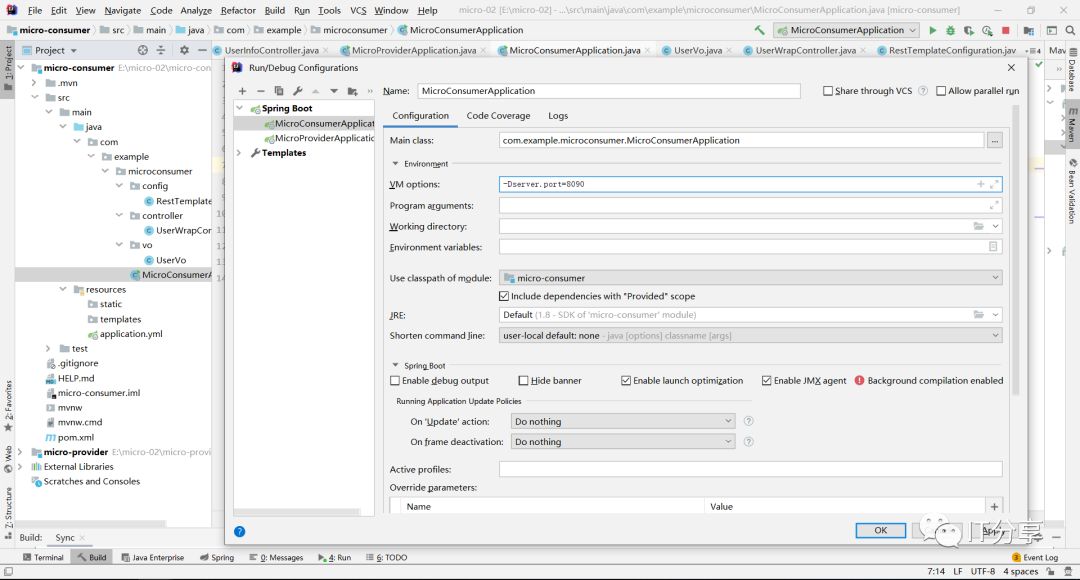
1.9:改下消费端的服务端口:一般我们不会在配置的文件中配置端口的,一般会在启动的时候vm里配置端口的,因为微服务和其他 的服务是不一样的
2.0:然后测试一波:
这就部署起来了。访问下也是可以的。
2.1:如果有多个服务列表的话,相当于我这里部署了多个提供服务的服务实例,就是一个微服务部署了多个实例出来:我这里部署三个微服务实例:
2.2:然后同时启动下服务端的服务:
2.3:客户端的zookeeper登录进去:
2.4:服务列表还是p1,说明刚刚部署的东西被覆盖掉了。所以说discovery instance-id:不是随便写的,一般要写的话是有约定的,不是随便写的,部署的时候,这里可以不写。
2.5:然后把所有的服务停下,再重新部署下:一个服务部署了三个微服务实例,但是这三个服务实例时同一个服务,是同一个名称。说明在名称为provider的节点下面创建了三个同节点的三个微服务实例。并且服务实例的名称没有指定,说明名称是由UUID生成的。这里就有三个服务的列表
这个时侯的id就是随机的,是让系统来起的名字。
服务实例与服务实例之间这时端口号是不一样的,ip地址是一样的。
如果三个服务的名称不一样的话,配置文件里写哪个服务,就调用哪个。
现在启动客户端:
浏览器请求刷新9次:
提供服务得服务端自动会实现负载均衡的。
2.6:如果当某台机器宕机之后的话,某一台服务实例如果宕机的话:
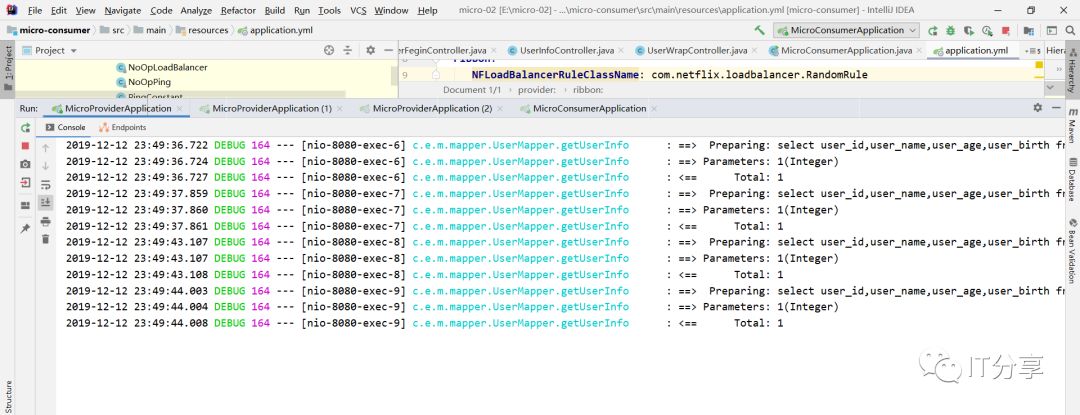
例如把provider-2宕机的话,这时只有两台机器了,现在我再去调用得话会不会当访问第三台机器得话,它会不会把这个请求给忽略了呢?
