





哈喽,大家好,好久不见,甚是想念。
今天和大家分享一点关于数据预处理中过采样和欠采样的内容。
欢迎关注哔哩哔哩UP主:我家公子Q
微博账号:我家公子Q
坚持、努力;你我同行!Born to fight!
目录
 引言
引言
 过采样
过采样
 欠采样
欠采样
 总结
总结

我们在平常做建模时往往会对大量的样本数据进行整理、清洗和分析,在后续的建模工作时,常常会直接拿所得的样本数据进行训练,但是这样会遗漏一个问题。各类样本的比例不均衡,比如做一个客户违约与否的二分类问题,我们拿到的样本可能会存在某一类样本过多(或过少),比如样本数据中违约的样本数量远远大于不违约的样本数量,则在模型训练时,导致模型大部分精力在违约样本上,这样可能就导致可能最终训练得到的模型在训练集中表现良好,但是在测试集中却表现糟糕。

综上所述,关于样本采样比例方面,我们在建模前应先看看样本的采样比例是否合适,若不合适则可采用过采样和欠采样的方法去调整样本。
注意:经过上述阐述,你应该了解到,“过采样”和“欠采样”是处理各类样本比例失衡的方法,或者叫手段,别误以为二者是表征样本状态的概念。

这里叙述两种过采样方法,分别是随机过采样和SMOTE法过采样。(使用的样本数据可以点击“阅读原文”获取)
(1)随机过采样
原来样本里有753个样本,其中152个违约样本,601个非违约样本(1代表违约,0代表不违约)。
随机过采样即从100个违约的样本中随机抽取旧样本作为一个新样本(有放回抽样),共反复抽取900次,然后和原来的旧样本构成1000个违约样本数据,和1000个不违约的样本一起构成新的训练集。因为随机过采样重复地选取了违约的样本,所以有可能造成对违约样本的过拟合。
(2)SMOTE法过采样
SMOTE法过采样即合成少数类过采样技术,是一种改进随机过采样容易模型过拟合的方案。我们通过绘图来讲解SMOTE法的原理,假设对少数类进行4倍过采样:
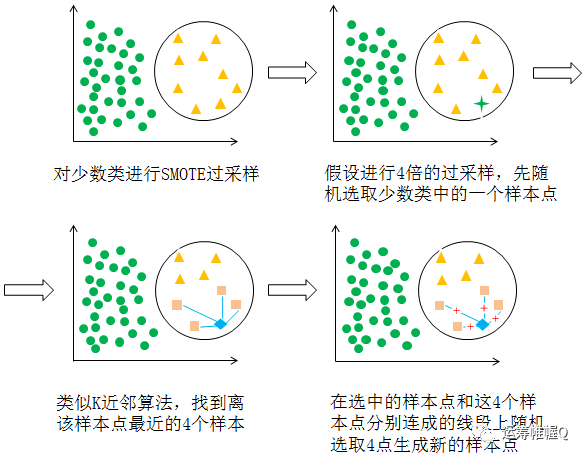
我们分步骤对SMOTE法进行说明:
随机选取少数类的一个样本点;
找到距离这个点最近的n个样本点(这里n是自定义的,表示将该类样本数量扩大n倍);
在最初选中的样本点和新找的n个样本点的连线上各自随机找一个点作为生成的样本点;
对少数类中的其余所有样本点重复步骤二和步骤三,直到少数类的样本点个数达到过采样目标为止。
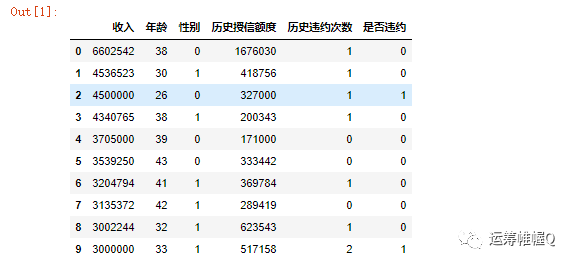
首先,使用Pandas读取数据。
1import pandas as pd
2data = pd.read_excel(r"C:\Users\phil\Desktop\过采样和欠采算例.xlsx")
3data.head(10)
其次,看一下各类样本的数量(这里先使用第一种方法看各类样本的数量)。
1data['是否违约'].value_counts()

可以看到0-1类样本比例严重失调,所以需要进行样本调整。
然后,建立自变量和因变量。
1X = data.drop(columns='是否违约')
2y = data['是否违约']
最后,使用过采样进行样本数据的平衡。
1from imblearn.over_sampling import RandomOverSampler
2ros = RandomOverSampler(random_state=0)
3X_oversampled, y_oversampled = ros.fit_resample(X, y)
imblearn库是Python中专门用来处理数据不平衡的工具库。第1行代码从imblearn库中引入用来随机过采样的函数RandomOverSampler();
第2行代码设定RandomOverSampler()函数的参数random_state为0,该数字没有特殊含义,只是保证每次生成的随机数一致,从而使得每次代码运行的结果都一致;
第3行代码使用原始数据的特征变量和目标变量拟合模型并将生成的过采样数据集赋值给变量X_oversampled和y_oversampled。
我们看一下现在两类样本数。
1y_oversampled.value_counts()
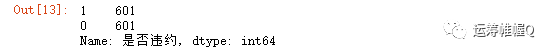
可以看到现在两类样本数量已经相等。
上边是随机过采样的方法,下边的代码是SMOTE过采样的方法,其他部分一致,此处不做过多展示。
1from imblearn.over_sampling import SMOTE
2smote = SMOTE(random_state=0)
3X_smotesampled, y_smotesampled = smote.fit_resample(X, y)
欠采样就是在非违约样本中随机选择152个样本,与152个违约样本构成新的样本数据。由于欠采样抛弃了大量的非违约的样本数据,所以以这种方式重新构建训练集,训练模型,可能会造成模型欠拟合的情况。

我们还是先看下各类样本的数量,使用另一个方法(使用collections库的Counter函数)。
1from collections import Counter
2Counter(y)
注意:这里的y还是前面定义的因变量。
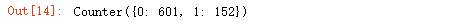
然后欠采样代码实现:
1from imblearn.under_sampling import RandomUnderSampler
2rus = RandomUnderSampler(random_state=0)
3X_undersampled, y_undersampled = rus.fit_resample(X, y)
第1行代码从imblearn库中引入用来随机欠采样的函数RandomUnderSampler();第2行代码设定RandomUnderSampler()的参数random_state为0,该数字没有特殊含义,只是保证每次生成的随机数一致,从而使得每次代码运行的结果都一致;第3行代码使用原始数据的特征变量和目标变量拟合模型并将生成的过采样数据集赋值给变量X_undersampled和y_undersampled。
再看下此时的样本情况。
1Counter(y_undersampled)
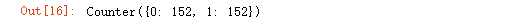
首先,本文说明了在进行模型训练时,要检查以下目前的样本数据是否合理,各类样本数量是否均衡,在不均衡的情况下,需要采取一定的手段,调整样本。

其次,过采样和欠采样时两种调整样本数据使其均衡的两种方法,而不是样本的状态。

最后,过采样其实就是就数量较多的样本,所以其可能出现模型过拟合的情况;而欠采样是就数量少的样本,会删掉大量样本数据,所以其可能会出现模型欠拟合的情况。然后过采样常见的方法有随机过采样法和SMOTE过采样法。



