





点击上方蓝字关注我

|前言

在此之前,先引入下面的这些问题:
【1】模糊查询什么时候走索引?什么时候不走索引?
【2】IS NULL和IS NOT NULL走不走索引?
【3】诸如<、>、IN、BETWEEN … AND这样的范围查询走不走索引?
【4】如何快速排序?
【5】!=、NOT IN一定走或一定不走索引吗,如果不走的话,优化起来有没有坑呢?
【6】OR到底能不能走索引?
【7】索引合并是什么?什么时候才会出现索引合并?
【8】如何揪出慢查询真凶?
如果你能轻松的回答下来以上所有问题,并且非常确定自己的答案就是对的,那这篇文章就没有看的必要了。否则,就跟我一起带着这些疑问耐心的看完这篇文章吧!相信在看完这篇文章后一定会有不小的收获的!
|尽量别用SELECT *
不推荐使用SELECT * 的原因主要有以下两个方面:
【1】select * 会返回全部字段,有些字段可能没必要。无形中增加了MySQL压力和网络压力。
【2】select * 在执行的时候会去查询表结构,也会产生本就不必要的开销。
基于以上两点,当我们写SQL语句时,尽量明确要查询的数据列。以避免额外的性能和网络开销。
|慎用模糊查询
模糊查询的通配符如果写在前面,则这条查询语句是不会走索引的。所以在编写模糊查询SQL语句时,尽量不要将通配符写在前面。
不走索引的模糊查询语句:
SELECT empno,ename,salFROM t_empWHERE ename LIKE "%C%";
走索引的模糊查询语句:
SELECT empno,ename,salFROM t_empWHERE ename LIKE "C%";
如果你了解MySQL的索引的存储机制,那这种现象不难理解。因为MySQL可以根据首字母快速在二叉树中找到数据列所在的位置,如果首字母是一个通配符,那就只能走全表扫描了。
这一点通过EXPLAIN分析SQL执行行为也可以验证:
通配符写在最前面的:
EXPLAIN SELECT empno,ename,salFROM t_empWHERE ename LIKE "%C%";

直接走的是全表扫描
通配符写在其他位置的:
EXPLAIN SELECT empno,ename,salFROM t_empWHERE ename LIKE "C%";

走的是范围扫描
|IS NULL、IS NOT NULL走不走索引?
在很多SQL语句优化文章里也会说到IS NULL和IS NOT NULL将不走索引,但事实真的是这样吗?其实,IS NULL能不能走索引取决于二叉树能不能存储空值。
接下来我将使用MySQL5.7和MySQL8.0这两个目前用的人最多的两个版本来验证一下IS NULL和IS NOT NULL是否会走索引这个问题:
MySQL 5.7 IS NULL 测试:
EXPLAIN SELECT empno,ename,salFROM t_empWHERE deptno IS NULL;

MySQL 8.0 IS NULL 测试:
EXPLAIN SELECT empno,ename,salFROM t_empWHERE deptno IS NULL;

MySQL 5.7 IS NOT NULL测试:
EXPLAIN SELECT empno,ename,salFROM t_empWHERE deptno IS NOT NULL;

MySQL 8.0 IS NOT NULL测试:
EXPLAIN SELECT empno,ename,salFROM t_empWHERE deptno IS NOT NULL;

下面说结论:
【1】无论是MySQL 5.7还是MySQL 8.0 IS NULL都可以走索引,而且走的还是效率相对来说比较高的ref类型,这也就意味着索引列的值为NULL也会被存储到二叉树中(二叉树可以存储NULL值)。
【2】MySQL 5.7的IS NOT NULL不会走索引,MySQL 8.0的IS NOT NULL会走索引。这是MySQL优化器优化的问题,理论上IS NOT NULL可以直接去二叉树中遍历不为空的索引。
既然IS NOT NULL在MySQL 5.7上走不了索引,那我们就要对其进行优化。改进思路是不允许数据列为空,用特殊值代替空值。比如针对UNSIGNED INT类型可以给定默认值0用来代替NULL值,则SQL语句可以优化成以下方式:
EXPLAIN SELECT empno,ename,salFROM t_empWHERE deptno > 0;