2.7:第三台机器宕机得话:第一台和第二台还会处理消费端得请求得:第一台处理得请求有4次,第二台机器处理得请求有5次。可以成功得切换得。
可能宕机得时候立刻访问得时候会报错,因为时间没有切换过来。只要时间切换过来就行了,他是可以自动切换了。它是保证高可用得。所以说在SpringCloud当中,做服务端得负载均衡得话高可用得配置是很简单得,它就自己做了高可用得,宕机一台,其他两台一样可以做也可以在负载均衡得策略。
一开始说上次讲的内容有问题:现在呈现给大家:
在本地有一个zookeeper,上面的方法是可以成功的把服务注册上去的,但是一旦不用本机的话,服务就会注册不上去的。现在把本机的zookeeper关掉,换成服务器上的zookeeper。启动zookeeper的服务:相当于这个是远程上的zookeeper,现在我是想把这个提供的服务注册到远程的zookeeper上去。启动虚拟机里的zookeeper:
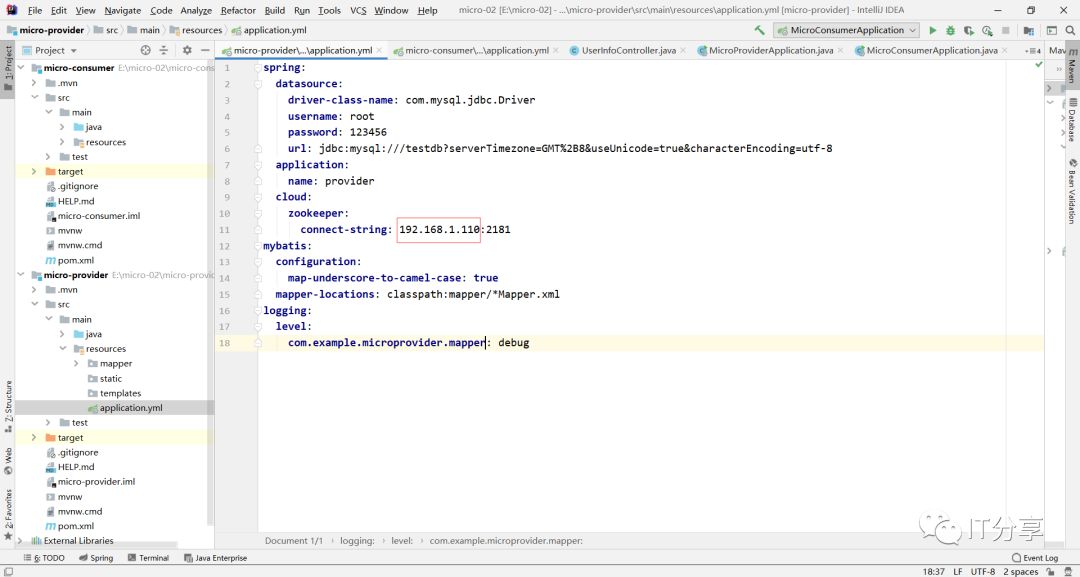
1.1:对应的提供的服务修改下IP地址
1.2:现在看服务端能否注册到zookeeper上去呢?重新启动下服务端
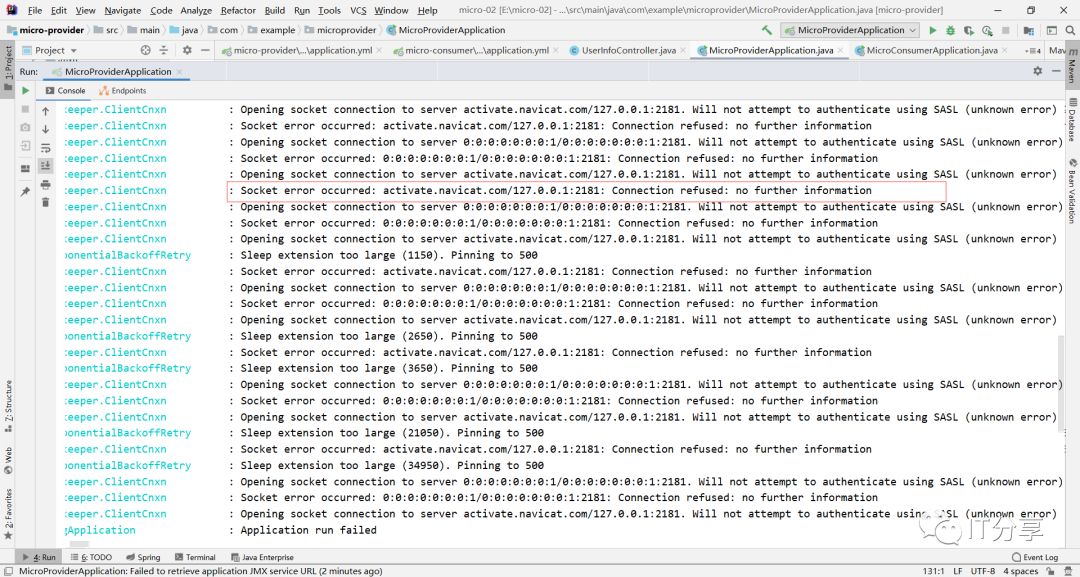
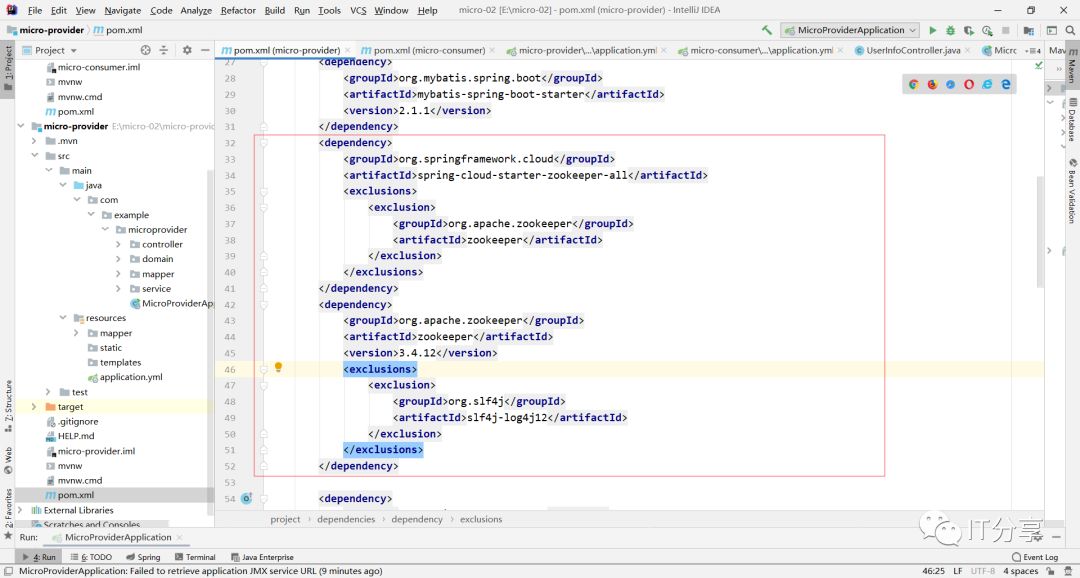
