




前面提到,行存储是一个基于磁盘的存储引擎。为了避免IO的高昂开销,存储引擎会缓存一部分页面在内存中,便于随时对其进行检索和更改。存储引擎会对缓存的页面进行筛选、替换和淘汰,保证留存在缓存的页面能够提高整个引擎的执行效率。
行存储中也有着种类较多的缓存,除去正常数据页面的缓存之外,还存在用于缓存各类表的元信息的Relation Cache(数据表缓存),以及用于加速数据库系统信息以及系统表操作的Catalog Cache(系统表缓存)。这些种类的缓存都以page(页面)的形式归由共享缓冲区结构管理。
共享缓冲区由大量的页面槽位构成,槽位本身有对应的描述结构体,以及用于管理处于这个操作的并发操作的页面级别锁,并配有一个空闲链表来进行空闲空间管理。如图9-19所示。
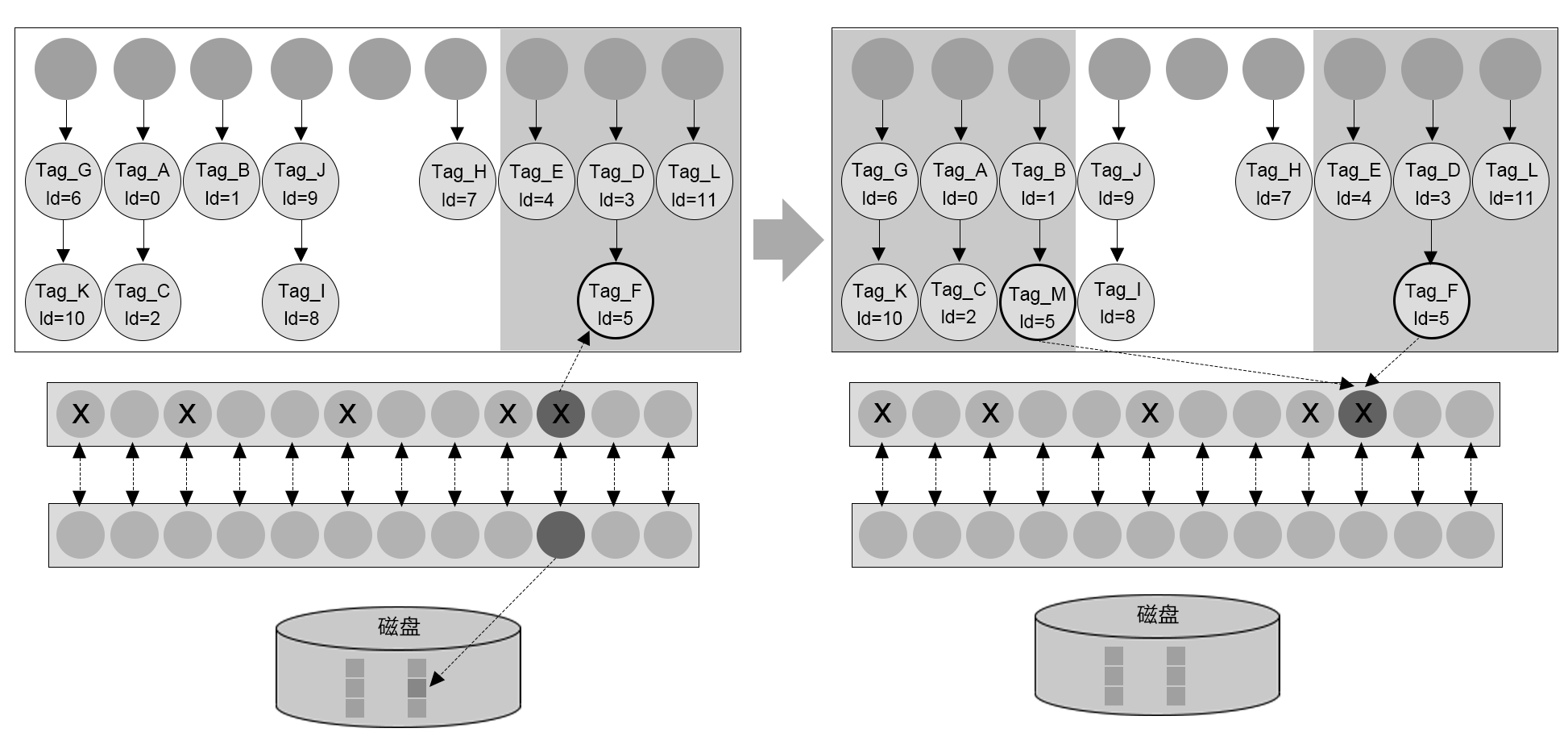
图9-19 共享缓冲区
行存储引擎中操作对事务的读写请求,都会被先传递至共享缓冲区。对一个页面的请求会现在缓冲区内进行搜索,如果未命中,则获取一个空的槽位(可能需要淘汰掉已经在缓冲区中不常用的页面),再与文件系统进行交互将所需页面读到槽位中,加锁并使用。根据业务的特征和负载、以及共享缓冲区的大小,已经在缓冲区内的数据页面会被反复命中,避免了与磁盘的IO开销,从而加速整个事务处理流程。
对页面的更改也会放在缓存中并被标为脏页面。此时后台写线程(background writer)会定期对脏页面进行清理和刷盘操作,把空间返还给缓冲区。另一方面,Checkpoint,也就是检查点操作,在进行时也会将所有的页面刷盘,确保数据的持久化。这里需要注意的一个概念是,当一个事务提交后,这个事务执行过程中更改的页面并不一定被刷盘至磁盘,事务本身的持久化机制实际上是由事务强制刷盘的WAL,也就是xlog,来保证的。在Checkpoint操作后,因为相关页面都已经持久化至磁盘,因此Checkpoint时间点之前的xlog,就可以被回收了。这个机制会在后续的章节继续展开。
共享缓冲区实际上是内存与持久化存储中协调管理调度的核心机制,对数据库管理系统的效率有着很大的影响。为了进一步提升缓冲区中页面的命中率,一些可能会影响缓冲区内页面与业务关联性的操作,都会使用一个专门单独开辟的缓冲区,Ring Buffer(环状缓冲区)。批量的读、批量的写、以及Vacuum的页面清理,都属于这类操作。