可以看到,因为在检索条件中用到了>号,所以优化后的SQL语句走了范围索引。关于范围查询还有要注意的地方,待会儿再讲。
|范围查询需要注意结果集数量
在检索条件中使用<、>、IN、BETWEEN … AND时,都会进行范围查询。范围查询可不可以走索引?不一定。 走不走索引需要看结果集的数量,结果集数量低于某个阀值是可以走索引的,高于这个值就直接走全表扫描了。
sbtest1表中有10W条数据,k有索引(该表以及数据是直接用sysbench生成的):
CREATE TABLE `sbtest1` (`id` int unsigned NOT NULL AUTO_INCREMENT,`k` int unsigned NOT NULL DEFAULT '0',`c` char(120) NOT NULL DEFAULT '',`pad` char(60) NOT NULL DEFAULT '',PRIMARY KEY (`id`),KEY `k_1` (`k`),KEY `c_1` (`c`)) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8 MAX_ROWS=1000000;
下面这条范围查询语句是可以走索引的:
SELECT id,k,cFROM sbtest1WHERE k < 40000;
用EXPLAIN分析一下:
EXPLAIN SELECT id,k,cFROM sbtest1WHERE k < 40000;

接下来试着增加一下结果集的数量:
EXPLAIN SELECT id,k,cFROM sbtest1WHERE k < 50000;

直接变成了全表扫描
IN、BETWEEN … AND在这里也是一样的。所以,可以得出结论:范围查询走不走索引,取决于结果集的数量。如果你确定在当前业务下,当前的范围查询的结果集数量不多,那可以放心大胆的用。否则就要做好出现慢查询的心理准备。
|可以给ORDER BY字段加索引
因为二叉树是有序的,所以当使用ORDER BY排序时,如果给用于排序的数据列添加了索引,将会增加排序速度。
|!=、NOT IN走不走索引?
!=、NOT IN会不会走索引?在绝大多数的SQL优化文章中会提到不走索引。但结果真的是这样吗?
还是拿MySQL 5.7和8.0做比较,直接说结论:
【1】对于MySQL 5.7,!=、NOT IN直接走全表扫描,效率低下。
【2】对于MySQL 8.0,优化器会判断!=、NOT IN查询条件的结果集数量。如果结果集低于一定的数量,则会走范围查询。如果高于一定的数量,则还是直接走全表扫描。
由于篇幅有限,在这里就不贴上我的实验过程了,感兴趣的同学可以自己试一下。
那!=、NOT IN有没有优化空间呢?以!=为例,优化的思路也只能是用UNION或UNION ALL连接两个范围查询:
EXPLAIN SELECT id,k,c FROM sbtest1 WHERE k < 50000UNION ALLSELECT id,k,c FROM sbtest1 WHERE k > 50000;

变成了2次全表扫描
为什么在本例中优化后的反而不如优化前的呢?其实这又回到范围查询的问题了,要根据自己的实际业务判断两个结果集的返回数量。优化不好的话,可能会拖慢性能,还不如不优化呢。
|避免在表达式左侧使用运算符或函数
表达式左侧使用运算符或函数必然导致索引失效(右侧不会),其实也没什么好解释的。
EXPLAIN SELECT id,k,cFROM sbtest1WHERE k * 2 = 100000

表达式右侧使用运算符或函数是没问题的:
EXPLAIN SELECT id,k,cFROM sbtest1WHERE k = 100000 / 2;

|OR能不能走索引?
如果你用的是MySQL 5.1及之后的版本,放心用,这得益于MySQL 5.1引入的索引合并技术。如果用的是之前的版本,那将不能完全走索引(OR之前的可以走,OR之后的不可以)。
EXPLAIN SELECT id,k,cFROM sbtest1WHERE k = 50000 OR c LIKE "737%";