这里在不停的连127.0.0.1,然后紧接着就会报错,说明上种的方式只能连本机,本机用是没有问题的,初学者的话会根据一些网上其他的资料查看演示一下就注册上去了,然后就行了,但是有的时候真实的环境的时候,不能注册到本地的,所以说这样是不行的。因为这是做的是zookeeper的配置的依赖,做的不是服务的发现的依赖,就相当于可以把这些信息写到zookeeper里面去。
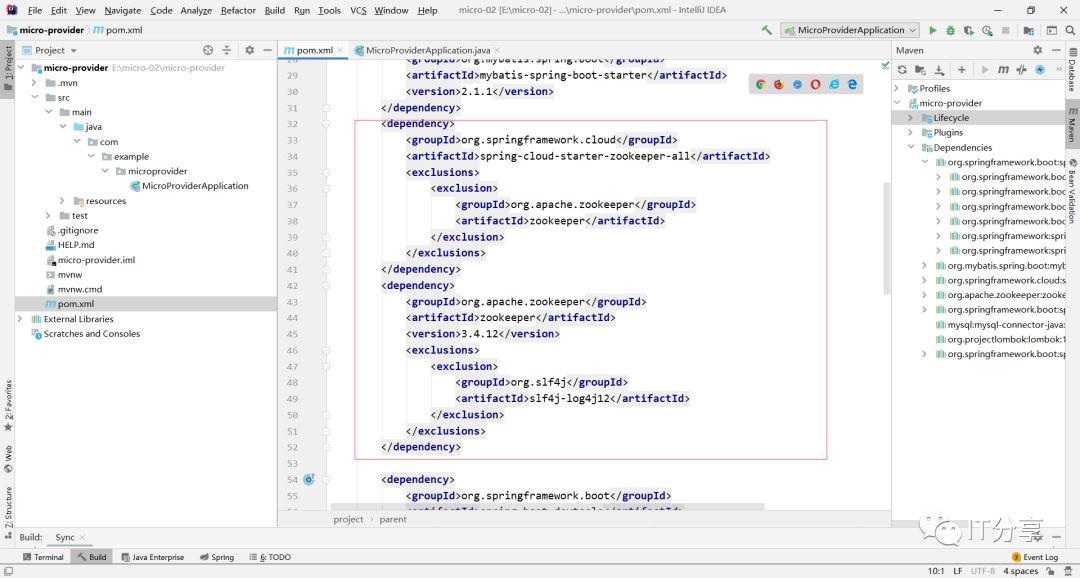
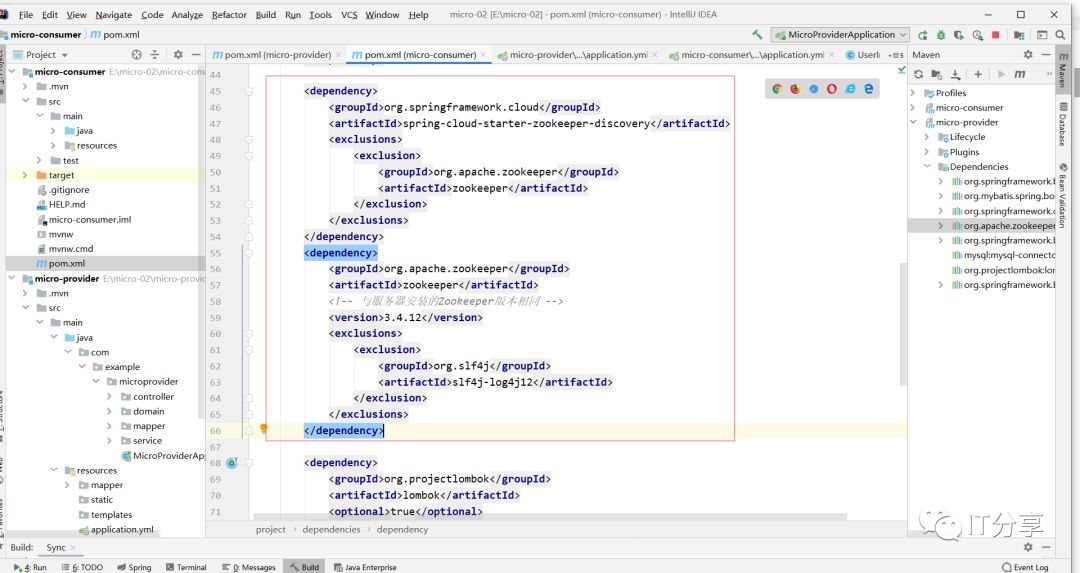
下面只是做了zookeeper的配置,这种配置只能连接本地的。而没有做了服务发现的配置。服务发现的依赖:
1.3:换成服务发现的依赖:
然后再来启动下服务端的服务:这就注册上去了。引入这个依赖在本地注册也是ok
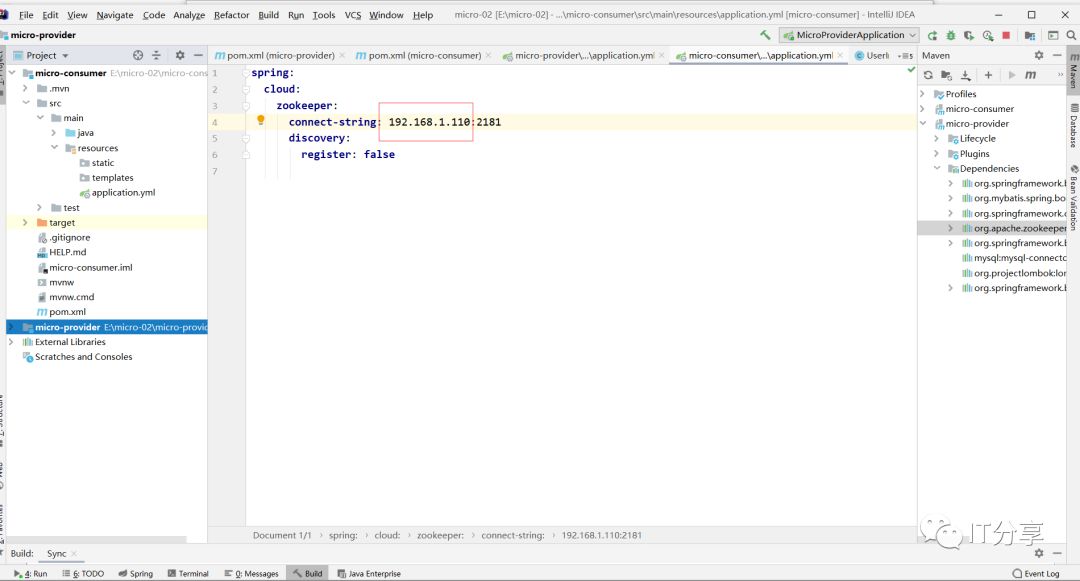
1.4:消费端也是一样的,也是和服务端提供的服务的配置也是一模一样的
最终拉取得服务列表是从这个ip里面拉取:
然后启动下消费端,看能否正常驱动:驱动成功了,请求也是可以的。
1.5:除了上面得方式以外还可以用什么方式来做负载均衡呢?还可以用Fegin框架来做负载均衡。
假如说在Controller中有100个RestAPI,看起来是非常的痛苦的,比如说在Controller中的方法中有间面上的逻辑处理的话。Controller中只知道调用接口就行了,不需要知道调用接口中的哪一个方法。以前的方法是通过路径就很容易找到访问地址,这样的是不安全的,在开发中这样地址不是很容易就暴漏出去的。