




7月份,Oracle DBA团队接到一项大型数据库的迁移加数据库字符集改造的任务。大型数据库迁移,基本上已经形成了以TTS(可传输表空间)为主,导出导入为辅,加上一些数据同步工具,基本上可以实现在两个小时的停机窗口内实现新老数据库的迁移切换。字符集转换是为了满足业务的不断推进,特别是国际业务的推广,适应中文的数据库字符集必须转换成适应多国文字的字符集。
根据业务情况,本次迁移可以有一个周末的时间用于迁移,这对我们来说是一个很好的消息,至少在迁移上时间是很充裕的。经过讨论之后确定了这样的方案路线:
①、搭建中转备机,并与源数据库同步;
②、 激活中转备机,将数据文件通过TTS的方式传输到目标环境;
③、 在目标环境上进行字符集转换;
④、 在停机窗口期间对激活备机到停机窗口期间的数据进行迁移(采用导出导入的方式)。
总体的迁移步骤与我们常规的迁移无二,这里重点介绍第三步,字符集转换,这是在日常中接触较少的内容。本次任务是数据库字符集从ZHS16GBK到AL32UTF8。ZHS16GBK是Oracle中支持中国国家字符集的字符集,通常来讲,数据库对于英文和中文字符的保存和处理是没有问题的。AL32UTF8对应UNICODE5.0,能够支持所有语言文字,所以ZHS16GBK是AL32UTF8字符集的子集,从子集到超集的转换,Oracle是支持的。我们很容易想到字符集转换涉及到了单个字符字节数的变换,比如中文字符在AL32UTF8下需要三个字节,而在ZHS16GBK只需要两个字节。接下来我们看一下数据库是怎么实现这种变化的。
在Oracle10g/11g版本环境下,GBK到AL32UTF8字符集的转换,通常有三种方案,分别是部分导出/导入与CSALTER脚本结合、单独使用CSALTER和传统的全库导出/导入。其中第一种方案是推荐使用的方案,也是本次迁移最终使用的方案;第二种方案通常行不通(因为GBK数据库不大可能没有存储中文字符),第三种方案由于风险较大、执行效率低(导致耗时较长)在实际环境下,基本上不推荐使用。字符集转换需要做导出导入,必须保证这期间数据库没有变动,因此需要一个较长的停机窗口,直接在源环境上实施风险大且无回退空间,本次转换在新环境上实施,顺带实现服务器从AIX操作系统项Suse迁移。字符集转换的步骤大致如下:
1、安装CSSCAN(Character Set Scanner utility)工具,CSSCAN是Oracle提供的一个用于检查字符集转换过程中可能出现的数据丢失或者损坏的情况。也可以单独地扫描某些表某些列能否进行字符集转换,并且能够并行扫描以加快扫描速度。通过@?/rdbms/admin/csminst.sql即可创建相关的用户。在操作系统运行指令csscan system/XXXX full=y tochar=al32utf8 array=4096000 process=4suppress=1000 lcsd=y log=csscan,即可获得检查报告。所消耗的时间与数据库的数据量以及并发数关系较大。完成后会生成*.out、*.txt、*.err三个文件,重点关注*.txt文件。
