




MIT 6.824: Distributed Systems Spring,涉及到分布式系统相关知识,能学到不少干货,之前看过设计数据密集型应用一书,很多内容和思想较为全面,6.824课程中涉及到的基本都是核心知识点,课程中的 4 个 labs 是真的值得花时间设计和实现一下,对学习分布式一定会有很大收获。我会慢慢跟进,把过程中有意思的部分整理成文发到博客中。
What is 6.824 about?
6.824 is a core 12-unit graduate subject with lectures, readings, programming labs, an optional project, a mid-term exam, and a final exam. It will present abstractions and implementation techniques for engineering distributed systems. Major topics include fault tolerance, replication, and consistency. Much of the class consists of studying and discussing case studies of distributed systems.
Prerequisites: 6.004 and one of 6.033 or 6.828, or equivalent. Substantial programming experience will be helpful for the lab assignments.
Lecture interoduction
Quick Preview
parrlelism
fault-tolerant
physical
secvrits / isolated
Challenges
challenges
partial failure
performance
Course Structure
lab1 - MapReduce
lab2 - Raft fault-tolerant
lab3 - k/v server
lab4 - sharded k/v server
比如:
mapreduce paper
lectures
papers - 每周一篇 paper
examples
labs
project (optional)
Infrastructure abstractions
Storage
Comms
computer
Impl
RPC、Threads、consistency
Performance
scalability - 2X computers -> 2X throughput
fault-tolerant
availability | Non-volatile storage
recoverability | Replication
Topic - consistency
Put(k,v)
Get(K) -> v
examples
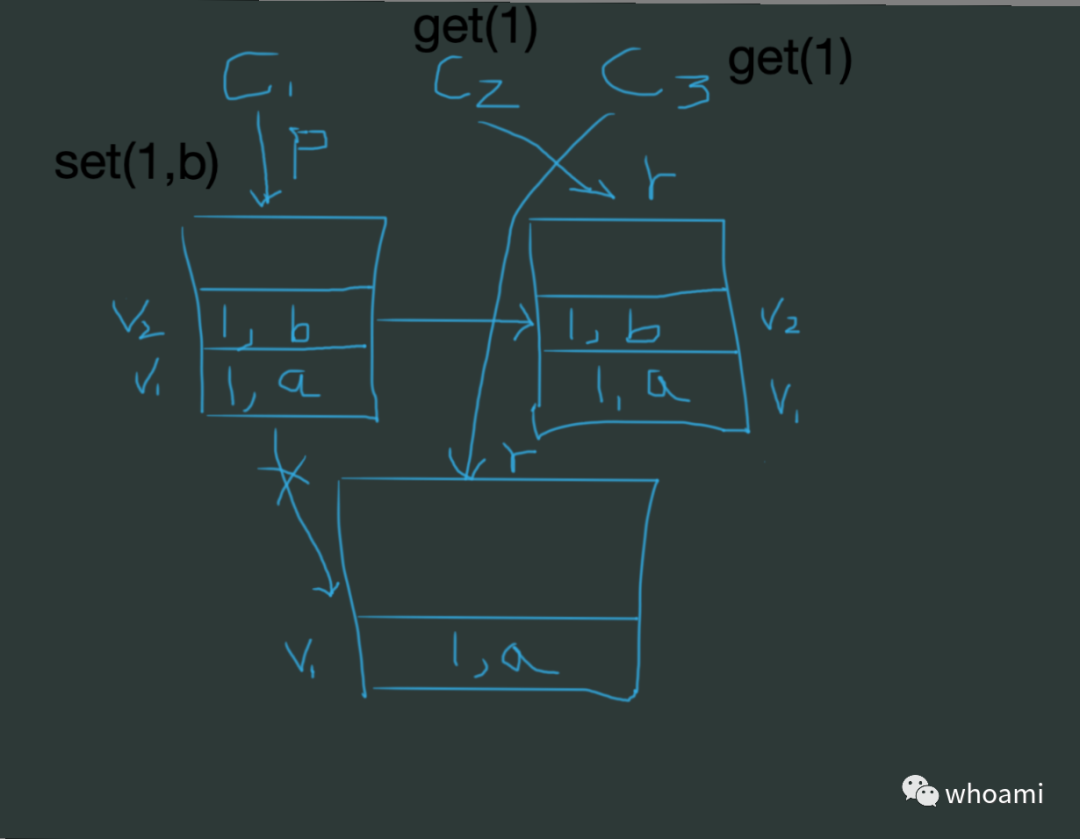
图,分布式 kv 一致性,思考如何在分布式加多数据副本情况下,变更数据保障不同 client 读取到的数据是一致的,有什么成熟的算法?