而是换种方式给它暴漏出来,而且这个框架更系统化的可以把RestApi统一的管理起来,而不是通过Controller的方式给我们提供RestAPI。原有得方式是由Controller暴漏出得API。Fegin是把暴漏出得服务接口统一得管理,就是一个简易版的WebService调用。服务端提供的RestAPI由Fegin框架去调用,然后Fegin框架做了一层封装之后,然后这个Fegin部署了另一台机器上去了,然后由客户端去应用。相当于就是做了一个路由的效果,做统一的管理/维护,也是为了安全而考虑的。其实不管怎么玩,大多是都是这么玩的,其实就是为了屏蔽直接去拿服务端的IP地址。
有点类似网关,但是和网关有一定的区别。



Fegin框架的学习:
1:fegin框架是客户端的调用框架。
2:如何去开启一个fegin呢?
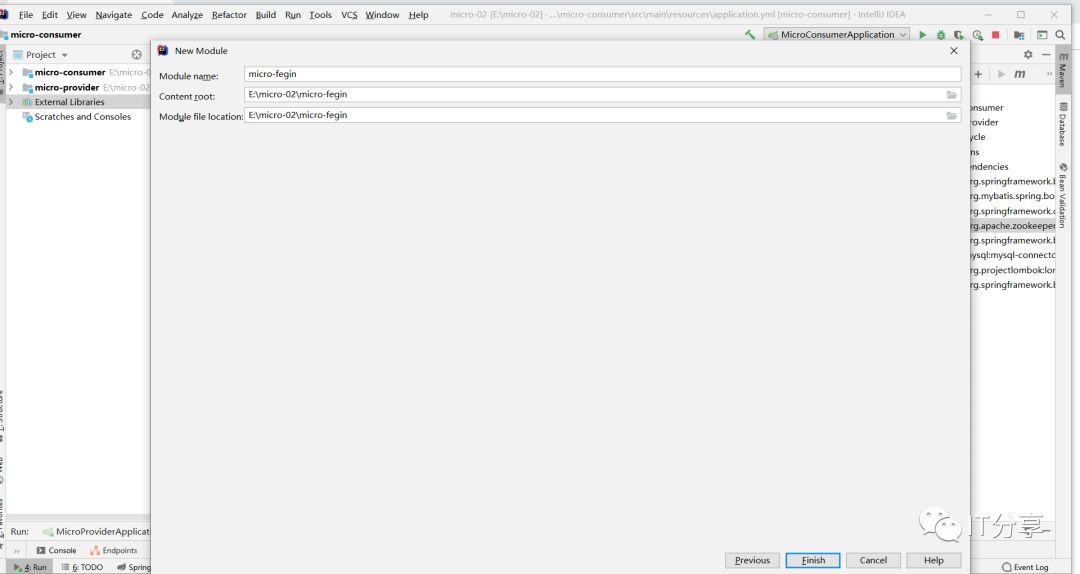
首先创建一个fegin模块得SpringBoot项目:
1.1:加入相关的依赖:
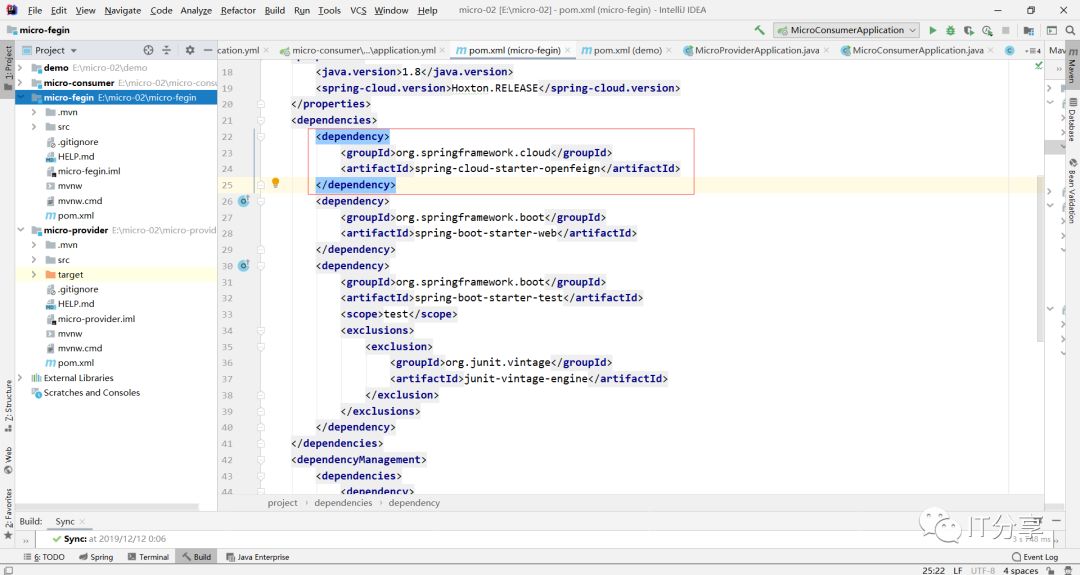
1.2:引入Fegin框架:
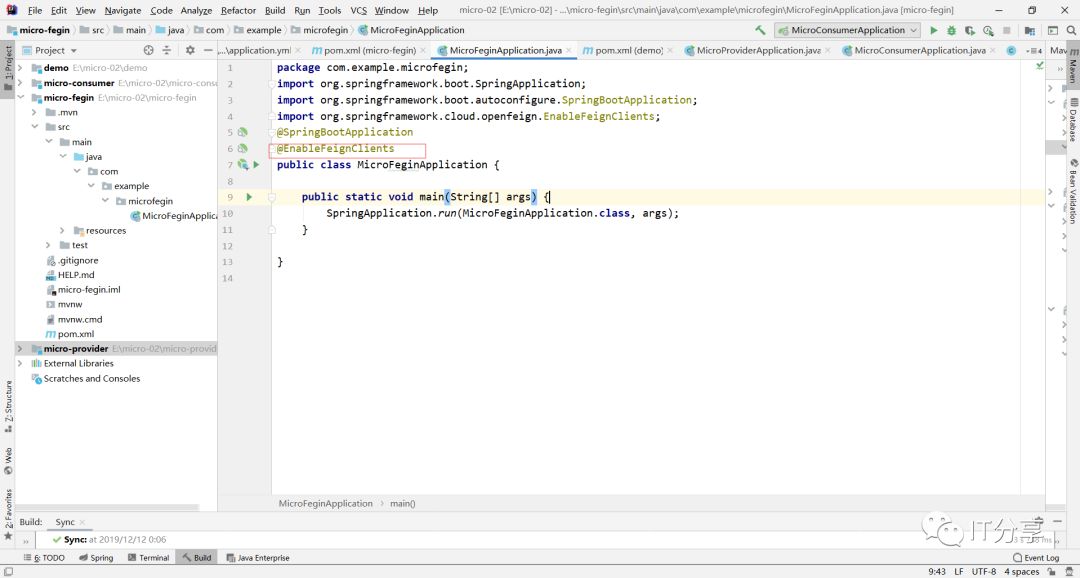
1.3:加一个启动Fegin服务端的注解。
1.4:在这里不需要做任何的配置。
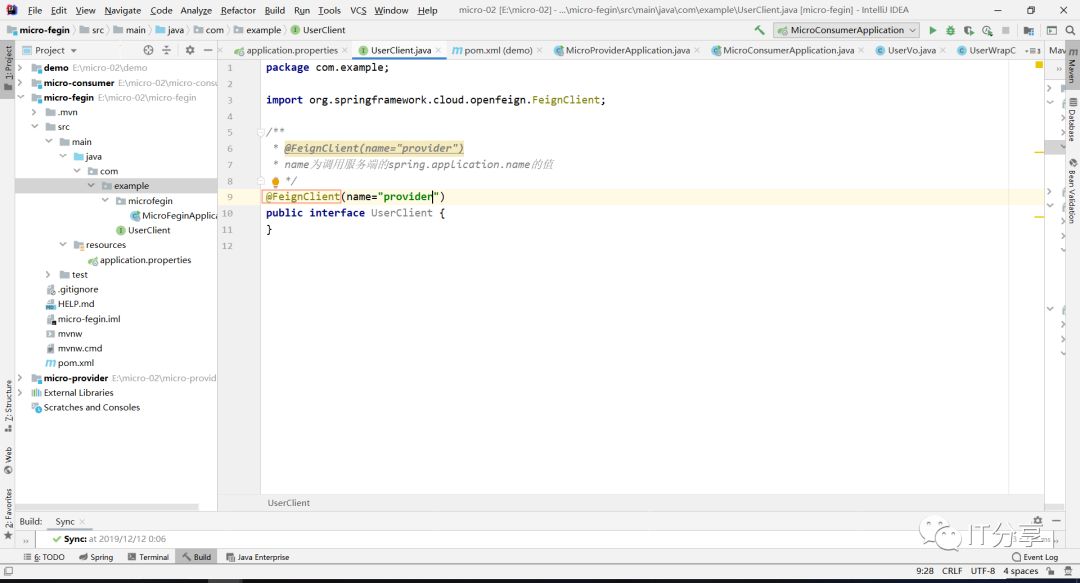
1.5:由于客户端去调用它 ,所以在Fegin端提供对应的接口才行:@FeignClient,启动Fegin客户端的注解。