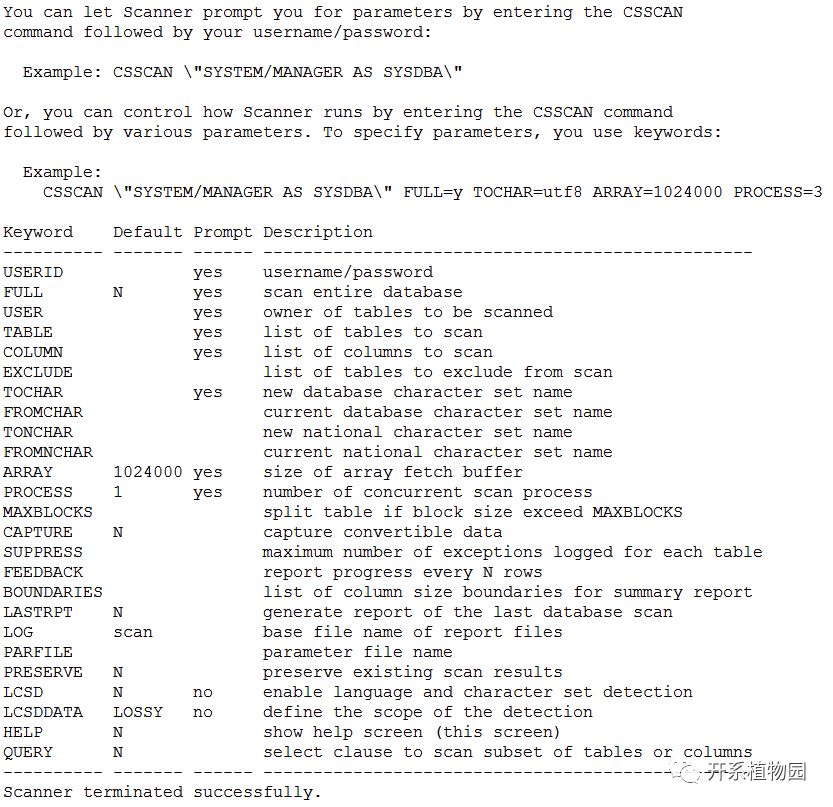
图1 CSSCAN用法
2、设置BLANK_TRIMMING参数为TRUE,可保证不同字节设置的数据之间能够成功迁移。例如,char类型之间的复制,varchar类型的截断复制。
3、处理不需要字符集转换的对象,包括清除RECYCLEBIN的对象;处理失效对象;处理数据泵无效对象(在使用数据泵进行导出导入操作时,会生成一个与导出导入过程相关的表,该表记录着数据泵导出或者导入的时候的一些信息,直接drop即可);处理以char、varchar2为单位的临时表(临时表需要重建,因为在字符集转换前后数据库保存这些临时表字段所需的空间有变化);清理注释。
4、实施CSSCAN,process可设置得大一点(可接近数据库cpu_count参数),因为是在全新环境上实施,不影响生产,实施完成后关注生成的txt文件。截取部分CSSCAN结果如下:
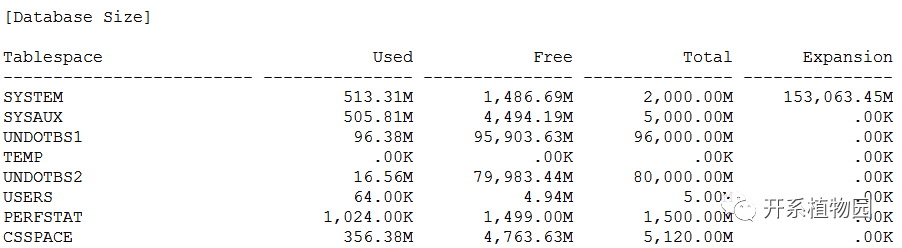
图2 CSSCAN结果-表空间信息

图3 CSSCAN结果-数据字典信息
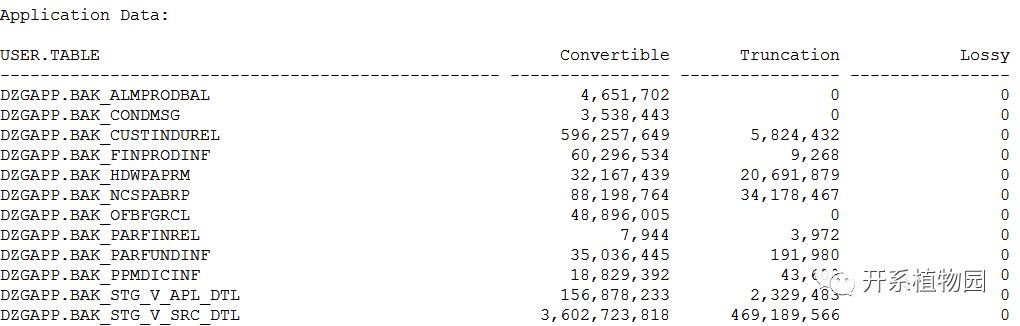
图4 CSSCAN结果-应用表信息
TXT文件主要包括表空间信息、数据字典信息、应用数据信息。因为对于一部分表需要进行扩位处理,所需空间会有所增减,csscan会评估出所需增加的空间大小。数据字典信息,应用数据信息会列出是否能够进行字符集转换的情况,主要包括changeless(无需转换,在实施CSALTER的时候会自动转换)、convertible(可转换的,可以通过导出导入的方式完成)、truncation(截断,转换过程中会出现截断,需要先进行扩位,扩位后会变成可转换类型)、lossy(有损失,出现的情况较少,一般为乱码,应用数据要确认好影响再处理,数据字典的处理要慎重,对不同的数据有不同的处理方式)。
5、对于扫描结果为convertible或者truncation的字段,进行扩位处理。本次实施的原则是CHAR类型的字段变为VARCHAR2类型。VARCHAR2类型的字段,原长度大于2000,扩位为4000。VARCHAR2类型的字段,原长度小于等于2000,扩位为原来的两倍。4000为Oracle11g varchar2数据类型的长度上限,12c提高至32000。具体的实施过程:①、导出数据;②、truncate掉相关表;③、进行扩位;④、字符集转换完成后导入数据。