MapReduce
因为没有必要让工程师花费所有的时间来编写分布式系统软件,也要有大量的面向普通业务的开发工作,因此,这些不是很熟悉分布式系统的普通工程师确实需要某种框架可以让他们轻松大胆地编写他们想进行的任何分析工作,例如:排序算法、Web索引或链接分析器等,并在写这些应用程序时无所畏惧,同时无需担心它是否能在数以千计的计算机上运行的诸多细节,比如:如果将这些工作分散到这些计算机上、如何组织所需任何数据的移动、如果应对不可避免的故障。因此寻找和创造一种框架使得非专业人员也能轻松开发和运行大型分布式计算系统,进行海量数据的处理,正是 MapReduce 全部意义所在。
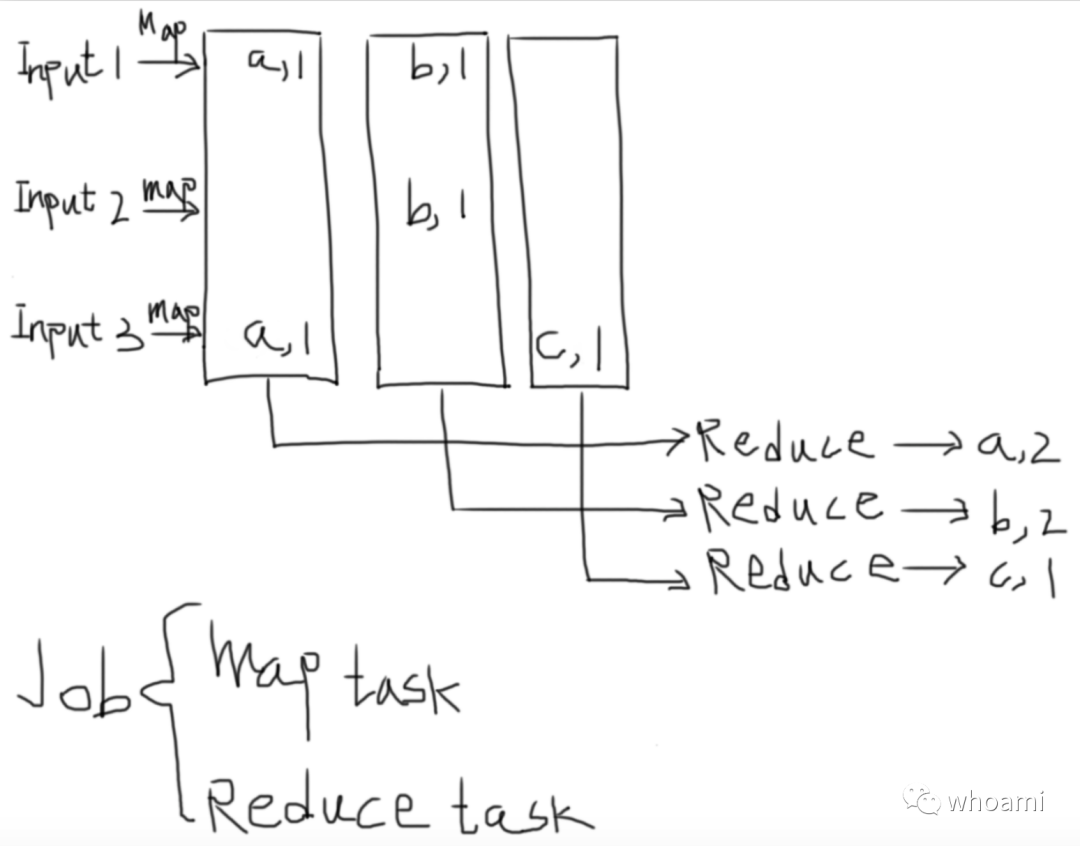
Map(k,v)
split v into words # K is filename, ignore
for each word w
emit(w, "1")复制
Reduce(k,v)
emit(len(v))复制
reference:http://www.itweet.cn/2018/04/23/mapreduce-osdi04/
homework: lab1 mapreduce
Reference:
6.824 - Spring 2020: https://pdos.csail.mit.edu/6.824/
6.824 Lab 1: MapReduce: https://pdos.csail.mit.edu/6.824/labs/lab-mr.html
MapReduce: Simplified Data Processing on Large Cluster