1.6:提供对应的接口的方法,地址rute/user/{id}->才是真正调用服务的地址,这个地址必须和服务端端提供的RestAPI地址完全一样,但是和消费端 的访问的RestAPI的地址不需要一样。
package com.example.microconsumer.client;
import com.example.microconsumer.vo.UserVo;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
/**
* @FeignClient(name="provider")
* name为调用服务端的spring.application.name的值
* */
@FeignClient(name="provider")
public interface UserClient {
@GetMapping("user/{id}")
public UserVo getUserVo(@PathVariable("id") Integer userId);
}复制客户端对应的框架可以写很多个,有点类似于通用工具,所以可以把启动类给pass掉,配置文件application.properties也不需要,因为它是一个客户端的调用框架。
如何去和Fegin进行通信呢?现在想要调用的就是UserClient的这个接口给consumer消费端用
这里可以把cloud-fegin直接依赖到cloud-consumer的模块里面去。
1.7:在消费端的启动类上加一个注解@EnableFeignClients去启用服务端的Fegin。
1.8:写对应的UserFeginController,把接口注入进来。UserClient得接口也是用实现类来注入到Spring容器中得。UserClient接口中加了@FeginClient(name="provider")得注解:就是客户端调用得RestAPI得管理得路由。而在UserFeginController写了一个"fegins/user/{id}"这样一个得调用。用了UserClient去调用了接口里得getUserVo()得方法
而路由得真正调用得地址是接口中得@GetMapping中得地址,不用管这个地址改怎么写,不用管和UserFeginController中得地址是否一样,但是必须和服务端得提供服务得RestAPI得地址相同。他是把真正调用服务端得地址给屏蔽了。相当于通过UserFeignController中得userClient找到接口中得方法,通过这个方法去路由到真实得RestAPI,再去调用服务端所提供得服务。户端得调用框架Fegin里的路径是不能随便写得,必须通过provider映射出来得地址。
1.9:加上Fegin框架也是可以访问成功的。现在就是用Fegin框架做了一个路由。把服务端真实的地址给屏蔽了。这就是Fegin框架得调用过程。其实Fegin框架一样依赖了ribbon(UserClient),一样做了负载均衡。
