




为了原生支持人工智能技术,对于大量AI算法(如回归、聚类、深度学习等)和底层算子(如张量计算)落地中普遍存在3个问题:
- 首先,存在大量矩阵运算,CPU计算粒度较低,处理这类运算的效率较差。
- 其次,AI算法中存在较复杂的标量运算,需要更高性能的CPU来处理。
- 再有,随着计算粒度要求的提升,芯片需要缓存更多的数据,数据宽度增加。传统数据库多只基于通用的CPU处理操作。
因此对于专门处理各类机器学习算法(如统计学习、深度学习、强化学习等)设计的昇腾芯片,能够为智能数据处理和计算提供硬件支撑。以华为开发的昇腾芯片310/910为例,其核心部件包括AI-Core、AICPU(ARM)、SVM(Support Vector Machine,支持向量机)大规模缓存,主要从5个方面对不同机器学习算子的计算能力进行优化:
- 卷积、全连接操作:利用3D Cube引擎,提供矩阵乘法的核心算力。
- Pooling、ReLu、Batchnorm、Softmax、RPN等其他张量运算:通过Vector计算单元,来覆盖剩下的向量运算操作。
- 标量运算:用Scalar计算单元,完成控制和基础的标量运算。并集成专门的AICPU,计算更复杂的标量运算。
- 数据宽度增加:丰富片上存储单元,用大数据通路保证Cube/Vector计算单元的数据供应。
- 增加协同运算:对算法和软件进行协同优化。
此外,在昇腾AI-Core统一的架构Davinci Core核心部件包括:
- Cube运算单元(矩阵乘)
- Vector运算单元(向量运算)
- Scalar运算单元(标量运算)
- MTE(数据传输管理)
- Buffer(高速数据存储)
- 指令和控制系统
面对全场景中不同的企业和产品,这套架构能够提供丰富的接口,支持灵活扩展和多种形态下的AI加速板卡的设计,有效应对多样化客户数据中心侧的算力挑战,加速AI算法在数据库系统中的落地。310昇腾芯片架构,如图6-5所示。
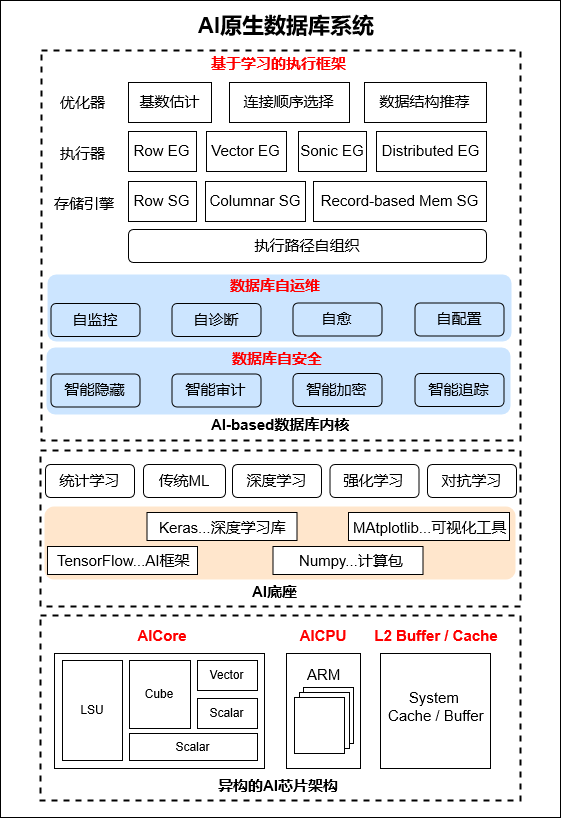
图6-5 昇腾310芯片架构示意图
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