6、搜集相关信息及处理,包括针对表的访问权限信息;获取使用以CHAR为长度单位的分区键或子分区键的分区表(扩位重建,导出导入);获取以CHAR为长度单位的索引字段的Function或Domain类型的索引列表,以及创建索引的DDL语句;获取以CHAR为长度单位的索引字段的Join类型的索引列表,以及创建索引的DDL语句;SYSTIMESTAMP类型字段的处理(提前修改为null,CSALTER后改回);使用CHAR作为长度单位的CLUSTER对象的处理;使用CHAR作为长度单位来定义“Unused columns”的处理(直接删除这些列)。此处收集的信息在CSALTER之后使用。
7、再次运行CSSCAN确认已满足字符集转换条件。在CSSCAN生成的TXT文件中应找到“The data dictionary can be safely migrated using the CSALTERscriptand. All character type application data remain the same in the newcharacter set”。表明已经满足转换条件了。
8、运行CSALTER。①、设置job_queue_processes、aq_tm_processes为0;②、停节点2实例,停节点1,以restrict模式启动节点1(防止其他用户连接数据库);③、执行脚本@?/rdbms/admin/csalter.plb(10s左右完成);④、检查是否调整成功,回调参数,重启数据库。
9、导入步骤5导出的数据,重建步骤6相关索引,恢复defaulttimestamp设置,编译失效对象,收集统计信息,重新导入PL/SQL等。
以上为字符集转换的主体步骤,完成后需要继续完成增量数据迁移,本文不作额外说明,下面稍微提一下字符集转换的影响。①、对SQL的影响,与字符字节相关的函数返回结果可能会有区别,比如LENGTHB与LENGTH、SUBSTRB与 SUBSTR、INSTRB与INSTR,还有PL/SQL中的字符型变量赋值可能会被截断;②、NLS_LANG设置,用于sqlldr的数据文件、PLSQL程序文件以及用户通过SQLPLUS输入的文本为GBK编码,则要求NLS_LANG的设置保持原有GBK设置不变,若用于sqlldr的数据文件、PLSQL程序文件以及用户通过SQLPLUS输入的文本为UTF8编码,则要求NLS_LANG的设置与数据库字符集(AL32UTF8)保持一致;③、性能的影响,单独的字符集转换影响不大,由于字符类型的长度变宽,缓存这部分数据会使用更多内存,对排序操作可能会有影响;④、PL/SQL工具的影响,存在部分工具无法支持UTF-8编码。
字符集转换步骤复杂,耗时较长,生产上不建议直接在源环境实施,否则容易导致数据库被破坏,恢复起来较为困难。可以激活备机的方式获取一个与源环境一致的数据库,在这个数据库上操作,可以获得比较充足的时间窗口,同时保证了源环境不被破坏,后续再制定方案迁移这期间的增量数据。一次成功的迁移从来都是一个联系紧密的过程,每一个环节都很重要,只有把握好了整体方案,理解每一步的作用,才能更好地完成迁移任务。