package com.example.microconsumer.controller;
import com.example.microconsumer.vo.UserVo;
import com.example.microconsumer.client.UserClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class UserFeginController {
@Autowired
private UserClient UserClient;
@GetMapping("fegins/user/{id}")
public UserVo getUserInfo(@PathVariable("id") Integer userId){
return UserClient.getUserVo(userId);
}
}复制
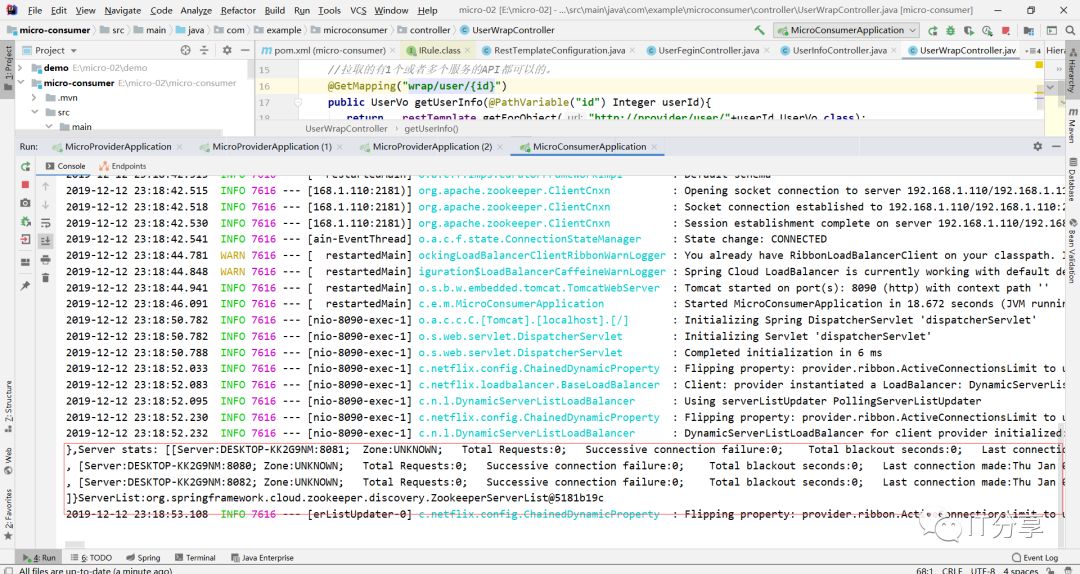
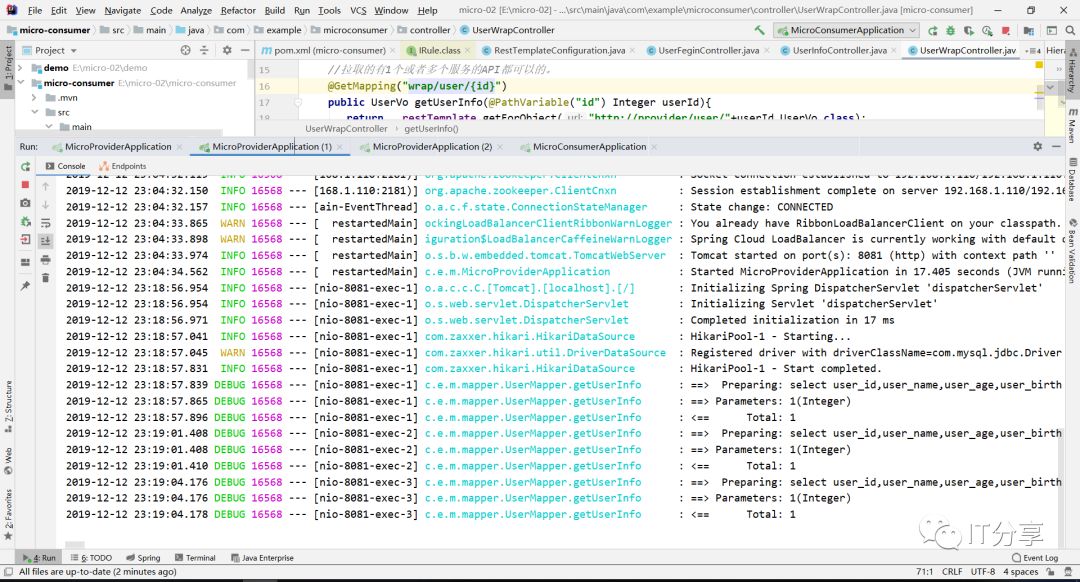
现在启动三台micro-provider
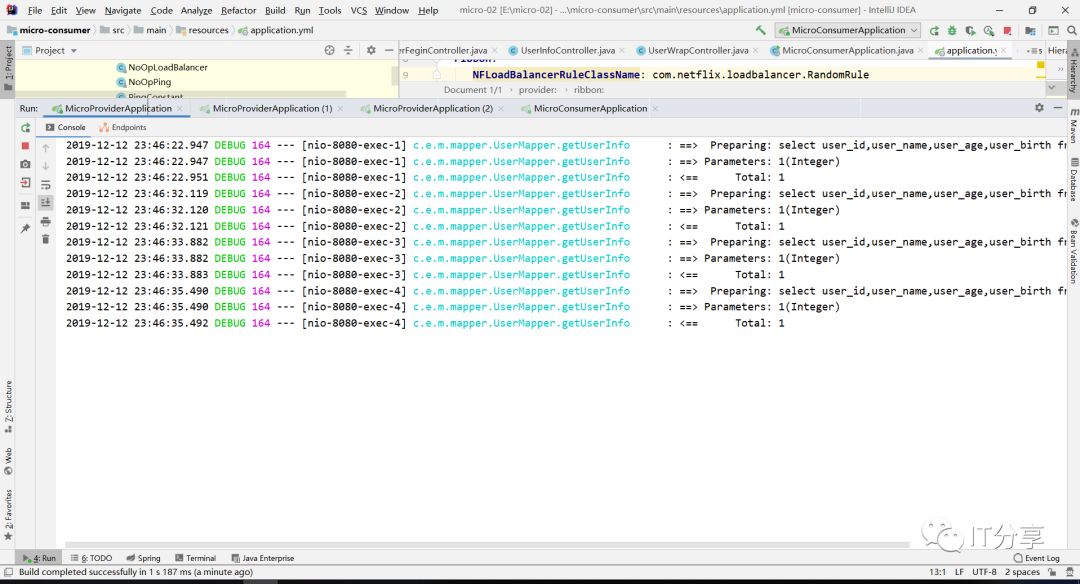
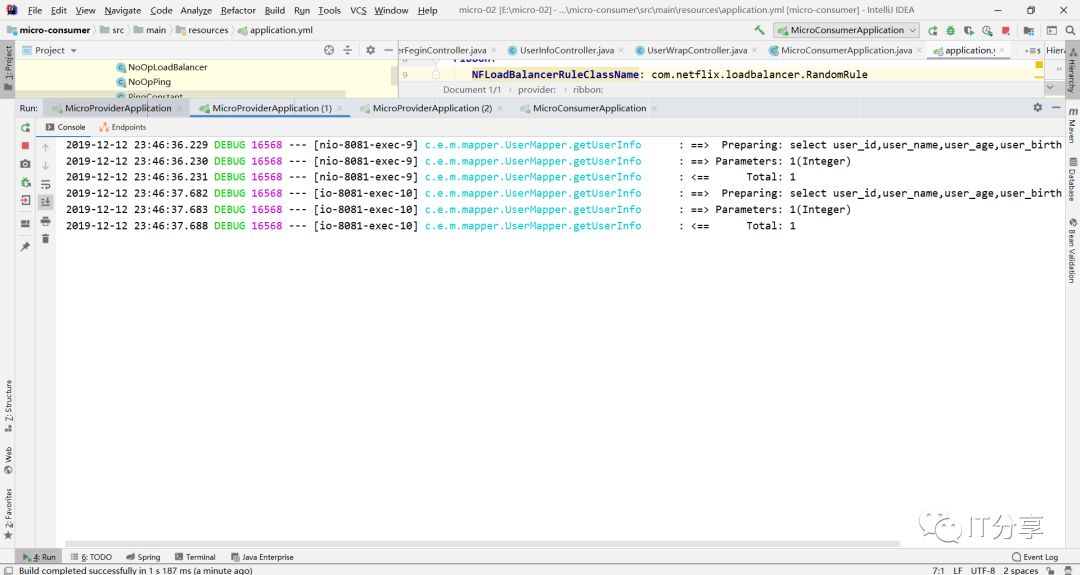
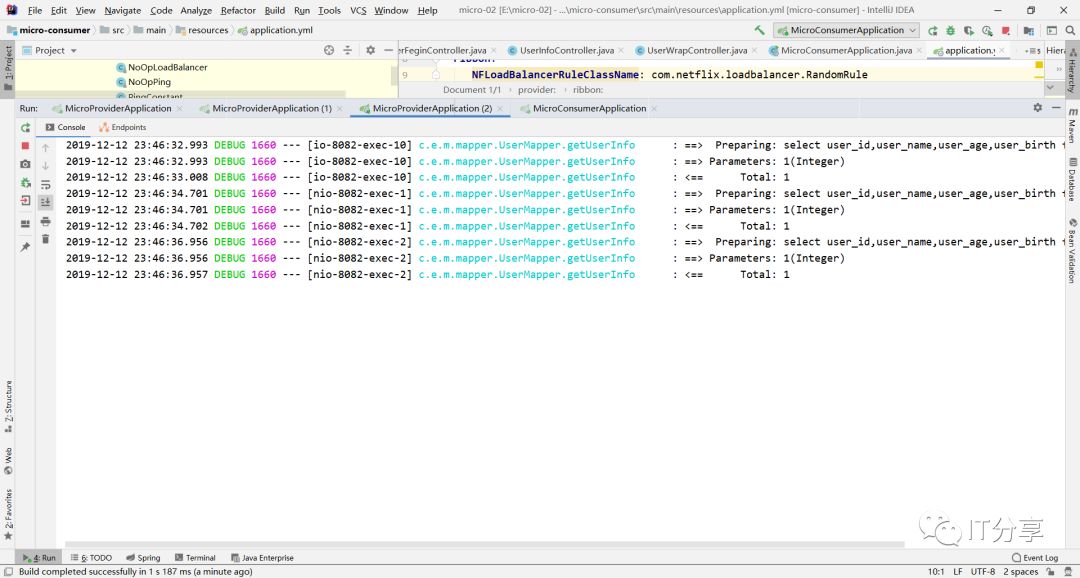
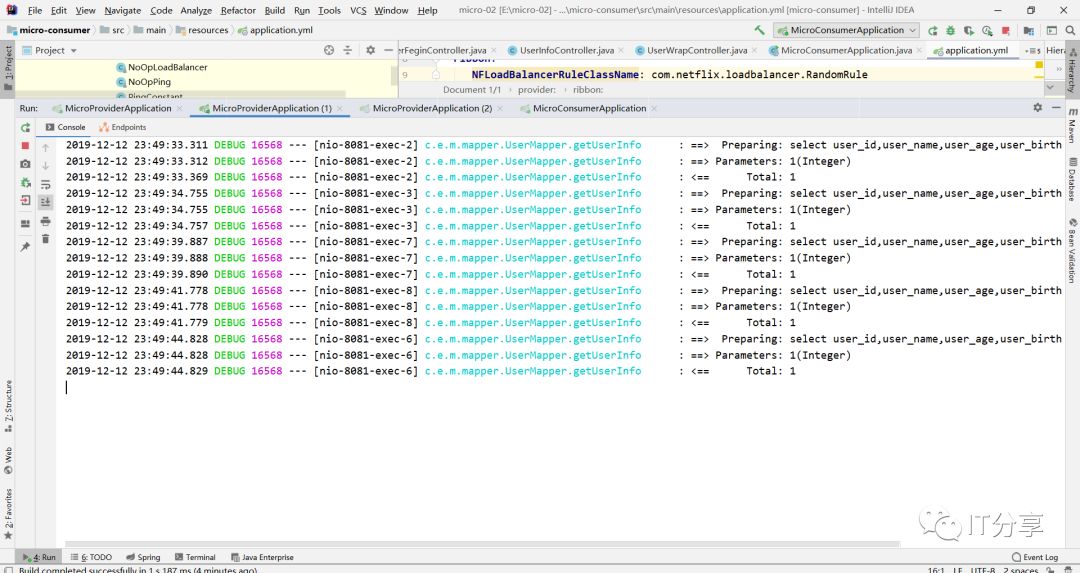