可以看到得益于索引合并技术,走了索引。关于索引合并技术,下面细说。
结论:
【1】MySQL 5.1之前不要用OR,用UNION 或 UNION ALL优化
【2】得益于索引合并技术,MySQL 5.1之后可以放心用OR,不需要对其进行优化。
|索引合并技术
索引合并是MySQL5.1之后引入的技术,MySQL5.1之前一个表一次只能使用一个索引,单次查询只能使用一个索引。理解索引合并算法有利于我们更好的建立索引,以及更好的编写SQL语句。索引合并说白了就是对多个索引条件进行扫描,然后对他们的结果进行合并或求交集。
索引合并算法有三个:
【1】intersect:将得到的结果进行交集运算,比如AND。如果有两个单独的索引都可用,但是其中任何一个都不是最优化的,那么优化器选择合并两个索引并且在他俩的结果集中做一个交集,然后根据这个交集对磁盘数据进行匹配。出现这种情况时,说明索引建立的不合理,应当将这两个单独的索引合并成一个索引。
【2】union:将得到的结果进行并集运算,比如OR。把所有相关索引连接起来,找到记录对应的ROWID,然后根据ROWID获取磁盘上的数据。
【3】sort_union:将得到的结果进行并集运算,比如OR。把所有相关索引连接起来,找到记录对应的ROWID,并且好顺序,然后根据ROWID获取磁盘上的数据。
|莫用相关子查询
关于相关子查询,我在我的上一篇文章中有写。感兴趣的可以去看我的文章:《CRUD?还能玩出花来?》。解决方式是用FROM子句代替相关子查询。
相关子查询语句:
SELECTename,salFROMt_empWHEREsal > ( SELECT sal FROM t_emp WHERE ename = 'JONES' )
优化:
SELECTe.ename,e.salFROMt_emp eJOIN ( SELECT sal FROM t_emp WHERE ename = 'JONES' ) t ON e.sal > t.sal
|慢查询日志
上面已经讲了在编写SQL语句时需要注意的问题,然而在实际应用中可能还是阻止不了慢查询的出现。出现了不要紧,揪出它再用EXPLAIN分析就行了。下面我就来说一说如何揪出慢查询真凶。
揪出慢查询真凶的方式就是开启慢查询日志,慢查询日志会把执行速度慢的SQL语句记录下来。可以使用下面的命令查看当前MySQL是否开启了慢查询日志,以及慢查询日志存放的具体位置:
SHOW VARIABLES LIKE "slow_query%";
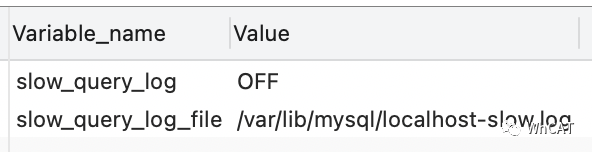
可以看到当前是没有打开慢查询日志的。开启的方式也很简单,在my.cnf中添加/修改以下两行代码即可:
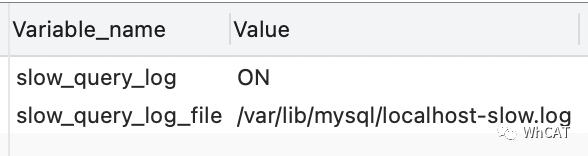
slow_query_log = ONlong_query_time = 1
long_query_time设定的是超时时间,当SQL语句的执行时间超过设定值(单位为s)后,则会被记录在慢查询日志中。修改完后记得重启一下MySQL服务。
下面故意执行一下耗时操作
SELECT SLEEP(2);
可以在慢查询日志中看到上面这条耗时SQL
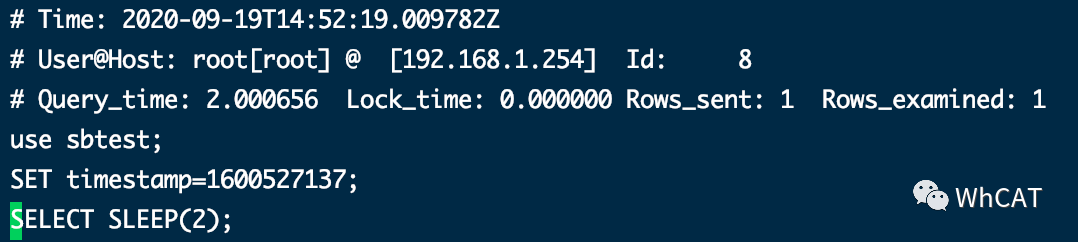
里面详细列出来了慢查询发生的时间、具体的慢查询语句等信息,可以帮助开发者快速定位问题。
这篇文章就写到这里了,如果有不足之处,还望指出。后面我还会更新更多MySQL优化,MySQL集群搭建(PXC、Replication集群),使用MyCat管理数据库集群等更多的MySQL相关知识。
非常感谢你能看到这里。如果你感觉这篇文章确实对你有所帮助,不妨点个在看,让更多人能够看到这篇文章。

