




谷歌公司发布TPU之后,众多芯片厂家也随之发布面向AI的加速芯片,华为于2019年发布了自研达芬奇架构的神经网络处理器昇腾系列芯片。其架构如图4-5所示:
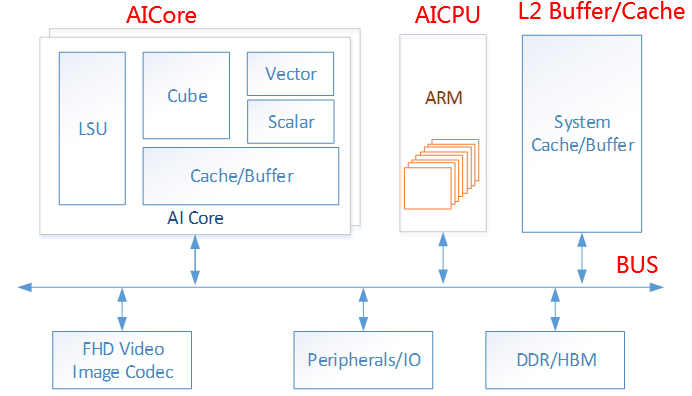
图4-5 昇腾架构
注:BUS是计算机系统中总线的意思,用于互联芯片上多个子单元,行业术语。Vector是矢量处理单元,用于将多个同一数据类型封装的数据包一次性处理,如(1,3,10,11)。Cube是矩阵处理单元,用于对矩阵数据结构进行线性代数操作,如点积、加减等。Cache是处理器上的高速缓存。Scalar是标量处理单元,用于对简单数据结构进行计算,如Int 1,Float 0.35等。HBM是高带宽内存,行业术语。Peripheral/IO是周边设备总线,用于将处理器和外部存储器等器件互联。FHD Video是高清视频的意思,Image Codec是图像编解码器的意思。
昇腾芯片当前有两个系列,分别为面向推理计算场景的310系列和面向训练场景的910系列,其规格如图4-6所示:

图4-6 昇腾310、昇腾910规格
注:DaVinci是华为昇腾处理器的芯片架构名称。FLOPS是指处理器每秒能处理的浮点数。EUV是芯片制造工艺,其采用极紫外线光刻技术。
昇腾芯片与业界顶尖厂商的AI处理器性能对比如图4-7所示:

图4-7 昇腾芯片与业界芯片对比
AI处理器芯片的普及,使数据库研究社区和厂商都在思考一个问题:如何使用AI处理器芯片巨大的算力优势,来帮助数据库系统运行的更快、更强、更好?如何利用AI芯片来提升数据库的智能性和高效性?
当前主要的研究方向是两个:
1. AI4DB(AI for DB):
传统数据库中,使用大量启发式算法,无法针对众多用户实际场景定制化开发,一般通过数据库系统预定义参数组合或可调节参数开关等方式,由DBA根据经验进行调整。AI算法与传统启发式算法最大不同,在于其可以根据历史数据学习,并根据现状在运行时进行动态调整。因此如何利用AI算法替换启发式算法,解决传统数据库的痛点问题成为研究的热点话题。典型方向:
优化器:传统代价优化基于采样统计信息进行表连接规划,统计信息不准(基数估计问题)、启发式连接规划(连接顺序问题)等是老大难问题。
参数调优:数据库有数十甚至上百可调节参数,其中很多参数是连续值调节空间,依靠人工经验无法找到最优参数组合。
自动化索引推荐和视图推荐:数据库有很多张表,很多列,如何自动构建索引和视图来提升数据库的性能?
事务智能调度:事务的并发冲突是OLTP数据库的难点,可以通过AI技术来进行智能调度从而可以提升数据库的并发性。
2. DB4AI(DB for AI):
- AI数据处理流程典型分四阶段,训练数据管理准备、模型训练和模型管理、推理应用,如图4-8所示:

图4-8 AI数据处理流程
训练数据管理和准备工作占据了AI全流程中80%以上时间,数据科学家和软件工程师花费大量精力在与数据标注、数据正确性、数据一致性、数据完整性、训练结果可重复性等问题打交道。使用定制化、拼凑型的数据存储解决方案,缺乏高效的AI训练数据管理系统是问题的根源。数据库系统半个世纪的研究成果能有效解决该领域的问题。当前已经有众多公司基于数据库系统启动相关系统的研发,典型如苹果公司的MLdp系统。
当前AI模型训练主要以AI计算框架为主,但其迭代计算中产生大量相似、冗余的参数、模型等数据,缺乏有效的模型管理,导致模型训练中不断重复计算,模型训练效率大打折扣。如何使用数据管理的方法,如物化视图、多查询优化等技术,对训练中产生的模型数据有效管理、实现存储换计算、加速AI训练计算成为研究的热点,如马里兰大学的ModelHub等项目。
模型推理计算是将训练好的模型部署到应用环境中的过程,如何减少推理计算的开销、降低推理延迟、提升推理的吞吐量是系统开发者关注的重点。当前AI计算框架缺乏针对以上诉求的优化,使用传统数据库优化器的技术优化该过程是研究热点,如伯克利大学的Model-less Inference等。
因此使用数据管理技术对AI流程进行全栈优化是数据库研究者需要考虑的问题。
2) 对于企业用户来说,仅仅优化AI流程的效率是远远不够的,因为:
当前AI应用仍处于早期阶段,搭建一套AI应用系统不但成本高昂,而且极为复杂,也难以在部署后继续开发业务。如何构筑一套开箱即用、业务领域专家也能轻松使用的AI应用系统是当前企业对AI系统厂商提出的重大挑战。
从历史上看,当前AI应用与数据库系统诞生之前的1960年代极为相似。在数据库系统内构筑一套端到端、全流程的AI处理系统,并提供类似SQL一样的声明式开发语言,将是解决企业用户应用AI门槛高难题的正确方向。
综上,DB4AI是用数据库技术打造一套端到端全流程AI系统的研究方向,是AI应用平民化的必经之路。