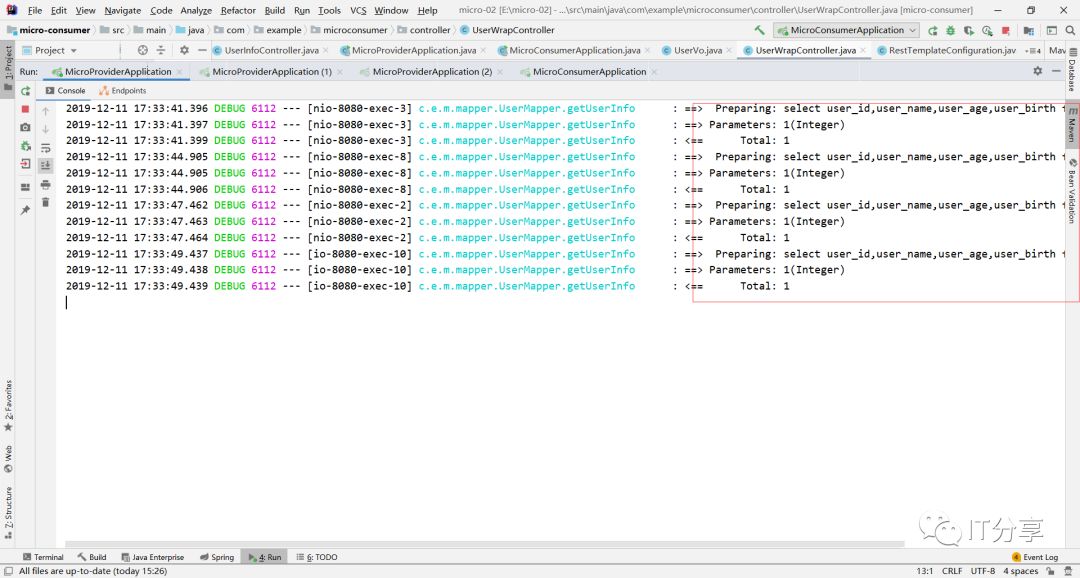
然后再启动消费端得服务,和让浏览器刷新访问9次消费端:可以看到它拉到三个服务列表
然后你在看下三个服务端的控制台,你会看到控制台分别打印出三条sql。
这里就有相应得负载均衡,每台机器都有相应得命中。
负载均衡怎么设置得呢?,来看下内部的原理,查看下源码IRule这个接口:
这个接口的里面有对应的实现类,在实现类中有对应的负载均衡的策略:
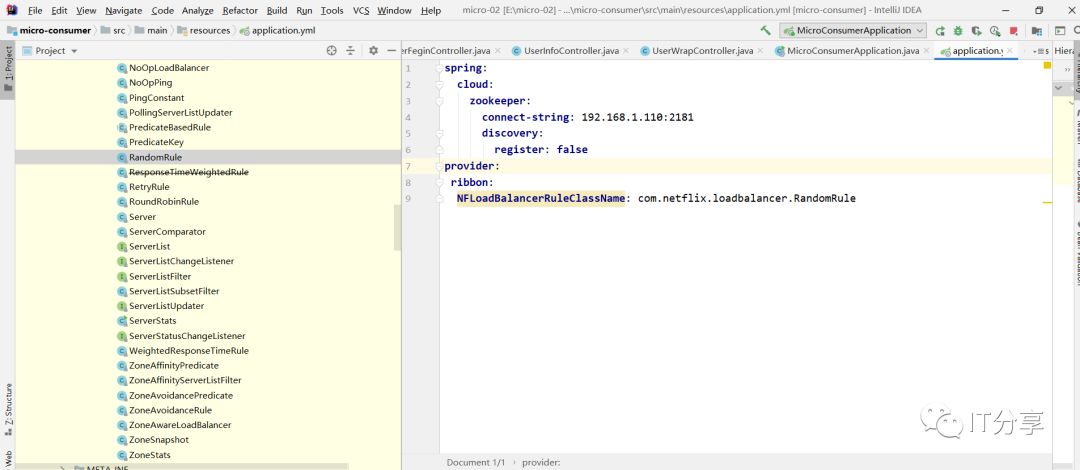
2.0:换成随机得策略:provider代表服务得名称。
2.1:再次得启动下消费端:然后再刷新浏览器访问九次消费端consumer
2.2:这就说明负载均衡得策略被改变了。现在宕机一台得话:也是保证高可用的。
总结:其实fegin框架主要得作用就是路由得效果,也能自动得实现了负载均衡。现在得负载均衡可以自定义得。去实现IRule接口。
或者继承AbstractLoadBalancerRule也是ok得。Fegin框架得核心其实还是Ribbon,但是再这里根本没有引入Ribbon框架。引入了Fegin其实就把Ribbon得一些依赖引入进来。Ribbon框架可以做负载均衡,也能做客户端得调用,也能做数据得传输。针对服务间得通信及其它自带得高可用,负载均衡做了一些讲解。
下次 分享SpringCloud config/bus······· 希望 大家继续关注:
如果想要代码的请加qq群:797853299